.png)


【摘要】为AI Agent选择大模型如同为其挑选“大脑”,是决定其能力上限的关键架构决策。文章系统性地从性能、成本、可控性、生态及安全合规五大核心维度出发,构建了一套科学的选型框架,并结合具体业务场景给出实战策略。
引言
在AI Agent的设计与落地过程中,有一个决策点,其重要性远超其他。它不是某个精巧的算法,也不是复杂的系统架构,而是为Agent选择那颗驱动一切的“智能大脑”——大语言模型。这个选择,是决定Agent能力上限和业务成败的关键一步。
一个恰当的模型,能让Agent精准洞察用户意图,自主规划并执行复杂任务。一个不合适的模型,则可能让所有后续的设计与开发都事倍功半,最终产出一个“听不懂、想不明白、做不好”的数字员工。
模型选型不仅影响Agent对复杂指令的理解深度,影响任务规划的可靠性,还直接关系到自动化流程的稳定性、合规性与长期运营成本。面对市场上琳琅满目、日新月异的大模型,从性能超群的闭源巨头到灵活可控的开源新秀,开发者和企业常常感到无所适从。
本文旨在拨开迷雾。我们将系统性地梳理一套实用的模型选型方法论,从五个核心评估维度出发,深入探讨不同业务场景下的选型策略,并提供一套可落地的评测流程与决策框架。希望通过这趟旅程,你能为你的AI Agent,找到那个最合拍的“大脑”。
一、🧠 模型选型的五大核心评估维度
%20拷贝-onae.jpg)
建立一套科学、全面的评估框架,是走出“模型选择困难症”的第一步。这套框架应该像一个多维度的坐标系,帮助你在纷繁复杂的模型市场中,精准定位最适合你的那一个。以下五个维度,构成了这个坐标系的核心轴。
1.1 性能与能力——它到底有多“聪明”?
性能是模型的基石,是Agent能力的天花板。但“聪明”是一个笼统的概念,我们需要将其拆解为具体、可衡量的指标。
1.1.1 通用基础能力
这是模型的“智商”底座,决定了它能否应对开放、多变的任务环境。
逻辑推理 模型的推理能力直接关系到Agent能否进行有效的任务拆解和规划。一个复杂的指令,比如“分析上个季度的销售报告,找出销售额下降超过10%的产品线,并起草一封邮件向销售总监汇报”,需要模型具备强大的逻辑链条构建能力。
代码生成与理解 现代Agent大量依赖工具调用(Tool Calling),而这本质上是模型生成和理解代码片段(如API调用)的能力。模型的代码能力越强,Agent与外部工具的交互就越可靠、越高效。
多模态理解 未来的Agent必然是多模态的。它需要能看懂图片、听懂语音、理解视频。评估模型时,必须考虑其处理图像、音频等非文本信息的能力,这决定了Agent应用场景的广度。
主流的闭源模型如GPT-4系列、Claude 3系列、Gemini 1.5 Pro等,在这些通用能力上通常表现突出,是处理复杂综合任务的优选。
1.1.2 本地化与中文能力
对于服务中国市场的Agent,模型的中文处理能力至关重要。这不仅仅是语言翻译的问题,更涉及到文化背景、专业术语和本土知识的深度理解。
中文语境理解 国产模型如通义千问的Qwen2.5-Max、文心一言4.0、智谱的GLM-4等,在训练数据中包含了海量的中文语料,因此在理解中文特有的习语、网络用语、文化典故方面具有天然优势。
本土知识储备 一个面向国内用户的法律咨询Agent,需要理解中国的法律体系;一个金融分析Agent,需要熟悉A股的财报格式和监管政策。国产模型在这方面的数据积累通常更胜一筹。
因此,在中文业务场景下,优先考虑和评测优秀的国产大模型,往往能获得更好的效果和用户体验。
1.1.3 垂直领域专业能力
通用大模型是“通才”,但在特定专业领域,我们更需要“专家”。
一个通用模型可能知道“青霉素”是什么,但一个经过医疗数据精调的模型,能准确理解“头孢菌素类抗生素与青霉素的交叉过敏反应风险”。在金融、法律、医疗、科研等知识密集型行业,模型的专业深度直接决定了Agent的价值。
这时,开源模型 + 领域精调的路径就显示出巨大优势。选择一个优秀的开源基座模型,如Code Llama(代码)、Baichuan(中文)、Qwen(综合),用高质量的行业私有数据进行微调,可以打造出在该领域超越通用模型的专家Agent。
1.1.4 指令遵循与风格差异
Agent的可靠性,很大程度上取决于模型能否严格遵循指令。
结构化输出 当你要求模型“以JSON格式返回结果,必须包含‘name’和‘status’两个字段”时,它能否稳定、不打折扣地执行?这对于需要程序化处理模型输出的Agent至关重要。任何多余的解释性文字或格式错误,都可能导致后续流程中断。
风格与语气适配 一个客服Agent需要亲切、耐心;一个专业报告生成Agent则需要严谨、客观。不同模型有其固有的“性格”和表达风格。例如,加州大学伯克利分校的一项研究发现,不同模型在输出的稳定性和创造性上存在显著差异。选型时,需要通过实际测试,评估模型输出的风格是否与你的产品调性相符。
下面这个表格可以直观地展示指令遵循能力的重要性。
1.2 成本与预算——钱要花在刀刃上
成本是决定项目能否从原型走向规模化的生命线。评估成本时,不能只看API的标价,而要进行全局、长远的核算。
1.2.1 API调用成本 vs 私有化部署成本
这是一个核心的战略选择,直接影响项目的技术路线和财务模型。
闭源模型API
优点 按需付费(通常按Token计费),初期投入低,无需关心底层运维,上线速度快。非常适合初创团队、快速原型验证和中小规模的应用。
缺点 规模化后,API费用会急剧增长,成为沉重的运营负担。你对成本的控制力较弱,受制于厂商的定价策略。
开源模型私有化部署
优点 长期来看,当调用量达到一定规模时,总拥有成本(TCO)远低于使用API。你可以完全掌控计算资源,进行极致的性能优化。
缺点 需要一次性投入较高的初始成本,包括购买或租赁GPU服务器、搭建MLOps平台以及组建专业的技术运维团队。
1.2.2 上下文长度与隐性工程成本
上下文窗口(Context Window)的长度,是一个常常被忽视但极其关键的成本因素。它带来的不仅是API费用的变化,更是巨大的隐性工程成本。
想象一下处理一份50页的PDF合同。
使用短上下文模型(如4K) 你无法一次性将整个合同喂给模型。工程师需要设计一套复杂的文本处理流水线,包括文档切片(Chunking)、向量化(Embedding)、构建检索系统(RAG),然后通过多次查询和总结,才能拼凑出完整的答案。这个过程不仅开发复杂、容易出错,而且每次交互都涉及多次模型调用,实际成本可能并不低。
使用长上下文模型(如Claude 3.5 Sonnet的200K,Gemini 1.5 Pro的1M) 你可以直接将整个合同作为提示词(Prompt)输入。模型可以在一次调用中通读全文,进行精准的交叉引用和深度分析。这极大地简化了开发流程,降低了工程复杂度和出错率,让开发者能更专注于业务逻辑本身。
我们可以用一个流程图来直观感受这种差异。
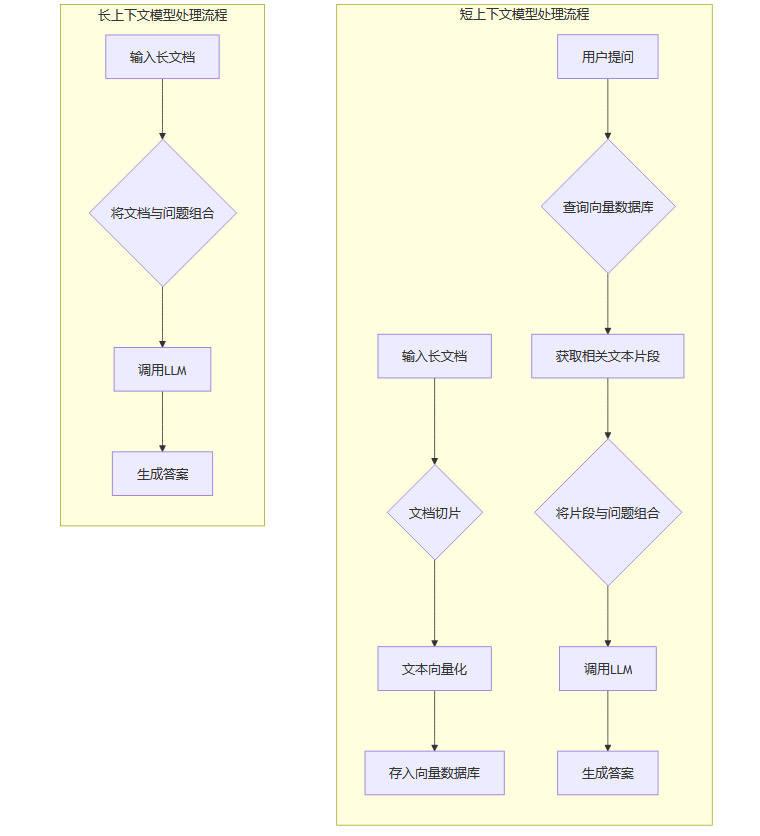
所以,一个API单价更高的长上下文模型,在处理长文本任务时,其综合成本(API费用 + 开发维护成本)可能反而更低。
1.3 可控性与稳定性——它是可靠的“员工”吗?
一个企业级的Agent,必须是稳定、可靠、行为可预测的。模型的可控性和稳定性,直接决定了你的Agent能否成为一名合格的“数字员工”。
闭源模型 你得到的是一个“黑箱”。它的优点是开箱即用,性能强大,并且有大厂持续进行维护和升级。但缺点也同样明显,你无法控制它的更新。今天运行正常的Prompt,明天可能因为模型版本迭代而效果大变,这就是所谓的“Prompt漂移”。这种不确定性对于需要长期稳定运行的自动化业务流程来说,是一个潜在的风险。
开源模型 你拥有的是一个“白箱”。最大的优势在于完全可控。你可以选择一个特定的模型版本并长期使用,确保Agent行为的一致性。你可以对其进行深度定制和微调,让它完全适配你的业务需求。你可以深入其内部机制进行优化,以达到最佳的性能和成本效益。当然,这种控制力是以更高的技术复杂度和运维责任为代价的。
选择闭源还是开源,本质上是在“便利性”与“控制权”之间做权衡。
1.4 生态与工具链——它是“孤岛”还是“枢纽”?
一个成熟的大模型,绝不是一个孤立的算法,它的背后是一个强大而繁荣的生态系统。这个生态系统,是你开发Agent时的“军火库”和“后援团”。
API与SDK 是否提供了各种主流编程语言的SDK?API文档是否清晰、完善?社区是否活跃,遇到问题能否快速找到解决方案?
开发框架兼容性 模型是否能与主流的Agent开发框架(如LangChain、LlamaIndex)无缝集成?良好的兼容性可以让你站在巨人的肩膀上,用更少的代码实现更复杂的功能。
配套工具 是否有成熟的推理优化框架(如vLLM、TensorRT-LLM)来加速私有化部署的性能?是否有便捷的微调工具(如Axolotl、LLaMA-Factory)?是否有公认的评估基准和工具来衡量模型效果?
一个生态繁荣的模型,意味着更低的开发门槛、更快的迭代速度和更强的技术支持。在选型时,考察其生态的成熟度,与考察模型本身的性能同等重要。
1.5 安全、合规与数据隐私——不可逾越的红线
对于任何企业级应用,尤其是处理敏感数据的场景,安全与合规是“一票否决”项。
数据隐私与主权
使用闭源API时,必须仔细阅读其服务条款。你的业务数据是否会流出境外?是否会被服务商用于模型的二次训练?对于金融、医疗、政务等行业,数据不出域是基本要求。
私有化部署是解决数据隐私问题的最彻底方案。数据始终保留在企业自己的服务器内,完全符合合规要求。
内容安全
模型自身的内容安全机制(即“护栏”)是否与你的业务场景匹配?一个用于生成营销文案的Agent,可能需要模型更有创造性、限制更少。而一个面向青少年的教育Agent,则需要极其严格的内容过滤机制。
法律法规遵循
模型及其应用是否符合所在地区的法律法规,如中国的《网络安全法》、欧盟的《通用数据保护条例》(GDPR)?这些法规对数据处理、存储和传输有严格规定。
建议企业在选型阶段,引入专业的第三方人工智能评测服务,对模型的安全性、稳定性和合规性进行全面评估,确保万无一失。
二、🗺️ 场景化选型策略
理论框架最终要服务于实践。下面,我们结合几个典型的Agent应用场景,给出具体的模型选择策略。
2.1 场景一:快速原型 / 低成本验证
核心需求 快速上线、低成本试错、验证商业模式(MVP)。
首选策略 高性价比的闭源API模型。
推荐模型
国际 OpenAI的
GPT-3.5-Turbo、Anthropic的Claude 3.5 Sonnet。它们在性能、速度和成本之间取得了绝佳的平衡,指令遵循能力出色,足以支撑绝大多数Agent流程的验证。国内 智谱的
GLM-3-Turbo或GLM-4-Air、通义千问、文心一言等。在中文场景下表现优异,API成本极具竞争力。
决策理由 在这个阶段,时间就是生命。利用成熟的API服务,可以让你在几天内就搭建起一个可用的Agent原型,快速推向市场收集反馈,避免在底层技术上投入过多沉没成本。
2.2 场景二:长文档处理 / 企业级专业Agent
核心需求 处理长篇幅、高信息密度的专业文档(如合同、财报、技术手册),并可能要求数据不出域。
首选策略 具备超长上下文能力的模型,并根据合规要求决定是否私有化。
推荐模型
云服务优先
Claude 3/4系列、GPT-4.1、Gemini 1.5 Pro。这些模型支持百万级别的上下文窗口,是处理长文本任务的“核武器”。合规优先 选择优秀的开源大模型进行私有化部署,并结合**RAG(检索增强生成)**技术。例如,使用
Qwen-72B或Llama 3 70B作为基座模型,将企业内部的文档构建为知识库。
决策理由 在此场景下,上下文长度和数据安全的重要性,超过了单纯的API调用单价。长上下文能力是刚需,而数据合规则是不可动摇的底线。
2.3 场景三:大规模 / 成本敏感型应用
核心需求 服务海量用户,每次交互的成本必须被压缩到极致(如AI社交、智能客服)。
首选策略 中小参数的开源模型 + 私有化部署 + 推理优化。
推荐模型
Qwen-7B、Llama 3 8B、DeepSeek-V2等。这些模型在保持相当不错性能的同时,对硬件资源的需求远低于巨型模型。关键技术
模型量化 将模型的权重从FP16/BF16转换为INT8甚至INT4,可以大幅减小模型体积和显存占用,提升推理速度。
模型剪枝/蒸馏 进一步压缩模型,去除冗余部分。
高效推理引擎 使用vLLM等工具进行部署,以获得更高的吞吐量(QPS)。
决策理由 当调用量达到每天数百万甚至上亿次时,API成本会成为压垮业务的稻草。通过私有化部署和极致的优化,可以将单次调用的边际成本降至几乎可以忽略不计的水平,这是规模化应用得以成立的经济基础。
2.4 场景四:垂直领域 / 行业专家型Agent
核心需求 在某个狭窄的专业领域(如中医诊断、特定芯片的Verilog代码生成)达到顶尖水平,构建技术壁垒。
必选路径 优秀的开源基座模型 + 高质量行业数据精调。
实施步骤
选择基座 根据领域特性选择一个合适的开源模型。例如,代码生成任务可选
Code Llama或DeepSeek-Coder;中文通用领域可选Baichuan或Qwen。数据准备 收集和清洗高质量的、专有的行业数据。这是决定精调成败最关键的一步,数据的质量远比数量重要。
进行微调 使用SFT(监督微调)或RLHF(基于人类反馈的强化学习)等技术,将行业知识“注入”模型。
决策理由 这是打造差异化竞争优势的唯一途径。通过精调,你可以创造出一个独一无二的、在特定领域远超任何通用模型的专家Agent,从而构建起坚实的护城河。
三、⚙️ 落地评测与决策流程
%20拷贝-xztl.jpg)
选型不是拍脑袋,而是一个严谨的工程过程。你需要建立一套从评测到决策的闭环流程。
3.1 建立你的评测清单
不要迷信任何公开的排行榜,唯一的标准是模型在你的真实业务场景中的表现。你需要设计一个全面的评测清单。
3.2 遵循清晰的决策法则
在评测数据的基础上,你可以通过一个决策树来辅助最终选择。
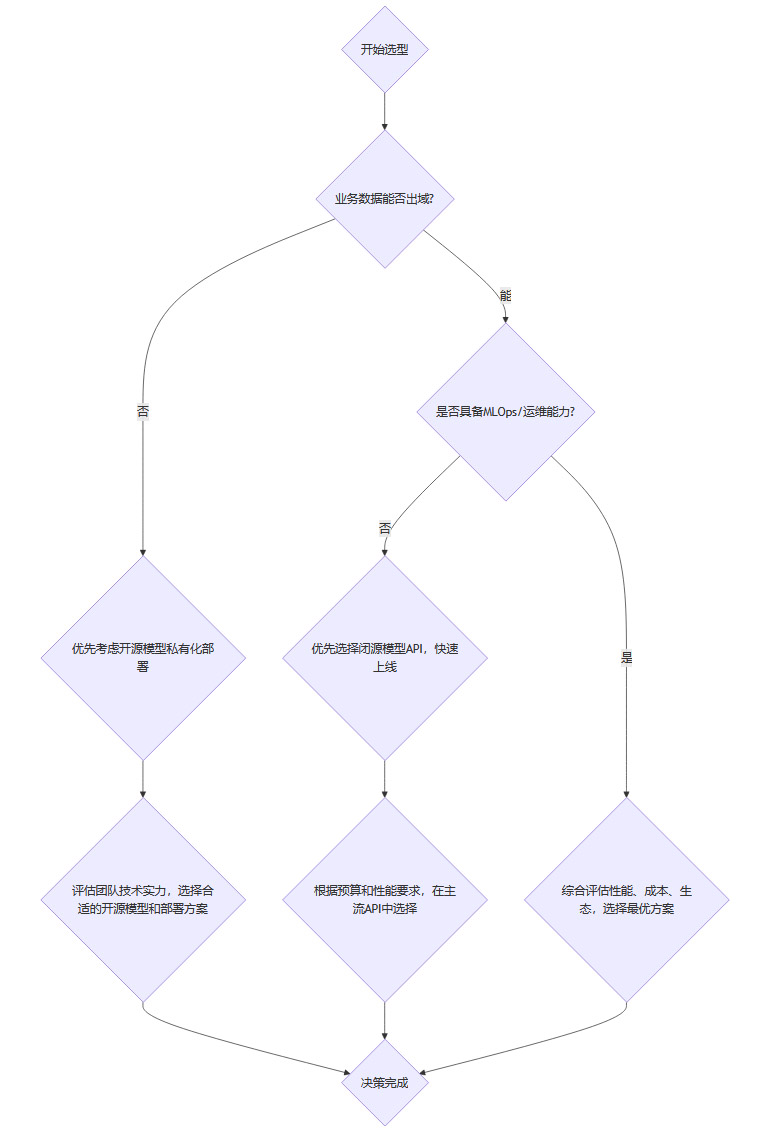
这个决策流程的核心思想是,由最刚性的约束(合规、技术能力)开始筛选,逐步缩小选择范围。
3.3 拥抱混合模型策略
顶级玩家从不做“单选题”。复杂的Agent系统,往往不是由单一模型驱动的,而是采用多模型路由的混合策略。
成本与性能的平衡 “小模型做粗活,大模型做细活”。系统可以设置一个路由层(Router),由一个快速、廉价的小模型(如
GPT-3.5-Turbo)来处理简单的、高频的请求,如意图识别、闲聊等。当识别到复杂任务时,再将请求转发给一个强大但昂贵的大模型(如GPT-4或Claude 3 Opus)来处理。能力互补 不同的模型有不同的“特长”。你可以让一个模型负责逻辑推理,另一个模型负责创意文案生成,还有一个本地部署的模型专门处理合规敏感数据。通过智能路由,将任务分配给最擅长它的模型,从而实现系统整体性能的最优化。
这种架构设计,既能保证Agent的能力上限,又能将运营成本控制在合理范围内,是未来Agent发展的主流方向。
四、🚧 常见误区与规避建议
%20拷贝-icor.jpg)
在模型选型的道路上,有一些常见的“坑”,提前了解可以帮助你少走弯路。
误区一:迷信榜单,忽视场景
表现 过分依赖MMLU、BBH等通用能力排行榜的分数来做决策。
后果 榜单上的“学霸”在你的具体业务场景中可能“水土不服”。一个代码能力登顶的模型,未必能写好营销文案。
建议 榜单仅供参考,场景化实测为王。必须建立自己的评测集,用真实的业务数据去检验模型。
误区二:只看API单价,不算综合成本
表现 在选择API时,只比较每百万Token的价格,选择最便宜的。
后果 忽略了长上下文带来的巨大工程优势。为了适配短上下文模型,投入了大量开发资源,最终的综合成本可能更高。
建议 建立总拥有成本(TCO)的视角,将开发成本、维护成本和API费用通盘考虑。
误区三:忽略安全合规,后期补课
表现 在项目初期只关注功能实现,对数据安全、隐私合规等问题掉以轻心。
后果 当产品上线或用户规模扩大后,发现合规问题,此时要进行架构改造,成本极高,甚至可能导致项目停摆。
建议 将安全与合规作为项目启动时的最高优先级。在技术选型之初就明确数据流向、加密方案、访问控制和审计策略。
总结
为AI Agent选择大模型,是一项兼具技术深度与商业智慧的战略决策。它没有一劳永逸的“标准答案”,而是一个动态匹配、持续优化的过程。
回顾全文,我们的核心建议可以归结为几点。
首先,建立框架。不要凭感觉行事,而是从性能、成本、可控、生态、安全这五个维度出发,进行系统性评估。
其次,场景驱动。脱离具体业务场景谈论模型好坏毫无意义。你的Agent是做什么的?它的核心需求是什么?这是所有选型决策的出发点。
再次,拥抱迭代。不要试图一步到位就找到“完美”模型。建议从一个简单、高性价比的模型开始,让你的Agent先跑起来。然后根据真实的业务数据和用户反馈,持续地进行测试、比较和优化。
最后,保持开放。大模型技术的发展一日千里。今天的王者,明天可能就被超越。保持对行业权威评测和开源社区的关注,灵活调整你的模型组合策略,避免被单一技术或厂商“锁定”,是保持长期竞争力的关键。
选择模型,就是选择你Agent的未来。希望本文提供的框架和思路,能帮助你做出更明智、更具前瞻性的决策。
📢💻 【省心锐评】
模型选型本质是业务、技术与成本的动态平衡艺术。别迷信“大力出奇迹”,用最合适的算力解决最核心的问题,才是长期主义。先让Agent跑起来,再用数据喂养它,让它在你的场景里进化。

评论