.png)


📜 【摘要】知识图谱作为人工智能的“认知中枢”,正在重塑信息管理与决策模式。本文系统拆解知识图谱的核心要素、全流程构建技术及行业实践,对比自顶向下与自底向上策略的优劣,并展望多模态融合、实时化更新与可解释性等前沿方向。通过医疗、金融、电商等领域的实战案例,揭示知识图谱如何驱动行业智能化转型,成为AI时代的核心基础设施。
🌍 引言:当数据遇见结构
在信息爆炸的洪流中,数据如星辰般散落,而知识图谱则是编织星空的经纬线。从谷歌搜索的“知识面板”到医疗AI的辅助诊断,从金融风控的关联网络到电商推荐的精准触达,知识图谱正悄然成为智能时代的“水电煤”。
然而,构建一张高精度、高覆盖的知识图谱,是一场技术与工程的交响乐——它需要融合自然语言处理、图计算、数据治理等多领域技术,跨越数据异构性、语义歧义性、动态时效性等重重障碍。本文将深入技术腹地,解析知识图谱从原始数据到智慧网络的蜕变之旅。
🧩 一、知识图谱的四大基石
-icqs.jpg)
知识图谱通过结构化表达实现“数据→信息→知识”的跃迁,其核心要素构成如下:
技术点睛:
本体设计工具:Protégé支持可视化定义类层次、属性约束及推理规则,如“每位患者必须有至少一个诊断结果”的强制性公理。
知识表示方案:RDF(资源描述框架)以三元组形式存储知识,支持SPARQL查询;属性图(如Neo4j)允许为节点和边添加灵活属性。
🛠️ 二、构建六步法:从混沌到秩序
🔍 阶段1:数据采集与预处理——知识的“采矿与冶炼”
目标:整合多源异构数据,提炼高质量知识原料
典型数据源处理方案:
医疗领域实践:
某三甲医院构建疾病知识图谱时,整合了HIS系统(结构化)、电子病历(半结构化)、CT影像(非结构化)三类数据:
使用NiFi搭建数据管道,每日同步HIS中的患者基本信息
通过OCR识别CT报告中的关键指标(如病灶大小、位置)
采用Apache Tika解析PDF格式的学术论文,抽取治疗方案数据
🔍 阶段2:实体识别与关系抽取——知识的“原子化提取”
技术演进四阶段:

关键技术对比:
金融领域突破:
关系抽取:使用FinBERT模型从财经新闻中抽取“公司-并购-标的”关系,准确率较传统模型提升23%
事件抽取:达观数据的“事件立方”技术可识别“IPO事件”中的时间、融资金额、参与机构等要素
🔍 阶段3:知识融合——消除“信息巴别塔”
核心挑战与解决方案:
电商场景实践:
京东商品知识图谱通过以下步骤实现亿级商品数据融合:
品牌归一化:将“iphone14”“苹果14”统一为“iPhone 14”
规格对齐:解析“6.1英寸”与“155mm”屏幕尺寸的等价关系
价格同步:基于时间窗口匹配各平台价格波动曲线
🔍 阶段4:本体构建与知识存储——搭建“知识大厦”
本体构建方法论:
-ylap.jpg) 存储方案选型指南:
存储方案选型指南:
医疗行业案例:
复旦大学附属医院采用Protégé构建肿瘤诊疗本体,包含:
类层次:恶性肿瘤→肺癌→非小细胞肺癌
关系约束:“病理分期”属性仅允许填写I-IV期
推理规则:若“EGFR基因突变阳性”则推荐“奥希替尼治疗”
🔍 阶段5:质量评估与优化——知识图谱的“健康体检”
质量评估四维矩阵:
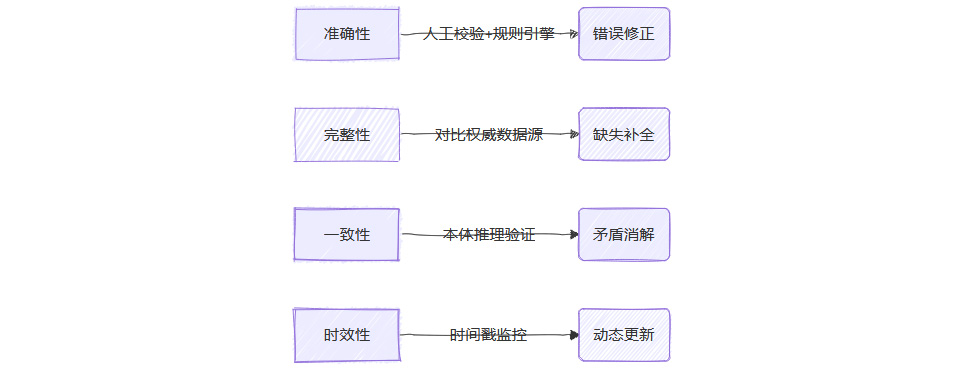
评估工具与方法:
纠错技术前沿:
对抗训练:微软DeBERTa模型通过注入噪声数据增强纠错鲁棒性
知识蒸馏:将GPT-4的纠错能力迁移至轻量级模型,推理速度提升5倍
众包平台:医学知识图谱采用“医生标注联盟”机制,关键数据人工复核
🔍 阶段6:动态更新与维护——知识的“新陈代谢系统”
实时更新技术栈:
数据源监听 → 变更捕获(CDC) → 增量处理 → 冲突消解 → 版本快照
行业实践对比:
关键技术突破:
增量图计算:Uber研发的Apache Marmaray实现TB级图谱的分钟级更新
版本化管理:使用Delta Lake存储知识图谱历史版本,支持“时间旅行查询”
🚀 三、关键技术全景透视

1. NLP革命:从规则到认知智能
技术演进里程碑:
1980s规则时代:有限状态机处理“姚明出生于上海”等简单模式
2000s统计学习:CRF模型在CoNLL-2003任务中F1值达88%
2018预训练崛起:BERT在实体识别任务上准确率突破92%
2023多模态融合:GPT-4V实现图文跨模态关系抽取
医疗文本解析突破:
BioClinicalBERT:在MIMIC-III数据集上疾病识别准确率94.2%
关系抽取强化:斯坦福REBEL模型构建1600万生物医学关系网络
2. 图计算引擎性能突围
主流图数据库对比:
性能优化技巧:
索引策略:为高频查询属性创建复合索引(如“人物-出生地”)
存储分片:按业务模块拆分图谱(用户画像 vs 商品知识)
缓存机制:Redis缓存热点子图(如热门商品关联关系)
🌈 四、构建策略博弈论:方法论的选择艺术

自顶向下 vs 自底向上 终极对决:
混合策略实践:
金融合规图谱:先基于FIBO本体搭建框架(自顶向下),再通过新闻舆情抽取动态关系(自底向上)
智能制造图谱:结合设备手册(结构化)与传感器日志(非结构化),采用双向迭代构建
🚄 五、未来战场:知识图谱的七大演进方向
1. 多模态知识融合
技术突破:
图文对齐:CLIP模型实现“CT图像→文本描述”跨模态映射
视频理解:Facebook DINOv2提取视频帧中的时空关系
应用场景:
工业质检:融合设备图纸(图)、维修记录(文)、振动数据(时序)构建故障知识网
智慧城市:关联监控视频(视觉)、交通信号(时序)、社交媒体(文本)实现事件推演
2. 实时化与流式构建
技术栈:
流处理:Apache Flink + Kafka
增量学习:GraphSAGE的流式训练变体
金融案例:
蚂蚁集团风控图谱实现:企业股权变更检测延迟 <1分钟
资金异动关联分析响应 <5秒
3. 可解释性革命
技术方案:
因果推理:微软DoWhy库解析“药物→疗效”的因果链
可视化追踪:Linkurious工具高亮“企业控制权路径”
医疗应用:
梅奥诊所的诊疗图谱可展示“基因突变→靶向药选择”的推理过程,医生点击即可查看支持文献
4. 隐私计算突破
前沿技术:
联邦图谱:IBM联邦学习框架实现跨医院数据协同
差分隐私:Google PrivateJoin保护用户搜索记录关联
金融实践:
微众银行采用多方安全计算,在不暴露客户数据的前提下构建跨机构反欺诈图谱
5. 自动化推理跃迁
技术突破:
符号推理:基于Datalog规则引擎实现合规审查
神经网络推理:GraphQA模型实现复杂路径查询
司法应用:
北大法宝法律知识图谱支持“劳动争议→赔偿标准→相似案例”的自动推理链
6. 低代码构建平台
代表产品:
阿里云DataWorks知识图谱模块
Stardog Studio可视化构建工具
核心功能:
拖拽式本体设计
自动化数据映射
一键式质量检测
7. 元宇宙知识引擎
创新实践:
英伟达Omniverse构建3D物体知识库,关联物理属性与行为规则
Decentraland虚拟地产图谱记录土地所有权与交易历史
🌟 六、总结:知识工程的黄金时代
知识图谱的构建已从实验室走向产业核心:
技术融合:NLP、图计算、多模态学习构成铁三角,大模型成为新引擎
工程哲学:在标准化与灵活性间寻找平衡,没有最优解只有最适解
未来形态:从静态知识库进化为具备感知-推理-决策能力的认知中枢
知识图谱作为人工智能时代的核心基础设施,已经从最初的结构化知识管理工具,发展为支撑智能搜索、推荐、问答、决策等多元场景的智能引擎。本文系统梳理了知识图谱的基本组成、完整构建流程、关键技术、自动化与半自动化方法、持续维护与动态更新机制,并深入探讨了多模态融合、知识推理、开放与行业知识图谱、跨语言、可解释性、隐私与伦理等前沿议题。
在技术层面,知识图谱的构建涵盖了数据采集与预处理、实体识别、关系与属性抽取、知识融合、本体建模、质量评估与优化、知识表示与存储、持续维护与动态更新等多个环节。每一环节都离不开自然语言处理、深度学习、图数据库、知识推理、多模态融合等核心技术的支撑。随着预训练大模型、多模态AI、图神经网络、因果推理等前沿技术的不断突破,知识图谱的自动化、智能化、可解释性和可信度正持续提升。
在应用层面,知识图谱已广泛服务于智能搜索、智能问答、个性化推荐、企业知识管理、金融风控、医疗健康、法律教育、工业制造、物联网等众多行业和场景,成为企业数字化转型和智能化升级的重要引擎。行业知识图谱的标准化、开放知识库的互操作、跨语言与多模态的融合创新,正在推动知识图谱生态的繁荣与进化。
未来,知识图谱将在数据智能、认知智能、决策智能等更高层次的智能应用中发挥更大作用。与此同时,数据质量、知识可信度、隐私保护、伦理治理等挑战也将持续存在。只有不断提升技术创新能力,加强行业协同与生态建设,才能让知识图谱真正成为智能社会的“知识底座”,驱动人类社会迈向更加智能、高效、公平和可持续的未来。
💡 【省心锐评】
“知识图谱是AI从感知走向认知的桥梁,未来十年将重构所有行业的智能底座。”

评论