.png)
%20%E6%8B%B7%E8%B4%9D.jpg)

【摘要】本文系统梳理了AI幻觉的成因、表现及应对策略,结合主流大模型的最新数据与工程实践,深入分析其技术根源、行业影响与未来趋势,旨在为AI开发者与用户提供科学、全面的认知与实用建议。
引言
人工智能,尤其是大语言模型(LLM)的迅猛发展,正在深刻改变着信息获取、知识生产和决策支持的方式。无论是在医疗、法律、金融,还是在日常生活的智能助手场景中,AI的应用正变得无处不在。然而,随着AI能力的提升,一个不可回避的问题也日益凸显——AI幻觉。所谓“AI幻觉”,即模型在缺乏真实依据时,生成虚假、误导性甚至完全虚构内容的现象。这种现象不仅影响AI输出的准确性,更可能对业务决策、风险控制乃至社会信任体系带来深远影响。
在技术原理、工程实现和实际应用的多重维度下,AI幻觉已成为业界和学界共同关注的焦点。它既是AI生成机制与现实世界之间的落差,也是当前模型能力边界的真实写照。如何理解AI幻觉的本质?主流模型在幻觉率上有何差异?我们又该如何在实际工作中识别、应对甚至与幻觉“共处”?这些问题的答案,关乎AI技术的健康发展,也关乎每一位AI用户的切身利益。
本文将以系统化的视角,融合最新的行业数据、工程案例与理论分析,深入剖析AI幻觉的形成机制、表现特征、主流模型的对比进展及多维度的应对路径,力求为技术开发者、行业决策者和普通用户提供一份兼具深度与广度的参考指南。
一、AI幻觉的本质与技术根源
%20拷贝.jpg)
1.1 AI幻觉的定义与现实影响
AI幻觉(Hallucination)是指大语言模型在缺乏真实依据时,生成虚假、误导性甚至完全虚构内容的现象。它的本质在于模型“说得像真的,但其实是错的”。这一现象广泛存在于各类主流AI模型中,对输出准确性、业务决策和风险控制构成了直接挑战。随着AI在医疗、法律、金融等高风险领域的渗透,幻觉问题的影响愈发凸显,成为AI落地应用的核心难题之一。
1.2 语言模型的工作机制
1.2.1 预测而非理解
大语言模型(如GPT、Claude、Gemini等)并非真正“理解”事实,而是基于概率预测下一个最可能出现的词(token)。其本质是统计语言模式,而非事实回忆或推理。模型通过在大规模语料库中学习词与词之间的共现关系,形成对语言结构的把握,却并不具备对世界知识的结构化理解。
1.2.2 典型案例
例如,输入“乔布斯和马斯克在球场上”,模型可能续写“展开了一场激烈的篮球比赛”,即使这从未发生。模型并非有意捏造,而是基于语料中高频的语言搭配生成内容。这种“合理但不真实”的输出,正是幻觉的典型表现。
1.3 技术根源剖析
1.3.1 训练机制的局限
无监督学习目标:主流大模型采用无监督学习,以最大化下一个词出现的概率为目标。模型记忆的是“词与词的共现关系”,而非结构化知识库。
缺乏事实核查:模型生成内容时,并不主动查证事实,仅依赖于训练时学到的统计规律。
1.3.2 数据覆盖与时效性
数据有限与过时:训练数据的覆盖范围有限,且存在时效性。例如,GPT-3.5的训练数据截止于2021年,无法正确回答“2022年冬奥会冰壶金牌得主”。
知识盲区:在训练数据未覆盖的领域,模型更易“胡编乱造”。
1.3.3 Prompt诱导效应
用户提问方式影响结果:Prompt的措辞对模型输出有极强导向性。模型不会主动验证事实,只会按“剧本”生成内容。
虚构前提的风险:如“请写一篇关于爱因斯坦和马斯克辩论环保问题的稿件”,模型会默认事件真实存在,生成合理但虚构的内容。
1.3.4 世界建模与推理能力不足
缺乏世界建模能力:模型不理解时间、空间、因果关系,逻辑冲突时也不会主动识别。
推理链断裂:在复杂推理任务中,模型容易出现推理链断裂,导致输出内容偏离事实。
1.3.5 知识检索与指令模糊
知识检索失败:无法检索或查证正确信息时更易幻觉。
指令模糊:模糊指令或推理不一致时,模型更易生成偏离事实的内容。
1.4 幻觉的七大特征
AI幻觉的七大特征如下:
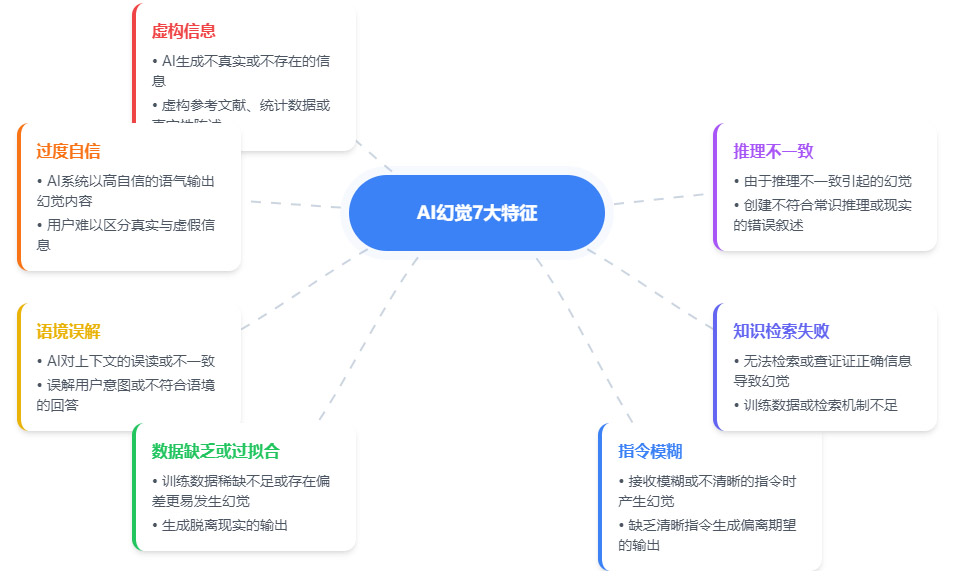
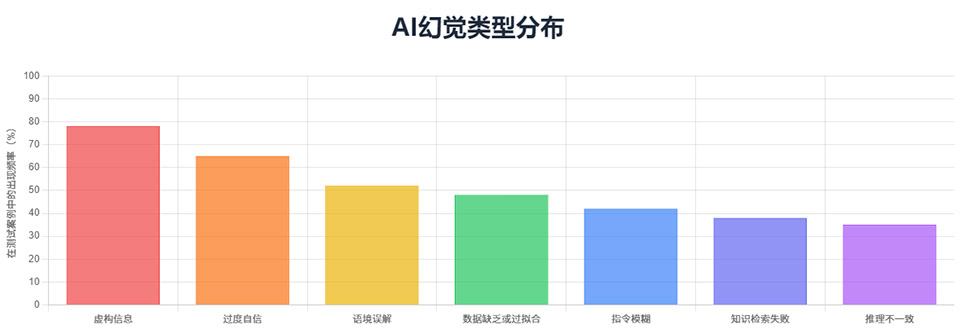
AI幻觉特征的出现概率:
虚构信息:AI生成不真实或不存在的信息,如虚构参考文献、统计数据或事实性描述。
过度自信:AI系统以高自信的语气输出幻觉内容,用户难以区分真假与虚假信息。
话境误解:AI对上下文的误读或不一致,或误解用户意图,给出不合语境的回答。
数据缺乏或过拟合:训练数据稀缺或存在偏差时更易发生幻觉,生成脱离现实的输出。
指令模糊:接收模糊或不清晰的指令时产生幻觉,缺乏清晰指令会生成偏离期望的输出。
知识检索失败:无法检索或查证正确信息导致幻觉,训练数据或检索机制不足。
推理不一致:由于推理不一致引起的幻觉,或创建不符合常识推理或现实的错误叙述。
整体来看,这张图帮助我们快速理解AI幻觉的主要类型及其成因,为后续识别和防范AI幻觉提供了结构化的参考。
1.5 幻觉的现实影响
AI幻觉不仅影响文本生成的准确性,更直接影响到医疗、法律、金融等高风险行业的业务决策和风险控制。幻觉输出一旦被误信,可能导致严重后果。因此,识别和应对AI幻觉,已成为AI应用落地的关键环节。
二、主流模型幻觉率对比与进展
2.1 幻觉率的定义与测量
幻觉率是衡量大语言模型输出中虚假或无依据信息比例的核心指标。Vectara幻觉排行榜通过对主流模型在标准任务下的表现进行量化,统计截至2024年12月11日的数据,成为行业内重要的参考标准。
2.2 幻觉率排行榜与数据解读
2.2.1 幻觉率最低的模型
2.2.2 幻觉率最高的模型
2.2.3 数据解读
顶尖模型幻觉率已降至1.3%~1.8%,显示出AI技术在控制幻觉方面的显著进步。
部分模型幻觉率仍高达30%,表明模型架构、训练数据和优化策略的差异对幻觉率有决定性影响。
OpenAI、Google、智谱AI等新一代模型在幻觉控制方面表现突出,成为行业标杆。
2.3 幻觉率进步的技术驱动力
2.3.1 更大训练数据集
扩展数据覆盖面,涵盖更多领域与长尾知识,减少“知识空白”导致的猜测。
2.3.2 上下文窗口扩大
如GPT-4 context window扩展至32k token,模型能记住更多上下文,减少断章取义和语义漂移。
2.3.3 人类反馈强化学习(RLHF)
在模型微调阶段引入人类标注反馈,强化“承认不知道”优于“胡编乱造”的行为。
2.3.4 置信度判断机制
增加对输出置信度的判断,低置信度时输出更保守,减少幻觉。
2.3.5 专业领域精调
在医学、金融、法律等专业领域训练专用子模型,显著降低幻觉率。例如,谷歌Med-PaLM 2通过医学论文训练和人类审核,错误率比通用模型降低50%。
2.4 进步背后的局限性
冷门专业领域、模糊或虚构前提、最新事件等场景下幻觉仍易发生。
训练数据截止后无法回答新事实,模型对最新知识的掌握存在天然滞后。
结构性知识和因果推理能力仍有限,复杂推理任务下幻觉风险依然存在。
三、GPT-4等新一代模型的改进与局限
%20拷贝.jpg)
3.1 技术进步的多维度解析
3.1.1 数据与架构的双重升级
更大规模的数据集和更深层次的模型架构,使得模型在理解复杂语境和长尾知识方面能力显著提升。
上下文窗口的扩大,提升了模型对长文本的处理能力,减少了语义漂移和断章取义。
3.1.2 人类反馈与微调策略
RLHF(人类反馈强化学习)成为提升模型可靠性的关键。通过人类标注,模型学会在不确定时承认“我不知道”,而不是编造答案。
微调阶段引入置信度机制,使模型在低置信度时更倾向于给出模糊或保守的回答,降低幻觉风险。
3.1.3 专业领域的精细化训练
针对医学、金融、法律等高风险领域,训练专用子模型,显著提升专业领域的准确性和安全性。
以谷歌Med-PaLM 2为例,通过医学论文训练和人类审核,错误率比通用模型降低50%。
3.2 依然存在的局限性
在冷门专业领域、模糊或虚构前提、最新事件等场景下,幻觉问题依然突出。
训练数据的时效性限制了模型对最新事实的掌握,导致在新兴领域或突发事件中幻觉率上升。
结构性知识和因果推理能力的不足,使得模型在复杂推理任务中仍有较高的幻觉风险。
3.3 典型案例与行业数据
GPT-4在美国律师考试中成绩超越90%考生,GPT-3.5仅超越10%,但幻觉风险依然存在。
谷歌Med-PaLM 2通过医学论文训练和人类审核,错误率比通用模型降低50%。
Vectara幻觉排行榜显示,顶尖模型幻觉率已降至1.3%,最差模型接近30%。
MIT课堂案例:GPT-3.5因数据截止,错误回答2022年冬奥会金牌归属。
四、应对AI幻觉的协同策略
4.1 用户端优化路径
4.1.1 明确指令与结构化Prompt
明确指令:如“若不知道答案,请直接说明”“仅基于我上传的文档回答”。
结构化Prompt:限定输出格式(如“分三点说明”“用表格列出”),减少模型自由发挥空间,降低幻觉概率。
4.1.2 避免诱导性提问与交叉验证
避免诱导性提问,尤其在高风险领域,防止模型被虚构前提误导。
交叉验证:用不同模型(如Claude、Gemini)比对答案,或查权威资料,提升输出可靠性。
4.2 系统端工程优化
4.2.1 检索增强生成(RAG)
回答前先检索外部数据库,显著降低幻觉率。例如,法律领域RAG后幻觉率从15%降至2%以下。
4.2.2 插件与实时联网
集成WolframAlpha(计算)、BingSearch(新闻)等插件,提升事实核查能力,增强模型对最新信息的获取能力。
4.2.3 多阶段生成机制
将任务理解、信息检索、内容生成分步执行,避免单步误导,提升整体输出的准确性和可靠性。
4.2.4 专业模型精调
针对特定领域训练专用子模型,提升专业领域的准确性和安全性。
4.3 行业治理与标准建设
4.3.1 标准化评测体系
建立标准化评测体系(如TruthfulQA),定期发布模型幻觉指数排名,推动行业健康发展。
4.3.2 开放可信知识图谱
构建开放可信的知识图谱,供模型调用,提升事实核查能力,降低幻觉风险。
4.4 多模型融合与协同防控
4.4.1 多模型交叉验证
在关键场景下,采用多模型并行输出,通过对比不同模型的答案,筛查潜在幻觉。例如,医疗诊断、法律咨询等高风险领域,建议同时调用GPT-4、Claude、Gemini等主流模型,取其交集或一致性高的结论,显著提升输出的可靠性。
4.4.2 智能代理与自动化校验
利用AI Agent机制,自动对模型输出进行事实核查和逻辑一致性检测。通过集成外部知识库、权威数据库和事实查验工具,自动标记和过滤高风险幻觉内容,为用户提供多层次的安全保障。
4.4.3 反馈闭环与持续优化
建立用户反馈闭环机制,收集实际使用中的幻觉案例,反哺模型微调和系统优化。通过持续的数据积累和反馈迭代,动态提升模型的事实准确性和幻觉防控能力。
4.5 典型工程实践案例
4.5.1 法律领域RAG应用
某法律科技公司在智能合同审查系统中引入RAG(Retrieval-Augmented Generation)架构,模型在生成答案前自动检索权威法律数据库。经实测,系统幻觉率由原先的15%降至2%以下,极大提升了法律文本生成的可靠性。
4.5.2 医疗领域专业模型精调
医疗AI平台通过引入医学论文、指南和病例数据,对通用大模型进行专业精调。结合人类医生的审核反馈,模型在罕见病诊断、药物推荐等场景下的幻觉率显著下降,部分指标优于行业平均水平。
4.5.3 金融领域多阶段生成机制
金融智能问答系统采用“任务理解-信息检索-内容生成”三阶段流程,确保每一步均有事实校验和逻辑审查。系统上线后,用户反馈的幻觉案例大幅减少,业务风险得到有效控制。
五、理性共处与未来展望
%20拷贝.jpg)
5.1 流畅≠真实:幻觉的本质认知
AI幻觉是统计生成与真实世界之间的落差,是当前大语言模型能力边界的自然结果。模型输出的流畅性和逻辑性,并不等同于事实的可靠性。用户在享受AI带来高效与便捷的同时,必须保持对幻觉风险的高度警觉。
5.2 保持怀疑与验证:用户的必修课
任何“头头是道”的AI回答都应保留验证习惯,尤其在医疗、法律、金融等高风险领域。建议用户在关键决策前,主动查证AI输出内容,结合多源信息和权威资料,避免因幻觉导致的误判和损失。
5.3 关注模型更新与能力边界
AI模型的能力和幻觉率随技术进步不断演化。用户和开发者应及时关注主流模型的能力变化、幻觉率排名和新特性,合理选择和使用,规避模型在特定领域的短板。
5.4 未来展望:多元协同与责任机制
随着外部工具的深度接入、Agent机制的完善和行业责任机制的明确,AI幻觉问题有望进一步缓解。未来,AI系统将更加注重事实核查、逻辑一致性和多源信息融合,推动内容生成的真实性和可靠性持续提升。
5.5 行业治理与标准化趋势
行业治理和标准化是AI幻觉防控的基础。建立统一的评测体系、开放可信的知识图谱和权威幻觉指数排名,将为AI内容的健康发展提供坚实保障。行业各方应共同推动标准制定和数据共享,构建开放、透明、可追溯的AI生态。
📢💻 【省心锐评】
“幻觉是LLM的‘思想呼吸’,无法窒息但可导流。未来属于懂得以RAG为肺、以验证为血的工程师。”

评论