.png)


【摘要】构建临床就绪AI,需超越单一指标,建立算法、临床、安全、融合的多维度评测蓝图,确保系统在真实世界中能用、可用、可信。
引言
在医疗人工智能领域,一个普遍的现象是,许多模型在论文或竞赛中展现出近乎完美的性能曲线,但在部署到真实的临床环境后,却面临来自一线医生的诸多挑战。高AUC(Area Under the Curve)分数,并不能直接兑换为临床价值。模型干扰诊断节奏、缺乏解释依据、加重工作负担等问题,尖锐地指出了技术演示与临床产品之间的鸿沟。
医疗AI的临床落地,是一个复杂的系统工程,远不止于算法的精准。它要求产品在技术性能、临床效用、安全伦理、工作流融合等多个维度上,都达到高度成熟与可靠的标准。一个“临床就绪”的AI系统,必须是一个能够无缝嵌入现有诊疗流程,并被医生真正信赖的“超级助手”。
本蓝图旨在系统性地梳理一套面向临床落地的多维度、闭环评测体系。它融合了业界前沿的思考与实践,旨在为医疗AI的健康发展,提供一份兼具理论深度与工程实践意义的路线图。
一、算法性能评测:奠定技术基石
%20拷贝.jpg)
算法性能是医疗AI产品的技术内核。评测的起点,是确保模型在技术层面具备足够的稳健性与可靠性。但这绝非仅仅追求单一指标的最大化,而是要根据临床场景,做出精细化的权衡与选择。
1.1 基础分类指标的场景化解读
脱离场景谈指标,是评估工作中的首要误区。不同的临床任务,对模型的性能侧重有着截然不同的要求。
1.2 阈值策略的动态匹配
模型的输出通常是一个概率值,而最终的二元决策(如“阳性”或“阴性”)则依赖于一个预设的决策阈值。阈值的选择直接决定了模型的临床行为模式。
高召回率策略(低阈值)
场景:大规模疾病早筛、社区筛查。
目标:宁可错杀一千,不可放过一个。最大化地发现潜在患者(高TPR),即便这会带来更多的假阳性(高FPR)。后续可通过更精确的检查手段来排除假阳性。
高精确率策略(高阈值)
场景:门诊精确转诊、治疗方案决策。
目标:确保每一个阳性判断都高度可信。最大化地减少对健康人群的干扰(低FPR),避免不必要的医疗资源消耗和患者焦虑。
一个成熟的AI产品,应允许临床医生根据具体任务,灵活调整或选择预设的阈值策略。
1.3 校准度:让概率回归真实
校准度(Calibration) 衡量的是模型输出的置信度概率与真实事件发生频率的一致性。一个校准度高的模型,当它预测某结节有“90%概率为恶性”时,在大量此类预测中,恶性结节的真实比例就应该接近90%。
高AUC不等于高校准度。一个模型可能很擅长排序(将恶性排在良性前),但其输出的具体概率值可能被系统性地高估或低估。在依赖概率进行风险分层、制定干预措施的临床决策中,差的校准度是致命的。
评测工具
可靠性图 (Reliability Diagram):将预测概率分箱,对比每个箱内的平均预测概率与真实阳性率。理想情况下,点应落在对角线
y=x上。期望校准误差 (Expected Calibration Error, ECE):可靠性图上各点与对角线偏差的加权平均值,是量化校准度的核心指标,越小越好。
1.4 鲁棒性与泛化能力
实验室数据训练出的模型,必须在真实世界的复杂环境中保持性能稳定。
跨中心、跨设备验证:模型必须在来自不同医院、不同品牌型号设备、不同扫描参数的数据集上进行严格测试。这是检验其泛化能力的“试金石”。
数据漂移 (Data Drift) 监控:临床实践在不断演进,新的设备、诊断标准、患者群体的变化,都可能导致线上数据分布与训练数据分布产生差异,即“数据漂移”。必须建立持续监控机制,定期评估模型在实时数据上的表现,防止性能静默衰减。
1.5 不确定性量化:模型的“自知之明”
在高风险的医疗决策中,模型不能总是给出非黑即白的答案。当遇到其知识范围之外的“域外”(Out-of-Distribution)样本或模糊不清的边界案例时,一个安全的AI系统应该能够表达“我不确定”。
不确定性量化(Uncertainty Quantification) 旨在让模型评估自身预测的可靠性。通过设定一个不确定性阈值,当模型对某个输入的预测不确定性过高时,系统可以自动触发人工复核流程,将决策权交还给医生。这是从技术上为临床安全设置的一道重要防线。
二、临床效用评测:回归医疗价值本源
一个技术上完美的模型,若不能为临床带来实际价值,终将沦为昂贵的摆设。评测的重心必须从算法指标转向对临床效用和效率的真实世界验证。
2.1 临床效用:AI是助手还是干扰?
评测AI是否真正解决了医生的临床痛点,需要设计严谨的临床研究来回答。
研究设计:通常采用随机对照试验(RCT),将医生随机分为“AI辅助组”和“无AI对照组”,在标准化的病例集上进行诊断。
核心评测指标:
诊断性能:比较两组医生在召回率、精确率、AUC等指标上的差异。
诊断信心:通过李克特量表等工具,评估AI是否提升了医生的诊断信心,尤其对年轻或经验不足的医生。
决策影响:统计医生在参考AI结果后,修改其初始诊断的比例,并分析这些修改的正确性。
2.2 真实世界研究:从实验室到临床现场
真实世界研究(Real-World Study, RWS) 强调在真实的临床工作环境下,使用来自日常诊疗活动的数据来评估AI的性能。这与在高度筛选、净化的“实验室数据”上的测试有本质区别。
国际上如美国放射学AI委员会(Radiology AI Council)等权威机构,已将真实世界性能验证作为评估AI产品的核心标准。他们的研究发现,约有23%的AI模型在真实世界中的表现显著低于厂商宣称的指标。这凸显了独立、透明、客观的第三方评测的极端重要性。
2.3 效率与工作流:AI是减负还是增负?
即使AI能提升准确率,但如果交互繁琐、响应迟钝,反而会打断医生的工作流,成为新的负担。
效率量化指标:
时间指标:单例阅片/报告平均耗时、报告周转时间(TAT)。
操作指标:完成标准任务所需的鼠标点击次数、AI结果加载时间。
吞吐量:单位时间内处理的患者数量。
主观易用性评估:
系统可用性量表 (SUS):标准化的10项问卷,快速评估用户的主观易-用性感受。
半结构化访谈:深入挖掘医生在使用过程中的具体痛点,如“AI的标注框是否遮挡了关键解剖结构?”“交互逻辑是否符合阅片习惯?”
2.4 诊断逻辑与时序推理
临床诊断是一个复杂的逻辑推理过程,而非简单的特征匹配。模型必须能够理解症状之间的因果关系和时间演变。
时序推理评测:构建“时序最小对立体”评测集。例如,提供两个描述几乎完全相同,仅在时间或趋势词上有细微差异的病例(如“持续一周的钝痛,今日突发刺痛” vs “持续一周的刺痛”),检验模型是否能捕捉到这种关键的动态变化。
因果逻辑评测:
由临床专家构建目标疾病的“症状因果图”,明确症状之间的因果、伴随关系。
利用思维链(Chain-of-Thought, CoT) 等技术,提示模型在给出诊断的同时,输出其推理路径。
将模型输出的推理路径与专家的“因果图”进行图论上的相似度匹配,评估其诊断逻辑的临床一致性。
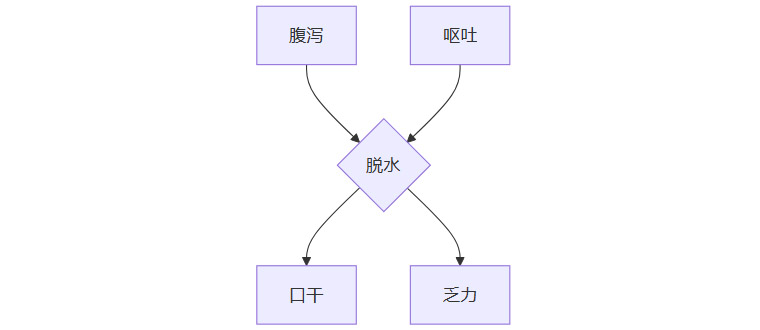
上图展示了一个简化的症状因果图。模型应理解“腹泻”和“呕吐”是“乏力”的间接原因,而非三个独立的、同等权重的症状。
2.5 互操作性:打破数据孤岛
AI系统不能是一个孤立的“黑盒”,必须能够与医院现有的信息系统(如HIS、EHR、PACS)进行高效、标准化的数据交换。
数据标准:支持 HL7 FHIR(用于临床文本数据)、DICOM(用于医学影像)等国际标准,是实现互操作性的基础。
技术架构:采用 RESTful API 和事件订阅机制,支持实时数据推送与批量数据处理,确保AI分析能及时响应临床事件。
三、安全与伦理:构建可信赖的AI防线
%20拷贝.jpg)
在医疗这个高风险领域,安全与伦理是不可逾越的底线。一个可信赖的AI,必须是透明、可解释、风险可控的。
3.1 可解释性:打开“黑箱”,建立信任
医生需要理解AI做出判断的理由,才能在人机协作中建立信任。
解释的有效性:可解释性(XAI)的评测,不应只停留在是否提供了热力图(Saliency Map)等可视化功能。更重要的是评估:
忠实度 (Fidelity):解释是否真实反映了模型的内部决策逻辑?
临床意义 (Clinical Meaningfulness):解释是否能对应到具体的解剖结构或病理特征,对医生的诊断有无实际帮助?
反事实解释 (Counterfactual Explanations):提供“如果输入的某个特征发生何种最小改变,模型的预测就会翻转”的解释。这能帮助医生更深刻地理解模型的决策边界。
3.2 失败模式与效应分析 (FMEA)
FMEA (Failure Mode and Effects Analysis) 是一种系统性的、前瞻性的风险管理方法,旨在主动识别、分析并缓解系统所有环节的潜在失败模式。
识别潜在失败模式:跨职能团队(包括算法工程师、产品经理、临床医生)共同脑暴所有可能的风险点,覆盖算法、人机交互、数据流转等全链路。
风险量化:对每个失败模式,从三个维度进行打分(1-10分):
严重性 (S - Severity):失败发生后对患者的危害程度。
发生率 (O - Occurrence):失败发生的可能性。
可探测性 (D - Detection):失败发生前或发生时被检测到的可能性。
计算风险优先级数 (RPN):
RPN = S × O × D。RPN值越高,风险优先级越高。制定缓解措施:对高RPN项,必须制定并执行强制性的风险缓解措施,如在产品设计中增加二次确认、设置警报阈值、加强医生培训等。
这是一个动态迭代的过程,需在产品全生命周期中持续进行。
3.3 安全性能与合规
安全测试:建立统一的测试框架,覆盖数据安全(如隐私保护)、算法安全(如对抗攻击鲁棒性)、功能稳定性、高并发压力场景等。
伦理原则:遵循患者隐私保护、公平性(避免对特定人群的偏见)、透明性、责任归属等核心伦理原则,并建立常态化的伦理审查机制。
变更控制:遵循FDA的**全生命周期方法(TPLC)和预定变更控制计划(PCCP)**等监管理念,对模型的任何更新(无论是数据、算法还是性能优化)都进行严格的风险评估、验证和文档记录,确保变更的安全可控与可追溯。
四、临床融合与经济价值:实现可持续落地
一个AI产品最终的成败,取决于它能否真正融入复杂的临床工作流,并为医疗系统带来可衡量的价值。
4.1 工作流融合度
AI的引入,目标是成为医生工作流程中的“催化剂”,而非“绊脚石”。
信息呈现:AI的分析结果呈现是否清晰、直观、无歧义?关键信息是否被有效突出?过多的低优先级警报是否会导致“警报疲劳”,反而降低医生的警觉性?
操作流畅性:医生调用AI、查看结果、进行交互(如确认、修改、拒绝)的操作是否简便快捷?是否增加了不必要的点击和等待?
场景匹配度:AI的功能是否与医生的实际工作步骤(如初筛、精读、会诊、报告书写)精准匹配?它是在医生最需要帮助的节点出现,还是生硬地打断了原有的工作节奏?
4.2 经济价值评估
对于医院管理者和医保支付方而言,引入AI必须有明确的投资回报率(ROI)。
成本效益分析:量化评估引入AI后,在整个诊疗路径中节省的成本(如减少不必要检查、缩短住院日、降低人力成本)与采购、部署、维护AI本身的成本之间的关系。
系统级影响预测:基于试点数据,预测在更大规模的医疗机构或区域内全面部署该AI产品后,对总体医疗支出、患者结局、医疗资源分配的宏观影响。
五、面向未来的评测演进:拥抱生成式AI
%20拷贝.jpg)
随着技术的发展,特别是生成式AI在医疗领域的应用日益广泛,我们的评测框架也需要不断演进。
5.1 生成式AI的评测新维度
当AI从一个“识别器”进化为一个“生成器”(如自动生成影像报告、医患对话摘要),传统的评测指标已不足以全面衡量其质量。必须引入新的评测维度:
知识溯源与事实一致性:模型生成的内容,其关键信息点是否能准确溯源到原始输入(如影像、病历)?是否存在“幻觉”(Hallucination),即捏造事实?
临床逻辑与安全性:生成的报告或建议,是否符合临床逻辑和诊疗指南?是否存在可能误导医生、危害患者安全的表述?
沟通质量与同理心:在模拟医患对话等场景中,模型生成的语言是否清晰、易懂、富有同理心,能否有效传递信息并安抚患者情绪?
5.2 新兴评测基准与联盟
为了应对这些新挑战,行业内已经出现了一批专门针对医疗大模型的评测基准。
OpenAI HealthBench:通过模拟真实临床场景中的开放式问题,评估模型在医学知识、推理能力、沟通技巧等方面的综合表现。
GenMedicalEval:由上海AI实验室等机构推出,专注于评估医疗大模型在中文环境下的能力,覆盖了从医学知识问答到复杂病例分析的多个维度。
未来,建立跨国、跨机构的医疗AI评估联盟,共享标准化的评测数据集和最佳实践,将是推动行业规范化、高质量发展的关键一步。
六、落地闭环:从蓝图到治理流程
将上述评测蓝图转化为可执行的治理流程,是确保医疗AI产品持续安全、有效运行的保障。
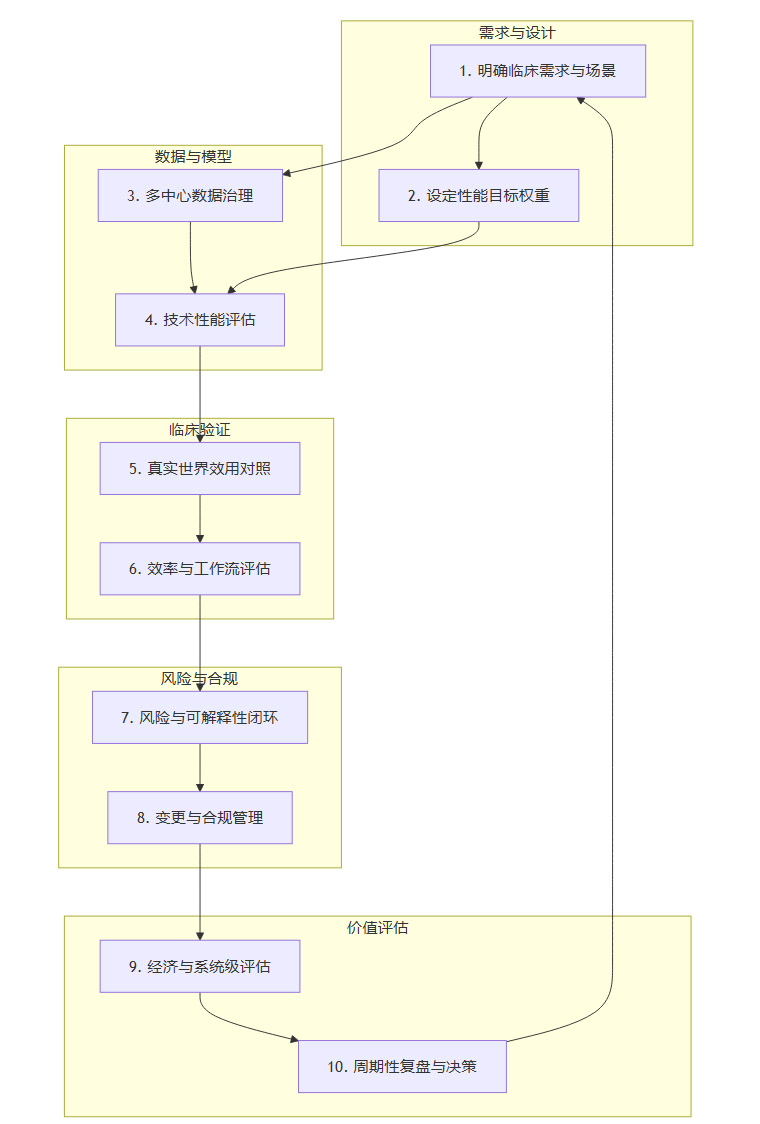
上图展示了一个医疗AI产品从需求定义到持续运营的闭环治理流程。评测贯穿于每一个环节,形成持续反馈与优化的动力。
结论
医疗AI的成功,最终不取决于单一的AUC分数,而在于其面向临床的综合可信度。构建一个“临床就绪”的AI系统,需要我们超越对算法性能的孤立追求,建立一个覆盖技术、临床、安全、融合四大维度的整体评测蓝图。
通过严谨的多维度指标、基于真实世界证据的验证、前瞻性的风险闭环管理,以及与临床工作流的深度整合,我们才能将AI从一个技术演示,真正锻造为医生的“超级助手”。随着生成式AI等新技术的涌现,评测体系本身也需要保持开放与演进。行业协作与标准化的不断深化,将是推动医疗AI实现其普惠价值、迈向可持续发展的必由之路。
📢💻 【省心锐评】
医疗AI落地,始于算法,成于临床,安于伦理,终于融合。这套评测蓝图,是连接技术理想与临床现实的桥梁,更是构建可信赖AI的工程手册。

评论