.png)
%20%E6%8B%B7%E8%B4%9D-imuv.jpg)

【摘要】2025年AI从狂飙突进转向深耕细作,算力基建化、推理高效化、Agent网络化与科学融合化共同重塑产业技术栈与商业逻辑。
引言
人工智能的发展历程中,2023年和2024年是属于“大模型”的狂欢。参数规模的指数级增长、通用能力的涌现,让整个行业陷入了一种对“更大、更强”的迷信。然而,站在2025年的门槛上,风向变了。
行业不再单纯通过堆砌显卡来换取几个百分点的Benchmark提升。企业的关注点从“模型能做什么”迅速转移到“模型如何落地”、“成本如何控制”以及“系统如何闭环”。我们正在进入AI的“下半场”。
这个阶段的特征不再是单一维度的参数竞赛,而是系统工程的全面较量。算力正在从企业级IT资源演变为国家级基础设施;模型架构为了打破Transformer的效率瓶颈正在发生质变;Agent(智能体)正在重构互联网的连接方式;而AI for Science(AI4S)则让比特世界的智能开始反哺原子世界的科学发现。
这四重引擎——算力、推理、Agent、科学,构成了未来五到十年AI产业的全新底座。本文将从架构师的视角,剥离市场喧嚣,深度拆解这四大维度的技术演进与产业逻辑。
🏗️ 一、 算力基建化:从“IT设备”到“国家电网”
%20拷贝-wvmg.jpg)
在AI上半场,算力是企业争夺的稀缺物资。在下半场,算力正在经历一场类似“电力革命”的基建化重构。它不再仅仅是服务器的堆叠,而是涉及能源、网络、调度和芯片架构的复杂系统工程。
1.1 算电共生:能源定义算力边界
过去我们谈论数据中心,核心指标是PUE(电源使用效率)。现在,核心制约因素变成了“电力容量”和“能源结构”。千亿级参数模型的训练和推理,本质上是将巨大的电能转化为智能。
“算力工厂”概念的兴起,标志着超大规模数据中心(Hyperscale Data Center)的建设逻辑发生了根本转变。
选址逻辑重构:不再单纯跟随网络节点,而是跟随能源节点。“东数西算”工程的本质,就是将算力部署在可再生能源丰富的西部,通过特高压输电和光纤网络,实现“瓦特”与“比特”的跨区域置换。
能源协同:数据中心不再是电网的被动负载,而是具备调节能力的“虚拟电厂”。通过AI预测负载波动,数据中心可以与电网进行源网荷储互动,实现“以电促算、以算强电”。
表 1:传统数据中心 vs 智算中心(AIDC)的特征对比
1.2 芯片AI化:架构的“去通用化”革命
通用GPU(GPGPU)统治了AI的上半场。但在下半场,随着推理需求的爆发和模型架构的固化,通用性带来的效率损耗变得不可接受。芯片产业正在经历从“通用算力”向“AI原生算力”的范式转移。
1.2.1 异构计算的崛起
GPU的主导地位正在受到挑战。NPU(神经网络处理器)、ASIC(专用集成电路)和FPGA正在瓜分特定场景的市场份额。
训练端:GPU依然是王者,但为了追求极致的互联带宽和显存容量,晶圆级封装(Wafer-Scale)和HBM(高带宽内存)堆叠成为技术制高点。
推理端:ASIC因其极致的能效比(TOPS/W)正在边缘侧和端侧迅速普及。对于确定的模型结构(如Transformer),专用电路比通用指令集效率高出数个数量级。
1.2.2 全栈国产化的“深水区”
中国AI芯片的发展已经过了“做出来”的阶段,现在进入了“用起来”的深水区。单纯的硬件参数对标(如FP16算力)已无意义,真正的护城河在于软件栈。
“芯片 + SDK + 框架”的垂直整合是国产算力破局的唯一路径。
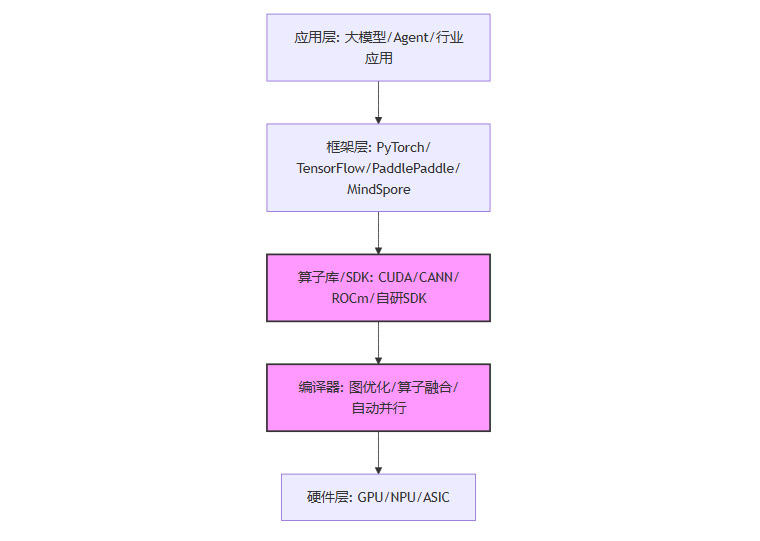
graph TD
A[应用层: 大模型/Agent/行业应用] --> B[框架层: PyTorch/TensorFlow/PaddlePaddle/MindSpore]
B --> C[算子库/SDK: CUDA/CANN/ROCm/自研SDK]
C --> D[编译器: 图优化/算子融合/自动并行]
D --> E[硬件层: GPU/NPU/ASIC]
style C fill:#f9f,stroke:#333,stroke-width:2px
style D fill:#f9f,stroke:#333,stroke-width:2px
上图展示了算力栈的关键环节。国产化的难点主要集中在C(算子库)和D(编译器)。目前,国产方案已在千亿级模型训练中完成了实战验证,通过算子级的深度优化和异构集群的调度适配,逐步实现了从“可用”到“好用”的跨越。
1.3 算力网络的调度难题
当算力成为基础设施,如何像调度水电一样调度算力,是“全国一体化算力网络”面临的最大技术挑战。
这不仅仅是网络带宽的问题,更是异构算力统一抽象的问题。不同厂商的芯片(NVIDIA, 华为, 寒武纪, 海光等)指令集不同、显存管理机制不同。构建一个能够屏蔽底层硬件差异、实现跨广域网任务切分与调度的“算力操作系统”,是2025年基础设施领域的攻坚重点。
🚀 二、 模型与架构进化:效率革命与“推理时间”
如果说上半场是“参数竞赛”,下半场就是“效率为王”。模型架构的演进不再盲目追求参数量,而是聚焦于如何在有限的算力预算下,实现更强的推理能力和更长的上下文窗口。
2.1 架构突围:打破Transformer的枷锁
Transformer架构统治了NLP领域多年,但其自注意力机制(Self-Attention)的 O(n2)O(n2) 计算复杂度,在处理超长文本时成为了巨大的资源黑洞。
2.1.1 线性注意力(Linear Attention)
为了解决长程依赖问题,线性注意力机制成为研究热点。通过核函数技巧或RNN式的状态传递,将复杂度降低到 O(n)O(n)。
技术价值:这意味着推理成本不再随上下文长度呈指数级增长,而是线性增长。这对于RAG(检索增强生成)、长文档分析和代码库理解至关重要。
落地现状:Moonshot AI的Kimi Linear架构、蚂蚁集团的Ring-flash-linear等方案,已经证明了线性Attention在保持性能的同时,能大幅降低显存占用和推理延迟。
2.1.2 MoE(混合专家模型)的主流化
MoE架构通过“大参数、小激活”的设计,完美解决了模型容量与推理成本的矛盾。
原理:将模型拆分为多个“专家(Expert)”,每次推理仅激活其中一小部分(例如总参数1000B,每次仅激活10B)。
优势:
训练快:并行度高,收敛速度快。
推理省:计算量(FLOPs)远小于同等参数规模的稠密模型。
上限高:可以通过增加专家数量无限扩展知识容量,而不显著增加推理延迟。
2025年,MoE已成为大模型的标配。DeepSeek、GPT-4等前沿模型均采用了MoE架构。未来的竞争点在于**路由算法(Routing Algorithm)**的优化,即如何更精准地将任务分发给最合适的专家,以及如何解决专家负载不均衡的问题。
2.2 推理时间的到来:OpEx > CapEx
随着大模型应用的大规模铺开,企业的成本结构发生了翻转:推理成本(OpEx)逐渐超过训练成本(CapEx)。
“推理时间”(Inference Time)不仅仅指模型运行的时间,更是一个产业阶段的代名词。在这个阶段,真正的竞争力在于:同等精度下,谁更便宜、谁更快。
2.2.1 投机采样与KV Cache优化
为了加速推理,业界发展出了一系列工程化手段:
投机采样(Speculative Decoding):用一个小模型快速生成草稿,大模型进行验证。如果草稿正确,则跳过大模型计算。这种“大小模型协同”的方式可以成倍提升推理速度。
KV Cache压缩:长文本推理中,KV Cache占用大量显存。通过PagedAttention(类似操作系统的虚拟内存分页)和量化技术(4bit/8bit KV Cache),可以显著提升吞吐量。
2.2.2 端侧推理与“云边端”协同
并不是所有任务都需要云端千亿模型处理。80%的日常任务(如语音交互、简单摘要、日程管理)完全可以在端侧完成。
端侧AI:手机、PC、汽车正在集成高性能NPU。例如,高通和联发科的新一代芯片,已能支持端侧运行10B-30B参数的模型。
混合AI架构:
端侧:处理敏感数据、实时性要求高、计算量小的任务。
边缘侧:处理区域性数据聚合与初步推理。
云端:处理复杂逻辑、长程推理和兜底服务。
这种分层架构不仅降低了云端算力压力,更解决了隐私和延迟问题,是AI规模化落地的必经之路。
2.3 硬件觉醒:模型与芯片的协同设计
RockAI CEO刘凡平提出的“硬件觉醒”观点非常犀利。未来的模型不应是被动适应硬件,硬件也不应只是通用的计算容器。
Co-design(软硬协同设计)将成为常态。
模型设计者需要了解硬件的内存带宽、缓存层级和互联拓扑,设计出对硬件友好的架构(如减少非连续内存访问)。
芯片设计者需要针对主流算子(如Softmax, LayerNorm)进行指令集优化,甚至在硬件层面实现稀疏计算加速。
🕸️ 三、 Agent 织网:重塑互联网的流量与交互
%20拷贝-blps.jpg)
如果说大模型是“大脑”,那么Agent(智能体)就是具备手脚和感官的“完整的人”。2025年,互联网正在从“内容互联网”向“Agentic互联网”演进。
3.1 交互范式革命:从“人找服务”到“服务找人”
在PC和移动互联网时代,我们的交互逻辑是指令式的:打开App -> 点击按钮 -> 获取服务。
在Agent时代,交互逻辑变成了意图式的:告诉Agent目标 -> Agent拆解任务 -> Agent调用工具 -> 交付结果。
这种转变对现有的互联网生态是毁灭性的打击,也是巨大的机遇。
入口消失:用户不再需要打开美团、携程、滴滴,只需要告诉个人Agent“帮我安排一次去上海的差旅”。App变成了Agent调用的API接口。
超级连接器:Agent成为了新的操作系统。它向下连接各种模型和工具,向上连接用户意图。
3.2 Agent Infra:AI时代的操作系统
为了支撑数以亿计的Agent运行,我们需要全新的基础设施——Agent Infra。
这套基础设施需要解决以下核心问题:
记忆管理:Agent需要长短期记忆(Long-term/Short-term Memory),记住用户的偏好、历史交互和上下文。向量数据库(Vector DB)在这里扮演了海马体的角色。
工具注册与发现:成千上万的API如何被Agent理解和调用?需要标准化的工具描述语言和注册中心。
规划与反思:Agent需要具备CoT(思维链)能力,能够自我规划任务路径,并在执行失败时进行反思和修正。
表 2:传统OS vs Agent OS
3.3 具身智能:物理AI的觉醒
Agent不仅存在于数字世界,正在通过具身智能(Embodied AI)进入物理世界。2025年是“信息AI应用期”与“物理AI研发期”的交汇点。
3.3.1 世界模型与VLA
机器人要像人一样行动,必须先像人一样理解物理规律。
世界模型(World Model):让AI在脑海中推演“如果我做一个动作,世界会发生什么变化”。这解决了机器人训练数据稀缺和试错成本高的问题。
VLA(Vision-Language-Action):将视觉感知、语言理解和动作控制统一在一个大模型中。Google的RT-2、自变量机器人的Great Wall模型,都是这一路径的探索者。
3.3.2 端到端控制
传统的机器人控制栈是分层的:感知 -> 规划 -> 控制。每一层都有信息损耗。
现在的趋势是端到端(End-to-End):直接从传感器输入(像素)映射到电机输出(力矩)。这种方式虽然训练难度大,但能涌现出传统控制算法无法实现的灵巧操作和泛化能力。
🔬 四、 科学跃迁:AI4S 成为科研新基建
如果说生成式AI改变了内容生产(AIGC),那么AI for Science(AI4S)正在重塑科学发现的底层逻辑。这不仅仅是工具的升级,而是科研范式的转移——从“实验归纳+理论推演”的传统范式,迈向“数据驱动+AI生成”的第五范式。
4.1 突破“维度灾难”:AI 求解薛定谔方程
在微观世界,量子力学支配着原子和分子的行为。理论上,只要解出薛定谔方程,我们就能预测任何材料的性质。但现实是,随着粒子数量增加,计算复杂度呈指数级爆炸(维度灾难),传统超算也无能为力。
AI4S 的核心突破在于,利用深度神经网络(DNN)强大的高维函数拟合能力,绕过复杂的解析求解,直接预测微观系统的波函数或能量面。
材料科学:AI可以快速筛选数亿种晶体结构,预测其稳定性、导电性和催化活性。例如,DeepMind的GNoME模型发现了220万种新晶体结构,相当于人类过去800年发现总量的45倍。
生命科学:AlphaFold 3不仅能预测蛋白质结构,还能预测蛋白质与DNA、RNA、小分子的相互作用。这标志着生物学从“描述性科学”转变为“预测性科学”。
4.2 闭环自动化:AI 科学家的雏形
AI4S 不止于计算,更在于实验闭环。未来的实验室将是“无人化”的。
AI 科学家(AI Scientist) 的工作流如下:
阅读文献:LLM(大语言模型)阅读海量论文,提取知识,生成假设。
设计实验:根据假设,规划合成路径和表征方案。
驱动设备:控制自动化合成工作站(机器人化学家)执行实验。
分析数据:实时分析实验结果,反馈修正假设,进入下一轮迭代。
这种“干湿闭环”(干实验:计算模拟;湿实验:真实实验)将科研迭代的周期从“年/月”压缩到“天/小时”。清华大学张亚勤院士提到的“原子、分子和比特的融合”,正是这一趋势的精准概括。
🌏 五、 中国路线:从跟随者到生态定义者
%20拷贝-ycbk.jpg)
在AI的上半场,中国企业更多是在追赶硅谷的步伐。但在下半场,凭借独特的场景优势、数据红利和举国体制的基建能力,一条清晰的“中国路线”正在浮现。
5.1 开源生态的“中国时间”
2024-2025年,中国开源模型在全球社区的表现令人瞩目。DeepSeek、Qwen(通义千问)、Yi(零一万物)等模型在Hugging Face排行榜上频频霸榜。
这背后的逻辑发生了变化:
不再盲目对标:中国团队不再单纯复刻LLaMA的架构,而是针对中文语境、长文本、代码能力进行深度优化。
全栈自主:从底层的深度学习框架(PaddlePaddle, MindSpore)到上层的微调工具(LLaMA-Factory),中国开发者正在构建一套独立于PyTorch/TensorFlow之外的备选生态。
5.2 产业链的垂直整合
与美国“设计与制造分离”的模式不同,中国正在走一条“垂直整合”的道路。
华为模式:昇腾芯片 + MindSpore框架 + 盘古大模型 + 行业解决方案。这种全栈打通的能力,在政务、金融、能源等对安全可控要求极高的领域具有不可替代的优势。
应用驱动:中国拥有全球最丰富的应用场景。从智能座舱到工业质检,从电商推荐到即时物流,庞大的数据反馈闭环正在反哺底层模型的迭代。
5.3 战略定力:AGI 与安全并重
在国家层面,AGI(通用人工智能)已被置于战略核心。但与西方的“加速主义”不同,中国路线更强调发展与安全的平衡。
可控性:强调算法的可解释性、价值观对齐和内容安全。
普惠性:通过算力网络和公共服务平台,降低中小企业使用AI的门槛,避免技术鸿沟。
🏁 结论:AI 下半场的竞争本质
站在2025年回望,我们会发现,AI上半场是一场关于“想象力”的狂欢,而下半场则是一场关于“执行力”的急行军。
竞争的本质已经改变:
从单点技术到系统工程:不再是比拼谁的模型参数大,而是比拼谁能把算力、模型、数据、应用串联成高效运转的机器。
从虚拟世界到物理世界:AI不再满足于生成文本和图片,它要控制机械臂拧紧螺丝,要设计出新型电池材料,要像水电一样流淌进千家万户。
从通用泛化到垂直深耕:通用的基座模型将成为少数巨头的游戏,绝大多数企业的机会在于利用行业数据和Agent架构,构建垂直领域的“超级专家”。
对于技术从业者而言,这是一个最好的时代,也是最坏的时代。好的是,工具箱从未如此丰富;坏的是,技术栈的半衰期从未如此短暂。
唯有拥抱变化,深入理解算力底座的重构、模型架构的演进、Agent网络的编织以及科学范式的跃迁,我们才能在这场智能革命的下半场中,找到属于自己的生态位。
📢💻 【省心锐评】
上半场拼参数,下半场拼落地。算力是粮草,模型是兵法,Agent是先锋。谁能把AI做成水电般便宜好用,谁就是下一个时代的“国家电网”。

评论