.png)
%20%E6%8B%B7%E8%B4%9D-iebb.jpg)

【摘要】揭示AI量化交易的技术内核。阐述从数据处理、因子构建到机器学习、深度学习、NLP及强化学习等核心模型的应用链路,最终形成一套严谨、可回溯的决策系统。
引言
金融市场本质上是一个复杂动态系统,充满了噪声与不确定性。长期以来,量化交易试图通过数学和统计模型来捕捉其中的微弱信号。随着算力与数据的爆发,人工智能技术,特别是机器学习,为这一领域带来了范式级的变革。许多人将AI量化视为一个难以理解的“黑箱”,充满了神秘色彩。
这种看法存在偏差。AI量化交易并不是“玄学魔法”,而是一条相当清晰的技术链路:数据 → 因子 → 模型(ML/DL/NLP/RL)→ 回测评估 → 实盘执行与在线优化。 这条链路的每一步都建立在坚实的计算机科学、统计学和金融工程基础之上。它用一套系统化的工程方法,将人类的投资逻辑与机器强大的计算、学习能力相结合,目标是在不确定的市场中寻找概率优势。
本文将逐一拆解这条技术链路,深入剖析每个环节的核心技术与实现逻辑。我们将看到,AI如何处理海量异构数据,如何构建有效的预测因子,以及各类模型如何在其中扮演不同角色,最终驱动交易决策的产生。
❖ 一、数据与因子库是AI量化的地基
%20拷贝-kkki.jpg)
任何智能系统的起点都是数据。在量化交易中,数据的质量、广度和深度直接决定了策略天花板的高度。原始数据本身往往是杂乱无章的,需要通过工程化的手段将其转化为模型可以理解和利用的“因子”。
1.1 市场数据来源的多样性
现代量化策略早已超越了传统的量价数据范畴,转而拥抱一个多源、异构的数据环境。这些数据源可以被粗略地划分为几个类别。
获取并清洗这些数据是第一步。这需要稳健的数据ETL(提取、转换、加载)管道,处理数据缺失、异常值、时间戳对齐等工程问题。
1.2 因子工程,从数据到特征的编码
原始数据无法直接喂给模型。因子(Factor)是连接数据和模型的桥梁。它是一个经过计算和编码的数值序列,旨在捕捉市场的某种特定规律或驱动资产价格变动的某个维度。构建因子库是量化研究中最核心、最耗时的工作。
1.2.1 常见因子类别
因子可以被归纳为几个大类,每一类都代表一种不同的投资逻辑。
价值因子 (Value) 衡量资产的估值水平。例如市盈率(PE)、市净率(PB)、市销率(PS)的倒数。逻辑是买入被低估的资产。
成长因子 (Growth) 衡量公司的成长潜力。例如营收增长率(Revenue Growth)、净利润增长率(Net Profit Growth)。逻辑是投资于高速成长的公司。
动量因子 (Momentum) 衡量资产价格在过去一段时间的趋势。例如过去N天的收益率(ROC)。逻辑是追涨杀跌,强者恒强。
质量因子 (Quality) 衡量公司的盈利能力和财务健康状况。例如净资产收益率(ROE)、资产负债率(Debt-to-Asset Ratio)。逻辑是投资于“好公司”。
情绪因子 (Sentiment) 衡量市场参与者的情绪。例如通过NLP分析新闻文本得到的情绪评分、社交媒体讨论热度、看涨/看跌期权比例。
1.2.2 因子计算流程
一个典型的因子计算流程如下。

特征构建 根据金融逻辑设计计算公式。
标准化 将不同因子的数值范围统一,便于模型处理。常用Z-Score标准化。
去极值 消除异常值对整体分布的影响,增强因子稳定性。
中性化 剥离因子中与某些宏观风格(如市值、行业)的相关性,确保得到的是纯粹的alpha信号。例如,通过对市值和行业哑变量进行回归取残差。
1.3 降维与聚类,提炼核心信息
随着因子数量的增多,因子之间可能存在高度相关性(多重共线性),并且包含大量噪声。直接使用高维稀疏的因子矩阵会影响模型的稳定性和泛化能力。因此,需要进行降维和结构分析。
主成分分析 (PCA) 一种经典的线性降维方法。它将原始的多个相关因子线性组合成少数几个不相关的主成分因子,这些主成分能最大程度地解释原始数据的方差。
因子聚类 使用K-Means等聚类算法,将相似的因子(如多个衡量估值的因子)分到一组,然后从每组中选取一个代表性因子或合成一个新的因子。
自编码器 (Autoencoder) 一种非线性的降维方法。它是一个深度学习模型,通过一个“编码器”将高维因子压缩到一个低维的“隐空间”,再通过一个“解码器”尝试从低维表示中重构原始因子。这个低维的隐空间表示就是提炼后的核心因子。
经过这一系列处理,我们得到一个干净、低相关性、信噪比高的因子矩阵。这是后续所有模型训练的地基。
❖ 二、机器学习是量化预测与风控的“基石算法”
当地基搭建完毕,机器学习模型便开始登场。它们是量化策略的“大脑”,负责从因子数据中学习规律,并做出预测。在这一阶段,监督学习和无监督学习扮演着不同但互补的角色。
2.1 监督学习,预测未来
监督学习的核心任务是学习一个从输入(因子)到输出(标签)的映射函数。在量化交易中,这个“标签”可以是未来的收益率、涨跌方向,或是某个风险指标。
2.1.1 目标标签的定义 (Labeling)
如何定义“未来”是关键。一个好的标签需要具备可预测性和可交易性。
分类标签 将未来N日的收益率划分为几个类别,如“上涨”(1)、“下跌”(-1)、“横盘”(0)。这对应一个分类问题。
回归标签 直接使用未来N日的收益率作为标签。这对应一个回归问题。
二元标签 例如,未来N日收益率是否超过某个阈值(如市场中位数),是(1)或否(0)。
2.1.2 常用模型选型
不同的模型适用于不同的场景,没有“银弹”。
线性模型 (Linear Models) 如线性回归、逻辑回归、多因子模型(Fama-French模型是其经典代表)。它们简单、可解释性强,是理解因子与收益关系的基础。但它们假设关系是线性的,难以捕捉复杂的市场动态。
决策树 (Decision Trees) 通过一系列“是/否”问题对数据进行划分。它能自然地处理非线性关系和特征交互。单个决策树容易过拟合。
集成学习 (Ensemble Learning) 这是目前因子模型中的绝对主力。它将多个弱学习器组合成一个强大的学习器,显著提升了模型的稳定性和预测精度。
随机森林 (Random Forest) 通过构建多棵决策树并对它们的预测结果进行投票或平均,来降低过拟g合风险。
梯度提升决策树 (GBDT/XGBoost/LightGBM) 采用串行方式,后一棵树主要学习前面所有树的残差,不断优化预测结果。XGBoost 和 LightGBM 因其高效的计算性能、对缺失值的良好处理以及强大的正则化功能,在各大机器学习竞赛和量化私募中被广泛应用。
2.2 无监督学习,发现隐藏结构
无监督学习不依赖于预先定义的标签,而是直接在数据中寻找模式和结构。它在量化中的应用同样广泛,主要用于市场理解和数据增强。
市场状态聚类 (Market Regime Clustering) 市场在不同时期表现出不同的行为模式,如牛市、熊市、高波动震荡、低波动趋势等。使用K-Means或高斯混合模型 (GMM) 对宏观因子或市场波动率指标进行聚类,可以识别出当前所处的市场状态(Regime)。策略可以根据不同的市场状态,动态地切换到最适合该环境的子模型。
因子压缩 如前文所述,使用PCA或自编码器对高维因子进行降维,本身就是无监督学习的应用。
股票风格分群 对所有股票的因子暴露度进行聚类,可以将股票自动划分为不同的风格组,如“大盘价值股”、“小盘成长股”、“高动量股”等。这有助于构建风格中性的投资组合或进行风格轮动策略。
❖ 三、深度学习刻画复杂非线性与长期依赖
%20拷贝-hnoy.jpg)
当线性模型和树模型遇到瓶颈时,深度学习提供了更强大的武器。它通过深层神经网络结构,能够自动学习特征的层次化表示,并捕捉数据中极其复杂的非线性关系和长期时间依赖性。
3.1 循环神经网络 (RNN),处理时间序列的利器
股票价格、交易量、资金流等都是典型的时间序列数据,其当前状态与历史状态密切相关。传统的机器学习模型通常将每个时间点视为独立样本,丢失了时序信息。RNN正是为解决这个问题而生。
长短期记忆网络 (LSTM) / 门控循环单元 (GRU)
标准的RNN存在梯度消失/爆炸问题,难以学习长期依赖。LSTM通过引入输入门、遗忘门和输出门这三个“门控”结构,精巧地控制着信息在时间步中的流动与遗忘。这使得它能够记住几百甚至上千个时间步之前的重要信息,非常适合捕捉金融市场中的长期趋势和季节性效应。GRU是LSTM的一个简化版本,参数更少,训练更快,在许多任务上表现与LSTM相当。一个典型的应用场景是,将一只股票过去60天的量价因子序列输入LSTM,模型可以学习到其中的动量、反转等模式,并输出对未来5天收益率的预测。
3.2 Transformer,自注意力机制的革命
Transformer模型最初在自然语言处理领域取得巨大成功,其核心是自注意力机制 (Self-Attention)。该机制允许模型在处理一个序列时,动态地计算序列中每个元素对其他元素的重要性权重。
与RNN必须按顺序处理数据不同,Transformer可以并行处理整个序列。这使得它在处理超长序列时效率更高,并且能够捕捉序列中任意两个位置之间的依赖关系,无论它们相距多远。
在量化交易中,Transformer的应用场景非常广阔。
多资产联合建模 可以将多只股票或多种资产(股票、期货、期权)的时间序列数据同时输入一个Transformer模型。自注意力机制可以帮助模型学习资产间的联动关系和风险传导路径。
多因子融合 对于一个给定的时间点,可以将多个因子(如价值、动量、情绪等)视为一个“句子”中的不同“单词”,输入Transformer。模型可以学习不同因子在特定市场环境下的重要性权重,实现动态的因子加权。
3.3 深度学习实现端到端建模
深度学习的一个强大之处在于其端到端 (End-to-End) 的学习能力。传统的量化流程中,因子构建和模型训练是分离的。而深度学习模型,特别是结合了CNN(用于提取局部模式)和RNN(用于处理时序关系)的混合模型,理论上可以直接从最原始的多维数据(如高频订单簿快照)中,自动学习出有效的特征表示和预测逻辑,直接输出交易信号。
这种方式减少了对人工设计因子的依赖,有可能发现人类难以察觉的复杂模式。但它也带来了模型“黑箱”化和过拟合风险的挑战,需要更严格的评估和风控体系。
❖ 四、NLP让模型“读懂”新闻、研报和情绪
金融市场的价格波动不仅由量价数据驱动,更受到信息流的深刻影响。公司公告、行业研报、财经新闻、社交媒体讨论等海量文本数据,蕴含着丰富的alpha信号。自然语言处理(NLP)技术就是解锁这些信息的钥匙。
4.1 预训练语言模型 (PLM) 的应用
近年来,以BERT (Bidirectional Encoder Representations from Transformers) 及其衍生模型(如RoBERTa, FinBERT)为代表的预训练语言模型(PLM)彻底改变了NLP领域。这些模型在海量通用语料(甚至金融专业语料)上进行了预训练,已经具备了强大的语义理解能力。
在量化中,我们可以利用这些模型进行微调 (Fine-tuning),让它们适应特定的金融任务。
文本分类 判断一篇新闻或公告对某公司的影响是正面的、负面的还是中性的。
命名实体识别 (NER) 从研报中自动抽取出公司名称、关键财务指标、分析师评级等结构化信息。
关系抽取 识别文本中实体之间的关系,如“A公司宣布收购B公司”。
4.2 构建情绪因子与事件因子
通过NLP技术,我们可以将非结构化的文本转化为量化的因子,融入到模型中。
情绪因子 对每日与某公司相关的所有新闻、社交媒体帖子进行情感打分,然后加权平均,得到一个日度的情绪分数序列。这个因子可以用于构建情绪反转策略(买入极度悲观的股票)或情绪跟随策略。
事件因子 构建一个事件知识图谱,定义一系列关键事件类型,如“高管变动”、“产品发布”、“收到监管问询”、“分析师上调评级”等。通过NLP模型自动检测文本中是否提及这些事件,并将其转化为二元的事件因子。
4.3 文本信号与价格因子的融合
文本信号的价值在于其时效性和独特性。它往往能比财务报表更早地反映公司的基本面变化。将NLP提取的情绪因子和事件因子,与传统的量价因子、基本面因子一同输入到机器学习或深度学习模型中,可以显著提升模型的预测能力,尤其是在事件驱动的行情中。
例如,一个模型可能会学到,当一只股票的“动量因子”很高,同时其“新闻情绪因子”也急剧上升时,未来上涨的概率会远高于只有单一信号的情况。
❖ 五、强化学习将预测模型变成“会行动的智能体”
%20拷贝-bvbz.jpg)
前面的模型主要解决“预测”问题,即判断未来会上涨还是下跌。但交易不仅是预测,更是决策。在什么时间点、以什么价格、买卖多少数量,这是一个复杂的序列决策问题。强化学习(Reinforcement Learning, RL)正是为解决此类问题而设计的框架。
5.1 从预测到决策的范式转变
强化学习将交易过程建模为一个智能体(Agent)与市场环境(Environment)持续互动、学习的过程。
智能体 (Agent) 就是我们的交易策略程序。
环境 (Environment) 是模拟的或真实的市场,包含价格、深度、交易成本等。
状态 (State) 智能体在每个时间点观察到的市场信息,可以是当前的因子值、持仓情况、账户资金等。
动作 (Action) 智能体根据当前状态可以执行的操作,如“买入100股”、“卖出50%仓位”、“保持不动”。
奖励 (Reward) 智能体执行一个动作后,环境反馈给它的一个标量信号,用于评价该动作的好坏。奖励函数的设计至关重要,它直接决定了智能体的学习目标。
与监督学习试图最小化预测误差不同,强化学习的目标是最大化在一个完整交易周期(Episode)内获得的累积奖励。
5.2 优化目标的升级
这种范式转变带来了优化目标的根本升级。监督学习模型通常优化的是单步预测的准确率(Accuracy)或均方误差(MSE)。而强化学习可以直接优化更贴近投资目标的长期指标。
通过精心设计奖励函数,例如 Reward = (每日收益率 - 无风险利率) - c * (最大回撤惩罚),RL智能体在学习最大化收益的同时,会内生地学会风险管理。
5.3 典型应用场景
强化学习在量化交易中的应用非常前沿,主要集中在以下几个领域。
择时与仓位控制 这是最经典的应用。智能体在每个时间点决定是全仓、半仓还是空仓,其动作空间是离散的仓位水平。
大额订单执行 对于机构投资者,一次性执行大额订单会冲击市场价格,产生高昂的交易成本。可以训练一个RL智能体,学习如何将一个大订单拆分成多个小订单,在一段时间内以最优的节奏执行完毕,以最小化市场冲击成本(VWAP/TWAP策略的智能升级版)。
多资产动态再平衡 对于一个包含多种资产(如股票、债券、商品)的投资组合,RL智能体可以学习何时以及如何调整各类资产的权重,以适应宏观经济环境的变化,实现动态的资产配置。
❖ 六、“因子库 + 历史交易数据”为大模型提供硬约束
近年来,以GPT为代表的大语言模型(LLM)展现了惊人的能力,引发了其在量化领域应用的讨论。然而,直接让LLM进行投资决策是极其危险的,因为它存在“幻觉”(Hallucination)问题,即可能一本正经地编造事实。
真正的落地应用,是让大模型扮演“助手”和“解释器”的角色,而不是“决策者”。其所有输出都必须被我们前面建立的因子库和回测框架所约束。
6.1 基于可回溯数据的硬约束
AI量化系统的严谨性体现在其可回溯性和可归因性上。
信号来源可追溯 任何一个交易信号,都必须能分解到是哪些具体的因子在起作用。例如,模型发出买入信号,我们可以分析出是因为该股票的“成长因子”得分高,还是“情绪因子”近期出现了异动。
表现归因可分析 策略盈利或亏损后,可以通过Brinson归因等方法,分析收益是来自行业选择、个股选择还是风格暴露。
这个闭环系统为大模型提供了硬约束。所有信号和解释都必须基于可查询的因子表现和回测统计数据,而非语言模型的主观臆测。
6.2 大模型的角色定位
在这样一个系统中,大模型可以承担以下辅助角色。
智能投顾与报告生成 大模型可以调用因子数据库和回测模块的API。当用户提问“为什么最近我的策略表现不佳?”时,大模型可以自动查询策略的因子暴露、持仓和近期市场风格,然后生成一段逻辑清晰、有数据支撑的分析报告:“您的策略近期在小盘成长风格上有较高暴露,而过去一周市场风格切换至大盘价值,导致了回撤。具体来看,您的重仓股XX在质量因子上的得分为...”。
自然语言策略生成 研究员可以用自然语言描述一个策略思想,如“寻找过去一个月超跌,但ROE连续三个季度增长的公司”。大模型可以将这段话解析,并翻译成调用因子库的Python代码,自动生成初步的回测结果,极大地提升了策略研究的效率。
通过这种方式,我们利用了大模型的语言能力,同时用量化体系的确定性数据,大幅度降低了幻觉风险。
❖ 七、模型评估与风险控制贯穿全流程
%20拷贝-walk.jpg)
一个在历史数据上看起来很美的策略,在实盘中可能一败涂地。这通常是由于过拟合(Overfitting)或模型未能适应市场变化。因此,一套严格、多维度的评估和风控体系是AI量化策略能够上线的生命线。
7.1 稳健性评估方法
样本外测试 (Out-of-Sample Test) 将历史数据分为训练集、验证集和测试集。模型只在训练集上学习,在验证集上调参,最终在从未“见过”的测试集上评估表现。这是检验模型泛化能力的最基本要求。
交叉验证 (Cross-Validation) 特别是对于时间序列数据,需要使用滚动窗口 (Rolling Window) 或扩展窗口 (Expanding Window) 的方式进行交叉验证,模拟真实场景中模型不断用新数据进行训练和预测的过程。
情景分析与压力测试 模拟历史上发生过的极端市场环境(如2008年金融危机、2015年市场大幅波动),测试策略在这些黑天鹅事件中的表现。
7.2 多维度绩效评估指标
评估一个策略的好坏,绝不能只看累计收益率。一个全面的评估体系应包括:
7.3 固化为代码的硬规则
除了模型自身的风险考量,策略执行层还需要嵌入一系列硬性的风控规则,作为最后的安全垫。这些规则通常由风控部门设定,并固化在交易系统中,拥有最高优先级。
止损线 单笔交易、单个头寸或整体策略净值的最大亏损限制。
仓位约束 单只股票的最大持仓比例、行业最大持仓比例、总杠杆率上限。
交易限制 禁止交易流动性过低的股票、ST股票、处于重大事件停牌期的股票。
❖ 八、在线学习与自适应优化:模型与市场共同演化
市场永远在变化,驱动价格的因子也会随时间“衰减”或“失效”。一个静态的模型无法长期生存。因此,让模型具备与市场共同演化的能力,是AI量化追求的终极目标之一。
8.1 在线学习与持续微调
传统的模型训练是离线的、批量的。而在线学习 (Online Learning) 允许模型在接收到新的数据点后,立即更新其内部参数。
在实盘中,模型每天做出预测并执行交易。收盘后,新的市场数据产生。在线学习框架可以利用这些新数据,对模型进行一次小幅度的参数微调。
这使得模型能够快速捕捉到市场短期的变化,保持对当前市场环境的敏感度。
8.2 市场状态自适应
如前所述,市场存在不同的状态(Regime)。一个高级的AI量化系统应该能够:
自动识别当前的市场状态。通过无监督学习模型,实时判断市场是处于趋势行情还是震荡行情。
动态切换或重加权子模型。系统内部可能维护着多个针对不同市场环境训练的子模型(如趋势跟踪模型、均值回归模型)。当识别到市场状态切换时,系统会自动增加适应当前环境的子模型的权重,降低其他模型的权重。
8.3 构建决策闭环
最终,一个成熟的AI量化系统应该是一个完整的、自适应的闭环。
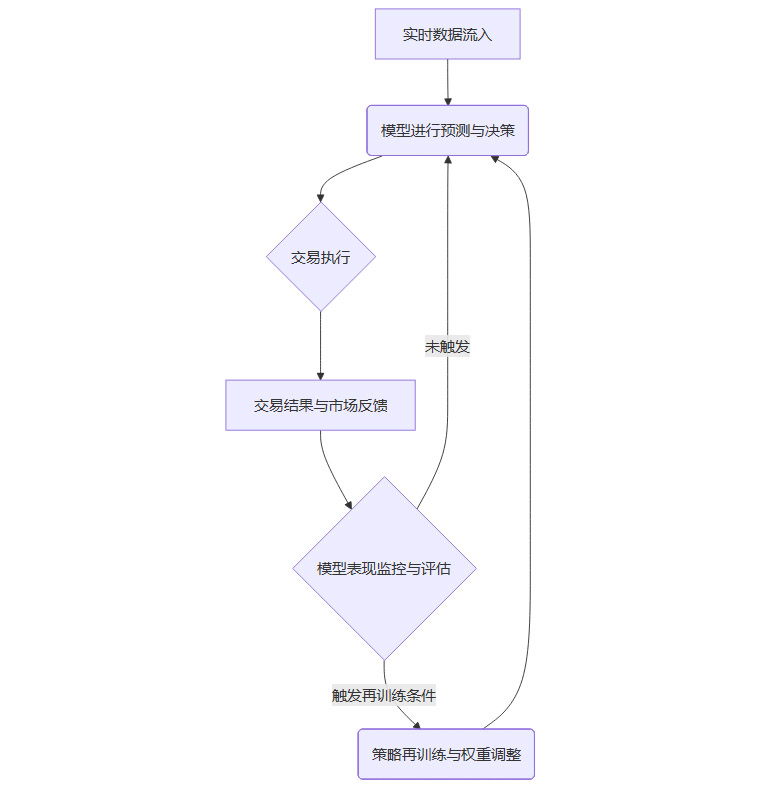
这个闭环确保了策略的持续迭代和自我优化,使其在不断变化的市场中保持生命力。
结论
AI量化交易的“黑箱”并非无法理解。当我们沿着“数据 → 因子 → 模型 → 评估 → 执行”的技术链路逐层深入,会发现其背后是一套高度工程化、逻辑严密的体系。从作为基石的机器学习,到刻画复杂关系的深度学习,再到理解文本信息的NLP和学习决策的强化学习,每一种技术都在这个体系中扮演着不可或缺的角色。
这个体系的核心,是用确定性的技术流程和可回溯的数据,去应对金融市场内在的不确定性。它不追求完美的预测,而是通过构建信息优势和模型优势,在概率和赔率上寻求长期的、可持续的微弱优势。随着技术的不断演进,这条链路将变得更加智能、更加自适应,持续重塑着现代投资的面貌。
📢💻 【省心锐评】
AI量化并非魔法,而是严谨的技术链路。它以数据为基,因子为梁,模型为核,风控为纲,通过系统化工程在市场不确定性中寻找概率优势,实现策略的持续演化。

评论