.png)


【摘要】腾讯发布的AudioGenie系统,以其创新的“无训练双层多智能体”架构,为多模态到多音频(MM2MA)生成领域带来了范式级革命。本文将深度剖析AudioGenie的核心技术原理,从其精巧的任务分解、自适应混合专家协作,到严谨的监督反馈机制,揭示其如何绕开传统模型对海量配对数据的依赖。同时,我们将探讨其配套基准数据集MA-Bench的构建理念与行业价值,并结合详尽的性能评测与应用场景分析,前瞻AudioGenie对游戏、影视乃至整个AIGC生态可能产生的深远影响,及其在全球AI技术竞争格局中的战略意义。
引言
在人工智能生成内容(AIGC)的浪潮之巅,我们见证了文字的奇思妙想,目睹了图像的绚烂多彩,甚至开始惊叹于视频的栩栩如生。从GPT系列模型对自然语言的精妙驾驭,到Midjourney、Stable Diffusion对视觉艺术的颠覆性重构,再到Sora对动态世界的初步模拟,多模态AI的每一次跃迁,都在重塑着人类与数字世界的交互边界。然而,在这场感官盛宴中,一个至关重要的维度——听觉,其智能化生成的进程似乎总是步履稍显蹒跚。
声音,是情感的载体,是氛围的催化剂,是叙事的灵魂。一个寂静无声的视频,无论画面多么震撼,终究是残缺的。长期以来,为视觉内容匹配高质量、多层次的音频(包括音效、语音、音乐、歌曲等),是一项高度依赖专业知识、耗费巨大时间与人力成本的工程。其背后的核心瓶颈,直指两大技术难题:高质量配对数据的极度稀缺与多任务学习框架的内在矛盾。前者意味着,我们很难获得海量“视频-多音轨”的精标数据来训练一个全能模型;后者则表明,让单一模型同时精通结构迥异的音乐、语音和音效生成,本身就是一项艰巨的挑战。
正当行业在数据与模型的“军备竞赛”中寻求突破时,腾讯悄然另辟蹊径,推出了一款名为AudioGenie的新型系统。它如同一位深谙音律的精灵,被赋予了从视频、图像、文本等多模态输入中“凭空”创造丰富音频世界的能力。更令人瞩目的是,AudioGenie的核心理念是**“无训练”(Training-Free),它不依赖于端到端的模型训练,而是构建了一个精密的多智能体(Multi-Agent)协作系统**。这不仅是一次技术路线的巧妙突围,更可能是一场关于AI音频生成范式的深刻变革。本文将带您深入AudioGenie的内核,探寻这位“全能配音师”诞生的秘密,并展望它为未来创意产业所开启的无限可能。
🎵 一、架构解构:当AI学会“团队协作”
%20拷贝-ggqz.jpg)
传统AI模型往往像一个孤军奋战的“通才”,试图用一个庞大的神经网络解决所有问题。而AudioGenie的设计哲学则截然不同,它认为“专业的事应该交给专业的角色来做”。为此,它构建了一个由多个AI智能体组成的“音频工作室”,内部组织严密,分工明确,形成了一个高效的双层多智能体架构。
这个架构的核心,是**“生成团队”(Generation Team)与“监督团队”(Supervision Team)**的动态博弈与协作。这好比一个电影音效团队,既有负责创作的音效师、配乐师,也有一位严苛的音效总监负责最终的质量把控和整体协调。
1.1 生成团队:音频创作的“梦之队”
生成团队是整个系统的创意引擎,其工作流程被精妙地划分为三个环环相扣的阶段。这个团队的目标是:理解输入,拆解任务,并以最优方式执行。
1.1.1 第一步:精细化任务分解(Systematic Task Decomposition)
当一段多模态输入(例如,一段包含人物对话、背景环境和动作的视频)进入AudioGenie系统时,它首先遇到的不是一个急于生成音频的“莽夫”,而是一位冷静的“项目经理”——任务分解模块。
这个模块的核心职责是深度理解与结构化解析。它会像一位经验丰富的导演审阅分镜脚本一样,对输入内容进行逐帧、逐场景的分析,提取出所有与声音相关的关键信息,并将其转化为一系列结构化的子任务。这个过程涉及:
时空定位(Spatio-temporal Grounding):精确识别出需要配音的事件发生在视频的哪一秒,以及声音在画面中的大致方位(例如,左侧、右侧、远处)。例如,视频第3.5秒,画面右侧有一只狗在吠叫。
事件识别与分类(Event Recognition and Classification):判断出需要生成何种类型的音频。这包括但不限于:
语音(Speech):识别出画面中人物的对话内容(如果输入包含文本描述)或口型,并标注为语音生成任务。
音效(Sound Effect):识别出物体的交互声,如关门声、脚步声、玻璃破碎声等。
音乐(Music):根据画面氛围、节奏或文本提示,判断是否需要背景音乐,并标注其风格(如“悲伤的钢琴曲”、“激昂的交响乐”)。
歌曲(Song):当输入明确要求或场景(如KTV、演唱会)强烈暗示时,生成包含人声演唱的歌曲。
环境声(Ambiance):识别整体环境,如“雨夜的街道”、“热闹的市集”、“宁静的森林”,并标注为环境音生成任务。
属性描述(Attribute Description):为每个声音事件附上更丰富的定性描述。例如,同样是“关门声”,它可以是“沉重的木门缓缓关闭”、“汽车门被用力甩上”;同样是“狗叫”,可以是“小狗的轻吠”或“大狗的咆哮”。这些描述将直接影响后续生成模型的效果。
经过这一阶段,原本混沌的多模态输入,就被转化为一张清晰的“音频制作清单”,每一个子任务都包含了时间戳、音频类型、内容描述、空间信息等关键字段。
1.1.2 第二步:自适应混合专家协作(Adaptive Mixture-of-Experts Collaboration)
任务清单制定完毕后,便进入了执行阶段。此时,AudioGenie的另一个核心创新——自适应混合专家(MoE)协作机制——开始发挥作用。
“混合专家”模型本身并非全新概念,但AudioGenie将其运用在了一个“无训练”的宏观调度层面。它预先集成了一系列在特定音频领域表现卓越的**“专家模型”**(可以是开源的,也可以是专有的)。这些专家各有所长,仿佛是音频工作室里各怀绝技的艺术家:
语音专家:可能是一个先进的文本到语音(TTS)或声音克隆模型(如VALL-E)。
音乐专家:可能是一个强大的文本到音乐生成模型(如MusicLM, AudioLDM)。
音效专家:可能是一个专注于根据文本描述生成高保真音效的模型(如Make-An-Audio)。
歌曲专家:可能是一个能够同时生成伴奏和人声的歌唱合成模型。
MoE机制的核心是一个**“智能调度网关”**。它会审阅任务分解模块生成的每一个子任务,并根据任务的类型和描述,动态地、自适应地为其指派最合适的专家模型。
这种方式的巨大优势在于:
专业性:确保每个细分任务都由最擅长它的模型来处理,避免了“通才”模型在某些领域的短板。
灵活性与可扩展性:系统可以随时集成更先进的专家模型,而无需改动整体架构。某个专家模型被淘汰或升级,就像工作室更换了一位成员一样简单。
效率:任务可以并行处理,大大提升了整体音频的生成速度。
1.1.3 第三步:试错与迭代优化(Trial-and-Error Iterative Refinement)
初稿完成,但工作尚未结束。生成团队内部还有一个关键的**“自我修正”**环节。这个模块像是一位富有经验的制作人,会对专家们提交的初步音频片段进行内部审查。
它会检查音频与任务描述的语义匹配度。例如,任务要求是“小狗的轻吠”,但生成的音频听起来像一只大狼狗,优化模块就会向专家模型发出“重做”指令,并可能微调输入的文本提示(Prompt),比如增加“高音调”、“温和”等关键词,引导模型生成更贴切的结果。
这个试错与迭代的过程是自动化的,它通过内部的评估函数(可能基于某些声学特征分析或小型判别模型)来判断生成质量,并进行多轮优化,直到生成的音频方案在内部审查中达到一个较高的满意度。这体现了智能体系统自主规划和解决问题的能力,极大地提升了最终输出的质量和美感。
1.2 监督团队:质量与一致性的“守门员”
当生成团队提交了它认为满意的“音频草案”后,这份草案并不会直接输出给用户,而是要经过第二层架构——监督团队的严格审核。监督团队是最终质量的保证,其核心职责是确保时空一致性并验证整体输出质量。
监督团队通过一个**反馈循环(Feedback Loop)**机制工作,它关注的焦点更为宏观和整体:
时空一致性验证(Spatio-temporal Consistency Verification):监督团队会像视频剪辑师对齐音画轨道一样,严格检查每一个音频事件的时间戳是否与视频画面中的动作精确同步。例如,嘴唇闭合的瞬间,对话声音是否恰好停止;玻璃破碎的画面出现时,破碎声是否同时响起。此外,它还会检查音频的空间感是否与画面逻辑一致,例如,角色从左走到右,声音是否也呈现出相应的平移效果。
多音频融合与平衡(Multi-audio Blending and Balancing):一个场景中往往包含多种声音(对话、背景音乐、环境声、音效)。监督团队需要评估这些声音的混合效果。对话是否清晰可闻?背景音乐是否过于响亮以至于压过了关键音效?环境声是否自然地融入了整个场景?如果存在问题,它会向生成团队发出调整指令,例如“降低背景音乐音量3dB”、“为人声增加一些混响以匹配室内环境”。
整体质量评估(Holistic Quality Assessment):最后,监督团队会对整个音频作品进行最终的艺术和技术评审。这包括检查是否存在爆音、噪声等技术瑕疵,以及评估整体听感是否和谐、是否符合输入所要求的情感氛围。
只有通过了监督团队全方位的苛刻检验,一份最终的、高质量的多轨音频才会被正式“签发”,完成整个生成流程。
下面,我们通过一个Mermaid流程图来直观地展示AudioGenie的双层架构工作流:
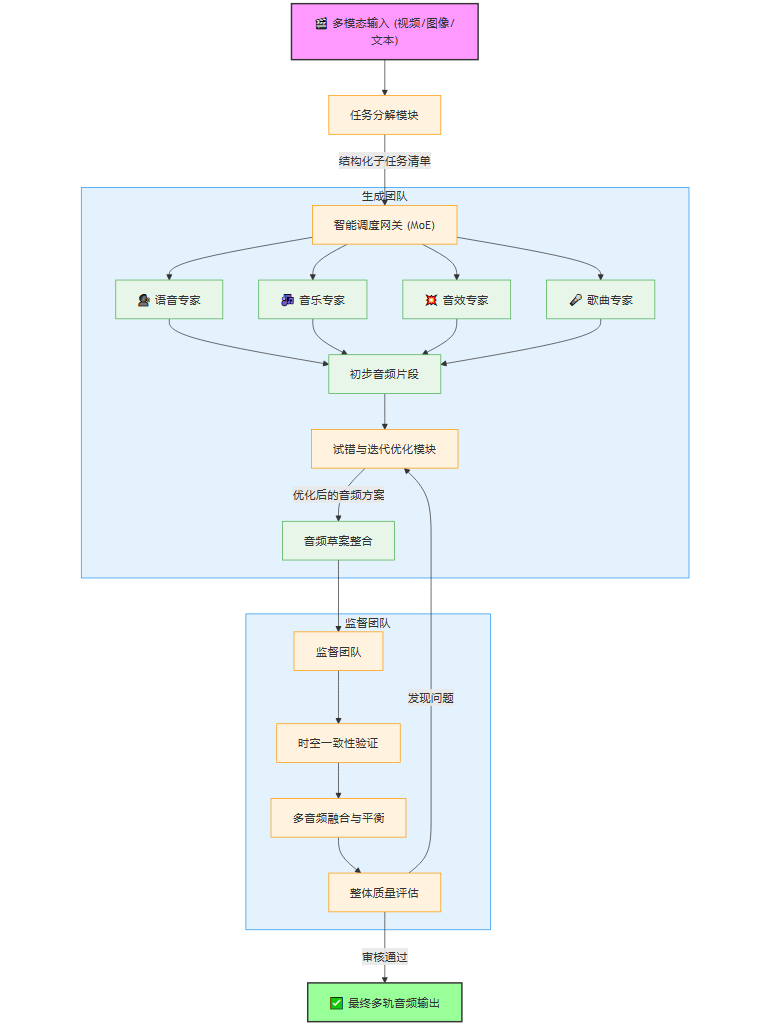
通过这种**“创作-审核”的分离与协作机制,AudioGenie巧妙地将复杂的MM2MA任务解耦,用流程的确定性弥补了单一模型能力的不确定性,最重要的是,这一切都无需进行端到端的模型训练**,从而彻底摆脱了对大规模、高质量配对数据的依赖。这不仅是技术的胜利,更是AI设计理念的一次重要演进。
💡 二、基石与标尺:MA-Bench数据集的开创性意义
任何一项开创性技术的诞生,都需要一个公平、科学的“试炼场”来证明其价值。在AudioGenie之前,MM2MA领域缺乏一个公认的、标准化的评测基准,这使得不同研究之间的比较变得困难,也阻碍了整个领域的快速发展。如同ImageNet之于计算机视觉,腾讯团队深知,要推动MM2MA技术走向成熟,必须先立下标尺。
为此,他们构建了全球首个专为多模态到多音频生成任务设计的基准数据集——MA-Bench。
2.1 MA-Bench:不止于数据,更是标准
MA-Bench不仅仅是198个视频的集合,它是一个精心设计、专业标注的评测体系。其构建理念体现了对MM2MA任务复杂性的深刻理解。
内容多样性:这198个视频经过精心挑选,涵盖了极其广泛的场景和类型,包括但不限于:
日常生活场景:如街头、餐厅、办公室,充满了丰富的环境声和零散的对话。
动作与事件:如体育比赛、车辆追逐、物体交互,需要精确同步的音效。
自然风光:如森林、海滩、雨景,考验环境氛围的营造能力。
情感与叙事:如电影片段、戏剧表演,需要音乐和语音来烘托情感。
抽象与创意:一些无具体现实对应的视觉效果,考验AI的想象力。
标注的专业性与精细度:这是MA-Bench的核心价值所在。每一个视频都由专业的音频工程师进行了多轨、多类型的音频标注。这种标注远超“视频里有狗叫”的粗略描述,而是达到了制作级别的精度:
精确时间戳:每个声音事件的起始和结束时间被精确到毫秒级。
多类型标签:明确标注每个声音是音效、语音、音乐还是环境声。
丰富文本描述:对每个声音进行详细的文字描述,如“清脆的玻璃杯碰撞声”、“中年男性低沉的耳语”。
层次化结构:标注不仅有前景音(如对话、关键音效),还有中景音(如次要环境互动)和背景音(如持续的环境氛围、BGM),形成了一个完整的音景(Soundscape)结构。
2.2 性能评测:在“考场”上证明实力
有了MA-Bench这个“标准化考场”,AudioGenie的性能得以被客观、全面地衡量。实验结果令人振奋:在涵盖8大类任务的9个关键评测指标上,AudioGenie均取得了当前最优(SOTA)或具有高度可比性的性能。
这些指标可能包括(根据行业通用标准推测):
客观指标:
FAD (Fréchet Audio Distance): 衡量生成音频与真实音频在分布上的相似度,分数越低越好。
KL Divergence: 同样用于评估音频分布的相似性。
CLAP Score: 衡量生成的音频与输入文本描述的匹配程度,分数越高越好。
Temporal Alignment Error: 衡量生成音效与视频事件在时间上的延迟或超前,误差越小越好。
主观指标:
MOS (Mean Opinion Score): 由人类评估者对音频的整体质量、真实感和与视频的匹配度进行打分(通常为1-5分),是衡量用户体验的金标准。
AudioGenie在这些硬核指标上的优异表现,雄辩地证明了其多智能体架构的有效性。它不仅能生成音频,而且生成得准、好、且与视觉内容高度协调。
2.3 用户研究:从数据到感知的最终验证
冰冷的数字之外,用户的真实感受是评判一个AIGC工具成功与否的最终标准。为此,研究团队还进行了广泛的用户研究。他们邀请了普通用户和专业音频从业者,对AudioGenie生成的音频以及其他SOTA模型生成的音频进行盲评。
结果进一步证实了AudioGenie的显著优势。用户普遍认为,AudioGenie生成的音频在以下几个方面表现突出:
音频质量(Audio Quality):声音更清晰、饱满,伪影(artifacts)更少。
准确性(Accuracy):声音内容与视频事件的匹配度极高,听起来“就是那个声音”。
上下文对齐(Contextual Alignment):音频的整体氛围和情感基调与视频内容高度统一,能有效增强沉浸感。
美学体验(Aesthetic Experience):多音轨的融合自然、和谐,具有一定的艺术美感,而不仅仅是声音的简单堆砌。
MA-Bench的建立和其上的优异评测结果,共同为AudioGenie的横空出世提供了最坚实的背书。它不仅证明了自身的技术领先性,更为整个MM2MA领域树立了一个可供追赶和超越的全新标杆。
🚀 三、裂变与赋能:AudioGenie的应用前景与行业冲击
%20拷贝-uqos.jpg)
一项颠覆性技术的价值,最终体现在其对现实世界的改造能力上。AudioGenie以其“无训练、高质量、多模态”的特性,正像一把钥匙,即将开启创意产业中无数尘封已久的大门。它所带来的,不仅是效率的提升,更是一场关于创作门槛、工作流程乃至商业模式的深刻变革。
3.1 降低创作门槛:从“专业限定”到“全民创作”
传统的音频制作,尤其是影视和游戏领域的音效设计,是一个技术与艺术高度结合的专业领域。它需要昂贵的设备、庞大的音效库、专业的软件技能以及长期的经验积累。一个独立开发者或小型内容创作者,往往因为无法承担高昂的音频制作成本,而在作品的最终呈现效果上大打折扣。
AudioGenie的出现,有望彻底改变这一局面。它将复杂的音频生成过程封装在一个简单易用的“黑箱”中,用户只需提供视觉素材(视频、图片)和简单的文本描述,就能获得专业级的多轨音频。这意味着:
独立游戏开发者:可以快速为游戏场景生成匹配的环境音、角色技能音效和动态背景音乐,极大地丰富游戏的可玩性和沉浸感,而无需再为寻找或购买合适的音效素材而烦恼。
短视频创作者与Vlogger:可以轻松地为自己的视频添加生动的音效和贴合情绪的BGM,让日常记录变得更具表现力和电影感,提升内容的吸引力。
教育与演示内容制作者:在制作教学动画或产品演示视频时,可以一键生成旁白、操作提示音和背景音乐,使信息传递更高效、更生动。
AudioGenie正在将音频创作的能力,从少数专业人士手中, democratize(大众化)给每一个有创意的人。 这无疑将催生出更加丰富多元的UGC(用户生成内容)和PUGC(专业用户生成内容)生态。
3.2 重塑工作流程:从“劳动密集”到“人机协同”
对于专业的影视、游戏、广告制作团队而言,AudioGenie同样具有革命性的意义。它并非要取代专业的音效师或配乐师,而是要成为他们强大的**“AI副驾”**,将他们从大量重复、繁琐的基础工作中解放出来,更专注于创意本身。
影视后期制作:
Foley(拟音)的自动化:传统拟音需要拟音师在录音棚里模拟各种声音,如脚步声、衣物摩擦声等,费时费力。AudioGenie可以直接根据画面生成高质量的拟音音轨,作为基础层,拟音师只需在此基础上进行精修和艺术化处理。
快速场景音景搭建:对于复杂的场景,如战争场面或繁华都市,音效编辑需要从音效库中挑选、混合数十甚至上百条音轨。AudioGenie可以一键生成一个包含环境声、主要音效的“音景草稿”,编辑只需进行微调和添加点睛之笔。
临时配乐(Temp Music)的智能生成:导演在剪辑阶段通常需要临时配乐来寻找感觉。AudioGenie可以根据画面情绪和导演的文字描述,快速生成风格多样的临时配乐,大大提升沟通效率。
游戏开发:
程序化音频生成:在开放世界游戏中,为成千上万个物体和环境交互都手动配置音效是不现实的。AudioGenie可以与游戏引擎深度集成,实现**程序化音频(Procedural Audio)**的实时生成。例如,当玩家角色走过不同材质的地面(草地、石板、雪地)时,系统可以实时生成匹配的脚步声,极大增强了世界的真实感和互动性。
动态音乐系统:根据游戏进程(如探索、战斗、潜行),AudioGenie可以动态生成和切换无缝衔接的背景音乐,营造出更具沉浸感的游戏体验。
AudioGenie将推动音频制作流程从“劳动密集型”向“创意密集型”转变,实现人机协同的“1+1>2”效应。
3.3 拓展交互边界:为虚拟世界注入“听觉灵魂”
随着元宇宙、虚拟现实(VR)、增强现实(AR)以及数字人技术的兴起,我们正在构建日益逼真的虚拟世界。然而,一个视觉上再真实的世界,如果听觉体验是贫乏和重复的,其沉浸感将大打折扣。AudioGenie为这些前沿领域提供了至关重要的技术支撑。
虚拟人与智能助手:当前的虚拟人交互,声音往往是预录制或由单一TTS引擎生成,缺乏情感和环境互动。结合AudioGenie,虚拟人不仅能根据对话内容调整语气和情感,还能在与虚拟环境交互时(如拿起杯子、敲击键盘)实时生成相应的音效,使其行为更加可信、生动。
VR/AR体验:在VR/AR应用中,声音的空间感和真实感至关重要。AudioGenie可以根据用户在虚拟空间中的位置和朝向,实时渲染出具有3D空间音效的音景。当用户靠近瀑布时,水声会变大并具有方向感;当虚拟物体从用户身边飞过时,声音也会随之移动,创造出极致的临场感。
元宇宙的“创世之声”:在元宇宙平台中,用户可以自由地建造和创造。AudioGenie可以成为元宇宙的“声音引擎”,允许用户通过简单的描述,为自己创造的物体和场景赋予独一无二的声音,让每一个虚拟空间都拥有自己独特的“听觉DNA”。
3.4 挑战国际格局:中国AI音频技术的“亮剑”时刻
长期以来,在AIGC的核心技术领域,尤其是大模型层面,国际上的头部公司(如OpenAI, Google, Meta)似乎掌握着更多的话语权。AudioGenie的发布,无疑是中国AI力量在全球舞台上的一次重要“亮剑”。
其“无训练多智能体”的创新架构,成功绕开了对超大规模专有数据集的强依赖,这在一定程度上规避了数据壁垒带来的竞争劣势,为后来者提供了一条“换道超车”的可能路径。这种设计哲学上的差异化创新,不仅在技术上取得了SOTA的成果,更向世界展示了解决复杂AI问题的另一种可能性。
AudioGenie的成功,有望:
提升中国AI技术的国际声誉:证明中国不仅能在应用层面快速跟进,同样能在底层架构和核心算法上做出世界级的原创性贡献。
推动国内相关产业链的升级:AudioGenie作为一项平台级技术,可以赋能国内众多内容创作、游戏、社交、硬件等领域的企业,形成一个繁荣的AI音频生态,带动整个产业链向更高附加值方向发展。
在全球AIGC标准制定中占据一席之地:通过MA-Bench数据集的开源和AudioGenie展现出的强大能力,腾讯有机会在多模态音频生成这一新兴领域的国际标准制定中,扮演更重要的角色。
总而言之,AudioGenie的影响力远远超出了一个技术工具的范畴。它是一粒种子,播撒在创意产业的沃土上,有望在未来几年内,催生出我们今天难以想象的新物种、新业态和新体验。
总结
从追赶到引领,从模仿到创新,腾讯AudioGenie的问世,无疑是AI音频生成领域,乃至整个AIGC版图上一个值得被浓墨重彩记录的里程碑。它没有选择在“更大模型、更多数据”的传统路径上进行豪赌,而是以一种近乎“道法自然”的哲学,构建了一个分工协作、自我进化的智能体生态。
这个精巧的双层多智能体架构,通过生成团队的精细化分解、专家协作与迭代优化,以及监督团队的严苛把关,成功地将一个宏大而模糊的MM2MA难题,解构为一系列清晰、可执行、可评估的子任务。这种“化整为零,各个击破”的策略,不仅巧妙地规避了数据稀缺的行业痛点,更展现出一种高度灵活、可扩展的未来AI系统设计范式。
与之相辅相成的MA-Bench数据集,则如同为这片新兴的技术蓝海树立起第一座灯塔,为后续的研究者和开发者指明了方向,提供了统一的度量衡。AudioGenie在其上的卓越表现,不仅是自身实力的证明,更是对这一全新技术路线可行性的强力验证。
放眼未来,AudioGenie所开启的,是一个声音创作权被极大释放的时代。从独立创作者到好莱坞巨制,从虚拟世界的构建到人机交互的革新,这位“全能配音师”的身影,将无处不在。它不仅将极大地丰富我们的数字感官体验,更有望在全球AI技术的激烈竞逐中,为中国赢得关键的战略身位。AudioGenie的故事,才刚刚开始,而它所奏响的,无疑是AI赋能人类创造力的又一华彩乐章。
📢💻 【省心锐评】
AudioGenie跳出了“大力出奇迹”的模型竞赛,以架构创新破局数据困境。这不仅是技术的胜利,更是AI设计哲学的进化,预示着“智能体协作”将成为解决复杂AI任务的新范式。

评论