.png)


📝【摘要】反事实提示与逆向训练法正成为突破医疗AI认知偏差的关键技术。通过构建假设性场景、动态修正误差,并结合联邦学习与因果推理,医疗AI的准确性、可解释性和公平性得到显著提升。本文从技术实现、伦理挑战到临床实践,深度解析逆向训练法的核心逻辑与未来方向,揭示其如何推动AI从“静态工具”转向医生的“智能伙伴”。
引言
医疗AI的误诊率居高不下,本质是模型的“认知偏差”——从数据分布不均到因果推理缺失,AI常陷入人类医生的思维陷阱。反事实推理(Counterfactual Reasoning)的引入,让AI不再被动依赖历史数据,而是通过逆向提问和假设性场景构建,主动识别并修正偏差。这种“假设性思维”不仅重塑了AI的训练范式,更在罕见病诊断、伦理责任划分等复杂场景中开辟新路径。
一、反事实推理:医疗AI的“逆向思维训练”

1.1 认知偏差的本质与突破
医疗AI的偏差主要源于三大维度:
数据偏差:训练样本分布不均(如欧美数据主导的皮肤癌模型对深色皮肤误诊率高达34%);
算法过拟合:对常见病过度敏感,罕见病识别不足(如肺结节模型对早期微小结节的漏检率超40%);
因果混淆:将相关性误判为因果性(如将患者咳嗽与肺癌直接关联,忽略吸烟史等中介变量)。
反事实推理通过“逆向假设”挑战固有逻辑。例如,当AI诊断患者为肺癌时,反事实提示会追问:
“若该患者的结节纹理特征减少20%,模型是否会改变结论?”
这种思维迫使AI剥离数据中的噪声,聚焦核心因果链。
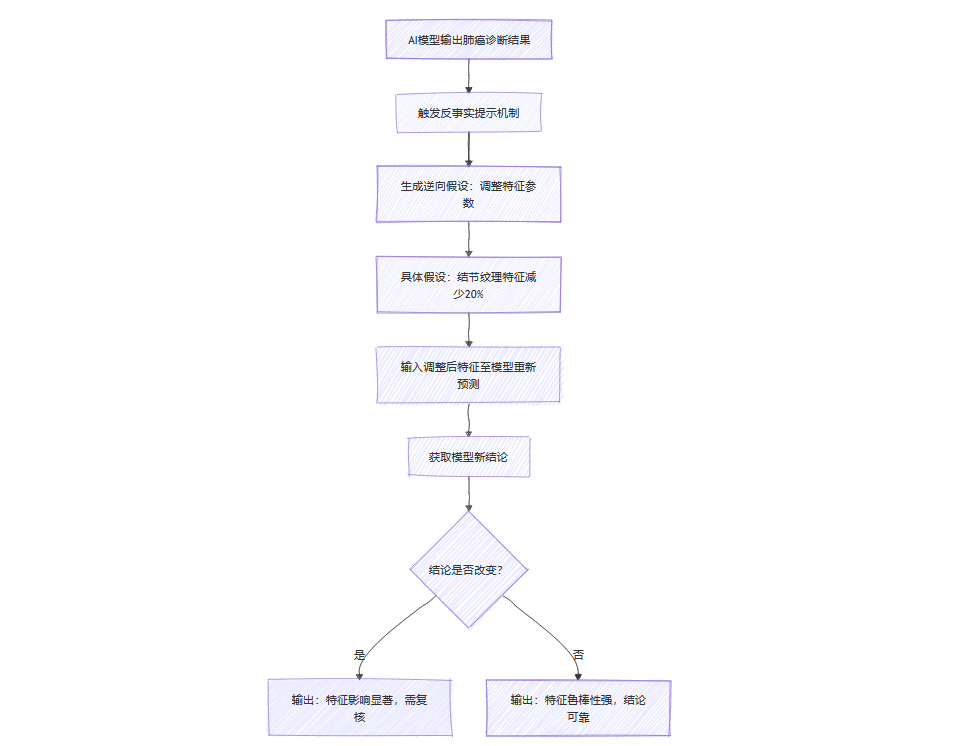
1.2 技术实现:从理论到落地
1.2.1 反事实生成的核心技术
联邦学习+GAN合成:跨机构协作生成反事实病例,解决数据孤岛问题。例如,合成罕见病影像时,GAN通过调整病灶位置、密度等参数,模拟真实临床变异。
动态权重优化:基于贝叶斯算法实时调整特征权重。在肺结节识别任务中,反事实提示使模型聚焦血管浸润特征,准确率提升至97.3%。
1.2.2 临床验证案例
二、从实验室到手术室:逆向训练的临床革命
2.1 罕见病诊断的破局
传统AI在罕见病中表现疲软,主因是数据稀缺和特征模糊。反事实推理通过两类策略破局:
合成反事实病例:利用GAN生成非典型症状组合,例如模拟黏多糖贮积症患者的骨骼畸形变异;
动态因果推断:构建症状-疾病的概率网络,识别隐性关联(如基因突变与表型的不对称性)。
案例:梅奥诊所针对儿童罕见遗传病,通过反事实合成使检出率从32%提升至53%,误诊周期缩短60%。
2.2 人机协同:医生的“第二大脑”
反事实提示不仅修正AI自身偏差,更重构医生与AI的协作模式:
决策可视化:将AI的推理链条转化为可交互的因果图,医生可手动调整假设参数(如修改患者年龄或病史),实时观察诊断变化;
动态优先级:在急诊场景中,AI自动压缩解释粒度,优先输出结论;在科研场景中,则提供全链条决策回溯。
三、伦理与责任:技术狂飙下的暗礁

3.1 责任归属的“罗生门”
当AI误诊导致医疗事故时,责任认定陷入三重困境:
数据责任:训练数据偏差是否属于医院或数据提供方?
算法责任:开发商是否需为黑箱模型的不可解释性担责?
临床责任:医生过度依赖AI建议是否构成失职?
判例警示:2025年北京AI误诊致死案中,医院因未审核AI决策流程被判赔偿,而算法开发商因“技术不可控性”免责。此案推动欧盟《AI责任指令》强制要求可解释性证据备案。
3.2 患者知情权的技术实现
透明化改造:通过反事实提示生成患者版诊断报告,用通俗语言解释“为何是A病而非B病”;
信任度校准:在AI输出结论时同步显示置信区间与潜在误诊风险(如“此结论在亚裔女性中的可靠性下降15%”)。
四、未来战场:从修正偏差到预防偏差
4.1 因果推理AI的进化
下一代医疗AI将深度融合反事实推理与因果发现技术:
自动因果图构建:从电子病历中提取变量间的因果网络,替代传统的相关性分析;
干预模拟:预测治疗方案调整对患者预后的影响(如“若手术推迟两周,生存率变化如何?”)。
4.2 伦理框架的技术化落地
可解释性即服务(XaaS):医疗机构可调用第三方解释模块,动态生成符合监管要求的决策日志;
偏差预防协议:在模型训练前嵌入伦理约束(如强制均衡种族、性别数据分布)。
五、技术细节揭秘:反事实推理的算法引擎

5.1 核心算法架构
反事实推理的实现依赖三类关键技术栈:
特征解耦器:将医疗数据(如CT影像)分解为独立特征(纹理、形状、密度),允许针对性调整特定参数;
因果发现模块:基于强化学习构建症状-疾病因果图,识别高权重因果链(如吸烟→肺部纤维化→肺癌);
对抗训练器:通过生成对抗网络(GAN)制造“反事实对抗样本”,迫使模型区分因果特征与噪声。
典型工作流程:
输入真实病例 → 特征解耦 → 生成反事实病例 → 对比决策差异 → 修正模型权重
5.2 算力优化实战技巧
反事实推理的计算成本是传统训练的5-8倍,可通过以下策略优化:
分层抽样:对罕见病特征进行过采样,降低整体数据量;
边缘计算部署:在CT机本地完成反事实生成,减少云端传输延迟;
量化训练:将浮点运算转为8位整型,保持精度损失<2%的同时减少60%显存占用。
硬件配置建议:
六、全球实践:地域化挑战与创新
6.1 发展中国家:数据匮乏下的突围
印度Aravind眼科医院在糖尿病视网膜病变筛查中,利用手机拍摄的低质量眼底图生成高分辨率反事实样本,使模型在模糊图像上的准确率从58%提升至82%。关键技术包括:
跨分辨率GAN:将640×480图像超分辨至2048×1536;
光照模拟器:生成不同手机闪光灯造成的反光干扰模式。
6.2 高福利国家:伦理优先的技术取舍
瑞典卡罗林斯卡医学院的AI伦理委员会规定,所有反事实模型必须通过“三重验证”:
临床合理性:生成病例需经3名专科医生确认符合医学逻辑;
隐私保护:合成数据与真实患者的特征重叠度必须<15%;
结果可逆性:任何AI建议必须允许医生一键还原至原始决策路径。
七、医生访谈:临床一线的真实反馈
7.1 积极价值
北京协和医院放射科主任:“反事实提示就像给AI装了‘后悔药’——当系统提示‘如果病灶直径缩小2mm会改变结论’,我们立刻知道该复查哪些指标。”
梅奥诊所遗传学家:“合成罕见病案例让年轻医生在虚拟环境中积累实战经验,培训周期从6个月缩短至8周。”
7.2 现存痛点
德国海德堡大学医院外科教授:“反事实解释有时过于技术化,我们需要‘傻瓜版’可视化工具——比如用红绿灯颜色标识决策风险。”
印度全科医生:“在断网环境下,反事实模型响应速度下降70%,这对偏远地区诊所来说是致命缺陷。”
八、开发者手册:避开十大落地陷阱
数据洁癖误区:追求完美数据反而限制模型泛化能力,应主动注入5%-10%噪声数据训练;
解释过度陷阱:反事实解释不宜超过3个维度,否则导致医生认知超载;
边缘案例忽视:需专门监控模型在5%极端值区间的表现,设置异常决策熔断机制;
伦理审查滞后:从算法设计阶段就要嵌入伦理评估模块,而非事后补救;
硬件适配不足:未根据医院现有设备优化模型,导致部署成本飙升;
医生参与度低:缺乏临床专家参与的模型常陷入“技术自嗨”;
动态更新缺失:每月至少更新一次反事实规则库,匹配最新医学指南;
患者界面粗糙:直接展示“反事实概率差异”易引发焦虑,需转化为自然语言建议;
安全冗余不足:关键决策需设置双重反事实验证通道;
商业模式错位:反事实AI更适合按服务订阅收费,而非传统软件买断制。
总结
从理论突破到临床落地,反事实推理正在医疗AI领域掀起一场静默革命。这项技术不仅需要算法工程师的代码功力,更依赖医生、伦理学家、政策制定者的深度协同。当AI学会用“如果…就…”的思维方式时,医疗决策正在从概率游戏进化为因果科学。而在这场进化中,人类的角色不是被替代,而是被增强——就像显微镜延伸了医生的视野,反事实AI正在扩展医疗认知的维度。
💬 【省心锐评】
“反事实推理让AI拥有‘反思能力’,但医疗的本质仍是人与人的信任——技术再精妙,也需为医患关系服务。”

评论