.png)


【摘要】 探讨苹果公司与索邦大学联合研究的突破性成果——AI训练数据混合比例的科学公式。通过详尽分析"Scaling Laws for Optimal Data Mixtures"论文,揭示其理论基础、实践价值及产业影响,旨在为技术从业者提供深度洞察。
引言
人工智能的进步,离不开数据与算力的双轮驱动。过去十年,AI模型规模不断膨胀,数据集容量水涨船高,模型性能也随之跃升。然而,数据的“量”之外,“质”与“配比”同样关键。正如调酒师调制鸡尾酒,哪怕原料再好,比例失衡,终究难以成就佳酿。AI模型训练亦然,不同类型数据的混合比例,直接决定了模型的泛化能力与专用表现。
长期以来,AI研究者在数据混合比例的选择上,更多依赖经验与反复试错。缺乏科学公式,导致资源浪费与效率低下。2025年7月,索邦大学与苹果公司等团队联合发布的“Scaling Laws for Optimal Data Mixtures”(arXiv:2507.09404v1),首次为AI训练数据配比问题提供了可量化的数学公式。这一突破,不仅极大提升了训练效率,更为AI开发范式带来深远变革。
本文将系统梳理该研究的理论基础、公式原文、实验验证、应用价值与未来展望,结合行业现状与发展趋势,深度剖析其对AI开发的革命性意义。
一、理论基础与创新突破
%20拷贝.jpg)
1.1 Scaling Laws的历史与演进
1.1.1 传统Scaling Laws回顾
Scaling Laws(缩放定律)最早由OpenAI等机构提出,揭示了AI模型性能与参数量、数据量、算力之间的幂律关系。其核心观点是:
模型性能提升与参数量、数据量、算力呈现幂律递减关系。
通过小规模实验,可以预测大规模模型的表现。
经典的Scaling Laws数学表达式为:
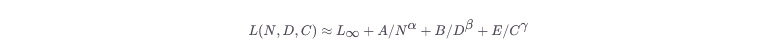
其中,L为损失,N为参数量,D为数据量,C为计算量,L∞为理论下界,A,B,E,α,β,γ为常数。
1.1.2 数据混合比例的空白
尽管Scaling Laws在参数、数据量、算力等维度取得突破,但“数据混合比例”这一关键变量长期缺乏系统研究。现实中,AI模型往往需要多种类型数据(如文本、代码、图像等)混合训练。不同配比对模型性能影响巨大,但缺乏科学公式,导致开发者只能凭经验摸索。
1.2 本研究的创新点
1.2.1 数据混合比例的Scaling Laws
本研究首次将Scaling Laws扩展到“数据混合比例”维度,提出了两类核心公式:
加性定律(Additive Law):假设数据混合比例对模型性能的影响是独立的,不随模型规模、数据量变化。
联合定律(Joint Law):考虑数据混合比例与模型规模、数据量的相互作用,能捕捉更复杂的动态变化。
1.2.2 公式原文与数学表达
研究给出的核心公式如下:
加性定律: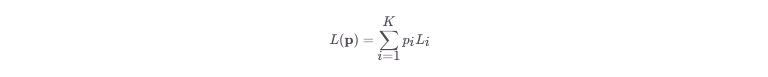
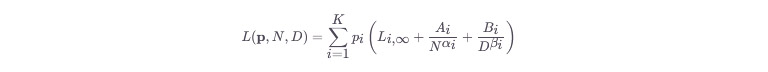
其中,p=(p1,...,pK)为各类数据的混合比例,Li为第i类数据的损失,N为模型参数量,D为数据量,Ai,Bi,αi,βi为拟合参数。
1.2.3 理论意义
该公式允许开发者通过小规模实验,拟合出最优数据混合比例,并准确预测大模型的最优配方。
极大提升了训练效率与资源利用率,为AI开发提供了科学、可预测的“配方指南”。
二、数据混合的重要性:配方为何如此关键
2.1 数据混合的本质
AI模型训练过程,类似于培养一位博学多才的学者。学者需要涉猎多领域知识,阅读科学论文、文学作品、历史记录、代码教程等。每种书籍的阅读比例,决定了其知识结构与能力表现。
2.2 传统方法的局限
传统AI训练常按数据量比例或经验分配数据类型,缺乏科学依据。
这种“随机阅读”或“按量分配”方式,往往无法获得最佳效果。
2.3 任务驱动的配比需求
不同目标任务,对数据混合比例有不同需求。例如,训练既能编程又能写作的AI助手,代码与文本数据的最优比例并非固定。
最优配比不仅与任务相关,还与模型规模、数据总量密切相关。
2.4 训练-目标不匹配现象
研究发现,针对某一任务的最优训练数据配方,通常与该任务本身数据的比例并不一致。
例如,AI在数学任务上表现最佳的训练配方,往往是数学数据与其他类型数据的特定混合,而非纯数学数据。
三、建立科学的配方公式:从经验到理论
%20拷贝.jpg)
3.1 数学框架的构建
3.1.1 配方计算器的诞生
研究团队建立了数学框架,将模型在特定任务上的性能,表示为模型规模、训练数据量和数据混合比例的函数。
这为AI训练提供了“配方计算器”,让开发者不再依赖经验,而是用公式精准调配数据。
3.1.2 幂律关系的引入
两类公式(加性定律、联合定律)均基于幂律关系,捕捉了自然界与AI领域广泛存在的规律。
幂律关系在城市人口分布、词频、股市波动等领域均有体现。
3.2 实验验证与精度
研究团队训练了数百个不同规模的模型,尝试了多种数据混合比例。
实验结果显示,公式预测模型性能的平均误差通常在1-5%之间,精度极高。
四、三大验证实验:理论到实践的跨越
4.1 大语言模型实验
4.1.1 数据集与实验设计
使用SlimPajama数据集,涵盖7个文本领域(学术、书籍、网页、代码、常识、问答、百科)。
训练模型规模从1.86亿到70亿参数,训练样本高达1500亿。
4.1.2 结果与发现
60种不同配方在不同规模模型中测试。
小模型确定的最优配方,能准确预测大模型的最优配比,验证了公式的缩放能力。
4.2 多模态模型实验
4.2.1 多模态数据的复杂性
多模态模型需同时处理文本、图像及其组合。
数据类型包括纯文本、图像-文本配对、交错多模态数据。
4.2.2 交互效应与预测能力
不同模态数据间存在复杂相互作用。
公式依然能准确预测最优数据混合比例,显示出强大普适性。
4.3 大型视觉模型实验
4.3.1 数据质量的挑战
视觉模型数据来源多样,包括互联网噪声数据、高质量标注数据、AI合成数据。
数据质量差异对模型性能影响显著。
4.3.2 公式的适用性
公式在视觉模型上同样有效,能准确预测最优数据混合比例。
五、从小规模到大规模:预测的魔力
%20拷贝.jpg)
5.1 缩放能力的核心价值
小规模实验得出的公式,可准确预测大规模模型的最优配方。
这极大降低了大模型训练的试错成本。
5.2 实际应用场景
例如,训练100亿参数的大模型,传统方法需多次大规模实验,成本高昂。
采用本研究公式,仅需在10亿参数小模型上做少量实验,即可预测大模型最优配方。
5.3 配比随规模动态变化
研究发现,最优数据混合比例会随模型规模变化。
小模型最优配方在大模型上未必最优,需动态调整。
5.4 联合定律的优势
联合定律能更好捕捉配比随规模变化的动态。
某些数据类型在大模型中变得更重要,另一些则相对次要。
六、寻找最优配方:理论到实践的优化路径
6.1 优化算法的引入
研究团队采用“镜像梯度下降”算法,智能调整数据类型比例,逐步逼近最优配方。
6.2 任务定制化配方的优势
针对特定任务优化的配方,能显著提升模型在该任务上的表现。
定制化配方并未显著牺牲模型在其他任务上的性能。
6.3 多模态配比的规模效应
随模型规模增大,文本数据的重要性提升,交错多模态数据的重要性下降。
这一发现为大规模多模态系统设计提供了指导。
七、深入分析:配方背后的科学原理
%20拷贝.jpg)
7.1 实验效率与数据量需求
仅需10-20组不同数据混合比例实验,即可拟合出可靠预测公式。
大幅降低了AI模型开发的试错成本与时间。
7.2 学习率调度的鲁棒性
公式对不同学习率调度策略(恒定、余弦等)均表现出高鲁棒性。
7.3 固定点现象与泛化能力
最优训练数据配方与目标任务数据分布通常不一致。
只用目标任务数据训练,反而不如用优化混合配方。
7.4 类比与启示
优秀网球运动员的训练,不仅仅是打网球,还需多项运动辅助,提升整体素质。
AI模型亦需多样化数据训练,提升泛化与专用能力。
八、理论基础:信息论视角的解释
8.1 损失函数的分解
模型损失可分解为目标数据分布复杂性与训练分布-目标分布差异两部分。
8.2 适应性与泛化的平衡
最优数据混合是在“适应性”与“泛化能力”之间寻找平衡。
过度聚焦损失背景信息,过度发散则主体不清。
8.3 模型规模与表达能力
随模型规模增大,表达能力增强,能从更复杂数据混合中提取有用信息。
经验丰富的“厨师”能驾驭复杂配方,新手则需简单配比。
九、应用价值与产业影响
%20拷贝.jpg)
9.1 降低训练成本
通过小模型实验预测大模型最优配方,节省约90%调优成本。
降低AI训练门槛,利好中小企业与研究机构。
9.2 推动模型专用化
定制化数据配方使小模型在特定任务上超越通用大模型。
推动AI从“大而全”向“小而精”转型,适用于医疗、金融等高精度领域。
9.3 多模态与持续学习指导
为多模态模型(文本-图像-视频)提供配比优化范式。
持续学习中,通过动态调整数据比例,缓解“灾难性遗忘”问题。
9.4 工程实践建议
开发者可参考论文公式,通过小规模实验拟合最优数据混合比例,再应用于大模型训练。
目前尚无即插即用工具,需结合自身任务与数据类型进行实验调整。
未来有望出现更多易用工具或开源框架,进一步降低使用门槛。
十、适用范围与局限性
10.1 适用模型类型
已在大语言模型、多模态模型、视觉模型三类主流架构中验证有效,显示出较强普适性。
对新兴或非Transformer架构模型,仍需进一步实验验证。
10.2 主要适用于预训练阶段
目前公式主要用于预训练,微调(如SFT、RLHF)和持续学习阶段的配方优化尚待深入研究。
10.3 数据质量量化待完善
现有公式侧重混合比例,尚未将数据质量(如噪声、信息密度)纳入量化体系。
未来需发展更完善的数据质量评估标准。
十一、未来展望:动态调整与持续优化
%20拷贝.jpg)
11.1 动态调整的可能性
未来有望实现训练过程中数据混合比例的动态调整,适应模型学习进度与任务变化。
11.2 高质量数据的重要性
数据质量与多样性将成为提升AI模型性能的关键变量。
11.3 理论到工程的转变
该研究推动AI开发从经验主义向系统工程转型,为AI训练提供科学、可预测的“配方指南”。
结论
“Scaling Laws for Optimal Data Mixtures”研究,为AI模型训练中的数据混合比例优化提供了科学、可量化的理论基础和实践路径。它不仅大幅提升了训练效率,降低了资源门槛,还为多模态、持续学习等前沿方向提供了理论指导。尽管在适用范围、数据质量量化和工具化方面仍有待完善,但其对AI开发范式的推动意义重大。开发者可结合自身需求,参考论文方法进行实验,未来可期待更多自动化、易用的配方优化工具问世。
📢💻 【省心锐评】
“数据混合从玄学变为科学,中小团队能用1/10成本逼近大厂模型效果,但数据质量评估仍是圣杯。”

评论