.png)
%20%E6%8B%B7%E8%B4%9D-jdvd.jpg)

【摘要】AI规模化常败在数据链路、调度、IO与尾延迟,场景画像与软硬协同才决定成本和稳定性。
引言
2025 年的生成式 AI 已经不缺模型,也不缺算力口号。更常见的情况是,企业把试点跑通了,却迟迟不敢把它推到核心链路里。原因不复杂,业务要的是稳定、可控、可复用的产出,技术团队给出的往往是一次性的“能用”,两者之间隔着工程化和成本结构这条鸿沟。
MIT 在 2025 年 7 月发布的《The GenAI Divide: State of AI in Business 2025》给了一个很刺眼的现实。全球 300 亿到 400 亿美元的 AI 转型投入里,绝大多数项目停留在试点阶段,难以产生可衡量的业务价值,真正跨越到规模化的比例很低。把问题归因到“模型还不够强”很省事,但也最误导。规模化阶段的失败,往往不是算力不足,而是算力被用在了错误的位置。
很多团队在一次次“上 GPU,上更大模型”的循环里消耗预算,却没有把端到端链路拆开看。数据从哪里来,怎么清洗、转码、压缩、检索,特征怎么存,RAG 怎么读,在线服务的 P99 怎么控,系统抖动怎么收敛,弹性怎么做,合规怎么落地。这些环节里,GPU 只是其中一段,甚至不是最难的一段。把 AI 落地简化成 GPU 采购清单,是一种典型的工程错觉。
接下来讨论的重点只有一个。AI 落地要从行业口号回到业务场景,把算力需求做成“画像”,再用软硬协同把性能、成本、稳定性拉到同一张表里对齐。
◆ 一、GPU崇拜为何会让项目走偏
1.1 规模化失败的常见形态
试点阶段的成功标准通常很宽松,能展示效果就算赢。规模化阶段的标准很硬,线上要有 SLA,成本要能解释,安全要能审计,出了问题要能回滚。很多项目在扩容时突然失速,表现形式很固定。
1.1.1 端到端时延并不由模型决定
在线业务的用户体验看的是端到端时延,尤其是 P99、P999。模型推理时延只占其中一段,前后处理、特征读取、向量检索、缓存未命中、跨可用区网络、容器冷启动、线程调度抖动,都可能把尾延迟拉爆。只优化 GPU 推理毫秒数,无法解决尾延迟的秒级波动。
1.1.2 单位成本失控并不来自模型价格
规模化后最敏感的是单位成本,例如每千次请求成本、每分钟视频成本、每 GB 数据处理成本。很多系统的成本大头不是 GPU 推理本身,而是数据管道长期跑满、存储回源频繁、CPU 预处理吞吐不足导致 GPU 空转、离线任务调度不合理导致资源碎片化。成本失控常见的根因是链路效率,而不是模型 license 或卡价。
1.1.3 系统稳定性变差并不是模型不稳定
规模化以后,系统面对的是复杂输入、异常流量、依赖抖动、跨地域访问、合规策略差异。模型只是一段计算,真正影响稳定性的是工程系统,例如熔断与限流策略、依赖超时配置、缓存层击穿、索引重建窗口、队列积压处理、跨区灾备演练。把故障归因到模型波动,常常是对系统问题的回避。
1.2 “GPU算力等于AI能力”这句话的问题
%20拷贝-fvxn.jpg)
“算力越强效果越好”在研究阶段有一定道理,但在工程落地里,它把多维约束压扁成单指标,容易产生三个偏差。
第一,GPU 强并不等于系统强。很多链路的瓶颈在 CPU、内存带宽、网络和存储,GPU 再多也会被喂不饱。
第二,SOTA 并不等于可用。模型越大,输入输出越复杂,对上下游链路的压力越大,反而更难达成稳定的 SLA。
第三,采购并不等于能力。企业真正缺的是持续交付能力,包括数据治理、评测体系、可观测性、成本核算、弹性调度、安全合规。GPU 只能买到峰值算力,买不到端到端确定性。
1.3 把需求从“行业”切到“场景”才有解
同一个行业里,算力需求可以相差一个数量级。金融既有离线风控训练,也有在线实人认证。制造既有视觉质检在线推理,也有离线数据回放。游戏既有大厅在线服务,也有战斗服低抖动计算。行业标签只能告诉你业务大概在哪,不能告诉你系统会卡在哪里。
场景画像比行业标签更可靠。画像的核心不是一句话描述,而是指标集合和资源模型。做到这一步,选 GPU、选 CPU、选网络规格才有依据。
◆ 二、场景化算力的三类“底层特征”
把复杂需求压缩成三类特征不是为了偷懒,而是为了把系统指标和资源手段对齐。落地时可以用这三类作为第一层分类,然后在每一类里再细分业务子场景。
2.1 在线业务 低时延、高并发、高可用
在线业务的共同点是用户在等结果,系统容错空间很小。典型包括 Web、数据库服务、IoT 平台长连接、实时认证、在线推理与智能体服务。
2.1.1 在线业务真正看的是尾延迟
在线系统优化不能只看平均值,必须围绕 P95、P99、P999 做闭环。常见的尾延迟来源包括缓存不命中、向量检索回源、序列化与反序列化、线程调度抢占、NUMA 访问、跨区网络抖动、虚拟化开销。在线系统的优化目标是把抖动变小,把可解释性变强。
2.1.2 在线业务的资源模型更像“峰值防御”
很多在线系统的瓶颈在峰值时刻,例如活动流量、夜间设备上报高峰、跨国访问波动。资源策略要兼顾弹性和隔离,否则会出现相互挤压,导致业务互相拖垮。
2.2 离线业务 高吞吐、高效率、成本控制
离线业务的共同点是处理量大、时效性相对可控、成本敏感。典型包括训练前数据处理、PB 级多模态清洗、转码压缩、批量检索、索引构建、仿真任务流水线。
2.2.1 离线链路里 CPU 经常是主角
自动驾驶数据工程就是典型例子。多模态数据的清洗、畸变校正、转码、压缩、切片、抽帧、特征提取,很多都是 CPU 密集型工作。GPU 负责训练,但训练之前的准备决定了 GPU 的利用率。离线链路的关键指标是吞吐和单位成本,GPU 空转是最贵的浪费。
2.2.2 离线链路要把 IO 变成可控变量
离线任务经常被存储和网络拖慢。把冷热数据分层、压缩格式选择、并行度控制、批处理窗口、对象存储读写模式,都会直接影响吞吐。只在计算侧加卡,无法解决 IO 瓶颈。
2.3 高主频低抖动业务 游戏、量化交易、实时仿真
这类业务的共同点是对抖动极敏感,算力波动会直接变成体验或收益波动。游戏强调稳定帧时间和网络同步,量化交易强调微秒级路径稳定,实时仿真强调确定性。
2.3.1 抖动来自哪里
抖动常见来源包括 CPU 频率波动、邻居噪声、虚拟化层开销、NUMA 跨节点访问、GC 暂停、锁竞争、网络队列拥塞。这一类系统的优化重点是确定性,不是峰值。
2.3.2 资源隔离比弹性更重要
高主频低抖动业务可以接受更高成本,但不能接受不可预测。资源隔离、绑核、拓扑感知调度、网络栈优化,比“多开几台”更有效。
2.4 一张表把三类场景的指标对齐
把业务归类到这张表里,选型和优化才会变得可执行。
◆ 三、CPU为何重新回到核心位置
%20拷贝-uqbc.jpg)
GPU 对矩阵计算很强,这一点没有争议。问题在于,企业的 AI 系统并不是一段矩阵计算,它是一条链路。链路里最容易被忽略的部分,常常由 CPU 决定上限。
3.1 端到端链路里 CPU 负责“前后左右”
很多团队把 CPU 视为“只能跑业务逻辑”,这已经过时了。现代 CPU 在数据处理、向量计算、压缩解压、加密、网络栈、调度方面都扮演关键角色。放到 AI 链路里,它承担的工作包括但不限于以下几类。
3.1.1 数据预处理和转码
视频转码、抽帧、图像解码、音频处理、日志解析、特征拼接,这些操作对 CPU 和内存带宽敏感。离线任务里,预处理吞吐决定训练供给速度。在线任务里,预处理时延决定尾延迟。
3.1.2 检索与 RAG 的高频数据访问
RAG 场景的瓶颈经常出现在向量检索和文本检索的组合上。索引扫描、缓存命中、序列化开销、网络回源,都是 CPU 和 IO 的工作。RAG 做不稳,很多时候不是 embedding 不好,而是检索链路不稳。
3.1.3 服务编排和调度
在线推理服务要做线程池、队列、限流、熔断、批处理、优先级,调度策略不合理会带来排队放大和尾延迟扩散。调度是 CPU 的工作,也是系统工程能力的集中体现。
3.2 以“指令与加速”补齐 CPU 在 AI 负载的短板
讨论 CPU 不是回到纯通用计算,而是讨论它在 AI 负载里的效率。以业界常用的矩阵指令加速、向量指令、压缩卸载为例,它们可以把原本占 CPU 周期的热路径压下去,把单位成本做出来。
这里不展开具体品牌对比,只强调一个工程规律。**只要 AI 系统里存在大量前后处理、检索、压缩、加密、协议栈工作,CPU 的能力就会影响 GPU 的利用率和系统的尾延迟。**规模化阶段,这往往比单次推理快多少更重要。
3.3 一张“链路视角”的示意图
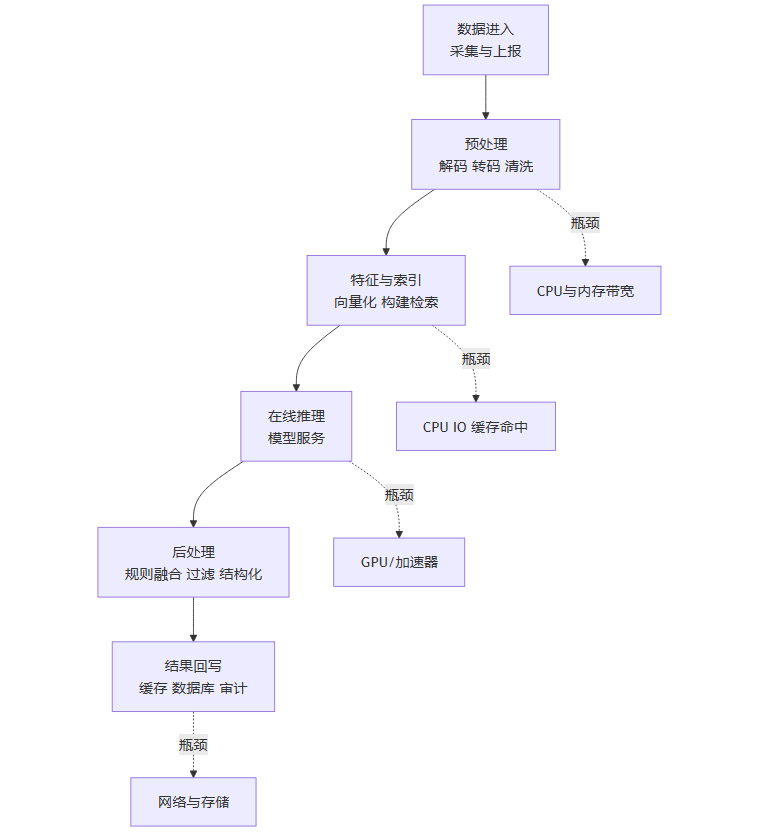
这张图想表达的点很简单。GPU 只在 D 处是主角,但 B、C、E、F 的问题会决定 D 能不能持续满载,也会决定端到端 SLA 能不能守住。
◆ 四、把“场景画像”落到工程动作
很多团队知道要“按场景优化”,但落地时容易停在概念层。工程上更有效的方法是把场景画像变成指标表,再把指标表变成资源和代码层的动作清单。
4.1 先做指标再做选型
在线、离线、低抖动三类场景各自最关键的指标不同,不能混用。
4.1.1 在线业务的指标最小集合
在线业务至少要有以下四类指标,并且要能按业务维度切片。
SLA 指标,例如成功率、超时率
时延指标,例如 P50、P95、P99、P999
并发与队列指标,例如队列长度、排队时长、拒绝率
依赖指标,例如缓存命中率、回源时延、跨区调用比例
没有 P99 和依赖分解,在线业务的优化方向经常是拍脑袋。
4.1.2 离线业务的指标最小集合
离线业务要把吞吐、成本和资源利用率绑定起来看。
吞吐指标,例如每小时处理数据量、每节点吞吐
成本指标,例如每 TB 处理成本、每分钟任务成本
利用率指标,例如 CPU 利用率、IO 吞吐、GPU 利用率
稳定性指标,例如失败重试率、任务拖尾分布
离线链路最怕平均值好看,拖尾把窗口撑爆。
4.1.3 低抖动业务的指标最小集合
这类业务要用稳定性指标替代平均性能指标。
抖动指标,例如帧时间方差、延迟抖动分位数
频率稳定性指标,例如全核频率波动范围
调度干扰指标,例如上下文切换、抢占次数
网络稳定性指标,例如丢包、队列抖动
4.2 再把指标映射到“资源与架构动作”
下面是一张更贴近工程实施的映射表,方便在评审时对齐。
这张表里有一个共同点。动作大多不是“换更大模型”,也不是“多买几张卡”,而是围绕链路效率和确定性做系统工程。
◆ 五、案例视角下的“同名需求,不同本质”
%20拷贝-chtq.jpg)
行业里经常出现同一句需求,比如高并发、低时延、降本增效。真正决定方案的,是需求背后的约束。
5.1 金融安全的高并发是零容错
实人认证、反欺诈、深度伪造对抗这类系统的特征是风险高、链路短、合规重。它需要在很短时间内并行完成多任务,并且对数据访问和审计留痕有硬要求。工程上常见的关键点包括并行流水线、低尾延迟、数据加密与隔离、跨地域一致性策略。
在这类场景里,**算力不是单点峰值,算力是可预测的响应时间。**这也是很多团队开始关注通用计算与云侧调度能力的原因,例如更好的缓存与内存带宽、更低的虚拟化损耗、更稳定的网络路径,往往比单次推理快几毫秒更有效。
5.2 游戏的高并发是零抖动
游戏服的压力不只在并发连接,更多在高频同步、物理仿真、AI 逻辑、状态广播。玩家感知的是帧时间稳定和延迟稳定。这里的关键不是平均性能,而是抖动控制,包括线程调度隔离、频率稳定、网络隔离、拓扑固定。
低抖动业务的本质是确定性工程。这类工程做得好,体验会稳到玩家不说话。做不好,社区会替你说。
5.3 自动驾驶离线链路的关键是吞吐和成本
自动驾驶的数据工程常见痛点在 PB 级数据处理,包括多模态清洗、转码、压缩、抽帧、标注协同、仿真回放、相似度检索。GPU 训练消耗高,但训练效率取决于数据供给效率。工程上最常见的浪费,是 GPU 等数据,或者一边等一边空转。
离线链路的降本路径往往来自 CPU 预处理、压缩卸载、存储分层、调度策略,而不是减少训练轮次。
5.4 AIoT 平台的核心是连接稳定性和峰值守护
千万级设备长连接的系统面对的是持续在线、状态上报、指令下发、夜间峰值。它更接近通信系统,对网络吞吐、连接维护、稳定性、热升级能力敏感。这里的“算力”常常被网络与系统开销重新定义。
在线连接型系统的成本优化,核心是单位连接成本和故障域控制。
◆ 六、软硬协同不是口号,是一套可验证的方法
把“软硬协同”讲清楚,要回到可验证的东西,例如指标提升、成本下降、迁移复杂度降低。以业界公开信息较多的云实例升级为例,像采用新一代通用 CPU 并结合云侧卸载与调度架构的路线,通常带来三类变化。
第一类是通用负载性能提升,例如数据库、Web、Java 等工作负载在新一代实例上获得可量化提升。第二类是单位成本下降,例如同等目录价格下性能上升,或者在性能更高的同时价格不升反降。第三类是迁移门槛降低,例如不改代码就能享受到指令级加速、缓存与内存带宽提升、虚拟化开销下降等红利。
这三类变化之所以重要,是因为它们符合规模化落地的真实约束。企业可以接受渐进式升级,但很难接受大规模重构。能在不大改系统的前提下,让端到端链路更稳、更省,这类提升才会被业务买单。
结论
AI 落地进入深水区后,失败和成功的分界线开始从模型侧移到系统侧。试点阶段比的是“有没有效果”,规模化阶段比的是“能不能稳定交付,能不能把单位成本压下来”。这要求团队放下对单一硬件指标的迷信,把业务拆成可度量的链路,再用场景画像把指标、资源、架构动作对齐。
别只盯着 GPU。GPU 解决的是一段计算,场景化算力解决的是整条链路。当在线业务的尾延迟可控,离线链路的吞吐和成本可控,低抖动业务的确定性可控,AI 才会从演示走到生产,从试点走到规模化。
📢💻 【省心锐评】
规模化AI拼的是链路效率和确定性,先做场景画像和指标拆解,再谈GPU和大模型,成功率会高很多。

评论