.png)


【摘要】多Token预测(MTP)技术正引领大语言模型训练范式的效率革命。本文系统梳理MTP的技术原理、架构优化、实验成果、优势创新、挑战局限及未来展望,深度剖析其在加速模型收敛、提升推理速度、增强全局语义建模等方面的突破,并结合典型案例与行业趋势,全面展现MTP在AI大模型领域的广阔前景。
引言
在人工智能领域,尤其是自然语言处理(NLP)和大语言模型(LLM)的发展浪潮中,模型规模的不断扩张带来了前所未有的能力提升。然而,随之而来的训练效率瓶颈、推理速度限制和泛化能力不足等问题,也日益成为制约AI产业化落地和学术创新的关键障碍。传统的“下一个token预测”训练范式,虽然在过去十年中支撑了Transformer、GPT等模型的崛起,但其局限性在大模型时代愈发突出。
多Token预测(Multi-token Prediction, MTP)技术的提出,正是对这一范式的深刻反思与创新突破。通过在每一步训练中并行预测多个token,MTP不仅极大提升了训练信号密度和模型收敛速度,还为推理加速、全局语义建模和样本效率带来了革命性进步。本文将以技术论坛深度文章的标准,系统梳理MTP的理论基础、工程实现、实验验证、优势创新、现实挑战与未来展望,力求为AI从业者、研究者和产业决策者提供一份兼具深度与广度的权威参考。
一、🌟 多Token预测的技术原理与架构创新

1.1 传统范式的瓶颈与MTP的提出
1.1.1 传统“下一个token预测”范式的局限
在大语言模型的训练过程中,最常见的目标函数是“下一个token预测”(Next-token Prediction)。即给定一个长度为L的输入序列,模型每次仅预测下一个token的概率分布。这种方法虽然实现简单、易于并行化,但存在如下局限:
训练信号稀疏:每步仅有一个token的预测信号,导致模型收敛速度受限,尤其在长序列建模时,训练效率低下。
局部依赖强:模型更倾向于捕捉短距离依赖,难以充分学习全局结构和长距离语义关系。
推理速度慢:自回归生成方式下,每次只能生成一个token,推理速度受限于序列长度,难以满足实时应用需求。
训练-推理分布差异:训练时采用“教师强制”(Teacher Forcing),推理时则为自回归生成,二者分布不一致,影响泛化能力。
1.1.2 多Token预测的核心思想
多Token预测(MTP)技术应运而生。其核心思想是:在每个训练步骤中,模型不再只预测下一个token,而是并行预测接下来的n个token。这样,模型被迫学习更丰富的全局结构和长距离依赖,训练信号密度大幅提升,收敛速度加快,推理效率也随之提升。
MTP的提出,既是对传统范式的突破,也是对人类语言学习机制的模拟——人类在理解和生成语言时,往往会同时考虑多个词之间的关系,而非仅关注单个词。
1.2 MTP的技术架构与实现细节
1.2.1 架构总览
MTP的典型技术架构如下:
1.2.2 训练流程Mermaid流程图
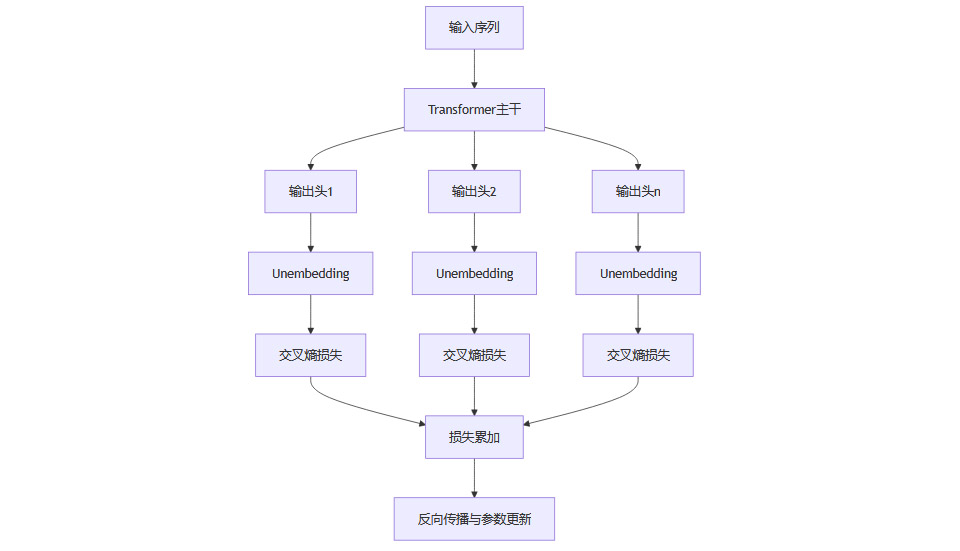
1.2.3 关键优化策略
内存与计算优化:并行预测多个token理论上会增加显存消耗。为此,工程实现中采用“依次前向/反向传播并即时释放中间数据,仅在主干网络处累积梯度”的策略。这样,GPU峰值内存占用大幅降低,使MTP在大模型训练中可行。
推理加速:结合“自推测解码”(Self-Speculative Decoding)等技术,模型可一次性生成多个token,再用主输出头验证结果,推理速度提升显著。实际应用中,4-token预测模型推理速度可提升3倍,8-token预测模型提升6.4倍。
1.2.4 损失函数与信息论优化
MTP的损失函数不仅是多个位置的交叉熵之和,还可结合信息论优化目标,通过最小化多位置信息熵之和,强化token间的关联性决策。这一优化进一步提升了模型的全局建模能力和泛化性能。
1.3 MTP与传统范式的对比
二、🚀 多Token预测的实验成果与典型应用
2.1 大模型规模效应与任务适应性
2.1.1 模型规模对MTP效果的影响
实验表明,MTP在大模型(如13B参数)上的优势尤为显著,而在小模型(如300M参数)上提升有限。这一现象的本质在于,大模型具备更强的参数容量和表达能力,能够更好地捕捉多token间的复杂依赖关系,从而充分发挥MTP的训练信号密度优势。
2.1.2 任务类型对MTP效果的影响
MTP在代码生成、长文本建模、数学推理等任务上表现突出,尤其是在需要全局结构和长距离依赖的场景中,性能提升明显。而在自然语言选择题等任务上,提升有限。这与任务本身对全局建模能力的需求密切相关。
2.2 典型实验成果
2.2.1 代码生成任务
在HumanEval基准测试中,13B参数模型采用MTP后,解决问题能力提升12%。
在MBPP(多步编程问题)数据集上,13B模型提升17%。
字节级模型下,8-byte预测模型在MBPP上Pass@1提升67%,HumanEval提升20%。
2.2.2 推理速度提升
4-token预测模型推理速度提升3倍。
8-token预测模型推理速度提升6.4倍。
在长文本建模中,第二token预测接受率达85%-90%,显示出高度可靠性。
2.2.3 其他生成式任务
在摘要、长文本生成等任务中,MTP模型表现优异,生成质量和效率同步提升。
在自然语言选择题等任务上,提升有限,需进一步优化评估方法和模型结构。
2.3 工业界与学术界的应用实践
2.3.1 工业界应用
采用MTP技术后,主流大模型在代码生成、数学推理、长上下文处理等任务上表现优异,训练成本大幅降低。
在实际部署中,推理速度的提升极大缓解了大模型在实时应用中的性能瓶颈,为AI产业化落地提供了坚实基础。
2.3.2 学术界验证
多项学术研究系统评估了MTP的效果,覆盖从300M到13B参数的模型,数据集涵盖代码、自然语言等多种任务,结论高度一致:MTP在大模型和复杂任务上优势显著。
三、💡 多Token预测的优势与创新点
%20拷贝.jpg)
3.1 训练信号密度与收敛速度的革命性提升
3.1.1 并行预测带来的信号密度提升
MTP通过每步并行预测多个token,使得模型在同等训练步数下获得更多的训练信号。这一机制极大提升了模型的学习效率,加快了收敛速度,尤其在大规模数据和长序列任务中优势明显。
3.1.2 收敛速度加快的实证分析
实验数据显示,采用MTP的模型在相同训练资源下,达到同等甚至更高性能所需的训练步数显著减少。这不仅降低了训练成本,也为大模型的快速迭代和优化提供了可能。
3.2 推理速度的质变提升
3.2.1 推测性解码与并行生成
结合推测性解码技术,MTP模型可一次性生成多个token,再用主输出头验证结果。实际应用中,推理速度提升3-6倍,极大满足了实时生成和大规模推理的需求。
3.2.2 推理加速的实际意义
推理速度的提升,不仅降低了算力成本,还拓展了大模型在对话系统、智能客服、代码自动补全等场景的应用边界,为AI普及和产业化提供了坚实支撑。
3.3 全局语义建模与生成质量的提升
3.3.1 长距离依赖与全局结构的建模能力
MTP迫使模型在每步训练中关注多个未来token,显著增强了对长距离依赖和全局结构的建模能力。这一优势在代码生成、长文本生成等任务中尤为突出,生成内容更连贯、逻辑更严密。
3.3.2 生成质量的提升
实验表明,MTP模型在生成式任务中的表现优于传统范式,生成内容更具一致性和创新性,极大提升了用户体验和应用价值。
3.4 样本与数据效率的提升
3.4.1 更高的数据利用率
在相同计算资源下,MTP模型能够获得更优性能,尤其在代码、算法推理等高复杂度任务上表现突出。这一特性对于数据稀缺或高价值场景具有重要意义。
3.4.2 训练-推理分布一致性的优化
MTP通过减少“教师强制”与自回归生成的分布差异,提升了模型的泛化能力和实际应用效果,缓解了传统范式下的分布不一致问题。
3.5 信息论优化与token间关联性强化
3.5.1 多位置信息熵最小化
MTP的损失函数可结合信息论优化,通过最小化多位置信息熵之和,强化token间的关联性决策。这一优化进一步提升了模型的全局建模能力和泛化性能。
四、🔍 多Token预测的挑战与局限
4.1 最优n值选择的难题
4.1.1 n值选择的影响
MTP的性能与并行预测的token数量n密切相关。n值过小,无法充分发挥并行预测的优势;n值过大,则可能导致内存消耗过高、梯度不稳定等问题。
4.1.2 动态n值调整的研究前景
如何根据任务类型、模型规模和训练阶段动态调整最优n值,是当前MTP研究的重要方向。未来有望通过智能调度和自适应机制,实现n值的动态优化,进一步提升MTP的效率与适应性。
4.2 内存与计算复杂性的权衡
4.2.1 内存消耗的挑战
尽管已有优化策略,MTP在极大规模模型下的内存和计算资源消耗仍需关注。尤其是在多卡并行和分布式训练场景下,如何高效管理内存和计算资源,是工程实现的关键难题。
4.2.2 资源优化的工程实践
通过梯度累积、混合精度训练、分布式调度等技术,MTP的内存和计算消耗已大幅降低。但在超大规模模型和超长序列任务中,资源优化仍是持续攻关的重点。
4.3 任务适应性的局限
4.3.1 任务类型对MTP效果的影响
MTP在代码生成、长文本建模等任务上优势明显,但在自然语言选择题等任务上提升有限。这与任务本身对全局建模能力的需求密切相关,未来需针对不同任务进一步优化模型结构和训练目标。
4.3.2 评估方法的优化需求
现有评估方法多以生成质量和准确率为主,难以全面反映MTP在不同任务中的实际效果。未来需开发更细致、多维度的评估体系,全面衡量MTP的性能优势和局限。
4.4 模型规模依赖性与部署门槛
4.4.1 大模型的规模效应
实验一致表明,MTP在大模型上效果更佳,小模型提升有限。这一现象对小型团队和资源有限的应用场景提出了挑战,需进一步研究MTP在小模型上的优化策略。
4.4.2 部署门槛与产业化挑战
大模型的部署单元较大,对算力、存储和工程能力要求较高。如何降低MTP模型的部署门槛,提升其在中小企业和边缘计算场景的适用性,是产业化落地的关键课题。
五、🌈 多Token预测的未来展望与发展趋势
%20拷贝.jpg)
5.1 动态预测机制的智能化
未来,MTP有望实现n值的智能动态调整,根据任务复杂度、模型状态和硬件资源,实时优化并行预测的token数量。这一机制将进一步提升MTP的效率与适应性,推动其在更广泛场景中的应用。
5.2 更高效的内存与计算资源管理
随着硬件进步和算法优化,MTP的内存与计算资源管理将持续优化。通过分布式调度、异构计算、存储优化等技术,MTP有望在超大规模模型和超长序列任务中实现高效训练和推理。
5.3 更广泛的任务适配与模型创新
MTP的应用场景将不断拓展,涵盖更多自然语言任务、跨模态任务和多语言场景。未来,MTP有望与多模态建模、知识增强、强化学习等前沿技术深度融合,推动AI系统向更高效、更智能的方向发展。
5.4 产业与学术的协同进化
随着产业界和学术界的持续实践,MTP有望成为下一代大模型训练的主流范式。主流大模型厂商和开源社区将加速MTP的标准化、工具化和生态建设,推动AI生成质量与推理速度的协同提升。
结论
多Token预测技术以其革命性的训练信号密度提升、推理速度加快和全局语义建模能力增强,正在引领大语言模型训练范式的效率革命。无论是在代码生成、长文本建模,还是在数学推理等高复杂度任务中,MTP都展现出显著优势。尽管仍面临n值选择、内存优化、任务适应性和部署门槛等挑战,MTP有望随着技术进步和产业协同,成为大模型训练的标配范式,推动AI系统向更高效、更智能、更普惠的方向发展。对于AI从业者和研究者而言,深入理解和掌握MTP技术,将是把握未来AI发展机遇的关键。
📢💻 【省心锐评】
“MTP不是渐进优化,而是训练范式的代际跃迁。它重新定义了参数效率的极限,将成为千亿模型的基础设施。”

评论