.png)
%20%E6%8B%B7%E8%B4%9D-xuug.jpg)

【摘要】本文剖析表征自编码器(RAE)如何颠覆传统VAE范式。通过复用DINOv2等冻结表征,结合DiTDH架构,RAE在图像生成质量与训练效率上实现双重突破,为生成式AI开辟了新路径。
引言
在图像生成领域,我们长期与一个根本性的矛盾共存。主流的生成模型,特别是扩散模型,其底层依赖一个被称为变分自编码器(VAE)的组件。VAE遵循一种“压缩-还原”的逻辑。它首先将一张高分辨率图像强行压缩到一个维度极低的潜空间(Latent Space)中,然后再由一个解码器尝试从这个高度浓缩的信息中重建原图。
这个过程存在一个固有的“信息瓶颈”。压缩必然导致信息损失,尤其是高频细节、精细纹理和复杂的语义关系。这成为制约生成图像质量和真实感的关键瓶颈。无论后续的扩散模型主干多么强大,如果其起点是一个信息残缺的潜空间,最终的生成结果也难以突破上限。
纽约大学谢赛宁团队联合郑博洋、马南叶、童胜邦等人于2024年10月发表的研究(arXiv:2510.11690v1),直面这一核心问题,并提出了一套全新的解决方案——表征自编码器(Representation AutoEncoder, RAE)。RAE的核心思想是彻底抛弃“为了压缩而编码”的旧范式,转向“为了理解而编码”的新思路。它不再从零训练一个编码器,而是直接借力于那些已经通过海量数据预训练、具备强大视觉理解能力的模型,如DINOv2、SigLIP等。
这项工作不仅是模型架构的优化,更是一次底层思想的革命。它标志着生成式AI正从单纯的像素拟合,迈向一个更深层次的、基于语义理解的创作阶段。本文将深入剖析RAE的技术原理、核心创新以及其对整个AI领域的深远影响。
一、 范式之困:传统生成模型的“信息瓶颈”
%20拷贝-adfe.jpg)
1.1 VAE的“压缩-还原”路径
要理解RAE的颠覆性,必须先看清它所要取代的VAE范式。一个标准的VAE包含两个核心部分。
编码器(Encoder):负责将输入的图像
x映射到一个低维的潜空间向量z。这个过程是破坏性的,旨在用尽可能少的维度来“概括”图像内容。解码器(Decoder):负责从潜空间向量
z中重建出图像x'。它的任务是“猜”出原始图像可能的样子。
在扩散模型(如Stable Diffusion)中,VAE的作用是预处理数据。它将像素空间(例如512x512x3)的操作,转移到潜空间(例如64x64x4)进行,极大地降低了计算复杂度。扩散过程本身是在这个低维潜空间中完成的。当扩散过程生成一个新的潜空间向量z_new后,再由VAE的解码器将其放大回像素空间,形成最终图像。
1.2 瓶颈的根源:不可逆的信息损失
VAE的效率来自于它的压缩能力,但其上限也受限于此。这个瓶颈体现在三个层面。
高频细节丢失:图像中的精细纹理、锐利边缘等高频信息在压缩过程中最先被丢弃。解码器很难无中生有地恢复这些信息,导致生成图像普遍偏“糊”或缺乏真实感。
空间关系错乱:复杂的物体结构和空间布局信息在低维向量中难以精确编码。这导致生成图像时常出现结构性错误,例如多余的手指、错位的五官等。
语义信息模糊:深层次的语义概念,比如物体的材质、光照的氛围、图像的情感,在压缩后会变得模糊不清。解码器只能依赖有限的线索进行重建,容易产生语义不符的“幻觉”。
一个直观的类比是,VAE就像一位图书管理员,为了节省书架空间,把一本厚重的百科全书强行缩写成一张单页摘要。 当你需要查询具体知识时,这张摘要只能提供一个大概轮廓,无数生动的细节和严谨的逻辑链条早已荡然无存。
1.3 对扩散模型的制约
扩散模型本身具备强大的生成能力,但它的能力被VAE这个“猪队友”严重拖累。扩散主干(如U-Net或Transformer)接收的输入是经过VAE编码的潜空间特征。如果这些特征本身就是残缺和模糊的,那么无论扩散模型如何学习,都无法超越这个信息的上限。
SD-VAE的下游任务分类准确率仅有约8%,这个数字触目惊心。它说明SD-VAE的潜空间几乎没有保留任何可供高级任务使用的高质量语义信息。生成模型在这样一个“信息荒漠”上进行创作,其难度可想而知。
二、 破局之道:表征自编码器(RAE)的核心理念
RAE的提出,旨在从根源上打破VAE的信息瓶颈。其核心思路可以概括为一句话:不再自己从零学习如何“压缩”,而是直接借用“专家”的“理解”。
2.1 从“压缩”到“理解”的范式转移
RAE重新定义了自编码器的目标。
旧目标(VAE):找到一个尽可能低维的潜空间,同时保证重建误差尽可能小。这是一个以“压缩率”为核心的优化问题。
新目标(RAE):找到一个能够最大程度保留原始图像语义信息的表征空间,并能从中高质量地重建图像。这是一个以“信息保真度”为核心的优化问题。
这个转变意味着,编码器的首要任务不再是压缩,而是理解。它需要像一个经验丰富的图像分析师,准确地抽取出图像中最重要的结构、物体、关系和风格特征。
2.2 “冻结的AI老师”:关键的赋能者
RAE的巧妙之处在于,它没有尝试从头训练一个具备强大理解能力的编码器,因为这样的“专家”已经存在。近年来,自监督学习领域涌现出了一批强大的预训练视觉模型,它们通过在海量无标签数据上进行学习,已经掌握了对视觉世界深刻的理解力。
RAE将这些模型直接拿来,作为其“冻结的”编码器,也即“AI老师”。
这些“老师”是冻结的,意味着在训练RAE的过程中,它们的参数保持不变。这样做的好处是双重的。
直接继承高质量语义:生成模型直接站在了巨人的肩膀上,起点就是高质量、高信息密度的语义表征。DINOv2的表征在下游任务上的准确率可以达到84.5%,与SD-VAE的8%形成鲜明对比。
训练效率高:无需训练庞大的编码器,只需专注于训练一个相对轻量的解码器,极大地降低了训练成本和时间。
2.3 RAE的工作流程
RAE与扩散模型结合的工作流程清晰而高效。
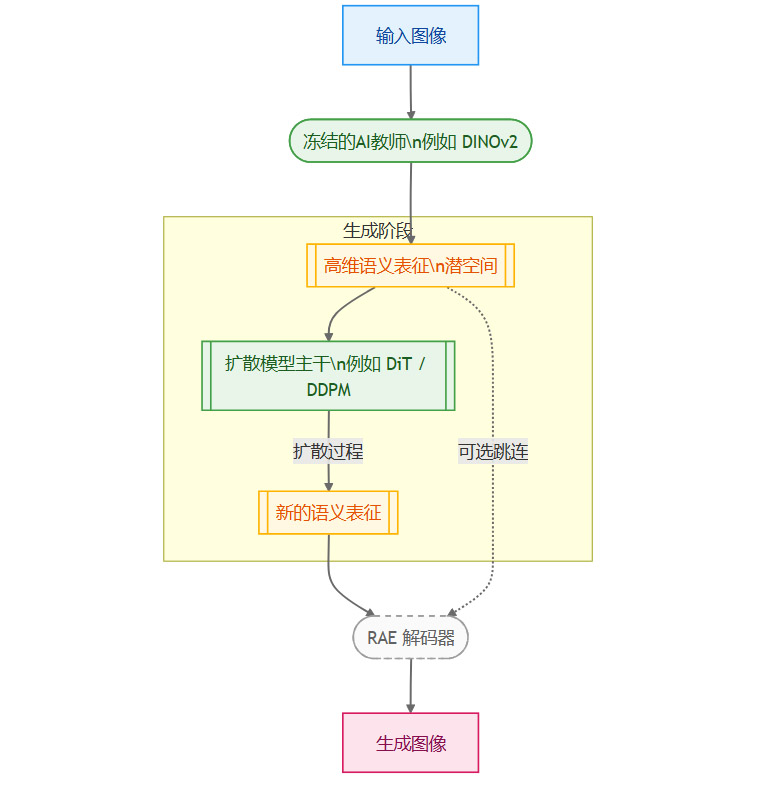
这个流程与传统方法的关键区别在于潜空间C的性质。它不再是低维、信息稀疏的向量,而是高维、信息密集的特征图。这就对后续的扩散模型主干提出了全新的要求。
三、 架构革新:为高维表征量身定制的DiTDH
%20拷贝-yhbn.jpg)
当“AI老师”提供了信息丰富的“教材”(高维表征)后,新的问题出现了。传统的“学生”(如标准的DiT,Diffusion Transformer)是为处理VAE压缩后的“薄册子”设计的,它的“理解能力”或“信息吞吐量”是有限的。直接将高维表征喂给它,就像让一个小学生去读研究生物论文,完全无法消化。
这就是RAE团队面临的第一个核心挑战:容量匹配(Capacity Matching)。
3.1 容量匹配的理论原则
研究团队通过理论分析证明了一个关键原则:生成器(学生)的容量,必须至少与教师表征的维度相匹配。 如果生成器的信息处理能力低于教师提供的信息量,那么无论如何训练,信息都会在传递过程中丢失,无法实现高质量的生成。
传统的DiT架构在处理高维输入时,要么因为计算量爆炸而无法训练,要么因为结构限制而无法充分利用信息。
3.2 DiTDH的设计哲学:“浅而宽”的高带宽接收盘
为了解决容量匹配问题,团队设计了一种全新的Transformer架构——DiT with Dimensionality-aware Transformer Heads (DiTDH)。
DiTDH的设计思想非常巧妙。它没有粗暴地将整个DiT模型加深或加宽,因为这会导致计算成本急剧上升。相反,它进行了一项“外科手术式”的改造。
标准DiT:将输入的Patch序列(Token)直接送入一系列标准的Transformer模块。
DiTDH:在将Token送入Transformer主干之前,增加了一个特殊的“接收头”(Head)。这个接收头是一个浅而宽的多层感知机(MLP)。
这个“接收头”的作用,就像是给原来狭窄的管道入口加装了一个宽大的接收盘。
“宽”:接收头的隐藏层维度远大于Transformer主干的维度。这使得它有足够的容量来接收并初步处理来自“AI老师”的高维特征,而不会造成信息拥塞。
“浅”:接收头的层数不多。这保证了它不会引入过多的计算开销和训练难度。
通过这种设计,DiTDH成功地在不显著增加整体模型复杂度的前提下,极大地提升了模型对高维信息的承载和处理能力。
3.3 架构对比:DiT vs. DiTDH
DiTDH的提出,是RAE能够成功的关键工程保障。它为高质量的语义表征找到了一个与之匹配的高效生成器,使得从“理解”到“重建”的通路被彻底打通。
四、 训练策略优化:三大匹配难题的系统性解法
解决了架构层面的容量匹配问题后,研究团队还面临着训练动态过程中的两个匹配难题。他们为此设计了一系列创新的训练策略。
4.1 挑战二:节奏匹配与维度感知调度
高维表征不仅信息量大,其信息分布也与低维潜空间完全不同。如果沿用为低维信息设计的传统训练策略(例如固定的学习率和优化节奏),会导致训练过程非常低效,甚至无法收敛。这就像用文火慢炖的方式去处理需要大火爆炒的食材。
为了解决节奏匹配(Pacing Matching)问题,团队提出了一种“维度感知”的训练调度(Dimensionality-aware Scheduling)。
其核心思想是让训练的“强度”与信息的“复杂度”相匹配。具体来说,他们调整了扩散过程中的信噪比(SNR)调度策略。对于信息维度更高的表征,采用更激进的训练步长和更强的优化信号,迫使模型更快地学会处理复杂信息。这种动态调整的策略,确保了训练过程始终保持在最高效的学习轨道上。
4.2 挑战三:适应性与鲁棒性
“AI老师”提供的是在干净数据集上学到的“完美”表征。但在实际的扩散生成过程中,模型需要处理的是带有各种噪声的、不完美的输入。这之间存在一个分布差异(Distribution Gap)。如果模型只学会在理想条件下工作,那么在推理生成时就会表现脆弱。
为了解决**适应性匹配(Adaptation Matching)**问题,团队在训练过程中主动注入了扰动。
输入噪声:在送入RAE解码器进行重建训练时,对“AI老师”输出的干净表征主动添加少量高斯噪声。
数据增强:采用多种数据增强手段,模拟真实世界中可能出现的各种视觉变化。
通过这种“逆境训练”,解码器学会了在非理想条件下进行稳健的重建。这大大缩小了训练和推理之间的分布差异,提升了生成模型的鲁棒性。
4.3 综合效应:系统协同的力量
DiTDH架构、维度感知调度和适应性训练,这三项创新并非孤立存在,而是构成了一个协同工作的有机系统。
DiTDH 提供了足够大的“容器”。
维度感知调度 找到了最高效的“注水”方法。
适应性训练 确保了容器里的“液体”即使被搅动也能保持稳定。
正是这个系统性的解决方案,使得RAE最终得以发挥出其全部潜力。
五、 实验验证:刷新纪录的性能表现
%20拷贝-wtck.jpg)
理论和架构的先进性,最终需要通过实验结果来验证。RAE的表现没有让人失望,它在多个关键指标上都取得了突破性的成果。
5.1 生成质量的飞跃:FID新纪录
FID(Fréchet Inception Distance)是衡量生成图像质量和多样性的黄金标准,分数越低越好。RAE在标准的ImageNet数据集上创造了新的纪录。
1.51和1.13这两个数字是惊人的。它意味着RAE生成的图像在真实感、细节丰富度和多样性上,都显著超越了以往所有基于VAE的模型,达到了新的SOTA(State-of-the-Art)水平。
从视觉效果上看,RAE生成的图像极大地减少了传统模型中常见的语义错误。得益于DINOv2等“老师”对物体结构的深刻理解,RAE很少出现“把狗的耳朵安在猫头上”这类荒谬的错误。生成的物体结构更合理,物体间的关系也更符合常识。
5.2 训练效率的革命:16倍速收敛
RAE不仅生成质量更高,训练起来也更快。由于直接利用了预训练的编码器,并采用了高效的训练策略,RAE的收敛速度远超传统模型。
实验数据显示,RAE仅需传统模型约1/16的训练周期,就能达到甚至超越后者的最佳性能。
这种效率的提升带来了巨大的工程收益。
降低算力成本:更少的训练时间意味着更低的GPU小时消耗和能源成本。
加速迭代周期:研究人员和开发者可以更快地进行实验和产品迭代。
普惠化:使得顶尖的图像生成技术不再是少数拥有海量算力的巨头的专利。
5.3 重建质量的压倒性优势
为了直观展示RAE表征的信息保真度,研究团队对比了RAE和SD-VAE的图像重建能力。即输入一张图片,经过编码再解码,看还原得如何。
结果是压倒性的。SD-VAE的重建图像模糊不清,大量细节丢失。而RAE的重建图像则清晰锐利,与原图高度相似。这雄辩地证明了RAE的潜空间保留了远比VAE丰富得多的信息。
六、 行业影响与未来展望
RAE的成功,其意义远不止于一篇优秀的学术论文或一个性能强大的模型。它为整个人工智能领域,特别是生成式AI的发展,指明了一个新的方向。
6.1 广阔的应用前景
凭借高质量和高效率的双重优势,RAE技术有望在众多行业中落地开花。
内容创作:艺术家、设计师可以利用RAE快速生成高质量的灵感图、素材和最终成品,将创意与实现之间的距离无限拉近。
游戏与影视:游戏开发者和特效师可以高效地生成大规模、高分辨率的场景、角色和道具,极大地降低美术成本,提升生产力。
教育与科研:可以实时生成高保真的科学可视化图像、历史场景复原图,让抽象的知识变得具体可感。
6.2 AI协作新范式:“知识重用”的时代
RAE最重要的启示,在于它成功实践了**“AI协作”和“知识重用”**的理念。
在过去,构建一个强大的AI系统,往往意味着从零开始,在一个庞大的模型中训练所有能力。RAE则展示了一种更聪明、更高效的路径:将不同的任务分解,让最擅长的“专家”模型来负责对应的部分,然后将它们有机地组合起来。
在这个范式中,DINOv2是“视觉理解专家”,DiTDH是“生成构建专家”。它们各司其职,协同工作,最终实现了1+1>2的效果。这种模块化、可组合的思路,将是未来构建更复杂、更强大AI系统的主流范式。它不仅适用于图像生成,也为视频、音频、3D等其他模态的生成任务提供了宝贵的借鉴。
6.3 已知挑战与未来方向
RAE并非终点。尽管它取得了巨大成功,但仍有值得探索和改进的空间。
生成速度:当前的扩散模型在推理时需要多步采样,生成一张高质量图片仍需数秒。如何通过更优的采样策略或模型结构(如一致性模型)来进一步提升生成速度,是一个重要的研究方向。
多样性与可控性:如何确保生成内容足够多样,避免模式化,同时给予用户更精细的控制能力,是提升模型实用性的关键。
多模态融合:将RAE的思路扩展到文本、音频等多模态领域,实现跨模态的、基于深度理解的生成,将是下一个激动人心的前沿。
结论
纽约大学团队提出的RAE体系,是图像生成领域的一次范式革命。它通过巧妙地“站在巨人肩膀上”,用冻结的预训练视觉表征取代了传统VAE的压缩路径,从根本上解决了长期存在的信息瓶颈问题。
结合为高维信息量身定制的DiTDH架构和一系列精巧的训练策略,RAE不仅在生成质量上刷新了ImageNet的纪录,更在训练效率上实现了数量级的提升。
这项工作的影响是深远的。它推动图像AI从“像素的模仿者”进化为“语义的理解者和创造者”。更重要的是,它所倡导的“知识重用”和“AI协作”理念,为我们构建下一代更复杂、更强大的智能系统提供了清晰的路线图。从“压缩”到“理解”,这不仅仅是技术路径的更迭,更是我们对人工智能本质思考的一次升华。
📢💻 【省心锐评】
RAE的核心是“借脑”,抛弃低效的VAE压缩,直接用DINOv2等成熟模型的“理解力”做输入。配合专为高维信息设计的DiTDH,实现了质量与效率的双赢,为生成AI指明了模块化协作的新方向。

评论