.png)
%20%E6%8B%B7%E8%B4%9D-hvad.jpg)

【摘要】“AI-牛顿”系统在无先验知识下,从噪声数据自主发现牛顿第二定律。该成果展示了AI从数据拟合工具向自主科学发现主体的范式转变,其核心在于可解释的符号化知识体系构建。
引言
人工智能在科学研究(AI for Science)领域的应用,长期以来主要集中在两个层面。其一是处理海量数据,加速模拟计算,如材料科学中的分子动力学模拟或气象预测中的流体力学求解。其二是识别复杂模式,进行高精度预测,AlphaFold2对蛋白质结构的精准预测便是此中典范。这些应用极大提升了科研效率,但其本质仍是作为人类科学家的“超级工具”,执行数据处理与模式匹配任务。
一个更深层次的挑战始终存在,即AI能否超越数据拟合,真正像人类科学家一样,从原始观测中提炼抽象概念,并总结出普适、简洁且可解释的物理定律。传统的深度学习模型,尽管预测能力强大,其“黑箱”特性却使其难以胜任此项任务。神经网络的权重参数无法直接映射为人类可以理解的物理公式。这构成了AI for Science领域的一道关键壁垒。
北京大学马滟青教授课题组开发的“AI-牛顿”系统,正是在这一背景下取得的突破。它并未发现全新的物理知识,其真正价值在于,它演示了一条技术路径,让AI能够在无任何物理学先验知识的“白板”状态下,仅通过观察带噪声的实验数据,自主重构出经典力学的核心框架,包括牛顿第二定律(F=ma)。这项工作被《自然》(Nature)新闻栏目长篇报道,因为它触及了AI能力边界的核心问题,即AI能否从一个高效的计算工具,演进为一个具备初步自主发现能力的“研究主体”。
🌀 一、AI for Science的范式困境与破局
%20拷贝-erlg.jpg)
在探讨“AI-牛顿”的具体实现前,有必要先厘清当前AI在科学发现领域所面临的根本性困境。这有助于我们理解这项工作的破局意义。
1.1 传统AI范式的局限性
主流的深度学习模型,本质上是高维函数拟合器。它们通过学习大规模数据集中的统计相关性,构建从输入到输出的复杂映射。这种范式在许多领域取得了巨大成功,但在科学定律发现上存在几个固有瓶颈。
1.1.1 “黑箱”与可解释性缺失
一个训练好的神经网络,其内部包含了数以亿计的参数。这些参数共同决定了模型的行为,但我们很难将它们与具体的物理意义对应起来。模型或许能精准预测一个物体未来的运动轨迹,却无法告诉你它遵循的是“F=ma”还是某个其他复杂函数。这种不可解释性对于科学发现是致命的,因为科学的核心追求不仅是“知其然”,更是“知其所以然”。
1.1.2 内插强,外推弱
深度学习模型在其训练数据的分布范围内表现优异,这个过程称为内插(Interpolation)。一旦遇到训练数据之外的新情况,其性能往往会急剧下降,这个过程称为外推(Extrapolation)。物理定律的价值恰恰在于其强大的外推能力,一个在地球上总结出的定律,同样适用于月球或更遥远的星系。依赖数据统计相关性的AI模型,很难自发获得这种普适性。
1.1.3 数据依赖与“无监督”的鸿沟
监督学习需要大量带标签的数据。在物理学中,这意味着需要预先定义好“力”、“质量”等概念,并对实验数据进行标注。这本身就违背了“自主发现”的初衷。无监督学习虽然不需要标签,但其目标通常是聚类、降维等数据结构挖掘,离发现符号化定律仍有距离。
1.2 破局之路:符号回归的复兴
要让AI发现物理定律,就需要它输出人类能理解的、简洁的数学公式,而非一堆神经网络权重。**符号回归(Symbolic Regression)**正是实现这一目标的关键技术。
与传统回归分析(如线性回归)寻找已有公式的最佳参数不同,符号回归的目标是在不预设公式结构的前提下,直接从数据中寻找能够描述数据的最佳数学表达式。
符号回归并非新技术,其概念早已存在,通常基于遗传编程(Genetic Programming)等演化算法实现。但由于其巨大的搜索空间和计算复杂度,长期以来应用受限。“AI-牛顿”的成功,在很大程度上得益于将现代AI技术与符号回归思想的巧妙结合,为其注入了新的活力。
1.3 “AI-牛顿”的破局点
“AI-牛顿”的核心贡献,在于它没有将问题简化为单纯的符号回归任务,而是构建了一套从原始数据中自动生成概念,再在概念基础上进行定律发现的系统性框架。它回答了这样一个问题,在进行符号回归之前,AI如何知道应该在哪些变量(符号)之间寻找关系?如果连“力”和“质量”的概念都不知道,又如何去发现“F=ma”?
这正是“AI-牛顿”的精妙之处,它设计了一套机制,让AI能够自主完成从**“符号”到“概念”再到“定律”**的认知跃迁。
🌀 二、“AI-牛顿”的设计哲学与核心目标
理解了技术背景,我们再来看“AI-牛顿”项目本身的设计思想。其目标非常明确,并非为了寻找新物理,而是要在一个经典的、规则清晰的“沙盒”——牛顿力学体系中,验证一个核心假设。
2.1 核心假设
AI系统能否在满足以下**三个“无”**的严苛条件下,独立重构人类已知的物理知识体系?
无人工监督:不提供任何形式的标签或答案。AI看到的就是原始数据。
无物理先验:不预先告知AI任何物理公式、概念或单位。AI的知识库中没有“力”、“能量”、“动量”这些词汇。
无特定模型偏好:系统不被强制引导去寻找特定形式(如线性或二次)的方程。
这个假设的验证,旨在回答AI能否从一个被动的“科研工具”转变为一个主动的“研究主体”。
2.2 实验环境设定
为了验证上述假设,研究团队构建了一个虚拟的“实验平台”。
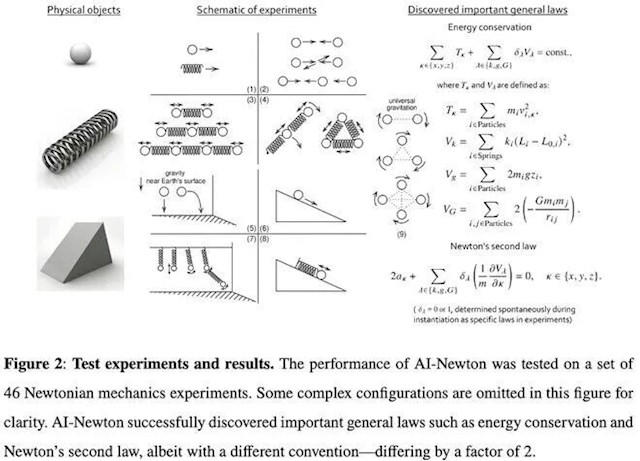
实验库:平台内置了46个典型的经典力学场景。这些场景足够简单,也足够多样,涵盖了从单体运动到多体相互作用的各种情况。例如,单摆、弹簧振子、双星系统、三体问题等。
数据输入:对于每个实验,提供给AI的输入数据极其原始。它们只包含物体随时间变化的时空坐标以及一些基本的几何信息(如物体的半径)。重要的是,这些数据还被人为加入了噪声,以模拟真实世界观测的不确定性。
禁止输入:所有高级物理概念,如质量、电荷、力、加速度、能量等,均被严格排除在输入之外。AI必须自己从坐标数据中“悟出”这些概念。
这个设定就像是让一个完全不懂物理的智能体,去观看一系列无声的、只有光点运动的录像,并要求它总结出这些光点运动背后的普适规则。
2.3 期望的输出
“AI-牛顿”的成功标准并非预测精度。即使一个黑箱模型能100%准确预测物体轨迹,在这个任务中也算失败。成功的输出必须是:
一个分层的知识体系:清晰地展示出基础符号、抽象概念和顶层定律之间的派生关系。
可解释的物理定律:输出简洁、明确的数学公式,如
F=ma,并且能说明公式中每个符号(F, m, a)是如何从原始数据中构建出来的。普适性:发现的定律必须在全部或绝大多数实验场景中都成立,而不是只适用于个别情况的“巧合”。
这个设计哲学,决定了“AI-牛顿”必须走一条与传统数据驱动AI截然不同的技术路线。
🌀 三、技术拆解:从原始数据到物理定律的构建之路
%20拷贝-vtrz.jpg)
“AI-牛顿”的实现路径,可以概括为一个三层知识架构的逐级构建过程。这个过程模仿了人类科学认知从具体观测到抽象总结的递进模式。
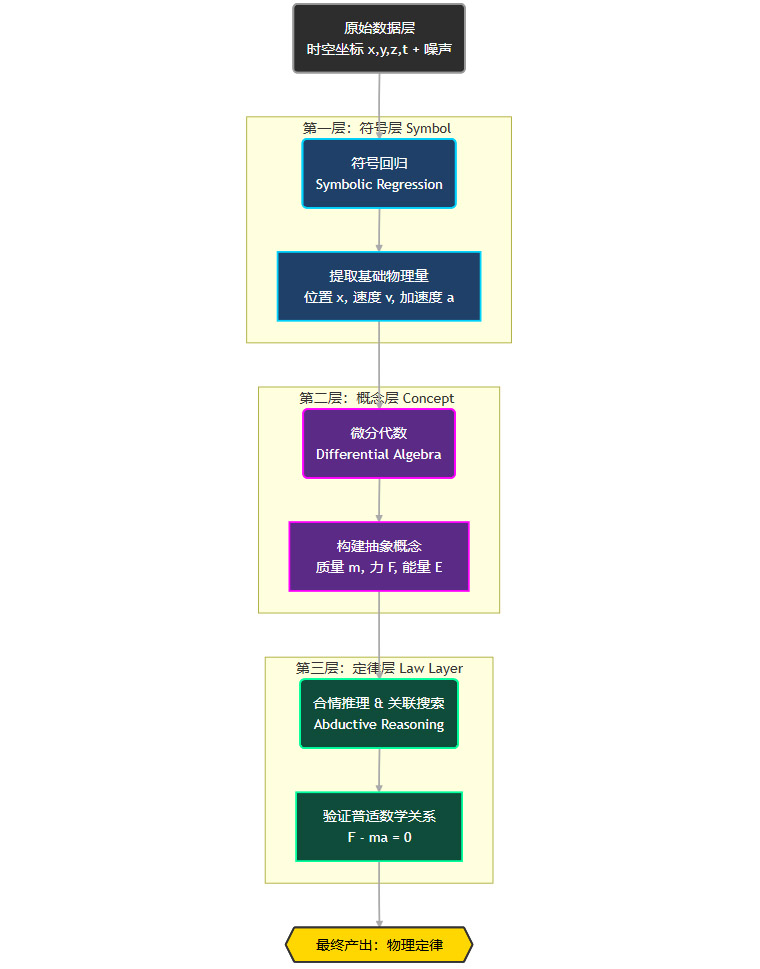
3.1 符号层(Symbol Layer):基础物理量的自动提取
这是知识构建的第一步。AI需要从离散、带噪声的时空坐标数据中,提取出有意义的基础变量。
核心技术:符号回归在这一层发挥了基础作用。系统会尝试用简单的函数(如多项式、三角函数)来拟合每个物体的坐标随时间变化的轨迹
x(t)。操作流程:
数据平滑:首先对带噪声的原始数据进行滤波或平滑处理,得到一个相对干净的轨迹函数。
符号化表达:利用符号回归算法,寻找一个简洁的数学表达式来近似这个轨迹函数。例如,对于一个抛物线运动,AI可能会找到
x(t) = v_0 * t和y(t) = y_0 - 0.5 * g * t^2这样的表达式。衍生变量生成:一旦获得了轨迹的符号表达式
r(t),就可以通过自动微分轻易地计算出其一阶导数(速度v(t))和二阶导数(加速度a(t))。
产出:这一层的最终产出是一系列基础的、与时间相关的符号变量(Symbolic Variables),包括位置、位移、速度、加速度等。这些变量构成了后续概念构建的“原子”。
3.2 概念层(Concept Layer):抽象物理量的涌现
这是“AI-牛顿”最具创造性的一步。如何从速度、加速度这些运动学量中,“无中生有”地发现像“质量”、“力”这样更本质的动力学概念?
核心技术:微分代数(Differential Algebra)和不变量发现(Invariant Discovery)。其基本思想是,在复杂的动态变化中,寻找那些保持不变的、守恒的量。这些不变量往往对应着深刻的物理概念。
操作流程:
组合与变换:系统将符号层生成的基础变量进行大量的数学组合。例如,计算
m*v,m*a,0.5*m*v^2等各种可能的表达式。这里的m最初可能只是一个待定的常数符号。寻找不变量:对这些组合表达式求时间导数
d/dt(...)。如果某个复杂的表达式C的时间导数在某个特定实验中恒等于零(或接近于零),即dC/dt ≈ 0,那么C就是该系统下的一个守恒量或不变量。概念定义:系统会发现,在很多碰撞实验中,某个形如
m1*v1 + m2*v2的量,其时间导数恒为零。系统便将这个守恒量定义为一个新的“概念”,我们人类称之为“动量”。类似地,0.5*m*v^2 + V(x)的守恒对应“能量”,而某个与加速度a成正比的量,在多体系统中表现出对称性(作用力与反作用力),则被定义为“力”。
“质量”的发现:质量
m这个概念的发现尤为巧妙。系统发现在不同物体的相互作用中,它们的加速度a1,a2之间总是存在一个恒定的比例关系,即a1 / a2 = -k。这个比例常数k在不同实验中是稳定的。系统便将这个内禀的、反映物体“惯性”的属性定义为一个概念,即质量比m2/m1。通过设定一个基准质量,所有物体的质量都可以被确定下来。
3.3 定律层(Law Layer):普适关系的搜索与确立
当概念层的各种抽象概念被构建出来后,最后一步就是寻找这些概念之间存在的、跨越所有实验场景的普适关系。
核心技术:全局关系搜索与帕累托最优(Pareto Optimality)。
操作流程:
关系假设生成:系统在所有已发现的概念(如力F、质量m、加速度a、能量E等)之间,再次利用符号回归生成海量的候选方程。例如
F = m*a,F = m*a^2,F*m = a等等。全局验证:每一个候选方程都会在全部46个实验数据上进行检验。一个公式只有在所有或绝大多数实验中都以高精度成立,才被认为是“定律”的有力候选者。
简洁性与准确性的权衡:在科学中,一个好的定律不仅要准确,还要简洁(奥卡姆剃刀原则)。系统采用帕累托前沿分析来筛选定律。它会同时优化两个目标,公式的复杂性(希望最小化)和拟合误差(希望最小化)。最终,
F=ma因为在所有候选者中达到了最佳的“简洁-准确”平衡而被筛选出来。
产出:最终输出的不仅仅是孤立的
F=ma,而是一个相互关联的定律网络。例如,系统会同时发现F = d(mv)/dt(力的另一种定义)以及能量守恒定律dE/dt = 0。这表明它把握住了整个经典力学体系的内在结构。
通过这三层架构,“AI-牛顿”完成了一次令人印象深刻的、自底向上的知识构建之旅,其过程高度模拟了人类科学史上从第谷的观测数据到开普勒定律,再到牛顿力学理论的认知飞跃。
🌀 四、“合情推理”:模拟科学家的认知路径
传统AI的“学习”过程通常是一个目标明确的优化过程,比如最小化损失函数。而人类科学家的发现过程则更像是一种探索,充满了试错、猜想和验证。“AI-牛顿”的一个核心亮点,就是它在机制上模拟了这种**“大胆猜想,小心求证”**的合情推理(Plausible Reasoning)模式。
4.1 猜想生成:巨大的假设空间
系统的“大胆猜想”阶段体现在其巨大的假设空间生成能力上。在概念层和定律层,AI并不畏惧生成看似“荒谬”的组合。
组合爆炸:通过对基础符号和概念进行加、减、乘、除、求导、积分、三角函数等一系列数学运算,系统可以生成一个天文数字级别的候选表达式库。
无偏见探索:这个过程是无偏见的。AI不会因为某个公式看起来不像人类已知的物理定律就提前放弃它。
F = log(m) * exp(a)和F = m*a在最初阶段被一视同仁。
这种暴力而无偏见的探索,使其有可能发现人类因思维定势而忽略的潜在关联。
4.2 求证筛选:严苛的检验标准
系统的“小心求证”阶段则体现在其多维度、跨场景的验证机制上。一个猜想必须通过层层考验才能“晋级”。
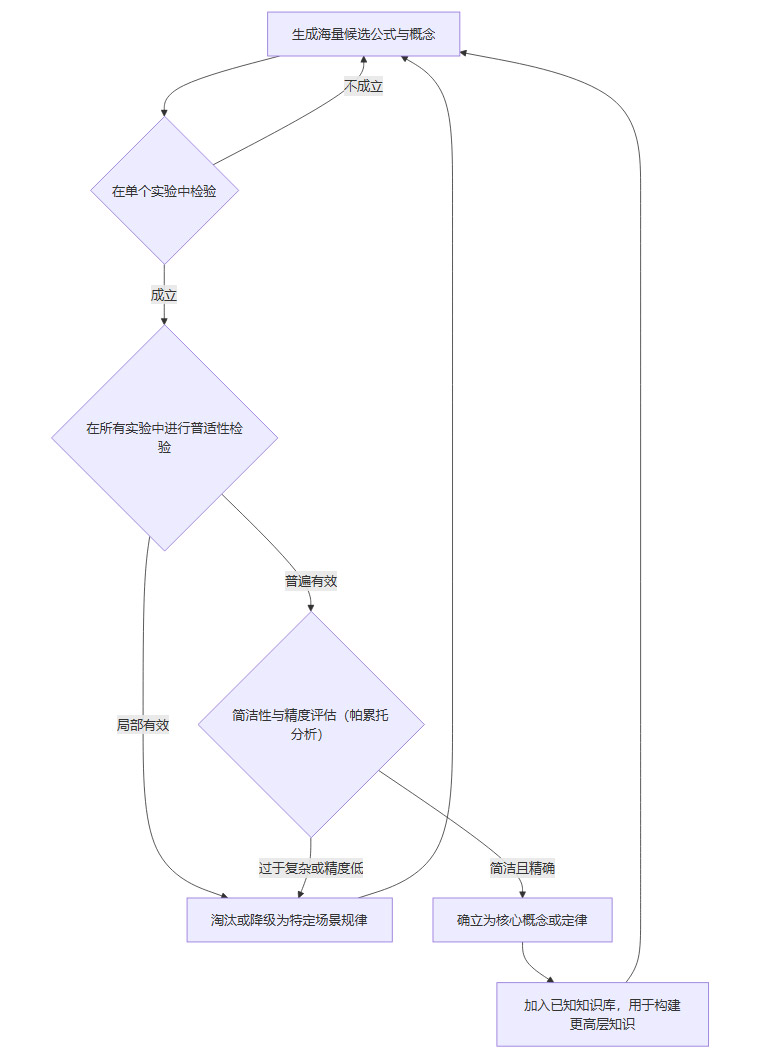
这个流程图清晰地展示了其迭代筛选的过程。
局部验证:一个公式首先要在单个实验场景内自洽。
全局验证:通过局部验证后,它必须被推广到所有46个实验中。任何只在特定条件下成立的公式都会被标记为“非普适的”。
量纲一致性:虽然系统不知道物理单位,但它通过符号的代数结构,可以隐式地保证某种程度的“量纲”一致性。例如,如果一个量被定义为
m*v,另一个被定义为m*v^2,系统知道它们是不同“种类”的量,不能直接相加。对称性与守恒律:系统还会特别关注那些体现了对称性的关系。例如,在两体相互作用中,施加在物体1上的“力”
F1和施加在物体2上的“力”F2之间如果满足F1 = -F2,这种对称性会给这个“力”的概念赋予更高的权重。
这种猜想与求证的循环,使得“AI-牛顿”的发现过程不是一个黑箱式的端到端映射,而是一个动态的、可追溯的、逻辑链条清晰的探索过程。
🌀 五、范式对比:AI-牛顿与黑箱模型的根本差异
%20拷贝-zgkb.jpg)
“AI-牛顿”的价值,不仅在于它成功推导出了F=ma,更在于它所代表的技术范式与当前主流的深度学习模型形成了鲜明对比。这种差异是根本性的,体现在输出形式、知识表示和核心目标等多个维度。
5.1 输出形式:可解释公式 vs. 不可解权重
最直观的差异在于最终的产出物。
“AI-牛顿”的输出是白箱的。它提供的是一个人类科学家可以阅读、理解、验证和复用的数学公式。这个公式本身就是一种高度凝练的知识。我们可以分析
F=ma,讨论力的本质,思考质量的起源,并将其应用到全新的问题中。传统深度学习模型的输出是黑箱的。一个训练好的神经网络,其知识固化在数百万甚至数十亿个浮点数(权重和偏置)中。它能给出精准的预测结果,但无法告诉你“为什么”。它的知识是“知其然,而不知其所以然”的隐性知识。
下表清晰地对比了二者的差异。
5.2 知识表示:结构化知识图谱 vs. 隐式统计分布
这种输出形式的差异,源于两者在内部知识表示上的根本不同。
“AI-牛顿”构建的是一个层次化的知识图谱。它的知识体系是有结构的,从底层的“符号”(位置、速度),到中间的“概念”(质量、力),再到顶层的“定律”(F=ma),存在清晰的派生和依赖关系。这种结构化的知识表示,与人类的知识体系非常相似。
深度学习模型学习的是数据的高维统计分布。它的“知识”是对训练数据内在模式的一种隐式编码。它知道“哪些输入模式倾向于对应哪些输出模式”,但这些模式之间没有明确的逻辑或因果关系表达。知识是扁平的、纠缠在一起的。
可以做一个类比。“AI-牛顿”像是在学习和编写一本物理教科书,内容有章节、有定义、有公式推导。而一个用于预测物理轨迹的神经网络,则更像一个经验丰富但无法言传身教的工匠,他能凭直觉做出正确的判断,却无法将自己的技艺总结成理论传授给他人。
5.3 核心目标:发现简洁规律 vs. 优化预测精度
两种范式的设计初衷也截然不同,这决定了它们最终的演化方向。
“AI-牛顿”的核心驱动力是“奥卡姆剃刀”原则,即在所有能解释现象的理论中,选择最简洁的那一个。它的优化目标是找到一个在复杂度和准确度之间达到最佳平衡的数学表达式。它追求的是对现象背后本质规律的压缩性描述。
深度学习的核心驱动力是最小化损失函数。它的目标是在给定的数据集上,使模型的预测值与真实值之间的误差尽可能小。它追求的是对特定任务的预测性能最大化。
这个目标差异导致,即使面对同一个问题,两者也会给出完全不同的解决方案。一个追求“理解”,一个追求“拟合”。“AI-牛顿”的工作证明,在科学发现领域,追求“理解”的范式是可行且具有巨大潜力的。
🌀 六、理性审视:局限、评价与未来航向
任何一项突破性工作,都需要放在一个客观的坐标系中进行审视。尽管“AI-牛顿”意义重大,但我们必须清醒地认识到它当前的局限性,并对其未来发展抱有理性的预期。
6.1 国际关注与客观评价
《自然》杂志新闻栏目的长篇报道,本身就说明了这项工作在科学界引发的高度关注。但需要精确理解这种关注的性质。
报道性质:这是一篇新闻专题报道(News Feature),而非经过同行评议的研究论文(Research Article)。这意味着其价值更多地体现在思想的启发性和方法的创新性上,是对一个可能开辟新方向的探索性工作的认可。
赞誉焦点:国际同行的评价,普遍聚焦于其**“AI模拟人类科学推理方式”**的创新尝试。它被看作是AI自主科学发现探索的一个重要里程碑,因为它展示了一条摆脱“黑箱拟合器”身份的技术路径,而不是因为它真的发现了什么新物理。
6.2 当前局限性:从“玩具世界”到真实宇宙
“AI-牛顿”的成功,是在一个高度简化和受控的环境中实现的。将其推广到真实、复杂的科学前沿,还面临诸多挑战。
6.2.1 场景复杂度的局限
当前的46个实验,本质上是一个经典力学的“玩具世界”。这个世界的规则清晰、变量较少、维度较低。真实的物理问题要复杂得多。
高维系统:在流体力学、等离子体物理或凝聚态物理中,系统由海量粒子组成,自由度极高。符号回归在如此高维的空间中进行搜索,将面临组合爆炸的严峻挑战。
随机性与混沌:许多真实系统(如天气系统)本质上是混沌或强随机的。从中提取确定性的简洁定律极为困难。
量子效应:量子世界的规则与宏观世界截然不同,充满了非局域性、不确定性和抽象的数学结构(如希尔伯特空间)。AI能否从实验数据中自主“发明”出算符、波函数这些抽象概念,是一个巨大的未知数。
6.2.2 “元能力”的缺失
“AI-牛顿”虽然能“做科研”,但它还不能像一个真正的人类科学家那样进行更高层次的思考。
问题提出能力:AI无法自行判断“哪个物理问题是值得研究的”。它的研究课题(这46个实验)是人类精心设计的。
实验设计能力:AI无法主动设计新的实验来验证或证伪自己的假设。它只能被动地接收人类提供的数据。
框架设定依赖:系统的符号空间(允许使用哪些数学运算符)、评价标准(如何定义“简洁”和“准确”)等顶层框架,仍然由人类设定。
可以说,当前的“AI-牛顿”是一个出色的“理论物理研究生”,能在导师设定的框架内解决问题,但还不是一个能独立开辟研究方向的“首席科学家(PI)”。
6.3 未来方向:迈向“AI科学家”操作系统
尽管存在局限,但“AI-牛顿”指明的方向令人振奋。未来的发展可能集中在以下几个方面。
6.3.1 挑战更前沿的物理领域
研究团队的下一步计划,正是将这套方法论应用于更复杂的领域,特别是量子理论。这将是对该范式能力边界的终极考验。如果AI能够从量子实验数据中,自主发现薛定谔方程或其中的某些守恒律,那将是比发现牛顿定律意义更为重大的突破。
6.3.2 融合多种AI技术:符号AI + 大语言模型
单一的技术路线可能存在瓶颈。未来的“AI科学家”很可能是一个混合系统。
大语言模型(LLM)的角色:LLM通过学习海量的科学文献,可以形成一种科学“直觉”。它可以为符号回归系统提供高质量的“猜想”或“假设”,极大地缩小搜索空间,解决组合爆炸问题。LLM负责“大胆猜想”,符号引擎负责“小心求证”。
自动化实验平台(A-Lab):将AI系统与机器人驱动的自动化实验室相结合,形成一个完整的“提出假设-设计实验-执行实验-分析数据-修正理论”的闭环。这使得AI能够真正主动地探索物理世界。
6.3.3 构建通用“AI科学家”平台
“AI-牛顿”以及清华大学等团队在相关方向上的工作,共同指向一个终极目标,即构建一个通用的、领域无关的“AI科学家”操作系统。这个平台将AI的计算能力与科学发现的逻辑框架相结合,不仅可以用于物理学,还可以应用于化学、生物学、材料科学甚至社会科学,成为未来科学研究的基础设施。
结论
“AI-牛顿”的成果,并非宣告AI已经超越了人类科学家,而是清晰地展示了一条让AI从数据处理工具进化为知识发现伙伴的技术道路。它通过模拟人类科学家的合情推理过程,成功地将不可解释的黑箱模型,转化为一个能够输出符号化、结构化、可解释知识的“白箱”系统。
这项工作最重要的启示在于,它将AI for Science的焦点从“更高精度的预测”拉回到了“更深层次的理解”。尽管当前系统仍局限于简化的经典力学世界,且高度依赖人类设定的框架,但它所开辟的“AI自主科学发现”范式,为我们探索更复杂的未知领域提供了全新的、强大的认知工具。未来,随着符号AI、大模型与自动化实验等技术的深度融合,一个真正意义上的“AI科学家”或许不再是遥远的科幻,它将与人类科学家并肩,共同拓展人类知识的边界。
📢💻 【省心锐评】
“AI-牛顿”的核心价值不在于“重新发现”了牛顿定律,而在于它验证了一条让AI从“拟合数据”走向“理解世界”的技术路径。这是从工具到主体的关键一步,预示着科学发现范式的深刻变革。

评论