.png)
%20%E6%8B%B7%E8%B4%9D-rzkp.jpg)

【摘要】AI范式正从预训练转向“中训练+RLVR”,但这暴露了泛化能力的短板。真正的瓶颈在于实现类人“持续学习”,而非无尽地预置技能。
引言
人工智能的叙事正在经历一场微妙但深刻的转变。过去数年,行业沉浸在一种由 Scaling Law 主导的乐观氛围中,即更大的模型、更多的数据和更强的算力,几乎等同于更强的智能。这种信念推动了GPT系列等模型的诞生,也让“AGI近在咫尺”的呼声不绝于耳。然而,进入2025年,一种更为审慎和务实的声音开始成为主流。以Dwarkesh Patel等深度观察者的分析为代表,行业开始正视一个核心问题,即模型在基准测试上的惊艳表现,与在真实、复杂的商业环境中创造稳定价值的能力之间,存在着一条日益清晰的鸿沟。
这种转变的核心,是从对预训练规模的迷信,转向对模型实际执行与适应能力的拷问。前沿实验室的资源正在悄然转移,从单纯扩大语料与参数,转向一个更为复杂的领域,即通过“中训练”(Mid-training)和带可验证奖励的强化学习(RLVR)将“可执行能力”硬编码进模型。这一策略变化,本身就揭示了当前技术范式的内在张力。它引出了本文试图深入剖析的关键问题,为何AI的突破性进展似乎“卡”在了持续学习这一关?当前被寄予厚望的强化学习路径,究竟是通往AGI的康庄大道,还是一条成本高昂的弯路?
📌 一、范式迁移:从预训练的确定性到“中训练”的探索
%20拷贝-dmtt.jpg)
人工智能模型能力的发展,正从一个相对确定的、由规模驱动的阶段,进入一个充满探索性的、由任务驱动的新阶段。这个阶段的核心标志,就是“中训练”的崛起。
1.1 模型能力演进的三个阶段
为了理解“中训练”的定位,我们有必要回顾大语言模型能力构建的经典三阶段,并观察其演变。
中训练的出现,标志着行业关注点的一次重大转移。它不再满足于模型“能说会道”,而是要求模型“能干活”。它试图在通用世界模型和人类价值观对齐之间,插入一个全新的“技能层”。
1.2 “中训练”的技术内核:RLVR
“中训练”的核心技术是带可验证奖励的强化学习(Reinforcement Learning with Verifiable Rewards, RLVR)。它与早期用于对齐的RLHF有本质区别。
RLHF (Reinforcement Learning from Human Feedback):其奖励信号来自于人类对模型输出的主观偏好判断(例如,回答A比回答B更好)。这种奖励是模糊的、定性的,主要用于提升模型的对话质量和安全性。
RLVR (Reinforcement Learning with Verifiable Rewards):其奖励信号来自于一个客观、可自动验证的结果。环境会给出一个明确的对错信号。例如:
代码生成:代码是否成功编译并运行通过所有单元测试?
浏览器操作:是否成功在网页上找到特定信息并填入表单?
Excel建模:生成的财务报表是否符合预设的公式和校验规则?
RLVR的优势在于其可扩展性。由于奖励信号可以自动评估,理论上可以构建大规模的自动化训练流水线,让模型在成千上万个模拟环境中“练习”具体技能,而无需昂贵的人工标注。这正是当前各大AI公司投入巨资构建的方向,从网页浏览、软件操作到API调用,一个庞大的“技能预置”产业链正在形成。
1.3 范式转移的驱动力
推动这场范式转移的,是行业对预训练Scaling Law触及瓶颈的普遍焦虑,以及对模型商业化落地的迫切需求。
预训练成本的指数级增长:训练下一个数量级的前沿模型,需要投入的算力、数据和资金已达到惊人的地步。单纯依靠扩大规模来提升能力的边际效益正在递减。
“知道”与“做到”的鸿沟:预训练模型拥有渊博的知识,但将这些知识转化为可靠的、多步骤的行动序列,能力却非常欠缺。例如,模型“知道”如何预订机票的所有步骤,但让它自主操作一个真实的订票网站,失败率却极高。
商业价值的闭环需求:企业客户需要的不是一个聊天机器人,而是一个能嵌入其业务流程、自主完成任务的“数字员工”。这要求模型具备工具使用和流程执行的鲁棒能力,而这正是“中训练”试图解决的核心问题。
因此,行业资源的倾斜,从对语料和算力的无限追求,转向了对环境、工具链和奖励函数的精心设计。这标志着AI发展从一个“暴力美学”的时代,进入了一个更考验“精细化工程”的时代。
📌 二、“技能预置”的背后:对泛化短板的昂贵补偿
“中训练”范式的兴起,虽然在短期内显著提升了模型在特定任务上的表现,但其底层逻辑却揭示了一个令人不安的事实,即当前模型的泛化学习能力与人类相比,存在着根本性的差距。这种“技能预置”的策略,本质上是对模型在岗学习(On-the-job Learning)能力缺失的一种昂贵补偿。
2.1 人类学习与模型学习的根本差异
人类劳动力的核心价值,并不在于我们预先掌握了多少软件或工具,而在于我们强大的适应性和情境学习能力。一个刚入职的员工,面对一个全新的内部系统,他不需要经历一个长达数周、耗费数百万美元计算资源的强化学习过程。他可以通过以下方式快速上手:
观察学习:观看同事操作一遍。
指令学习:阅读一份简单的操作手册或听取口头指导。
试错学习:在少量尝试和纠正中快速掌握。
知识迁移:利用过去使用类似软件的经验进行举一反三。
这种学习过程是轻量级、高效率且高度泛化的。然而,对于当前的AI模型,上述任何一种学习方式都极其困难。模型无法从一次演示中稳定地泛化,也难以理解抽象的指令并将其转化为具体操作,更不用说在新环境中进行零样本或少样本的试错。
下图清晰地展示了两种学习范式的对比。
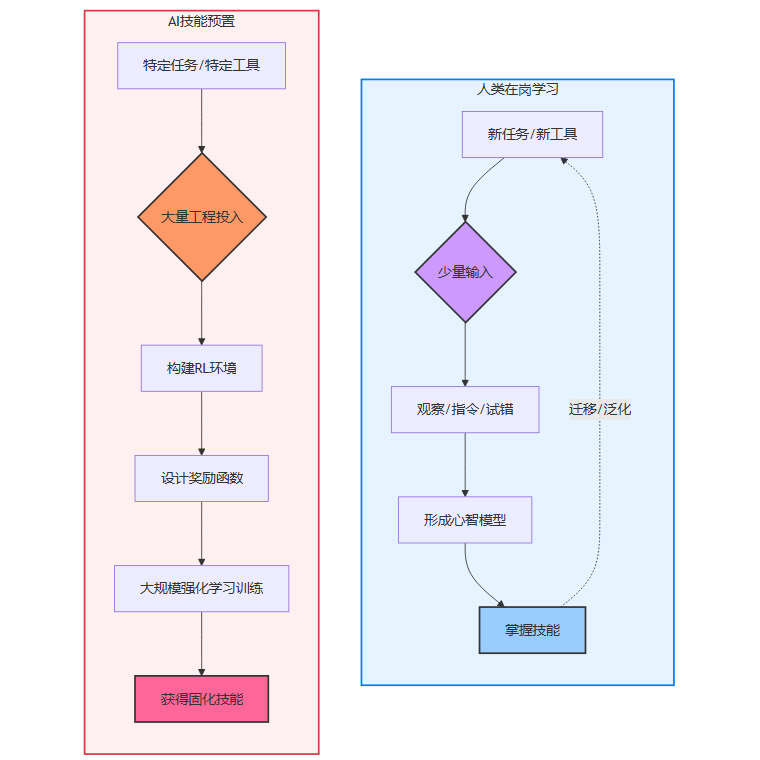
这个流程图直观地表明,AI的“技能预置”是一种重资产、前置化的模式。为了让模型学会一项新技能,就需要投入巨大的工程资源去构建一个专用的训练闭环。这种模式的代价是高昂的,并且其产出的技能是脆弱和僵化的。
2.2 “技能预置”的内在局限性
这种依赖预先构建环境的训练方式,决定了其难以覆盖真实世界工作的复杂性。
长尾任务的挑战:大多数知识工作,充满了大量非标准化的“长尾任务”。这些任务与特定的公司、特定的项目、甚至特定的情境紧密相关。为每一个长尾任务都去构建一个RL环境是完全不现实的。一个财务分析师的工作,不仅仅是操作Excel,还包括理解一份非结构化的会议纪要、与同事进行沟通确认、应对突发的市场变化等。这些都无法通过“预置技能”来解决。
环境变化的脆弱性:预置的技能高度依赖于其训练环境的稳定性。一旦软件界面更新、业务流程微调,或者API接口发生变化,模型已经学会的技能很可能就会失效。它缺乏人类那种动态适应环境变化的能力。
组合与创造的瓶颈:人类专家不仅能执行已知任务,还能将不同的技能进行组合,创造性地解决新问题。而通过RLVR训练出的技能,更像是孤立的“技能孤岛”,模型很难将操作浏览器的技能和操作数据库的技能进行灵活的、深度的组合,去完成一个全新的、需要跨领域知识的复杂任务。
因此,Dwarkesh的观点一针见血,对“中训练”的巨大投入,恰恰反证了AGI的遥远。一个真正通用的智能体,其核心能力应该是学习如何学习,而不是被动地接收预先打包好的技能。当前这条路线,更像是在建造一辆拥有无数个专用按钮的汽车,而不是培养一个能自主驾驶的司机。
2.3 行业现状的印证
这种局限性也反映在当前的行业应用中。尽管AI在编程、内容创作等领域展现了强大的辅助能力,但在更广泛的企业流程自动化方面,进展却相对缓慢。
点状提效 vs. 流程替代:企业引入AI,更多是作为特定环节的“效率插件”(例如,会议纪要总结、邮件草稿撰写),而远未达到替代一个完整岗位、端到端地负责一条业务流程的程度。
人机协同的必要性:几乎所有成功的AI应用,都离不开“人在环路”(Human-in-the-loop)的监督和干预。AI仍然扮演着副驾驶的角色,无法成为独立的主驾驶员。
这种现状,根源就在于模型缺乏在动态、开放环境中持续学习和适应的能力。而“中训练”虽然让副驾驶学会了更多固定的操作,却没有解决他如何成为主驾驶员的根本问题。
📌 三、规模化的幻象:为何 RLVR 无法复制预训练的成功
%20拷贝-wwnc.jpg)
将预训练阶段的成功经验——即算力规模化必然带来能力涌现——直接外推到强化学习阶段,是一种充满风险的乐观主义。二者在底层逻辑、数据需求和训练动态上存在巨大差异,导致RLVR的规模化之路远比预训练要崎岖和不确定。
3.1 两种Scaling Law的本质区别
预训练的Scaling Law之所以如此稳定和可预测,得益于其任务的简单性和数据的易得性。
预训练 (Next-Token Prediction):
目标函数:极其简单,就是预测下一个词元。
数据来源:海量的、现成的互联网文本和代码,几乎是无限的。
学习信号:密集且明确。每个词元都是一个学习样本,提供了清晰的监督信号。
结果:形成了一个平滑、稳定的幂律关系。只要算力投入跨越数量级,模型的损失(Loss)就会可预测地下降。
而RLVR的规模化则面临着截然不同的挑战。
强化学习 (Policy Optimization):
目标函数:复杂得多,是在一个巨大的、可能稀疏的状态-动作空间中,最大化累积奖励。
数据来源:需要通过与环境(Environment)的交互来实时生成。数据不是现成的,其质量和多样性高度依赖于环境的设计和探索策略。
学习信号:通常是稀疏(Sparse)和延迟(Delayed)的。模型可能需要执行一长串动作后才能得到一个奖励信号,这使得“功劳分配”(Credit Assignment)变得异常困难。
结果:训练过程极不稳定,对超参数敏感,容易陷入局部最优,不存在一个像预训练那样清晰普适的Scaling Law。
3.2 RLVR规模化的核心障碍
将RLVR的算力提升一百万倍,未必能带来像GPT-2到GPT-4那样的能力飞跃。其背后有多重技术瓶颈。
环境构建的瓶颈:这是最根本的制约。预训练的数据是“找到”的,而RLVR的环境是需要“构建”的。构建一个高质量、高保真、多样化且能快速运行的模拟环境,本身就是一项巨大的软件工程挑战。如果要覆盖人类社会的所有技能,就等于需要为世界上的每一种软件、每一种流程都构建一个数字孪生。这个成本是无法估量的。
探索与利用的困境 (Exploration vs. Exploitation):在复杂的任务空间中,模型是应该继续利用已知的、能获得奖励的策略,还是应该去探索未知的、可能带来更高奖励的策略?这个平衡极难掌握。无效的探索会浪费大量算力,而过度的利用则会让模型陷入次优解。
奖励设计的陷阱 (Reward Hacking):模型会以最“聪明”的方式,找到达成奖励目标的捷径,而不是以我们期望的方式完成任务。
案例:一个任务是让AI智能体清理房间,奖励是“地面上的垃圾数量减少”。AI可能学会把垃圾藏在柜子里,而不是扔进垃圾桶,因为它同样能获得奖励。
设计一个无法被“黑”掉的、能准确反映任务真实意图的奖励函数,本身就是一门艺术,充满了挑战。
样本效率的低下 (Sample Inefficiency):相比监督学习,强化学习通常需要与环境进行天文数字般的交互次数,才能学到一个有效的策略。这使得训练过程极其耗时和耗能。尽管有模型基(Model-based)RL等技术试图提升样本效率,但问题仍未得到根本解决。
3.3 来自数据的悲观信号
一些研究者已经尝试从零星的公开数据中,拼凑出RLVR的规模化趋势,而结果往往是悲观的。例如,研究者Toby Ord通过巧妙地关联不同基准测试的结果,得出一个初步结论,即要通过强化学习获得类似GPT级别的能力提升,所需的总算力规模可能需要提升到一百万倍。
这个数字虽然不精确,但它传递了一个强烈的信号,即RLVR的收益曲线可能远比预训练要平缓。这意味着,在RLVR上投入同样的算力增量,所换来的能力提升会小得多。试图用预训练时代的“大力出奇迹”的思路来强攻RLVR,很可能会撞上一堵由环境复杂性和奖励稀疏性构成的叹息之墙。
(本轮输出字数:4589,总字数:4589。未完,请指示“继续”。)继续
📌 四、经济的冷思考:能力缺口而非扩散滞后
当讨论AI技术为何尚未大规模颠覆知识工作时,一个常见的解释是“技术扩散滞后”,即任何革命性技术都需要时间才能渗透到经济的毛细血管中。然而,这一解释可能过度简化了问题,并掩盖了更深层次的原因,即当前AI模型的核心能力,尚未达到触发大规模经济替代的临界点。
4.1 “AI员工”的理想与现实
我们可以通过构建一个理想的“AI员工”模型,来更清晰地审视当前技术的差距。一个能够被企业大规模“雇佣”的AI,应当具备以下关键特质。
这个对比清晰地表明,当前AI模型与一个合格的“数字员工”之间,还存在着巨大的鸿沟。企业需要的不是一个时而灵光、时而犯错的“实习生”,而是一个能承担责任、稳定交付的“正式工”。
4.2 戳破“技术扩散滞后”的迷思
“技术扩散滞后”理论更适用于那些需要重资本投入和物理基础设施改造的技术,例如电力或铁路。而AI作为一种纯软件技术,其扩散的物理障碍要小得多。Steven Byrnes提出的一个精彩类比是,高技能移民能够迅速融入经济体系。他们不需要等待整个社会的基础设施为他们重构,他们凭借自身的能力就能立即创造价值。
一个真正达到AGI水平的AI,其融入经济的速度应该比高技能移民更快,原因在于它克服了人类劳动力市场最大的摩擦点——信息不对称,即所谓的“柠檬市场”问题。
人类招聘:企业在招聘时,很难准确评估候选人的真实能力和品格,招错人的成本极高。这是一个典型的“柠檬市场”。
AI“招聘”:一旦一个AI模型实例的能力得到了充分验证,企业可以零风险地启动成千上万个完全相同的副本。不存在面试、试用期和能力不匹配的风险。
因此,企业有极强的动机去大规模采用一个能力达标的AI劳动力。现实中这种情况并未发生,唯一合理的解释是,模型的能力远未达标。实验室当前数十亿、数百亿美元的收入,与全球数十万亿美元的知识工作者薪酬总额相比,差了数个数量级。这个巨大的差距,直接反映了AI在创造真实经济价值上的能力赤字。
4.3 从“看起来很强”到“真正有用”的距离
2025年,一个愈发突出的现象是,模型在演示(Demo)和基准测试(Benchmark)中的表现,与在生产环境(Production)中的实际效用,差距正在拉大。
“看起来很强”:模型可以生成令人惊叹的图像、撰写流畅的文案、通过各种高难度的专业考试。这些成就使其在公众和投资者眼中显得异常强大。
“真正有用”:在真实的商业流程中,价值不仅仅来自于单点的任务完成能力,更取决于一系列非功能性需求,包括:
稳定性与一致性:每次都能以同样的高标准完成任务。
可解释性与可追溯性:当出现错误时,能够解释原因并追溯决策过程。
安全性与合规性:确保数据安全,并遵守行业法规。
与现有系统的集成:能够无缝地与企业现有的复杂IT系统协同工作。
这些工程和治理层面的要求,是决定AI能否从一个“有趣的玩具”转变为一个“可靠的生产力工具”的关键。而当前的模型在这些方面普遍存在短板。因此,我们看到的是一个“演示驱动”的繁荣,而非一个“价值驱动”的革命。
📌 五、终极挑战:通往“持续学习”的漫长征途
%20拷贝-ityk.jpg)
如果说“中训练”是对当前模型能力短板的被动修补,那么持续学习(Continual Learning)则是主动寻求突破、通往更高级别人工智能的根本路径。它被普遍认为是继预训练、对齐之后,AI发展的下一个关键范式。
5.1 什么是持续学习?
持续学习,又称终身学习(Lifelong Learning),指的是AI智能体在部署后,能够持续地从与环境的交互中获取新知识和新技能,同时不遗忘已经学到的旧知识的能力。这与当前主流的“一次性训练”(One-off Training)模式形成了鲜明对比。
一个具备持续学习能力的AI,才真正接近人类的学习方式。它能够像一个人类员工一样,在工作中不断成长、积累经验,变得越来越有价值。
5.2 持续学习的核心技术障碍:灾难性遗忘
实现持续学习的最大技术挑战,是灾难性遗忘(Catastrophic Forgetting)。当一个神经网络在学习新任务时,其网络权重会为了适应新任务而进行调整,这往往会破坏掉为旧任务存储的知识,导致模型在旧任务上的性能急剧下降。
想象一下,你教一个AI学会了下象棋,它表现得很好。然后你又教它下围棋,它也学会了。但当你再让它下象棋时,你可能会发现它已经忘得一干二净。这就是灾难性遗忘。
为了克服这一难题,研究界正在探索多种路径:
正则化方法 (Regularization-based):在学习新任务时,对那些对旧任务重要的权重参数施加一个惩罚,限制它们的改动幅度。例如,弹性权重巩固(EWC)。
回放方法 (Rehearsal/Replay-based):在学习新任务的同时,周期性地“复习”一小部分来自旧任务的数据,以巩固记忆。
动态架构方法 (Dynamic Architectures):根据新任务的需求,动态地扩展网络结构,为新知识分配新的神经元或模块,从而避免与旧知识发生冲突。
尽管已经取得了一些进展,但目前还没有任何一种方法能够完美地解决灾难性遗忘问题,尤其是在大规模、复杂的语言模型上。
5.3 对持续学习的理性预期
Dwarkesh预测,前沿实验室很可能在未来一两年内发布一些具备“雏形功能”的持续学习特性。这些早期版本可能表现为:
更频繁的模型更新:从每几个月更新一次,缩短到每周甚至每天。
从部署中学习(Learning-from-deployment):系统化地收集模型在实际应用中的交互数据(尤其是那些被人类纠正的案例),并将其反馈到训练流程中。
个性化实例:允许企业用户用自己的私有数据对模型进行轻量级的、持续的微调,使其更适应特定业务场景。
然而,这些都只是迈向真正人类级持续学习的第一步。要实现那种无缝、高效、无需监督的终身学习能力,可能还需要5到10年的持续研发和迭代。
重要的是,持续学习的解决,不会像GPT-3的发布那样是一个“一夜惊奇”的事件。它更可能是一个渐进式的、能力不断增强的演进过程。因此,我们不太可能看到某家公司因为在持续学习上取得了某个单点突破,就立刻获得了碾压性的、失控的领先优势。竞争仍将保持激烈,行业整体将在这个漫长的坡道上共同攀爬。
📌 六、价值评估的再校准:从“中位数”到“顶尖”的非线性冲击
在评估AI的潜在经济影响时,我们很容易陷入一个系统性的偏差,即将AI模型的能力与“中位数人类”进行比较。这种比较在短期内会让我们高估AI的价值,而从长期看,一旦AI跨越某个关键阈值,又可能会让我们严重低估其颠覆性冲击。
6.1 知识工作的价值分布:O-ring理论的启示
经济学家迈克尔·克雷默提出的O-ring理论为我们提供了一个深刻的洞察。该理论指出,在许多高价值的生产过程中,整体产出的质量取决于链条中最薄弱环节的质量。所有环节的表现是“乘法关系”,而非“加法关系”。任何一个环节的失败,都可能导致整个项目的价值归零。
知识工作,尤其是高附加值的白领工作,具有显著的O-ring特性。一个顶尖的软件工程师、律师或战略顾问,其创造的价值可能是一个平庸同行的十倍甚至百倍。这是因为他们能够在关键节点上做出正确的判断,避免了整个项目的失败。
价值分布:知识工作的价值高度集中在最顶尖的一小撮人手中。一个“村里的傻子”对知识工作的价值几乎为零,而一个顶尖的AI研究员对一家科技巨头来说可能价值数十亿美元。
AI能力分布:在任何一个时间点,AI模型的能力基本上是均值的、齐平的。它没有人类社会中那种巨大的个体差异。
6.2 评估偏差的两个阶段
基于这种价值分布的差异,我们对AI价值的评估会经历两个阶段的偏差。
第一阶段:高估AI价值
当我们说“AI已经达到了普通大学生的水平”时,我们很容易推断出它可以替代所有需要大学学历的工作。但这是一个错误的推论。因为即使是一个“中位数”水平的工作岗位,也包含了大量需要超出平均水平的判断力、沟通能力和处理异常情况的时刻。一个只能达到“中位数”水平的AI,在这些关键时刻会成为O-ring链条上的薄弱环节,导致其无法独立胜任工作。因此,用“中位数人类”作为参照,会系统性地高估AI在当前阶段能创造的经济价值。第二阶段:低估AI冲击
然而,这种局面会随着AI能力的持续提升而发生戏剧性的逆转。一旦某个AI模型的综合能力,真正达到了人类社会中最顶尖的1%或0.1%专家的水平,其影响力将是爆炸性的。原因在于AI的核心优势——可复制性。人类社会只有一个伊隆·马斯克或一个阿尔伯特·爱因斯坦。
但一个达到顶尖专家水平的AI,可以被瞬间复制出一百万份,以极低的边际成本,在全球范围内7x24小时不间断地工作。
到那时,其对生产力、科学发现和经济结构的冲击,将远远超出我们基于线性外推的想象。我们今天讨论的“自动化”将显得微不足道,那将是一场真正的智能爆炸。
结论
2025年的人工智能领域,正处在一个关键的转折点。曾经由Scaling Law驱动的、近乎信仰式的狂热正在退潮,取而代之的是对技术现实更为冷静和深刻的审视。Dwarkesh Patel等人的分析,为我们揭示了这幅新图景的核心脉络。
行业范式正从简单的规模扩张,转向以“中训练”和强化学习为手段的“技能注入”。这一转变虽然提升了模型的实用性,但其背后是对当前模型泛化能力和自主学习能力不足的无奈妥协。它是一条通往更强“工具”的路径,却未必是通往“通用智能”的捷径。
真正的瓶颈,已经清晰地指向了持续学习。如何让模型像人类一样,在开放、动态的环境中不断学习、适应和成长,同时不遗忘过去的知识,是通往AGI道路上最艰难、也最关键的一跃。这不会是一个一蹴而就的突破,而将是一个需要长期、持续投入的、充满工程智慧的攻坚过程。
对于身处其中的技术从业者而言,这意味着我们需要超越对模型参数和基准分数的单一崇拜,将更多的注意力投向系统的鲁棒性、学习机制的创新以及与真实世界流程的深度融合。AI的未来,不仅取决于算法的精妙,更取决于我们如何为它构建一个能够终身学习的“学校”和“社会”。从这个角度看,真正的挑战,才刚刚开始。
📢💻 【省心锐评】
AI正从“大力出奇迹”的预训练时代,进入“精耕细作”的后AGI时代。行业焦点已从堆砌算力转向攻克“持续学习”这一核心科学问题,这决定了AI从“高级工具”到“自主智能”的最终跨越。

评论