.png)


【摘要】本文深入探讨了多智能体协作架构在小说、论文等长文本创作领域的应用范式与核心挑战。文章系统剖析了其在任务分工、记忆管理、质量控制等方面的实现机制,并结合AutoGen、CrewAI等开源框架与RAG、MemAgent等前沿技术,详细阐述了如何突破传统大语言模型的局限。同时,文章也对协同冲突、创造力瓶颈、资源消耗等现实挑战进行了分析,并展望了多模态融合、自进化系统与上下文工程等未来发展方向,旨在为相关领域的研究者与开发者提供一份详实的技术蓝图与实践指南。
引言
在数字内容以前所未有的速度膨胀的今天,长文本创作——无论是构建一个宏大世界观的奇幻小说,撰写一篇逻辑严密的学术论文,还是编写一本内容详尽的技术手册——始终是横亘在创作者面前的一项智力与耐力的双重考验。传统的创作过程,往往伴随着灵感的枯竭、资料检索的繁琐、逻辑脉络的混乱以及风格一致性的难以维系。
近年来,大语言模型(LLM)的横空出世,如同一道曙光,为内容创作领域带来了革命性的变化。它们强大的文本生成能力,让我们看到了自动化写作的潜力。然而,当我们将目光投向动辄数万乃至数十万字的长文本时,单一LLM的局限性便暴露无遗:有限的上下文窗口导致“记忆”衰退,难以维持全局的逻辑连贯与人物弧光;生成内容时而出现的“一本正经的胡说八道”,即事实性错误,在严谨的论文或报告中是致命的;而单一模型的“思维”模式,也容易让创作陷入某种固定的范式,缺乏真正的深度与惊喜。
正是在这样的背景下,**多智能体协作架构(Multi-Agent Systems, MAS)**应运而生,它并非简单地对单一模型进行功能叠加,而是从根本上重构了创作的生产关系。它不再依赖于一个“全知全能”的超级大脑,而是模拟人类社会中高效的专家团队——有负责谋篇布局的“总编”,有深耕细分领域的“研究员”,有文笔斐然的“执笔者”,还有一丝不苟的“审校员”。这些各司其职的智能体(Agent)通过精密的协作机制,共同完成一项复杂的创作任务。
本文将带您深入这个激动人心的新领域,系统地剖析多智能体协作架构如何“分而治之”,攻克长文本创作的重重难关。我们将一同探索其内部的系统分工与协作机制,揭示其突破“遗忘曲线”的长文本处理与记忆管理秘诀,审视其保证出品质量的反馈与控制闭环,并坦诚地面对其当前面临的技术挑战与未来方向。这不仅是一次技术的巡礼,更是一场关于未来内容创作范式的深刻思考。
🚀 一、数字工坊的诞生:系统分工与协作机制
%20拷贝.jpg)
想象一下一个顶级的写作工作室。这里没有孤军奋战的作家,而是一个各怀绝技的团队。有的人擅长头脑风暴,构建故事的骨架;有的人是资料搜集专家,能从浩如烟海的信息中找到最精准的素材;有的人则拥有化腐朽为神奇的笔力,能将枯燥的提纲填充得血肉丰满。多智能体系统,正是这样一个数字化的写作工坊。
1.1 “众智成城”:智能体的角色设定与分工
多智能体系统的核心优势在于其精细化的任务分解与专业化的角色分工。一个复杂的长文本创作任务,会被一个“主控智能体”(Master Agent)或“规划智能体”(Planner Agent)拆解成一系列更小、更明确的子任务,并分配给具备特定能力的“专家智能体”(Specialist Agents)。
一个典型的长文本创作智能体团队可能包括以下角色:
首席规划师 (Chief Planner Agent): 负责理解用户的最高指示(例如,“写一部赛博朋克风格的侦探小说,主角是一个失忆的仿生人”),并生成一份详尽的、结构化的大纲,包括故事背景、主要情节线、章节划分、人物设定等。
研究分析师 (Research Analyst Agent): 当写作需要专业知识或实时信息时(如论文中的文献引用、小说中的历史背景),该智能体负责接入搜索引擎、学术数据库、API等外部工具,进行信息检索、筛选和整理,为写作提供事实依据。
核心写手团 (Core Writer Agents): 这通常不是单个智能体,而是一个集群。它们接收规划师制定好的章节大纲和研究员提供的资料,负责具体的文本扩写。可以为不同章节或不同视角分配不同的写手,甚至可以训练具有特定“笔风”(如冷峻、华丽、诙谐)的写手智能体。
事实核查官 (Fact-Checking Agent): 专门负责验证文本内容的准确性,检查引用的数据、历史事件、科学原理等是否存在错误,是保证非虚构类文本严谨性的关键。
风格编辑 (Style Editor Agent): 负责全文的语言润色、风格统一和一致性检查。它会确保从第一章到最后一章,术语使用、人物口吻、整体语调都保持一致,避免因不同写手Agent并行工作而导致的风格割裂。
质量评审员 (Quality Reviewer Agent): 扮演着“第一读者”和“批评家”的角色。它会从逻辑性、流畅度、可读性、创意性等多个维度对生成的内容进行评估和打分,并提供具体的修改建议。
这种分工模式,将单一模型难以承受的巨大认知负荷,分散到了一个结构化的系统中,不仅显著提升了创作效率,更重要的是,通过专业化分工保证了各个环节的深度和质量。Anthropic的研究表明,在处理复杂编码任务时,采用多智能体方法比单个性能最强的模型表现提升了高达90%,这一结论同样适用于复杂的文本创作。
1.2 协同的艺术:智能体间的沟通与工作流
有了分工明确的团队,如何让他们高效地协同工作,而不是各自为战、一盘散沙?这便涉及到智能体间的协作机制。目前,主流的协作模式主要有以下几种:
分层控制 (Hierarchical Control): 这是最常见的模式,类似公司的组织架构。一个“管理者”Agent负责任务的顶层规划与分解,并将子任务分派给“执行者”Agent。执行者完成后向管理者汇报,管理者再进行整合或进行下一轮任务分配。这种模式结构清晰,易于管理和追踪。
黑板系统 (Blackboard System): 想象一个公共的白板,所有智能体都可以往上面写信息,也可以读取上面的信息。在这个系统中,任务的当前状态、共享的知识、中间结果都被放在一个公共数据区(即“黑板”)。智能体们根据黑板上的信息来决定自己下一步的行动。这种模式非常灵活,适合解决那些没有固定流程、需要机会主义和探索性协作的复杂问题。
消息传递 (Message Passing): 智能体之间像人类用即时通讯软件一样,直接进行点对点或群组的对话。一个Agent可以向另一个Agent请求信息、分配任务或提供反馈。这种模式交互性强,能够实现非常动态和复杂的协商过程。
在实践中,这些模式往往是混合使用的。一个典型的长文本创作工作流可能如下面的Mermaid图所示:
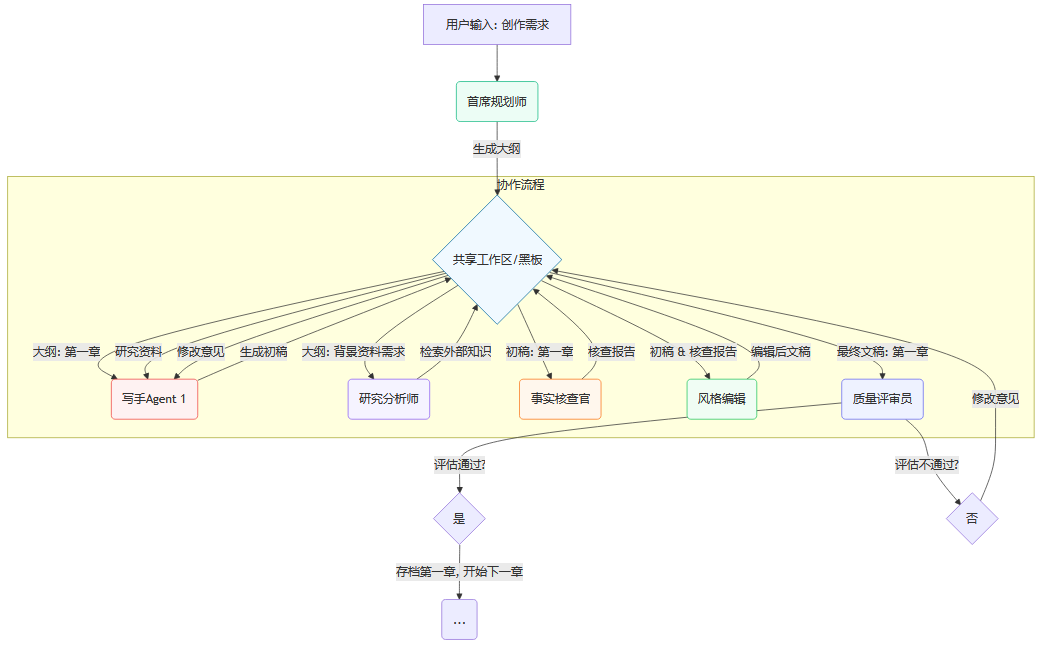
🧠 二、记忆的宫殿:长文本处理与记忆管理
如果说分工协作是多智能体系统的骨架,那么记忆管理就是其流淌的血液。长文本创作最大的敌人,莫过于“遗忘”。一个在第一章埋下的伏笔,如果在第三十章被遗忘,整个故事的精巧结构便会轰然倒塌。单一LLM受限于其固定的上下文窗口,就像一个记忆力只有几分钟的“金鱼”,难以胜任马拉松式的长文本创作。多智能体架构通过一系列精巧的设计,试图为AI构建一座永不遗忘的“记忆宫殿”。
2.1 挑战:上下文窗口的“紧箍咒”
首先,我们必须深刻理解问题的根源。大语言模型在处理文本时,依赖于一个被称为“上下文窗口”(Context Window)的机制。它只能“看到”并处理这个窗口内的文本。虽然像Claude 3的200K,甚至Gemini 1.5 Pro的1M token窗口已经非常惊人,但对于一部几十万字的鸿篇巨制来说,依然是杯水车薪。一旦信息滑出这个窗口,模型就会彻底“忘记”它。这就导致了:
情节断裂: 前文的关键线索、人物关系、特定事件被遗忘。
人设崩塌: 一个角色的性格、口吻、习惯在不同章节出现矛盾。
风格漂移: 文章的整体基调和叙事风格难以保持从一而终。
因此,有效的长时记忆管理,是多智能体系统能否成功创作长文本的生命线。
2.2 记忆的分层与架构:模拟人类大脑
为了克服这一挑战,研究者们从人类的记忆机制中汲取灵感,设计了分层的记忆系统,让智能体拥有不同类型、不同时效的记忆。
工作记忆 (Working Memory): 这相当于人类的“短期记忆”,也是智能体当前正在处理的任务的直接上下文。它通常就是LLM原生的上下文窗口。这里存放着最高优先级的信息,如当前章节的大纲、正在撰写的段落、以及最近的几次交互历史。
情节记忆 (Episodic Memory): 用于存储具体的事件和经验。在长文本创作中,这可以是一个结构化的数据库,记录着“在第三章,主角A在B地点遇到了C,并得到了关键道具D”。当智能体需要回忆特定情节时,可以通过关键词或语义检索来查询这段记忆。
语义记忆 (Semantic Memory): 存储的是关于世界的常识性知识、规则和概念。对于小说而言,这就是“世界观设定集”,包括地图、种族、历史、物理法则等。对于论文,这就是相关的理论框架和核心概念。
程序性记忆 (Procedural Memory): 存储的是“如何做某事”的技能。例如,一个“诗人Agent”可能存储了关于如何写十四行诗的规则和技巧。一个“代码文档写手Agent”则存储了如何根据代码生成清晰文档的流程。
这种分层结构,通过一个**记忆控制器(Memory Controller)**来管理。当智能体需要信息时,控制器会优先在工作记忆中查找,如果找不到,则会根据需求去情节记忆或语义记忆中进行检索,并将相关信息加载到工作记忆中,供LLM使用。
2.3 核心技术:让记忆流动起来
构建起记忆的宫殿,还需要先进的技术来填充和检索其中的宝藏。
2.3.1 检索增强生成 (RAG - Retrieval-Augmented Generation)
RAG是当前最主流、最有效的外部记忆使用技术。其核心思想是**“先检索,后生成”**。当智能体需要回答问题或生成文本时,它不直接依赖模型内部的参数化知识,而是:
查询转换: 将当前的任务或问题,转换成一个或多个精确的查询语句。
向量检索: 在一个外部的知识库(通常是向量数据库)中执行这些查询。这个知识库预先存储了所有相关的背景资料、历史章节内容、世界观设定等,并已将它们转换成了数学向量。检索过程就是寻找与查询向量最相似的文本片段。
上下文增强: 将检索到的最相关的文本片段,作为额外的上下文信息,与原始提示一起注入到LLM的上下文窗口中。
生成答案: LLM基于增强后的、信息更丰富的上下文,生成最终的文本。
通过RAG,智能体仿佛拥有了一个可以随时查阅的、容量无限的“外部大脑”。
2.3.2 记忆的压缩与蒸馏
即便有RAG,如何高效地构建和更新那个“外部大脑”也是一个挑战。随着文本越来越长,不可能把所有历史内容都原封不动地存起来。因此,记忆压缩技术至关重要。
自动摘要: 当一个章节完成后,可以由一个专门的“摘要Agent”对其进行总结,提取出关键的情节推进、人物变化、新设定等核心信息,然后将这份凝练的摘要存入情节记忆库。
记忆蒸馏: 更进一步,系统可以定期“反思”和“整理”自己的记忆。例如,将多个相关的零散记忆点,融合成一个更高级、更抽象的知识。或者,当发现两个记忆点存在冲突时,启动一个仲裁机制来解决它。
2.3.3 创新的记忆架构
学术界和工业界也在探索更具突破性的记忆架构。
谷歌的Chain-of-Agents (CoA): 这个框架将长文本处理变成一个“接力赛”。第一个Agent处理文本的第一部分,然后生成一个包含关键信息的摘要“记忆”,连同第二部分文本一起传递给下一个Agent。如此循环往复,每个Agent都站在前一个Agent的“肩膀”上,有效解决了信息在长链条中丢失的问题。
MemAgent: 这是一种非常新颖的设计,它引入了一个独立的“记忆智能体”,与“生成智能体”并行工作。当生成智能体逐字逐句地写作时,记忆智能体也在同步地“阅读”和“记忆”,它通过强化学习来决定哪些信息是关键的,需要被存入一个无限容量的外部记忆中。这种“边读边记”的机制,使其能够以近乎线性的时间复杂度处理百万级词元的超长文本,并且在问答任务中性能损失极小(例如,在处理3.5M长度的文本时,问答准确率损失小于5%),为处理真正海量的文本提供了可能。
⚙️ 三、质量的守护者:反馈、控制与迭代闭环
%20拷贝.jpg)
如果说分工与记忆是创作的引擎和油箱,那么质量控制体系就是这台精密机器的“制动系统”与“导航系统”。没有它,再强大的生成能力也可能驶向内容失控的深渊。多智能体架构的精妙之处,在于它将人类创作流程中至关重要的“审校”与“修改”环节,内化为了系统自身的、自动化的核心流程。
3.1 自动化的“编辑部”:多维度质量评估
在传统工作流中,稿件的质量依赖于人类编辑的主观判断,这不仅耗时耗力,且标准难以统一。多智能体系统则设立了一个不知疲倦、标准恒一的自动化“编辑部”,由专门的质量评估Agent(Quality Assessment Agent)或评审员Agent(Reviewer Agent)担当主力。
这些Agent的评估标准是多维度的,力求全面覆盖一份高质量长文本所需具备的要素:
逻辑一致性 (Logical Coherence): 检查文本内部是否存在前后矛盾的论点、情节冲突或不符合设定的行为。例如,在论文中,它会检查论据是否能有效支撑论点;在小说中,它会验证一个从不喝酒的角色是否突然在酒吧里畅饮。
事实准确性 (Factual Accuracy): 这是“事实核查官”的核心职责。它会利用外部工具(如搜索引擎、知识图谱)来验证文中的数据、日期、引文、科学常识等是否准确无误。
风格统一性 (Stylistic Consistency): 确保整部作品的语调、用词习惯、叙事节奏保持一致。它会捕捉到由于不同“写手Agent”介入而可能产生的风格割裂,并提出统一建议。
流畅性与可读性 (Fluency and Readability): 评估文本是否通顺、易于理解,是否存在语法错误、拗口的句子或不恰当的词汇。
任务完成度 (Task Adherence): 检查生成的内容是否严格遵循了“规划师Agent”制定的大纲和要求,没有偏离主题或遗漏要点。
这些评估Agent本身也可以是复杂的系统,它们可能基于一套严格的规则(Rule-based),也可能是一个经过大量优劣文本对比训练的机器学习模型(Model-based)。
3.2 “生成-评估-优化”的进化飞轮
仅仅发现问题是不够的,关键在于如何解决问题。多智能体系统引入了反馈修正循环(Feedback-Correction Loop),形成了一个强大的“生成-评估-优化”闭环,这也是其质量保证的核心机制。
这个流程可以被形象地看作一个不断旋转的飞轮:
生成 (Generate): “写手Agent”根据指令完成初稿。
评估 (Evaluate): “评审员Agent”和“核查官Agent”对初稿进行全面审查。
反馈 (Feedback): 如果稿件未达到预设标准,评估Agent会生成一份具体的、可执行的“修改意见报告”,明确指出问题所在(例如,“第三段的论据不足以支撑观点,请补充来自[某篇文献]的证据”或“主角的这段对话不符合其内向的性格设定”)。
修正 (Refine): “写手Agent”接收到这份报告,并根据其中的指令对原文进行修改,生成新一版的稿件。
再评估 (Re-evaluate): 修改后的稿件再次进入评估环节。
这个循环会持续进行,直到稿件的质量评分达到预设的阈值,才会被最终采纳。这个过程可以用下面的流程图清晰地展示:
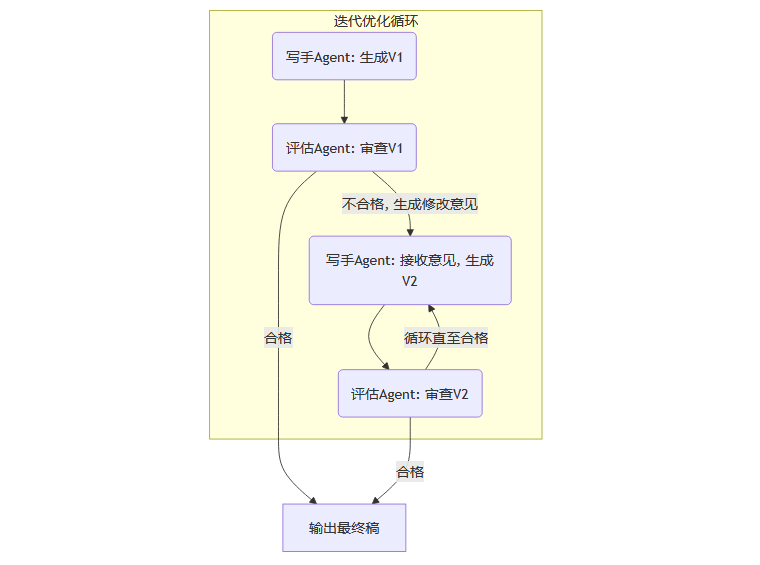
这种**多轮优化(Multi-turn Refinement)**的机制,极大地提升了最终成品的质量。它将复杂的修改任务分解为一次次小步快跑的迭代,确保了每一个细节都经得起推敲。
3.3 统一的“项目看板”:进度与状态管理
在多人协作的项目中,信息同步至关重要。想象一下,如果一个编辑还在修改第一版的草稿,而作者已经基于同样的草稿写完了第二版,混乱便不可避免。多智能体系统通过一个统一的进度与状态管理模块来避免此类问题,这个模块通常就是前文提到的“黑板系统”或一个共享数据库。
这个“项目看板”上清晰地记录着:
任务状态: 哪个章节正在撰写、哪个正在审核、哪个已经完成。
版本历史: 保存了每个章节的所有历史版本和修改记录,便于追溯和比较。
共享知识: 存放着所有Agent都需要访问的公共信息,如最终确定的世界观、人物小传、核心论点等。
通过这个共享的单一信息源(Single Source of Truth),系统确保了所有智能体都在最新的、最准确的信息基础上工作,保证了整个协作流程的节奏和信息一致性。一些前沿的实验性平台,如VirSci,已经开始模拟这种专家团队的合作模式,通过让智能体扮演不同学术角色,共同生成、评估和完善科学文献,进一步验证了这种协作模式在提升文本质量上的巨大潜力。
🧭 四、前方的迷雾与灯塔:技术挑战与未来方向
多智能体协作架构为我们描绘了一幅无比诱人的蓝图,但从蓝图走向现实的道路,依然布满了荆棘与挑战。清醒地认识这些挑战,并积极探索未来的发展方向,是推动这项技术走向成熟的必经之路。
4.1 当前航道上的暗礁:尚待解决的挑战
协同冲突与一致性难题 (Coordination Conflict & Consistency)
多智能体并行工作,如同一个房间里有太多厨师,极易产生冲突。例如,两个“写手Agent”在扩写相邻章节时,可能对一个模糊的剧情转折点做出完全不同的解读,导致情节无法衔接。或者,“风格编辑Agent”的润色意图与“事实核查官”的严谨性要求发生矛盾。如何设计出高效的冲突解决机制(Conflict Resolution Mechanism)——是通过一个更高权限的“主编Agent”来仲裁,还是通过Agent之间的协商协议来解决——是保证最终输出浑然一体的核心难题。创造力与个性化的瓶颈 (Creativity & Personalization Bottleneck)
这是当前系统最受诟病的一点。尽管多智能体系统在逻辑性和结构性上表现出色,但其生成的内容往往缺乏真正的灵魂和独特的艺术风格,容易陷入“高质量的平庸”和模板化的窠臼。它们可以很好地模仿,但难以进行真正的、源于深层感悟的创造。如何让系统不仅能满足用户明确的指令,还能在审美、情感和场景化需求上提供惊喜,是其从“高效的工匠”蜕变为“有灵感的艺术家”的关键一步。资源消耗与经济性困境 (Resource Consumption & Economic Viability)
性能的提升往往伴随着巨大的代价。多智能体系统中的每一次交互——无论是任务分配、信息查询还是反馈循环——都会消耗大量的计算资源和LLM的token。这种“通信开销”可能呈指数级增长,导致整个创作过程的成本高昂、耗时过长。如何在系统的性能、质量和经济成本之间找到一个最佳的平衡点,是决定该技术能否被广泛商业化应用的重要因素。上下文的“核心不对称性” (The Core Asymmetry of Context)
研究者发现,当前的大语言模型存在一种根本性的“不对称性”:它们在**“理解”给定的复杂上下文方面表现优异,但在“生成”**逻辑连贯、事实一致的、全新的长文本方面能力则相对有限。也就是说,让它读懂一部小说并回答问题,比让它从零写出同样质量的小说要容易得多。这揭示了当前模型在推理和规划能力上的深层局限,是需要从模型底层架构层面去突破的根本性挑战。
4.2 远方的灯塔:未来的发展方向
面对挑战,学术界和工业界并未止步,一系列前沿探索正为我们照亮前行的道路。
多模态的交响乐 (The Multimodal Symphony)
未来的长文本创作将不再局限于文字。通过引入强大的多模态大模型,智能体系统将能够处理和生成文本、图像、音频、视频等多种形式的内容。想象一个能够根据小说描述自动生成插画的“美术师Agent”,或是一个能为技术文档自动绘制流程图和数据图表的“图表工程师Agent”。国内的MiniMax公司推出的MiniMax-VL-01等模型,已经展现出强大的图文混合理解和生成能力,预示着一个内容创作的“融媒体”时代即将到来。自进化的创作灵魂 (Self-Evolving Creative Soul)
为了突破创造力的瓶颈,未来的系统将引入自进化与元学习机制。以Self-Refine框架为代表的思路,让系统具备自我反思和迭代优化的能力。智能体在完成一稿后,会自己扮演“批评家”的角色,审视自己的作品,找出不足,然后自我生成修改指令,进行优化。通过这种不断的“自我博弈”和“从经验中学习”,系统有望逐步形成自己独特的判断力和创作风格,减少对人类预设规则的依赖,真正实现能力的自我进化。系统化的上下文工程 (Systematic Context Engineering)
这可能成为下一代AI系统发展的关键。它主张我们应该超越简单的提示词工程(Prompt Engineering),转而从一个更宏观的视角,系统化地设计、管理和优化模型所需的信息流。这包括:如何最高效地构建和检索记忆库?在不同的任务阶段,应该向模型提供哪些不同类型的上下文?智能体之间的通信协议如何设计才能最节省token?“上下文工程”旨在将这些问题从“艺术”变为“科学”,为构建更强大、更高效的AI系统提供一套严谨的方法论。更智能的记忆与适应 (Smarter Memory & Adaptation)
未来的记忆系统将更加动态和智能。通过记忆蒸馏(Memory Distillation)技术,系统能自动将长期记忆中的冗余信息进行提纯,形成更高级的知识和规则。同时,通过动态示例选择(Dynamic Example Selection),系统可以根据当前任务的细微差别,从海量的知识库中动态选择最相关的几个例子(few-shot examples)来“启发”LLM,从而实现对不同风格、不同需求的快速自适应调整。
🛠️ 五、从蓝图到现实:开源工具与实践案例
%20拷贝.jpg)
理论的深度最终需要通过实践的广度来检验。幸运的是,多智能体协作架构的蓬勃发展,离不开一个日益繁荣的开源生态系统。这些工具不仅极大地降低了开发者构建和实验多智能体应用的门槛,更催生了众多富有想象力的实践案例,将曾经的理论蓝图变为了触手可及的现实。
5.1 开源工具生态概览
当前,围绕多智能体协作的开源工具已经形成了一个丰富的生态系统,它们各有侧重,可以像乐高积木一样灵活组合,以满足不同场景的需求。
5.2 典型实践案例分析
这些工具并非孤立存在,它们的真正威力在于组合与编排。下面,我们将通过几个典型的实践案例,一窥多智能体系统如何在真实场景中大显身手。
5.2.1 技术文档自动生成
在软件开发中,编写和维护技术文档是一项耗时但至关重要的工作。通过组合AutoGen和LangChain,可以构建一个高效的文档生成系统。AutoGen作为“项目经理”,负责将“为新功能X编写文档”这一宏大任务,分解为“分析代码变更”、“提取核心API”、“撰写功能描述”、“生成代码示例”等子任务。LangChain则扮演“资料库管理员”的角色,其RAG功能可以从代码库、历史文档、甚至开发者论坛中检索相关信息,为“写作Agent”提供精准的上下文。最后,一个专门的“代码核查Agent”负责验证示例代码的正确性,而“编辑Agent”则确保所有文档遵循统一的格式和术语规范,从而实现技术文档的自动化、高质量生成。
5.2.2 学术论文协同写作
学术论文对逻辑的严密性、事实的准确性和引用的规范性有着极高的要求。在此场景下,Haystack与MemGPT的组合能发挥巨大作用。一个“研究员Agent”可以利用Haystack强大的文档检索能力,对海量文献进行筛选和综述,为论文的“引言”和“相关工作”部分提供坚实基础。同时,“写作Agent”在撰写核心章节时,MemGPT负责维护全文的核心论点、实验数据和逻辑链条,确保跨章节的一致性。一个基于TextAttack的“评审Agent”可以模拟同行评审,从逻辑漏洞、论证不足等方面提出尖锐问题,触发反馈修正循环,从而极大提升论文的最终质量。
5.2.3 小说与创意写作
对于小说这类极富创造性的长文本,CrewAI和MemGPT的协作堪称天作之合。利用CrewAI,可以轻松定义一个“小说家班组”,其中包含负责构建世界观和情节大纲的“策划师Agent”,设计丰满人物形象的“角色设计师Agent”,以及多个负责具体场景和对话描写的“场景写手Agent”。而MemGPT则像一个忠实的“场记”,它将人物小传、关键情节、埋下的伏笔等核心信息存储在长期记忆中,确保当“写手Agent”在第三十章描写主角的某个决定时,依然能完美契合其在第一章就已设定的童年阴影,从而保证了人物弧光的完整和故事逻辑的自洽。
5.2.4 多模态内容生成
随着MiniMax-VL这类多模态模型的成熟,多智能体创作的边界被进一步拓宽。想象一下创作一篇关于“热带雨林生态系统”的科普文章。一个“科普作家Agent”负责生成生动有趣的文字描述。当它写到“巨嘴鸟有着色彩斑斓的巨大鸟喙”时,可以自动触发一个“插画师Agent”。该Agent调用多模态生成API,根据文本描述生成一张高质量的巨嘴鸟图片。最后,一个“排版设计师Agent”负责将文字和图片进行优雅的布局,生成一篇图文并茂的精美文章,其表现力和吸引力远非纯文本可比。
5.3 多智能体系统的部署与优化建议
要在实践中成功部署并优化一个多智能体写作系统,以下几点建议值得关注:
精准的任务拆解与Agent配置: 成功的关键始于规划。应根据最终的创作目标(如小说、论文、文档),对创作流程进行细致的、符合逻辑的拆解。在此基础上,为每个子任务配置能力最匹配的Agent。避免“一刀切”,例如,事实核查Agent应配备搜索工具,而风格编辑Agent则需要更强的语言理解能力。Agent的数量和角色也应力求精简高效,避免不必要的协同冲突和资源浪费。
深度的记忆管理与知识集成: 记忆是系统的灵魂。应根据文本的长度和复杂性,精心设计记忆管理策略。对于超长文本,必须结合MemGPT这类长时记忆工具和LangChain的RAG机制。这需要动态调整摘要的生成粒度、RAG的检索深度和知识库的更新频率,以在信息保真度和成本之间取得平衡。
严格的质量评估与反馈机制: 建立自动化的、多轮的反馈修正是保证质量的基石。可以利用TextAttack等工具构建强大的评估Agent,不仅检查语法和流畅性,更要深入评估逻辑和事实。反馈信息应具体、可执行,让写作Agent能够明确地进行优化,从而形成高效的“生成-评估-优化”飞轮。
拥抱多模态与上下文工程: 在追求更丰富内容表现力的场景下,应积极集成MiniMax-VL等多模态工具。更重要的是,要树立“上下文工程”的系统化思维,将Agent间的通信、外部知识的注入、记忆的调用视为一个整体信息流进行设计和优化,以最小的成本实现最智能的协作。
🏁 结论:迈向智能写作的协同新范式
多智能体协作架构,无疑是继大语言模型之后,人工智能在内容创作领域投下的又一颗重磅炸弹。它并非对单一模型的简单修补,而是一场深刻的范式革命。通过模拟人类专家团队的精细分工、构建仿生学的多层记忆宫殿、并建立严谨的自动化质量控制闭环,这一架构正以前所未有的力量,系统性地破解长文本创作中固有的效率、一致性与质量难题。
我们看到,从AutoGen、CrewAI等开源框架的普及,到RAG、MemGPT等前沿技术的落地,多智能体系统正在从一个遥远的理论概念,快步走入可触可及的工程实践。它让我们得以想象一个未来:在那里,撰写一部百万字的史诗巨著,或是完成一篇涉及多学科的博士论文,将不再是个人英雄主义式的苦修,而是一场人与AI智能体团队高效协同、灵感迸发的创作之旅。
当然,前路漫漫,挑战犹存。协同的冲突、创造的火花、经济的考量,以及模型自身能力的局限,都是横亘在我们面前的现实问题。然而,正如每一次技术浪潮所昭示的那样,挑战与机遇总是相伴而生。随着多模态技术的融合、自进化机制的觉醒以及上下文工程的系统化,我们有充分的理由相信,一个更高水平的“智能写作团队”正在地平线上冉冉升起。它将不仅是高效的工具,更有可能成为激发人类创造力的伙伴,共同开启一个内容生成更加智能、高效、乃至更具想象力的新纪元。
📢💻 【省心锐评】
多智能体不是简单的“人多力量大”,而是生产关系的重塑。它用架构的智慧弥补模型的短板,将创作从“炼丹”式的玄学,推向了“工程化”的科学。

评论