.png)


【摘要】中国机器人产业正经历企业数量与融资金额的爆炸式增长,但底层技术路径仍存巨大分歧。本文深度剖析具身智能在技术路线、数据与模型、数据来源三大核心领域的“非共识”争论,并展望行业在喧嚣与分歧中走向爆发与整合的未来。
引言
“人,实在是太多了。”
在2025年盛夏的世界机器人大会上,这句略带疲惫的感叹,几乎成了每个人见面的开场白。展馆内外,三十多度的高温也无法阻挡涌动的人潮,其中不乏带着孩子前来感受未来的家庭。这股热浪,不仅仅是天气的写照,更是中国机器人赛道,尤其是人形机器人与具身智能领域关注度急剧升温的真实缩影。
这片土地上,一场关于机器人的宏大叙事正在以惊人的速度展开。一方面,是令人目不暇接的产业数据:接近百万量级的企业主体,数百亿计的资本涌入,以及一个被预测将达到万亿规模的未来市场。这一切都在宣告,中国正从一个机器人应用大国,稳步迈向产业的策源地与创新中心。
然而,在这片繁荣景象的B面,与大模型赛道初期的喧嚣相似,具身智能的航船虽已扬帆,却仍未找到那条唯一的黄金航道。在通往通用人工智能的征途上,从业者们正站在思想的十字路口,进行着一场场深刻而必要的“非共识”辩论。这些争论,关乎技术路线的终极选择,关乎发展要素的核心权重,也关乎通往智能巅峰的数据基石。
本文将深入这股产业热潮的内核,首先系统梳理中国机器人行业在企业规模、产业链与资本市场的现状,用翔实的数据勾勒出这幅波澜壮阔的产业画卷。随后,我们将聚焦于具身智能领域最核心的三大“非共识”争论——是RL+VLA的渐进改良,还是世界模型的颠覆革命?是数据为王,还是模型为本?是拥抱真实世界的粗粝,还是沉醉于虚拟仿真的完美?
最后,我们将探讨这些分歧背后的行业共识,并展望在这场机遇与挑战并存的“淘汰赛”中,中国机器人产业将如何穿越迷雾,迎来属于自己的“ChatGPT时刻”。
一、📈 产业狂飙:数字背后的中国机器人力量
%20拷贝.jpg)
中国机器人产业的崛起,并非朝夕之功,而是一场持续近十年的厚积薄发。如今,这股力量正以前所未有的加速度,从量变走向质变,其声势之浩大,足以通过一组组冷静的数字清晰感知。
1.1 企业数量的井喷式增长
衡量一个行业景气度的最直观指标,莫过于市场主体的活跃度。在这方面,中国机器人行业交出了一份惊人的答卷。
根据企查查的数据,截至2025年8月12日,中国现存的机器人相关企业已高达95.8万家,一个接近百万的庞大集群已然形成。 更值得注意的是其增长的“加速度”。仅仅在2025年的前7个月,新注册的相关企业就达到了15.28万家,同比增速飙升至惊人的43.81%。这个数字不仅轻松超越了2024年全年4.59%的平缓增速,也预示着行业进入了一个全新的爆发周期。
回顾过去十年,这条增长曲线更显陡峭与激昂。
中国机器人相关企业注册量及增速 (2015-2025年)
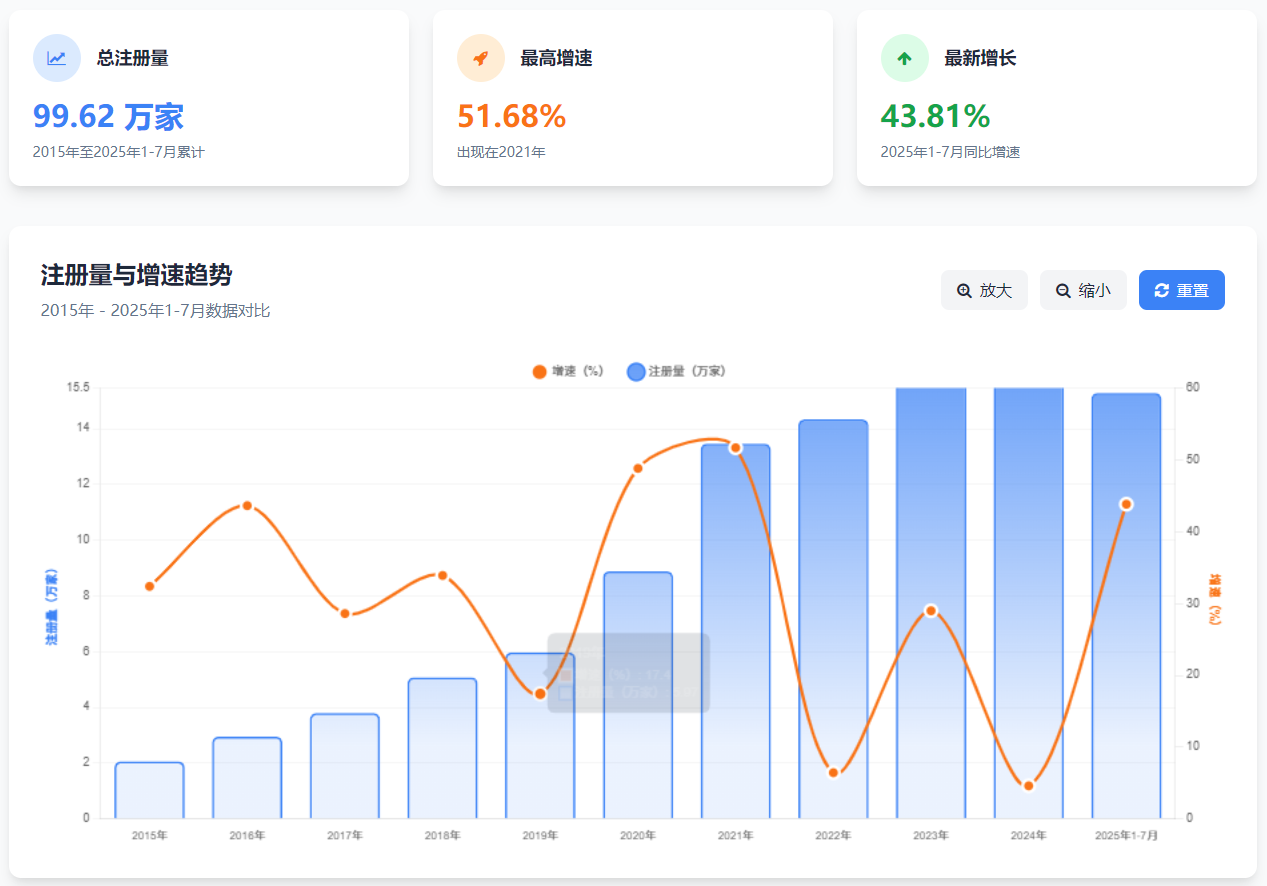
从上表可以看出,自2015年以来,除了个别年份的短暂回调,行业整体维持着高速扩张的态势。特别是在2020年和2021年,连续两年增速超过48%,这与全球范围内人工智能技术的突破与疫情催生的自动化需求密不可分。而2025年增速的再度跃升,则清晰地指向了以人形机器人和具身智能为代表的新一轮技术浪潮,正吸引着无数创业者和资本投身其中。
这种井喷式的增长,不仅意味着创业活力的迸发,更代表着一个庞大的人才库和创新生态正在快速形成。
1.2 产业链的深度与广度
如果说企业数量的增长是产业的“广度”,那么产业链的完善程度则决定了其“深度”。在这方面,中国机器人产业同样取得了长足的进步,正逐步摆脱“下游集成强、上游核心弱”的刻板印象。
一个显著的标志是,中国在全球人形机器人领域的产业链地位已举足轻重。 目前,国内已涌现出超过160家从事人形机器人整机研发的平台型公司,这一数字占据了全球总数的半壁江山。与此同时,为这些“未来战士”提供“关节”、“肌肉”和“感官”的核心零部件供应链企业也超过了600家。从高精度减速器、高性能伺服电机到复杂的传感器阵列,一个日益完善且自主可控的供应链体系正在形成。
此外,产业集群效应也日益凸显。华东地区凭借其雄厚的制造业基础、密集的科研院所和活跃的资本市场,聚集了全国近40%(39.64%)的机器人相关企业,形成了以上海、苏州、杭州、南京为核心的产业高地。珠三角地区则在机器人系统集成和商业化应用方面表现突出,两大区域遥相呼应,共同构成了中国机器人产业发展的双引擎。
这种全产业链的布局,意味着中国不仅能够“造出”机器人,更有能力在成本控制、技术迭代和市场响应速度上建立起全球性的竞争优势。
二、💰 资本热浪与市场星辰
产业的狂飙突进,离不开资本的 fueling( fueling )。2025年,资本市场对中国机器人赛道的追捧达到了前所未有的高度,它们用真金白银,为这个行业的未来投下了最坚定的信任票。
2.1 资本的“抢滩登陆”
2025年上半年,具身智能与机器人领域的投融资市场只能用“火热”来形容。
融资事件与金额双双创下新高:仅在1月至7月,相关领域的投资事件就超过了200起,已披露的融资总额更是轻松突破240亿元人民币。这一数字,已经大幅超越了2024年全年的总和,显示出资本正在加速向该赛道集结。
投资逻辑的转变:与前几年资本热衷于追逐炫酷的技术演示(Demo)不同,如今的投资者变得更加务实和挑剔。资本的关注点正清晰地从早期的技术概念验证,转向了企业的量产能力、供应链管理和商业落地潜力。 谁能率先将机器人从实验室推向工厂、仓库乃至家庭,谁就更有可能获得资本的青睐。
这种转变,标志着行业正在从讲故事的1.0时代,迈向拼落地、拼商业化的2.0时代。资本的“抢滩登陆”,不仅为企业提供了充足的弹药,也像一个加速器,推动着整个行业向着更成熟、更商业化的方向演进。
2.2 广阔无垠的市场前景
资本的狂热并非盲目,其背后是对机器人市场巨大潜力的深刻洞察。无论是短期、中期还是长期,中国乃至全球的机器人市场都展现出一条令人心潮澎湃的增长曲线。
短期(至2025年):据预测,到2025年,仅中国的人形机器人市场规模就将超过82亿元,占据全球市场份额的50%以上。这意味着,在人形机器人商业化的元年,中国就将成为全球最重要的市场。
中期(至2035年):展望十年后,行业的增长将更为可观。有机构预测,到2035年,中国人形机器人市场规模有望突破3000亿元大关,成为国民经济中一个不容忽视的新兴产业。
长期(至2050年):国际顶级投行如花旗集团的预测则更为大胆和富有想象力。他们认为,到2050年,全球人形机器人市场规模可能增长至惊人的7万亿美元(约合50万亿人民币)。届时,世界上将有近6.5亿台人形机器人,其中超过一半的产品将来自中国市场。 这是一个堪比汽车、手机的万亿级赛道,足以重塑全球经济格局。
2.3 政策的“东风”
宏大的市场前景,离不开国家战略层面的顶层设计与支持。中国政府早已将机器人产业视为推动制造业转型升级、发展新质生产力的关键。
2023年,工业和信息化部印发的《人形机器人创新发展指导意见》,无疑为整个行业注入了一剂强心针。该文件不仅系统描绘了人形机器人技术发展的路线图,更明确提出了到2025年实现初步量产,到2027年建立安全可靠的产业链供应链体系的宏伟目标。
这股强劲的政策“东风”,为行业发展提供了稳定、可预期的宏观环境,极大地提振了市场信心。它不仅引导着资本和人才的流向,也为企业在技术研发、标准制定和应用推广等方面提供了强有力的政策保障。
然而,正是在这片由资本、市场和政策共同浇灌的沃土之上,关于如何种出最丰硕果实的“方法论”之争,也变得愈发激烈和深刻。
三、🧠 思想的十字路口:具身智能的三大“非共识”
%20拷贝.jpg)
当一个行业处于爆发的前夜,喧嚣与骚动是常态,思想的碰撞与路线的争鸣更是其充满活力的标志。尽管市场一片火热,但在具身智能和人形机器人的技术内核深处,从业者们远未达成共识。这些分歧,并非细枝末节的改良,而是关乎技术范式、发展核心与实现路径的根本性问题。它们构成了当前行业最引人入胜,也最扣人心弦的篇章。
3.1 技术路径之争:VLA+RL vs. 世界模型
通往通用人工智能的道路不止一条。在具身智能领域,两条截然不同但同样雄心勃勃的技术路径正在激烈交锋。
3.1.1 VLA+RL:端到端的渐进之路
这可以被看作是当前更为主流和务实的路线。
核心理念:VLA,即视觉-语言-动作模型(Vision-Language-Action),其目标是构建一个端到端的闭环系统。机器人通过摄像头(Vision)“看”懂世界,结合人类的指令(Language)“理解”任务,然后直接输出控制电机转动的指令(Action)。
实现方式:为了让这个过程更智能、更具适应性,研究者引入了强化学习(RL)。通过在虚拟或现实环境中不断试错,机器人可以像人一样学习,根据行为的反馈(奖励或惩罚)来优化自己的策略,最终学会在复杂环境中自主决策。
优势与挑战:这条路径的优势在于其“端到端”的简洁性,理论上可以绕过传统机器人系统中复杂的模块化设计(感知、规划、控制),实现从输入到输出的直接映射,潜力巨大。然而,现实的骨感在于,目前行业还很难训练出一个性能强大且泛化能力强的机器人端到端VLA模型。 它对数据量的要求极高,训练过程极其不稳定,且“黑箱”的特性使得调试和纠错变得异常困难。
3.1.2 世界模型:构建未来的“缸中之脑”
如果说VLA+RL是在现实世界中“摸着石头过河”,那么世界模型(World Model)路线则试图在机器人的“大脑”中构建一个虚拟的“沙盘”来推演未来。
核心理念:世界模型的核心思想是,让智能体(机器人)首先学习一个关于世界如何运作的内部模型。这个模型能够根据当前的状态和即将采取的动作,预测世界在下一刻会变成什么样子。
实现方式:机器人不再是直接学习“看到什么就做什么”,而是先在自己脑海中的世界模型里进行快速、大量的模拟和规划。它可以在这个虚拟世界里“想象”出执行不同动作序列的后果,然后选择那个最优的结果,再去现实世界中执行。
优势与挑战:这条路径的最大魅力在于其数据效率和规划能力。由于可以在内部模型中进行海量“零成本”的模拟,它对真实世界交互数据的依赖大大降低。同时,基于对未来的预测,机器人可以做出更具远见的复杂规划。但其挑战同样巨大:构建一个足够精确、能够模拟复杂物理交互(如流体、柔性物体)的世界模型本身就是一项世界级的难题。 此外,模型训练所需的算力极为庞大,且如何弥合虚拟模拟与现实世界之间的“Sim-to-Real Gap”也是一个悬而未决的问题。
3.1.3 殊途同归,还是分道扬镳?
目前,这两条路线的支持者都阵容强大,且都取得了一定的进展。VLA+RL路线在一些具体的机器人操作任务上展现了潜力,而世界模型则在视频生成和简单物理预测上取得了突破。
这场争论的本质,是关于“认知”与“行为”关系的哲学思辨。VLA+RL更偏向行为主义,强调直接学习刺激-反应的联结;而世界模型则更偏向认知主义,强调内部表征和心理模拟的重要性。
未来,这两条路径可能会继续并行发展,在不同的应用场景中各自展现优势。也有一种可能,它们最终会走向融合——一个拥有世界模型的智能体,利用VLA框架来更好地连接其内部模拟与外部世界的交互。无论如何,这场技术路线的“赛马”,其结果将深刻影响未来十年具身智能的发展形态。
3.2 发展核心之辩:数据为王 vs. 模型为本
如果说技术路径的选择是战略层面的方向问题,那么在具体的战术执行中,“数据”与“模型”这两个核心要素,谁应占据更优先的地位,则引发了行业内另一场深刻的辩论。这场辩论的背后,是对当前具身智能发展主要瓶颈的不同判断。
3.2.1 “数据为王”:Scaling Law的坚定信徒
这一派观点深受过去几年大语言模型(LLM)成功经验的影响,其核心逻辑根植于“规模法则”(Scaling Law)。
核心论点:他们认为,正如ChatGPT的惊艳表现是通过“大数据+大模型+大算力”的暴力美学堆砌出来的一样,具身智能的突破同样依赖于海量、高质量、多样化的交互数据。数据是驱动模型能力提升的根本燃料,当前最主要的瓶颈在于我们远未获得足够多的有效数据。
论据支撑:
物理世界的复杂性:机器人模型与纯粹的语言模型不同,它需要理解三维空间、物理规律、物体交互等远比文本信息更复杂、更高维度的知识。这就意味着,要达到与LLM相当的泛化能力,所需的数据量可能是指数级的。
数据采集的困境:高质量的机器人交互数据获取成本极高。这不仅需要大量的机器人硬件进行7x24小时的持续工作,更困难的是如何对采集到的数据进行有效的标注和质量控制。一个错误的动作或失败的交互,其“数据毒性”可能远大于一段无意义的文本。
历史经验的佐证:无论是自动驾驶领域Waymo积累的数十亿英里数据,还是AlphaGo背后海量的棋谱学习,都证明了在复杂决策任务中,数据规模是通往成功的关键一步。
因此,在“数据为王”的信徒看来,当前行业的首要任务应该是建立高效、低成本的数据采集、清洗和管理流程,构建起驱动模型能力持续提升的“数据飞轮”。中国在这方面拥有得天独厚的优势——庞大的制造业场景提供了丰富的数据来源,而庞大的工程师红利则为数据处理提供了人力保障。 有观点甚至豪言,世界上最大的机器人数据集必将来自中国。
3.2.2 “模型为本”:对“数据崇拜”的反思
然而,行业内也有相当一部分专家对这种“数据崇拜”提出了冷静的反思。他们认为,在当前阶段,过度强调数据的重要性,可能会掩盖更深层次的问题——模型本身的能力不足。
核心论点:当前具身智能领域最大的问题,并非没有数据,而是有了数据也用不好。 现有的机器人模型架构普遍不够优秀,也不够统一,导致数据利用效率低下。因此,当务之急是进行模型架构的创新,设计出更能理解物理世界、更能高效学习的“大脑”。
论据支撑:
数据利用效率低下:很多团队发现,投入巨资采集了大量数据后,模型的性能提升却不成比例,很快就达到了瓶颈。这说明模型本身的学习能力和表征能力存在天花板。“你采了数据干嘛用?”——这个直白的质问,点出了许多团队的困境。
模型架构的“战国时代”:与语言模型领域Transformer架构一统天下的局面不同,具身智能的模型架构至今仍是百花齐放,或者说“群龙无首”。从各种CNN、RNN的变体,到引入Transformer、Diffusion Model,再到各种多模态融合的复杂设计,行业尚未找到一个公认的、能够有效扩展的“基石模型”。
软件与硬件的协同:具身智能不仅是算法问题,更是软硬件紧密耦合的系统工程。一个优秀的模型,必须能够实时处理传感器数据,并生成精确、平滑的底层控制指令。如果模型设计忽略了硬件的延迟、误差和动态特性,那么再多的数据也无法弥补这种“理论与实践的脱节”。
在“模型为本”的倡导者看来,应该优先将资源投入到模型架构的研发上,提升数据利用效率。 他们强调,未来的目标应该是在同样的数据量下,让模型学到更多;或者用更少的数据,达到同样的性能水平。只有当模型本身足够强大时,数据的价值才能被真正释放。
3.2.3 螺旋上升的共生关系
事实上,“数据”与“模型”并非非此即彼的对立关系,而是一个相互促进、螺旋上升的共生体。优秀的模型能够更高效地利用数据,而海量的数据则能激发和验证更强大的模型架构。
这场争论的现实意义在于,它引导着处于不同发展阶段、拥有不同资源禀赋的团队,根据自身情况做出战略抉择。对于拥有强大工程能力和场景优势的团队,或许可以先从构建数据壁垒入手;而对于算法能力突出的初创公司,则可能选择在模型创新上寻求单点突破。
行业普遍预测,具身智能的“ChatGPT时刻”——即模型能力发生质变、能够完成多种泛化任务的时刻——最快将在1-3年内到来。届时,很可能是一个全新的、统一的模型架构,与一个前所未有的超大规模数据集共同作用的结果。
3.3 数据来源之辩:真实世界 vs. 虚拟仿真
%20拷贝-xwlw.jpg)
在“数据是燃料”这一基本共识下,如何获取这些燃料,又催生了第三场核心争论:我们应该主要依赖从真实物理世界中采集的“真机数据”,还是可以大规模利用计算机生成的“仿真/合成数据”?
3.3.1 真机派:拥抱现实世界的复杂与不完美
这是目前行业内的主流选择,超过90%的具身智能和人形机器人企业,都将宝押在了真机数据上。
核心理念:智能的终极试炼场是真实世界,因此,训练数据也必须源于真实世界。 任何仿真环境都无法完全复刻现实世界中无穷无尽的细节、噪声和不确定性。机器人只有在真实的家庭、工厂里“摸爬滚打”,才能学会应对各种预料之外的情况。
观点陈述:“我不希望我们的机器人像赛车场里的赛车一样不停地绕圈,而希望我们的车走到真实的道路上、公开的道路上去面对、应对真实的交通和驾驶场景。” 这段来自自动驾驶领域的类比,生动地表达了真机派的核心信念。他们认为,只有进入真实世界去采集数据,才能打破具身智能的能力天花板。
优势与挑战:真机数据的最大优势在于其“保真度”,它包含了物理世界最真实的反馈。但其劣势也同样明显:成本高昂、效率低下、难以规模化,且存在安全风险。 让一台昂贵的机器人在未知环境中自由探索,本身就是一件奢侈且危险的事情。
3.3.2 仿真派:Sim2Real,通往智能的捷径?
尽管是少数派,但坚持“从仿真到现实”(Sim-to-Real)路线的企业,如银河通用、跨维智能等,却提出了一个极具诱惑力的愿景。
核心理念:在具身智能发展的初期阶段,合成数据是推动产业快速发展的关键数据资产。 我们可以利用强大的物理引擎和渲染技术,在虚拟世界中构建出无穷无尽的场景和任务,让机器人在其中进行近乎零成本、超高效率的训练。
实践案例:有公司宣称,其训练数据中99%均为合成数据,仅用1%的真实数据进行微调和“最后一公里”的对齐。他们通过自研的仿真引擎,生成了全球首个百亿级的抓取操作和柔性物体操作大数据集,并声称这使得其模型在真实环境中具备了极高的鲁棒性与泛化能力。
优势与挑战:仿真数据的优势在于成本低、效率高、规模大、安全可控,并且可以轻松实现对各种极端情况(Corner Case)的模拟。 但其核心挑战在于如何跨越“仿真与现实的鸿沟”(Sim-to-Real Gap)。仿真环境中的物理规律、物体材质、光照反射等,与现实世界总存在差异。如何让在虚拟世界中“学成”的模型,无缝迁移到现实世界中,是所有仿真派必须回答的关键问题。
3.3.3 动态平衡的艺术
这场关于数据来源的争论,本质上是在效率、成本和效果之间寻求一种动态平衡。一个越来越被接受的观点是,两者并非水火不容,而应是相辅相成的关系。
任务导向的混合策略:有专家指出,数据来源的选择不应该是人为的“拍板决定”,而应该由一套有效的机制,根据任务的复杂性来自动判断。例如,对于以“抓取”为中心的非持续性简单动作,仿真数据已经做得相当好。然而,一旦涉及到“擦桌子”、“刮胡子”这类需要持续力反馈和精细操作的复杂任务,仿真与真实效果的差距(Gap)就会变得巨大,此时就更加依赖真实数据。
“仿真基础训练 + 真机微调”:这可能成为未来的主流模式。利用仿真数据进行大规模的预训练,让模型掌握基本的物理概念和操作技能;然后,利用少量、高质量的真机数据进行微调,使其适应真实世界的噪声和不确定性。
总结来看,仿真数据为机器人提供了一个广阔而廉价的“新手村”,让它能够快速成长;而真实世界则是它必须通过的“终极考验”。如何巧妙地结合两者的优势,将是决定各家企业技术迭代速度和成本控制能力的关键。
四、🔭 喧嚣与分歧之上:行业的共识与未来
尽管在技术路径、发展核心和数据来源上存在诸多“非共识”,但这恰恰是行业充满活力、高速演进的证明。在这些激烈的辩论之下,一些更深层次的共识正在悄然形成,它们共同勾勒出中国机器人产业未来的轮廓。
4.1 “非共识”本身即是共识
行业内一个非常富有哲理的共识是:当前的“非共识”状态,本身就是最大的共识。
这表明,无论是从业者、投资者还是研究者,都清醒地认识到,具身智能和人形机器人产业仍处于技术范式远未收敛的早期阶段。大家普遍接受,通往通用机器人的道路不会是一条坦途,必然充满了探索、试错和路线的摇摆。
这种心态,使得整个行业能够以一种更加开放和包容的态度,去鼓励多元化的技术探索。无论是坚持VLA的团队,还是押注世界模型的先锋;无论是数据驱动的“大力出奇迹”,还是模型创新的“精雕细琢”;无论是拥抱现实,还是筑梦虚拟,每一种尝试都被视为对未知边界的宝贵探索。
这种“非共识的共识”,避免了行业过早地陷入技术僵化和路径依赖,为未来的颠覆性创新保留了最大的可能性。
4.2 应用场景的终极归宿
关于人形机器人“能做什么”、“该做什么”的讨论,也充满了趣味性的分歧。
表演 vs. 实干:一些企业,如宇树科技,在现阶段选择以跳舞、打拳甚至参加格斗比赛等偏娱乐化的方式,来展示其人形机器人的卓越运动能力。这不仅是绝佳的市场营销手段,也是对其硬件本体性能的极限测试。加速进化创始人甚至提出了一个浪漫的愿景:让机器人在2050年踢赢人类世界杯冠军。
进厂 vs. 入户:然而,几乎所有从业者都认同,炫技和表演只是通往终极目标的阶段性展示。行业的唯一共识在于,人形机器人的最终价值,必然体现在为社会创造实际价值上。 其商业化的路径,将遵循从工业、商业场景,逐步走向泛化需求更高的家庭环境。
“进厂打工”被视为商业化落地的第一站。在制造业、物流、仓储等结构化或半结构化场景中,人形机器人有望替代人类从事重复性、危险性的劳动。而“入户服务”,如端茶倒水、洗衣做饭,则是更遥远但更具想象空间的终极目标。
从表演到实干,从工厂到家庭,这条清晰的演进路线图,为行业的发展指明了从“秀肌肉”到“创价值”的必然方向。
4.3 “淘汰赛”与“爆发点”并存的未来
展望未来,行业普遍弥漫着一种既兴奋又焦虑的复杂情绪。
“ChatGPT时刻”的临近:多位行业领袖都做出了相似的预测——人形机器人行业已经走到了“ChatGPT时刻”的前夜,最快1-2年,最慢3-5年,就可能迎来技术和应用的质变时刻。 届时,一个统一的、端到端的智能机器人大模型可能会出现,彻底改变机器人的交互和学习方式。
残酷的“淘汰赛”:然而,黎明前的黑暗往往最为深沉。随着技术路线的逐步收敛和商业化窗口的开启,一场残酷的“淘汰赛”已不可避免。资本的耐心是有限的,市场不会给所有玩家留下足够的时间。有分析悲观地预测,在大浪淘沙的量产阶段,高达80%的人形机器人公司可能无法跨越商业化的鸿沟,最终会倒在这场马拉松的半途。
未来2-5年,行业的竞争焦点将高度集中在以下几个方面:
统一、端到端的智能机器人大模型:算法的领先优势。
更低成本、更高寿命的硬件:供应链与成本控制能力。
超大批量的制造能力:工程化与量产能力。
低成本、大规模的算力支持:基础设施的保障。
谁能在这四个维度上率先建立起综合优势,谁就最有可能在这场“百模大战”的机器人版本中胜出,成为定义下一个时代的巨头。
五、结论
中国机器人产业正站在一个波澜壮阔的时代交汇点。一方面,是接近百万家企业的庞大基数、超240亿的资本热潮、日益完善的产业链条和国家战略的强力背书,共同构筑了其黄金发展的坚实底座。放眼全球,中国在企业数量、融资规模和政策支持上均已处于领先地位。
但另一方面,深入产业肌理,我们看到的是一个在喧嚣中探索、在分歧中前行的年轻领域。具身智能在技术路径、发展核心、数据来源上的三大“非共识”争论,既是其早期发展阶段不成熟的体现,更是其充满创新活力、拒绝路径依赖的明证。正是这些思想的碰撞,在为行业积蓄着冲破技术瓶颈的强大动能。
从VLA与世界模型的路线之争,到数据与模型的权重之辩,再到真实与仿真的来源之选,这些分歧最终都将指向一个共同的目标:创造一个能够理解并与物理世界流畅交互的通用智能体。
未来已来,只是尚未均匀分布。中国机器人产业的“ChatGPT时刻”或许近在咫尺,但通往那里的道路注定不会平坦。一场关乎技术、资本、工程和商业的全面“淘汰赛”即将拉开帷幕。在这场伟大的远征中,唯有那些既能仰望星空、又能脚踏实地的企业,才能最终穿越分歧的迷雾,在全球人形机器人和具身智能的宏大叙事中,写下属于中国的辉煌篇章,实现从“量变”到“质变”的伟大跨越。
📢💻 【省心锐评】
喧嚣之下,路线之争是好事。别急着统一思想,让子弹再飞一会儿。真正的壁垒,不在于你今天选了哪条路,而在于你在这条路上能挖多深、跑多快。

评论