.png)
%20%E6%8B%B7%E8%B4%9D-ugjh.jpg)

【摘要】OpenAI推出“公司知识”功能,将ChatGPT升级为企业级知识引擎。通过整合内部数据源,提供可追溯、附带引用的精准回答,重塑企业信息检索与决策流程。
引言
企业内部,信息如星辰散落。它们分布在Slack的频道、Google Drive的文件夹、GitHub的代码仓库以及无数的邮件和文档中。员工寻找一份准确的资料,往往如同大海捞针,耗费大量时间与精力。这种信息孤岛现象,是长期困扰现代企业知识管理的顽疾。
OpenAI于2023年10月23日正式推出的“公司知识”(Company Knowledge)功能,正是为了破解这一难题。该功能直接面向Business、Enterprise及Edu用户,旨在将通用的ChatGPT模型,转变为一个深度理解特定企业内部知识的专属AI助理。它不再仅仅是一个外部信息查询工具,而是成为企业内部知识的“活字典”和“智能中枢”。
此举标志着大型语言模型(LLM)在企业应用领域迈出了关键一步。它不再满足于生成通用内容,而是开始深入企业工作流的核心,通过提供可信、可追溯、上下文感知的答案,直接赋能团队协作与业务决策。这不仅是一次功能升级,更预示着企业知识管理范式的深刻变革。
一、 功能解构:从通用AI到企业专属知识中枢
%20拷贝-dzpx.jpg)
“公司知识”功能的核心设计思想,是将外部的通用智能与企业内部的私有知识进行安全、高效的融合。它构建了一个全新的交互范式,让AI能够基于企业自身的真实数据进行推理和回答。
1.1 核心定位与目标用户
该功能精准定位于需要处理大量内部信息、并对信息准确性与安全性有高度要求的组织。
功能定位:一个企业级的对话式知识搜索引擎与智能问答平台。它并非要取代现有的知识库,而是作为一层智能“胶水”,将分散的知识源粘合起来,提供统一的、智能化的访问入口。
目标用户:
Business(商业版)用户:中小型团队,希望提升信息检索效率,快速响应客户与市场变化。
Enterprise(企业版)用户:大型企业,面临复杂的知识管理、严格的安全合规要求,需要强大的AI能力赋能全员。
Edu(教育版)用户:教育机构,用于整合学术资源、管理行政文档,为师生提供便捷的信息服务。
1.2 价值主张:解决企业知识管理的“最后一公里”
传统知识管理工具善于“存储”,但在“检索”与“应用”上存在天然短板。员工需要知道去哪里找、用什么关键词搜,这个过程本身就充满了摩擦。“公司知识”功能的核心价值,正是打通这“最后一公里”。
它通过自然语言交互,将“人找知识”的模式,转变为**“知识找人”**。用户只需提出问题,系统便能自动理解意图,跨越多个数据源进行检索、整合、提炼,最终生成直观的答案。这极大地降低了知识获取的门槛,让每个员工都能平等、高效地利用企业沉淀的集体智慧。
1.3 关键特性:可追溯性与引用机制
在企业环境中,答案的可信度至关重要。一个无法验证来源的AI回答,不仅没有价值,甚至可能带来风险。“公司知识”功能深刻理解这一点,将可追溯性作为其设计的基石。
答案附带引用:系统生成的每一条关键信息,都会明确标注其来源。这些引用并非简单的链接,而是包含具体内容片段的“证据”。
一键跳转原文:用户可以点击引用,直接跳转到Slack的某条消息、Google Docs的特定段落或SharePoint的某个文档。这确保了信息的透明与可验证性。
过程可视化:在生成答案的过程中,系统侧边栏会实时展示其检索过程,包括正在查询哪些应用、找到了哪些相关文档。
这一机制彻底改变了AI回答的“黑箱”属性,使其成为一个可靠、可审计的工具,为在严肃的商业决策中应用AI提供了信任基础。
二、 技术架构与实现原理剖析
“公司知识”功能的背后,是一套精密的、专为企业场景设计的技术架构。它巧妙地结合了数据连接、检索增强生成(RAG)以及先进的大语言模型,同时将企业级的安全与权限控制贯穿始终。
2.1 数据整合层:连接器的设计与实现
功能的第一步是连接数据。这依赖于一个灵活、可扩展的数据连接器(Connector)框架。
授权与认证:首次连接应用(如Google Drive)时,系统会通过 OAuth 2.0 等标准协议引导用户完成授权。此过程确保了ChatGPT仅能以该用户的身份访问数据,完全遵循用户在源应用中已有的权限设定。
API集成:连接器通过调用各个应用(Slack, GitHub等)的官方API来拉取数据。这些API通常支持增量同步,可以高效地获取最新信息,而无需每次都进行全量扫描。
非结构化数据处理:拉取到的数据类型多样,包括文档(.docx, .pdf)、消息流、代码、工单等。系统会对这些非结构化数据进行预处理,包括文本提取、格式清洗、元数据(如作者、时间戳、来源链接)标记等,为后续的检索做好准备。
2.2 检索增强生成(RAG)的核心应用
单纯将企业数据作为训练语料喂给LLM,既不安全也不高效。“公司知识”功能的技术核心是检索增强生成(Retrieval-Augmented Generation, RAG)。这是一种让LLM在回答问题时,能够参考外部知识库的先进技术。
其工作流程可以分解为以下几个步骤,我们可以用一个流程图来清晰展示。
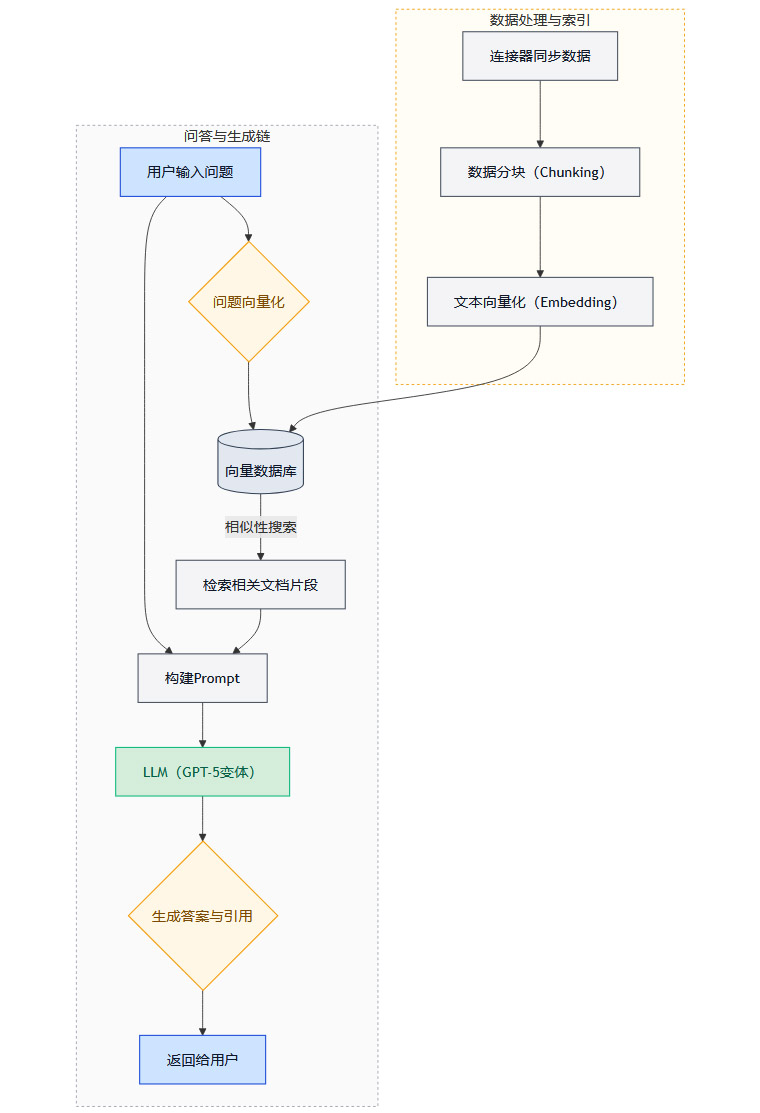
数据索引(离线/准实时):
数据分块 (Chunking):系统将同步来的长文档(如一份几十页的PDF报告)切分成更小的、有意义的语义块(Chunks)。这样做的好处是,检索时可以更精确地定位到与问题最相关的具体段落。
文本向量化 (Embedding):使用一个文本嵌入模型(如OpenAI自家的Embedding模型),将每个文本块转换成一个高维数学向量。这个向量可以被认为是该文本块在“语义空间”中的坐标。
构建向量索引:将所有文本块的向量存储在一个专门的向量数据库中。这个数据库能够极快地执行相似性搜索。
查询处理(实时):
问题向量化:当用户提出问题时,系统使用相同的嵌入模型将问题也转换成一个向量。
相似性搜索:在向量数据库中,搜索与问题向量“距离”最近(即语义最相似)的若干个文本块向量。
检索文档片段:根据搜索结果,从原始数据中找出对应的文本块。这些文本块就是与问题最相关的“上下文”或“背景知识”。
生成答案:
构建Prompt:系统将用户的原始问题和检索到的多个文档片段,共同组合成一个复杂的提示(Prompt)。这个Prompt的大致结构是:“请基于以下背景信息:[文档片段1]、[文档片段2]... 来回答这个问题:[用户原始问题]”。
LLM生成:将构建好的Prompt发送给底层的大语言模型(文章中提及的GPT-5或其企业版变体)。LLM会基于提供的上下文信息来生成答案,而不是依赖其内部的通用知识。
生成引用:由于LLM的回答是基于特定的文档片段生成的,系统可以精确地追踪到是哪个片段贡献了答案的哪部分内容,从而生成准确、可点击的引用。
RAG架构的优势在于,它将LLM的推理能力与企业实时、准确的数据结合起来,有效减少了模型“幻觉”(即编造事实),并实现了答案的可追溯性。
2.3 GPT-5模型(或其变体)的角色
文章中提及该功能依托“新版GPT-5模型”。虽然GPT-5尚未公开发布,但我们可以推断,这里指的是一个在长上下文理解、信息综合、遵循指令等方面表现更为出色的高级模型。
长上下文处理能力:RAG检索出的文档片段可能很多,组合成的Prompt会非常长。一个能处理超长上下文的模型,可以更全面地理解背景信息,生成更连贯、准确的答案。
信息综合与提炼:模型需要从多个可能存在冲突或重复的来源中,提炼出最核心、最准确的信息,并以结构化的方式呈现。
指令遵循能力:模型必须严格遵循“只使用给定信息回答”的指令,避免引入外部无关知识,这是保证答案忠实于企业数据的关键。
2.4 引用生成与溯源机制的技术链路
引用生成是RAG流程的自然延伸,其技术链路如下:
元数据绑定:在数据索引阶段,每个文本块都与其元数据(如文件名、URL、作者、章节等)牢固绑定。
来源追踪:在LLM生成答案时,系统会通过注意力机制或其他技术手段,追踪到生成答案的每个词或句子,主要依赖于输入Prompt中的哪些文本块。
引用构建:当答案生成完毕,系统会整理这些被“引用”的文本块,提取其元数据和内容片段,并将其附加在答案的相应位置。
前端呈现:前端界面将这些引用信息渲染成可点击的链接或卡片,用户点击后即可通过元数据中的URL跳转到原始位置。
这个闭环设计,确保了从数据源到最终答案的每一环都是透明和可验证的。
三、 应用场景深度实践
%20拷贝-yxmt.jpg)
“公司知识”功能的价值体现在其对企业各类工作场景的深度渗透。它不仅仅是一个问答机器人,更是一个能够融入复杂工作流的生产力工具。
3.1 日常运营与流程自动化
这类场景的特点是高频、标准化,是AI最容易产生降本增效价值的领域。
制度与流程问答:
传统方式:员工在内部Wiki、OA系统或企业群里反复询问“如何提交报销申请?”、“新员工的电脑权限如何开通?”。HR或IT人员需要重复回答。
赋能后:员工直接向ChatGPT提问,系统能从最新的制度文档或SharePoint页面中提取准确流程,并以步骤列表的形式清晰呈现,甚至附上申请链接。
内部信息查询:
传统方式:查询“上季度华东区的销售数据报告在哪?”需要翻找邮件、共享文件夹,效率低下。
赋能后:直接提问,系统可定位到Google Drive中的具体报告文件,并给出摘要和链接。
3.2 跨部门协作与项目管理
这类场景涉及信息同步与整合,是提升团队协作效率的关键。
会议筹备:
传统方式:项目经理需要手动从Slack频道里翻找讨论记录,从邮件里找客户反馈,从Google Docs里看上次的会议纪要,耗时数小时来准备一次重要的客户会议。
赋能后:输入“为明天与ABC公司的会议生成一份简报”,系统自动整合来自Slack、客户邮件、Google Docs通话记录及Intercom工单的最新动态,在几分钟内生成一份包含背景、议题、待办事项和关键风险点的会议简报。
工程协作:
传统方式:版本发布前,技术负责人需要手动检查GitHub的待办项(Issues)、Linear/Jira的工单,并回顾Slack工程频道的讨论,以确定还有哪些未解决的问题。
赋能后:提问“总结一下v2.5版本发布前所有未关闭的P0级问题和相关讨论”,系统能自动分析GitHub、Linear和Slack的数据,归纳出未解决的关键问题、负责人以及相关的技术讨论摘要,极大提升了发布决策的效率和准确性。
3.3 业务分析与战略决策支持
这是该功能最高价值的应用场景,AI从执行工具转变为决策辅助工具。
产品路线图制定:
传统方式:产品经理需要定期收集、整理来自不同渠道的客户反馈,如Slack的#feedback频道、用户调研问卷、客服工单等,然后手动进行分类、提炼,过程繁琐且容易遗漏。
赋能后:可以提出指令“将过去一个月所有渠道的客户反馈,按功能模块(如UI、性能、新功能建议)进行分类,并总结出Top 3的用户痛点”,系统能将非结构化的反馈数据转化为结构化的战略输入,为产品路线图的制定提供强有力的数据支持。
市场活动复盘:
传统方式:市场运营人员需要从HubSpot导出联系人数据,从Google Docs整理活动策划文档,从邮件中汇总媒体反馈,手动撰写活动绩效总结报告。
赋能后:通过“基于HubSpot的线索增长数据、项目文档和媒体邮件,生成本次‘秋季新品发布会’的绩效总结报告”,系统能快速提取关键指标(KPIs)、活动亮点、待改进点,自动生成一份数据详实的复盘报告初稿。
3.4 场景应用对比分析
为了更直观地展示其带来的变革,我们可以通过一个表格进行对比。
四、 企业级安全与合规体系
对于任何希望在企业内部署AI工具的组织而言,安全与合规都是不可逾越的红线。OpenAI显然对此有充分的准备,并围绕“公司知识”功能构建了一套多层次、企业级的安全保障体系。
4.1 权限继承与数据隔离
这是整个安全体系的基石,遵循最小权限原则。
严格的权限继承:该功能不会创建一个拥有超级权限的“上帝视角”。ChatGPT访问任何数据的权限,都与操作它的那个用户完全一致。如果一个用户在Google Drive中无权查看某个文件夹,那么通过ChatGPT他也绝对无法访问其中的内容。
数据访问在用户侧:从技术实现上,数据的访问请求是以用户的身份凭证(通过OAuth Token)发起的。这意味着所有访问行为都会在源应用(如Google Drive, SharePoint)中留下该用户的审计日志,完全符合企业现有的IT管控策略。
无数据交叉污染:不同用户、不同企业之间的数据是物理隔离和逻辑隔离的。A公司的知识库对B公司完全不可见,同一公司内不同权限的员工看到的世界也是不同的。
4.2 隐私保护:数据使用的边界
企业最关心的问题之一是,我的核心数据是否会被用于训练OpenAI的下一个模型?对此,OpenAI给出了明确且坚定的承诺。
默认不用于训练:对于Business、Enterprise和Edu用户,其通过API或ChatGPT Enterprise提交的数据,默认不会被用于训练或改进OpenAI的任何模型。这是一个至关重要的隐私边界,确保企业的商业机密、客户数据、源代码等核心信息不会外泄。
数据保留策略:企业可以根据自身合规要求,配置数据的保留策略,例如控制对话历史的存储时间。
4.3 多层安全防护架构
除了权限与隐私,OpenAI还提供了一系列行业标准的安全措施,构建纵深防御体系。
4.4 合规与审计支持
对于金融、医疗等受到严格监管的行业,可审计性是必备条件。
Enterprise Compliance API:企业管理员可以通过这个专门的API,以编程方式获取组织内的对话日志。这些日志包含了谁、在什么时间、问了什么、得到了什么回答等详细信息。
审计与报告:导出的日志可以被集成到企业现有的安全信息和事件管理(SIEM)系统中,用于内部审计、安全事件调查或生成满足外部监管要求的合规报告。
这套完整的安全与合规体系,旨在打消企业在拥抱先进AI技术时的后顾之忧,使其能够在一个安全、可控、合规的环境中,充分利用“公司知识”功能带来的生产力提升。
五、 当前局限与未来演进路线
%20拷贝-fmmv.jpg)
任何一项新技术的推出,都必然伴随着一些局限性。清晰地认识这些局限,并了解其未来的发展方向,对于企业做出合理的评估和规划至关重要。
5.1 功能边界与使用限制
根据OpenAI的公告,目前“公司知识”功能存在以下几个主要限制:
手动启用机制:用户需要在每次开启一个新对话时,手动选择启用“公司知识”功能。这增加了一定的操作成本。如果用户忘记启用,ChatGPT虽然可能依据对话历史参考已连接应用的信息,但无法提供完整、可点击的引用,功能体验会打折扣。
功能互斥:在启用“公司知识”的状态下,ChatGPT暂时无法进行联网搜索。这意味着它只能在企业内部的知识边界内回答问题,无法结合最新的外部公共信息。
内容生成类型限制:当前版本不支持生成图表和图像。例如,用户无法要求它“根据上季度的销售数据生成一个柱状图”,而只能得到文本形式的总结。
这些限制表明,该功能目前仍处于早期阶段,其核心聚焦于内部文本知识的检索与问答,尚未与ChatGPT的其他高级能力(如联网、多模态)完全融合。
5.2 路线图展望:迈向全功能整合
OpenAI已经明确了后续的演进方向,旨在将“公司知识”从一个“特殊模式”转变为ChatGPT的原生能力。
深度功能整合:未来的目标是打破当前的功能互斥。用户将无需手动启用,ChatGPT会智能判断何时需要查询内部知识、何时需要联网搜索,甚至可以将两者结合。例如,回答“对比我们公司产品与市场上最新竞品的优劣势”这类问题,就需要同时调用内部产品文档和外部网络信息。
扩展适配工具:当前支持的应用列表(Slack, Google Drive等)只是一个开始。OpenAI计划持续扩展连接器的生态,将更多主流的企业协作工具纳入支持范围,例如:
项目管理:Asana, Trello, ClickUp
代码与DevOps:GitLab Issues, Jenkins
CRM与销售:Salesforce
设计协作:Figma, Miro
提升检索与分析能力:除了扩展数据源,功能本身也会不断深化。例如,支持更复杂的查询,如按日期、作者、文档类型等多维度进行筛选和聚合,提供更深度的分析能力。
5.3 行业影响与趋势预测
“公司知识”功能的推出,不仅是OpenAI自身产品线的延伸,更对整个企业软件和AI应用市场产生了深远影响。
对企业搜索市场的冲击:它直接与Glean、Coveo以及微软的Microsoft 365 Copilot等企业搜索解决方案展开竞争。相比传统企业搜索,ChatGPT的优势在于其强大的自然语言理解和内容生成能力,用户体验更接近于与一个专家对话。
加速企业知识管理范式转型:它推动企业从“以存储为中心”的传统知识库模式,向“以应用和交互为中心”的动态知识图谱模式转型。知识不再是静态存放的文档,而是可以被AI实时调用、组合和创造的“活”的资产。
催生AI-Native工作流:未来,越来越多的企业应用可能会将这类AI能力作为其核心。工作流程将不再是人在不同软件之间切换,而是以一个统一的AI助手为中心,通过自然语言指令驱动所有后台应用完成任务。这预示着一个AI-Native的企业软件新时代的到来。
结论
ChatGPT的“公司知识”功能,是大型语言模型从通用走向专有、从外部走向内部的关键一步。它通过安全、可信的方式,将AI强大的理解和生成能力,与企业最宝贵的内部数据资产相结合,精准地解决了企业知识管理中的核心痛点。
通过提供可追溯、附带引用的回答,它在AI的“能力”与企业的“信任”之间架起了一座桥梁。尽管目前尚存一些局限,但其清晰的演进路线图和巨大的应用潜力,预示着它将不仅仅是一个工具,而可能成为未来企业智能化的核心基础设施。
对于企业而言,这既是提升效率的机遇,也是一次对内部知识管理体系进行重新审视和升级的挑战。如何更好地结构化和管理内部数据,使其能被AI更高效地理解和利用,将成为决定未来企业竞争力的一个重要议题。一个由AI驱动、知识无缝流动的智能化组织形态,正变得触手可及。
📢💻 【省心锐评】
这不是简单的功能叠加,而是企业知识交互的范式革命。当AI能安全、可信地阅读你的内部文档时,每个员工都拥有了一个全知的专家同事,生产力的天花板被再次拉高。

评论