.png)
%20%E6%8B%B7%E8%B4%9D-jtaf.jpg)

【摘要】算力狂热退潮,结构性过剩显现,2026年将是智算中心生死大考,无应用支撑的项目面临淘汰。
引言
过去两年,全球科技行业经历了一场罕见的“算力饥渴”。GPU 被奉为硅基时代的“石油”,企业抢购 H100 的疯狂程度不亚于淘金热。只要手里有卡,似乎就握住了通往 AGI(通用人工智能)的门票。2022 年到 2023 年,我们看到的是不计成本的投入,是恐慌性的囤货,是“宁可买错,不可错过”的焦虑。
时间来到 2024 年底至 2025 年初,风向变了。虽然宏观数据依然显示算力需求在增长,但在微观层面,焦虑的性质已经发生了根本性逆转。从“抢不到算力”变成了“算力怎么用才划算”,甚至在部分区域出现了“算力卖不出去”的尴尬局面。微软取消部分数据中心租约、Meta 裁撤基础模型团队、腾讯收紧资本开支增速,这些信号都在指向同一个事实:行业正在从“盲目基建”进入“理性算账”阶段。
作为一个在架构领域摸爬滚打十五年的从业者,我必须指出,算力中心面临的风险并非全行业的崩盘,而是一场残酷的结构性出清。真正的危机不在于算力本身有没有用,而在于我们建设的算力形式、位置和成本结构,是否匹配 2026 年前后的真实业务需求。本文将从技术架构、资本逻辑和产业周期三个维度,深度剖析这场正在发生的“去泡沫”运动。
🛑 一、 供需温差:宏观增长下的微观寒意
%20拷贝-ebuz.jpg)
外界看算力市场,看到的是 IDC 预测的千亿规模增长;行内人看算力市场,看到的是局部过热与库存积压并存的怪象。这并非全面过剩,而是严重的结构性错配。
1.1 数据的两面性:大厂扩容与中小厂闲置
我们先看一组对比鲜明的现象。一方面,AWS、Azure、Google Cloud 依然在签署长期的电力和土地合同,甚至在探索核能供电以满足未来十年的需求。另一方面,大量在 2023 年跟风成立的“第三方智算中心”或“算力租赁公司”,现在的日子并不好过。
这种温差的根源在于算力的可用性分级。
Tier 2 级别的算力中心,往往是由跨界资本(如房地产、传统制造业)投资建设。它们仅仅完成了“买服务器”这一步,却忽略了智算中心的核心不是硬件,而是让硬件协同工作的能力。当大模型训练对网络稳定性要求极高时,这些缺乏技术积淀的算力池根本无法承接高端需求,只能沦为低端渲染或挖矿的替代品,最终导致闲置。
1.2 资本开支(Capex)的逻辑重构
过去两年,大厂的 Capex 逻辑是“占坑”。只要是 GPU,先买回来再说,利用率低一点没关系,战略威慑力要有。
现在,Capex 的逻辑变成了“ROI(投资回报率)导向”。
微软的撤退信号:微软取消部分数据中心租约,并非没钱,而是发现单纯堆砌通用数据中心无法满足 AI 的特殊需求,或者预判现有模型规模的边际效益正在递减。
腾讯的务实策略:腾讯财报明确显示资本开支增速放缓,强调每一分钱都要看到业务增长。这代表了互联网巨头从“军备竞赛”回归“商业本质”。
这种转变对上游供应链是巨大的冲击。对于那些指望大厂“无限兜底”的算力建设方来说,最大的买家突然开始挑剔了,原本激进的扩容计划瞬间变成了烫手山芋。
1.3 隐形的库存:闲置算力去哪了?
还有一个不容忽视的现象是算力的“影子库存”。在 2023 年恐慌期,许多非科技企业、科研机构甚至高校都超额采购了 GPU。
如今,这些算力并未完全转化为生产力。由于缺乏配套的算法团队和数据资源,大量 A100/H800 处于半闲置状态。这些闲置资源正在通过各种“算力中介”回流市场,进一步冲击了新建算力中心的定价体系。当市场上充斥着大量低价的、碎片化的二手算力时,新建的高成本智算中心将面临巨大的回本压力。
📉 二、 算力“中介化”:价格战的导火索
算力市场正在经历类似房地产市场的“二手房冲击”。过去你只能找英伟达或云厂商买,现在你可以找中介租,甚至可以按小时租。
2.1 算力即服务(CaaS)的泛滥
Vast.ai、Genesis Cloud 以及国内涌现的各类算力调度平台,正在将算力大宗商品化。这些平台打通了供需双方的信息壁垒,让闲置算力得以流通。
从技术角度看,这提高了资源利用率。但从商业角度看,这对重资产投入的算力中心是毁灭性打击。
价格透明化:过去算力租赁是黑盒定价,利润空间巨大。现在在聚合平台上,价格一目了然,比价效应导致价格螺旋下跌。
利润坍塌:2023 年一张 H800 的租赁价格可能高达每小时数美元,且需长租。现在,随着供应增加和中介平台的竞价,价格已大幅回落。对于那些按高位价格模型计算回报周期的投资者来说,这意味着回本遥遥无期。
2.2 二级市场的灰色流通
除了正规的租赁平台,灰色的二级市场也在暗流涌动。
我们观察到,部分因资金链断裂或项目烂尾的智算中心,开始拆机卖卡。这些流入市场的 GPU 变成了“现货”,进一步挤压了正规渠道的出货空间。
更危险的是,这种流通打破了“算力永远稀缺”的信仰。一旦市场形成“算力随时能买到,而且越来越便宜”的预期,下游客户就会推迟签约,改用短租或按需付费。这对于依赖长期合同来覆盖基建成本的算力中心来说,是致命的现金流错配。
2.3 运营能力的降维打击
在“中介化”时代,单纯拥有硬件不再是护城河。
活下来的关键变成了运营效率:
你能否将 GPU 利用率从 40% 提升到 80%?
你能否通过虚拟化技术切分算力,同时服务多个小客户?
你能否提供开箱即用的模型部署环境,降低客户门槛?
那些只会“卖裸金属服务器”的算力中心,在这一轮价格战中将毫无还手之力。它们就像是只有房子没有物业管理的烂尾楼,注定被市场抛弃。
🏗️ 三、 架构错配:训练与推理的分野
%20拷贝-mprw.jpg)
很多投资人并不懂技术,他们认为“算力就是算力”。但在架构师眼中,**训练(Training)和推理(Inference)**是两种截然不同的负载。当前的算力基建泡沫,很大程度上源于对这两种需求的误判。
3.1 训练集群的“过度设计”危机
过去两年建设的智算中心,绝大多数是奔着“大模型训练”去的。其架构特点是:
高互联带宽:配备昂贵的 InfiniBand 网络,追求极致的节点间通信速度。
高精度计算:大量采购 FP64/FP32 性能强劲的高端卡。
高能耗密度:单机柜功率极高,依赖液冷等昂贵散热方案。
然而,大模型训练的需求是金字塔尖的。全球真正有能力、有资源从头训练千亿参数大模型的公司,加起来不超过 50 家。当这 50 家公司的军备竞赛告一段落,或者市场格局固化后,剩下的海量训练算力卖给谁?
3.2 推理需求的架构不兼容
未来的海量需求在推理侧。当 AI 应用大规模落地,我们需要的是低延迟、高并发、低成本的推理算力。
用训练集群跑推理,就像开法拉利送外卖:
成本过高:InfiniBand 网络在推理场景下是严重的资源浪费。
精度溢出:推理往往只需要 FP16 甚至 INT8 精度,高端训练卡的 FP64 能力完全闲置。
灵活性差:训练集群通常是整租,而推理需求是碎片化、弹性的。
那些只盯着“万卡集群”搞大炼钢铁的算力中心,在 2026 年将面临巨大的转型困境。它们昂贵的硬件设施无法在对成本极其敏感的推理市场中竞争。
3.3 兼容性陷阱
还有一个技术细节常被忽视:CUDA 生态的锁定与解绑。
许多智算中心为了省钱或规避制裁,采购了非英伟达芯片(如某些国产加速卡)。这在训练阶段可能通过定制化开发勉强跑通,但在推理阶段,面对海量的、快速迭代的开源模型和应用,软件栈的兼容性成本极高。
如果一个算力中心无法做到“模型拿来即跑”,它就无法承接长尾市场的推理需求。这种**“软件栈烂尾”**比硬件烂尾更难解决,因为它需要持续的高级人才投入,而这正是基建型公司最缺乏的。
🧩 四、 边缘计算的逆袭:云端算力的最大变量
如果说架构错配是内部隐患,那么**端侧 AI(Edge AI)**的崛起则是外部最大的黑天鹅。
4.1 云端算力的不可持续三角
目前 AI 应用主要依赖云端处理,但这面临着“成本-延迟-隐私”的不可能三角:
带宽成本:将高清视频流实时传回云端处理,带宽费可能比算力费还贵。
延迟瓶颈:自动驾驶、工业控制等场景无法容忍几百毫秒的网络延迟。
隐私顾虑:企业和个人越来越不愿意将核心数据上传到公共云。
4.2 算力下沉的必然趋势
2025-2026 年被普遍认为是端侧 AI 的爆发期。随着高通、联发科、英特尔在 NPU 上的激进推进,手机、PC 和汽车的本地算力正在指数级增长。
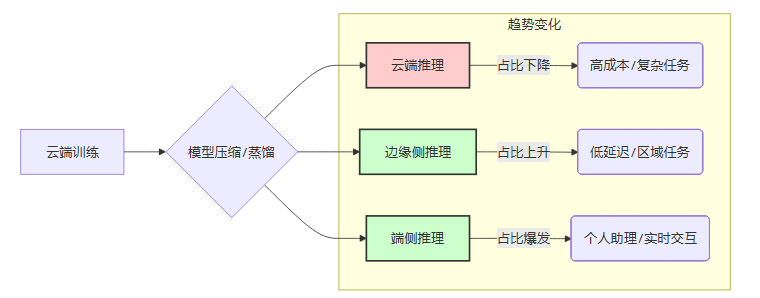
当 70 亿参数的模型可以在手机上流畅运行时,原本需要云端处理的请求将被大量拦截在本地。这意味着:
云端推理需求被分流:原本预期的云端推理增长曲线将变得平缓。
算力中心定位改变:云端将主要负责超大模型的训练和兜底推理,而海量的日常交互将发生在端侧。
4.3 对基建的冲击
如果我们在 2024 年按照“所有 AI 都在云端跑”的假设去建设算力中心,那么到 2026 年,当端侧 AI 普及,这些中心将面临利用率断崖式下跌。
特别是那些位于偏远地区、网络条件一般、主打低端推理服务的算力中心,它们既做不了高端训练,又抢不过零延迟的端侧算力,最终只能成为时代的弃子。
🦅 五、 英伟达的恐惧:从卖铲子到控矿山
%20拷贝-etuw.jpg)
春江水暖鸭先知。作为算力霸主,NVIDIA 的动作最能说明问题。黄仁勋比任何人都清楚,单纯卖硬件的生意是有周期的,而且泡沫终将破裂。
5.1 投资版图的玄机
近期 NVIDIA 疯狂投资软件、生物医药、EDA 甚至机器人公司。这不仅仅是财务投资,更是战略对冲。
软件化:通过 CUDA 和 NIM(NVIDIA Inference Microservices),英伟达试图将自己变成一个软件平台。它希望你不仅买它的卡,更离不开它的软件生态。
全栈化:从芯片到交换机(NVLink),再到服务器设计(DGX),英伟达正在吃掉整个数据中心的利润。
5.2 为什么英伟达要“控矿山”?
英伟达通过向 CoreWeave 等核心合作伙伴注资,甚至优先供货,实际上是在控制算力的分发权。它不希望算力掌握在那些不懂运营、只想倒买倒卖的投机者手中。
英伟达的恐惧在于:如果下游应用(App)赚不到钱,上游的卡就卖不动。因此,它必须亲自下场,扶持那些能产生真实商业价值的应用场景(如自动驾驶、药物研发)。
这给我们的启示是:连卖铲子的人都在担心挖不到金子,我们这些买铲子的人,如果还只盯着铲子本身(算力规模),而不去想怎么挖金子(应用落地),那就是在裸泳。
☠️ 六、 烂尾画像:哪些算力中心注定被淘汰
基于上述分析,我们可以清晰地描绘出 2026 年前后可能“烂尾”的高风险算力中心画像。如果你手中的项目符合以下特征,警钟已经敲响。
6.1 “政绩工程”型智算中心
特征:由地方主导,为了招商引资或政绩指标强行上马。选址缺乏产业支撑,本地没有 AI 企业,也没有数据源。
死因:缺乏运营能力。建成后发现没有本地客户,想做远程租赁又拼不过专业的云厂商,最终沦为参观展示厅,设备在通电空转中折旧。
6.2 “单腿走路”的定制园区
特征:深度绑定某一家大模型独角兽或单一互联网大厂,为其量身定制机房和网络。
死因:客户风险传导。AI 创业公司的死亡率极高。一旦该大客户资金链断裂或业务调整(如转投自建),园区瞬间失去 90% 的收入来源,且由于定制化程度高,很难快速改造适配新客户。
6.3 “二房东”模式的机房
特征:没有技术团队,没有云平台,没有生态服务。商业模式简单粗暴:租机柜、买服务器、加价转租。
死因:价格战牺牲品。在算力中介化和云厂商降价的双重挤压下,这类中心的利润将被压缩至负数。它们无法提供增值服务(如模型调优、数据清洗),客户粘性极低。
6.4 高能耗的“电老虎”
特征:PUE(能源使用效率)设计落后,位于电价高昂地区,未考虑液冷改造。
死因:运营成本失控。随着芯片功耗激增(Blackwell 架构功耗更高),电力成本将占到运营成本的 60% 以上。在算力价格下行周期,高昂的电费将直接击穿盈亏平衡点。
⏳ 七、 2026年:算力基建的“期末大考”
%20%E6%8B%B7%E8%B4%9D-wknq.jpg)
为什么是 2026 年?
这是一个多重周期叠加的时间节点:
交付周期:2023-2024 年疯狂立项的万卡集群,经过 2-3 年的建设,将在 2026 年集中交付。供给将达到峰值。
折旧周期:早期采购的 A100 等设备进入折旧中后期,性能开始落后,需要更新换代,资金压力倍增。
技术周期:端侧 AI 技术成熟,开始大规模分流云端负载。
商业周期:资本市场对 AI 公司的耐心耗尽,不再听 PPT 故事,要求看到正向现金流。
在这一年,市场将进行一次残酷的再定价。
通过考试的:是那些拥有稳定行业客户(如自动驾驶车队、科研机构)、具备全栈运营能力、能效控制优秀的算力中心。它们将成为真正的“新型基础设施”。
被淘汰的:是那些空有规模、没有生态、成本高企的“算力仓库”。它们将面临资产减值、重组甚至破产清算。
结论
算力不会烂尾,但错误的算力投资会。
我们正在经历的,不是 AI 时代的终结,而是 AI 基建从“野蛮生长”向“精耕细作”的转型。未来的算力中心,不再是简单的堆砌 GPU,而是需要像经营一家高科技工厂一样,精细化管理每一瓦特电力、每一毫秒延迟和每一个算力单元的产出。
对于从业者和投资者而言,现在是时候停止对“规模”的迷信,转而关注“效率”与“落地”了。毕竟,在退潮的时候,没人想成为那个被留在沙滩上的人。
📢💻 【省心锐评】
算力不是囤出来的,是用出来的。2026年不看谁卡多,看谁能把卡变成钱。别让你的机房,变成昂贵的电子废墟。

评论