.png)
%20%E6%8B%B7%E8%B4%9D-lqot.jpg)

【摘要】AI技术栈正面临每季度一次的强制重构,模型漂移与架构拼凑是核心诱因。企业需摒弃单体思维,通过分层模块化与工程化治理,将颠覆性重构转化为可控的滚动升级。
引言
在传统企业IT架构中,ERP或CRM系统的核心技术栈通常拥有5到10年的稳定生命周期。CIO们习惯了漫长的选型、数年的部署以及随后的长期维护。然而,生成式AI的爆发彻底粉碎了这一时间表。
当前,企业技术团队正面临一个前所未有的困境:技术栈的腐坏速度超过了构建速度。当你还在调试基于上个季度SOTA(State of the Art)模型的RAG(检索增强生成)系统时,新的模型架构、更高效的推理引擎或全新的Agent编排框架已经让你的方案显得笨重且昂贵。
数据显示,超过70%的受监管企业每90天就会对AI基础设施进行一次伤筋动骨的重构。这并非敏捷开发的常态,而是技术债爆发的信号。这种高频的“拆毁重建”不仅消耗了巨大的工程资源,更严重打击了业务侧对AI落地的信心。本文将深入剖析这一现象背后的技术根源,并从架构设计、工程实践与治理体系三个维度,探讨企业如何建立一套能够适应“季度性迭代”的稳态系统。
一、 🌪️ 现状解析:为何AI技术栈陷入“季度性抛弃”怪圈?
%20拷贝-zdql.jpg)
AI领域的摩尔定律似乎正在以周为单位生效。对于企业架构师而言,这种速度带来的不是红利,而是巨大的维护负担。我们观察到,导致技术栈频繁重构的根本原因,并非单纯是“新工具更好”,而是现有架构在应对变化时的极度脆弱。
1.1 90天周期的残酷现实
根据Cleanlab及多家技术咨询机构的调研,企业AI技术栈的平均“保质期”已缩短至3至6个月。这意味着一个在Q1立项、Q2开发的系统,可能在Q3上线前就需要更换核心组件。
这种重构并非简单的版本升级(如Java 17升级到21),而是组件级的替换:
模型层:从闭源API(如GPT-4)切换到开源私有化部署(如Llama 3、DeepSeek),或反之。
数据层:从单纯的向量数据库迁移到支持混合检索(Hybrid Search)的图数据库。
编排层:从早期的LangChain硬编码链条,转向LangGraph或AutoGen等状态机驱动的Agent框架。
这种剧烈变动导致了资源的巨大浪费。工程师们陷入了“学习新框架 -> 重写代码 -> 测试 -> 框架过时 -> 再次重写”的死循环中,无法沉淀核心业务逻辑。
1.2 从“拼凑”到“负债”:早期架构的必然崩塌
回顾过去两年的企业AI实践,绝大多数项目始于“演示驱动开发”(Demo Driven Development)。为了快速向管理层展示AI的神奇能力,技术团队往往采用拼凑式架构(Patchwork Architecture)。
拼凑式架构的典型特征:
这种架构在POC(概念验证)阶段表现尚可,一旦进入生产环境,面对高并发、长上下文和复杂指令时,其脆弱性暴露无遗。为了修复一个小的Bug(例如模型输出格式错误),往往需要修改整条调用链路,最终导致团队决定“不如推倒重来”。
1.3 模型漂移:非确定性系统的维护噩梦
传统软件工程建立在“确定性”基础之上:输入A必然得到输出B。如果逻辑变了,那是代码变了。但在AI系统中,逻辑包含在模型的权重里。
模型漂移(Model Drift) 是迫使技术栈重构的隐形杀手。
版本更新带来的行为改变:即使是同一供应商的模型,版本迭代(如从0613版到1106版)也会导致指令遵循能力的微小差异。原本能完美解析的JSON格式,新版本可能多输出了一段“Here is your JSON”的前缀,导致下游解析器崩溃。
微调后的灾难性遗忘:企业为了特定任务微调模型,却发现模型在通用推理或安全防护上的能力下降,迫使团队引入额外的防护组件或回退模型,引发架构调整。
由于缺乏对这种“概率性行为”的管控机制,企业只能通过不断修改外围代码来适配模型,当补丁打得足够多时,系统便无法维护,重构成为唯一出路。
二、 📉 智能体落地真相:概念火热与生产极寒
在技术栈频繁震荡的背景下,被寄予厚望的“AI智能体(AI Agents)”在企业中的实际表现如何?数据揭示了一个冰冷的现实:研发热度与落地成果之间存在巨大的剪刀差。
2.1 1%的存活率:POC到Production的死亡谷
尽管市场充斥着“智能体将替代员工”的言论,但调研显示,真正部署在生产环境且产生业务价值的智能体项目,在企业中占比仅约为1%至5%。绝大多数项目死于POC阶段,或被无限期搁置在实验室中。
智能体落地的“死亡谷”成因分析:
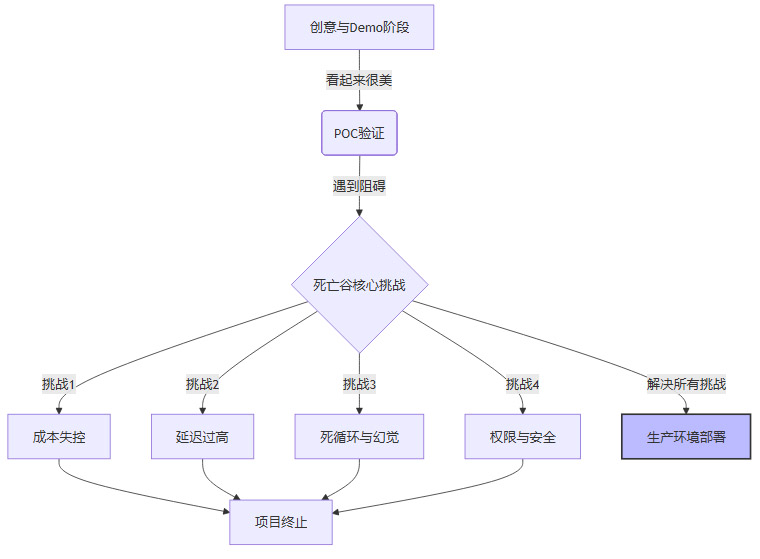
成本失控:在Demo中运行一次任务消耗0.1美元似乎可以接受,但在生产环境中,当智能体陷入思维链(Chain of Thought)的死循环,或为了追求准确率进行数十次反思(Reflection)时,Token消耗呈指数级增长。
不可控的交互:Demo中的智能体总是表现得乖巧听话,但在真实业务场景中,面对用户的模糊指令或对抗性攻击,智能体容易产生幻觉或执行越权操作。
2.2 满意度危机:基础设施的全面缺失
企业对现有AI技术栈的不满,很大程度上源于基础设施的滞后。目前的工具链大多面向“构建者”而非“运营者”。
可观测性黑洞:当智能体执行出错时,工程师很难复现。传统的APM(应用性能监控)工具无法展示智能体的“思考过程”。缺乏专门的Trace工具(如LangSmith、Arize等)的深度集成,导致调试极其困难。
编排工具的碎片化:市面上的编排框架(Orchestration Frameworks)层出不穷,但缺乏统一标准。企业今天选择了A框架,明天发现B框架对多智能体协作支持更好,于是又陷入了迁移的痛苦中。
2.3 信任赤字:为何企业不敢放手
只有28%的受访者对现有的智能体安全措施感到满意。这反映了企业对AI的信任赤字。
在受监管行业(金融、医疗),“可解释性”和“合规性”是红线。目前的端到端大模型方案往往是一个黑盒,企业无法解释为何智能体拒绝了某笔贷款申请,也无法保证智能体不会在无意中泄露敏感数据。为了解决这些问题,企业不得不不断在技术栈中增加“人机回环(Human-in-the-loop)”组件、敏感词过滤网关和合规审计日志,这些补丁式的修改进一步加剧了架构的不稳定性。
三、 🏗️ 架构重塑:分层与模块化的工程解法
%20拷贝-snkw.jpg)
要打破“每90天重构一次”的魔咒,企业必须从根本上改变AI系统的构建方式。核心思路是从单体应用(Monolithic) 转向分层模块化(Layered Modular) 架构。
这种架构的目标是:当某一层技术发生革命性变化时,其影响范围被限制在该层内部,而不会波及整个系统。
3.1 拒绝单体:五层架构设计详解
一个健壮的企业级AI技术栈应包含以下五个解耦的层级:
3.2 接口契约:如何隔离模型变动
在上述架构中,L3 模型网关层是防止重构风暴的防波堤。
错误做法:
业务代码直接import openai 库,并在业务逻辑中处理 response.choices[0].message.content。一旦更换为Claude或本地Llama,所有业务代码都需要修改。
正确做法:
定义企业内部的统一模型契约(Model Contract)。无论底层是GPT-4还是DeepSeek-R1,网关层都将其输出标准化为统一的内部格式。
json:
// 企业内部统一响应格式示例
{
"trace_id": "evt_123456",
"content": "...",
"tool_calls": [...],
"usage": { "input": 50, "output": 100 },
"metadata": { "model_version": "gpt-4-turbo-2024-04-09", "latency_ms": 450 }
}
通过这种适配器模式,当企业决定将底层模型从闭源切换到开源时,只需在网关层修改配置和适配逻辑,上层的智能体编排层和业务应用层感知不到任何变化。这使得“更换模型”从一个工程浩大的重构项目,变成了一个配置变更操作。
3.3 平台化演进:从孤岛到中台
为了避免每个部门重复造轮子,导致技术栈碎片化,企业需要将AI能力中台化。
统一的Prompt注册中心:不要将Prompt写在代码里。建立一个Prompt管理平台,允许非技术人员(如产品经理、提示词工程师)在平台上版本化地管理Prompt。代码只通过ID引用Prompt。这样,当模型升级需要调整Prompt时,无需重新部署代码。
工具(Tools)标准化:智能体使用的工具(如“查询库存”、“重置密码”)应封装为标准的API接口,并注册在统一的服务目录中。不同的智能体可以复用这些工具,而不是每个项目组自己写一套数据库连接代码。
通过将通用能力下沉为平台服务,业务应用变得更加轻量级。即使底层的RAG检索算法从“关键词匹配”升级为“多路召回+重排序”,也只需要升级中台服务,而不需要重构几百个业务应用。
四、 ⚙️ 工程进化:用DevOps驯服不确定性
架构的分层只是解决了静态的结构问题,要应对动态的“90天迭代周期”,企业必须引入适应AI特性的工程实践。传统的DevOps需要进化为LLMOps(大模型运维),将“重构”转化为平滑的“滚动升级”。
4.1 版本控制的颗粒度革命
在传统软件开发中,版本控制的对象主要是代码(Code)。但在AI工程中,代码只是系统行为的一小部分。一个AI应用的运行结果取决于三个变量的组合:
$System Behavior=f(Code,Model Weights,Prompts/Config)System Behavior=f(Code,Model Weights,Prompts/Config)$
任何一个变量的改变都可能导致系统行为漂移。因此,企业必须建立全链路版本控制体系:
Prompt版本化:像管理代码一样管理提示词。每一次Prompt的微调都应有Git提交记录,并关联到具体的评测结果。
数据快照:RAG系统的检索效果高度依赖知识库状态。在进行重大升级前,必须对向量数据库进行快照,以便在效果倒退时能快速回滚。
配置即代码(Configuration as Code):将模型的超参数(Temperature, Top-P)、路由规则等全部配置化,并纳入版本库管理。
实践建议:使用MLflow或Weights & Biases等工具,将每一次实验的“代码+模型版本+Prompt+数据版本”打包为一个不可变的Artifact(制品)。当生产环境出现问题时,可以精确地还原出当时的运行状态进行调试。
4.2 自动化测试:构建AI的“防退化护盾”
“不敢升级”是很多团队面临的窘境。因为缺乏测试手段,没人知道换了新模型后,原来的功能会不会挂掉。解决这一问题的唯一途径是建立自动化评估流水线(Evaluation Pipeline)。
这不仅仅是单元测试,而是针对AI特性的行为测试:
黄金数据集(Golden Dataset):构建包含数百个典型业务场景(包括正常查询、边界条件、恶意攻击)的测试集,并标注标准答案(Ground Truth)。
LLM-as-a-Judge:利用高智力模型(如GPT-4)作为裁判,自动评估待测模型在测试集上的表现。评估维度包括:准确性、相关性、安全性、格式合规性等。
回归测试门禁:在CI/CD流水线中设置门禁。例如,“新版本的意图识别准确率不得低于95%,且响应延迟不得增加超过10%”。只有通过测试的版本才能自动发布到生产环境。
通过这套机制,企业可以将“每季度重构”的风险降至最低。即使底层模型频繁更换,只要通过了评估流水线,就能保证业务体验的连续性。
4.3 灰度发布与AB测试
鉴于AI行为的不可预测性,全量发布是极度危险的。企业应全面采用灰度发布策略:
影子模式(Shadow Mode):新版本的智能体在后台与旧版本并行运行,处理相同的流量,但不向用户返回结果。系统记录并对比两者的输出差异。只有当新版本的表现稳定优于旧版本时,才考虑切换。
金丝雀发布(Canary Release):先将1%的流量切给新模型,密切监控错误率和用户反馈。如果发现“幻觉”激增,立即自动回滚。
这种渐进式的发布策略,使得技术栈的迭代变成了一个连续、可控的过程,而不是非黑即白的冒险。
五、 🛡️ 治理前置:安全是演进的基石
%20拷贝-ydzc.jpg)
在“拼凑式”架构中,安全往往是最后考虑的补丁。但在高频迭代的AI时代,安全必须左移(Shift Left)。如果缺乏统一的治理框架,每一次技术栈更新都可能撕开新的安全漏洞。
5.1 统一的防护栏(Guardrails)
不要指望模型本身是安全的。企业应在L5治理层建立独立于模型的防护栏系统。
输入过滤:在Prompt进入模型前,检测并拦截Prompt Injection(提示词注入)攻击、PII(个人敏感信息)泄露风险。
输出审查:在模型响应返回给用户前,实时检测是否包含有害内容、竞争对手提及或幻觉信息。
目前,开源社区如NVIDIA的NeMo Guardrails或微软的Guidance提供了很好的框架。将这些防护逻辑从业务代码中剥离出来,统一配置。这样,无论底层换成什么模型,企业的安全基线始终由这套防护栏守卫。
5.2 审计与合规的可追溯性
为了应对监管要求,企业必须建立全量的AI审计日志。这不仅包括“用户问了什么,AI答了什么”,还应包括:
AI调用了哪些工具?(例如:查询了数据库,修改了配置)
决策依据是什么?(例如:RAG检索到了哪几篇文档)
当时的系统上下文是什么?
这些日志应存储在不可篡改的存储介质中。当发生纠纷或合规检查时,企业能拿出确凿的证据链。更重要的是,这些真实数据是下一轮模型微调(Fine-tuning)的宝贵燃料。
六、 🎯 业务契约:精确定义“AI做什么”
技术栈的动荡,有时源于业务需求的不清晰。如果业务方只给出一句“用AI提升客服效率”,技术团队只能不断试错。
6.1 从“万能助手”到“单一职责”
Cleanlab的CEO Curtis Northcutt建议,在部署前必须经历一个严格的定义过程。与其试图构建一个全知全能的“超级智能体”,不如构建一组专精的、原子化的智能体。
智能体A:专门负责重置密码,拥有极高的权限但极窄的知识域。
智能体B:专门负责解答产品咨询,只读权限,连接知识库。
这种微服务化(Microservices) 的智能体设计,降低了单个智能体的复杂度。当需要重构“产品咨询”模块时,不会影响到“重置密码”模块的稳定性。
6.2 设定明确的SLA与边界
业务与技术团队应签署明确的AI服务等级协议(SLA):
成功标准:什么叫“处理成功”?是用户没有转人工,还是用户点了赞?
交接边界:在什么情况下,AI必须立即停止尝试,转交给人工坐席?(例如:连续两次无法理解用户意图,或检测到用户情绪愤怒)。
明确的边界减少了对模型“智能涌现”的过度依赖。当规则足够清晰时,即使底层模型变笨了一点,兜底逻辑也能保证业务不崩盘。
结论
AI技术栈的“90天重构周期”既是挑战,也是常态。在未来3到5年内,随着大模型技术的持续爆发,这种高频迭代不会停止。
企业不应幻想等待一个“完美且稳定”的技术栈出现,而应主动拥抱变化。通过分层解耦的架构设计,我们将变动的成本限制在局部;通过LLMOps的工程实践,我们让变化的过程可控可见;通过前置的安全治理,我们为变化守住底线。
最终,企业的核心竞争力将不再是“接入了哪个最强模型”,而是拥有一套能够快速吸纳新技术、同时保持业务连续性的演进能力。在这场风暴中,能活下来的不是最强壮的,而是适应性最强的。
📢💻 【省心锐评】
别指望AI技术栈能像ERP那样“传家”,拥抱变化才是生存之道。用工程化的笼子关住狂奔的模型,让技术迭代服务于业务,而不是被技术牵着鼻子走。

评论