.png)


【摘要】AI大模型正从追求规模转向追求效率。混合推理通过智能调度大小模型与融合多种推理范式,破解了性能、速度与成本的难题,标志着行业进入一个更聪明、更经济、更可持续的智能协作新时代。
引言
在人工智能的浪潮之巅,一场深刻的变革正在悄然发生。过去,我们习惯于用参数规模来衡量一个模型的强大与否,仿佛这是一场永无止境的军备竞赛。但现在,风向变了。从美团最新开源的龙猫大模型,到行业翘首以盼的GPT-5,再到明星创业公司DeepSeek的新品V3.1,顶尖玩家们似乎达成了一个心照不宣的共识。他们不再仅仅追求“更高、更强”,而是将目光聚焦于一个更核心、更务实的问题,如何让AI“更聪明、更经济”。
一个反直觉的现象正在行业内蔓延。明明单个Token的价格在持续下降,但许多AI应用服务的订阅费却在悄然上涨。TextQL的联合创始人丁一帆一语道破天机,人类在认知上总是贪婪地追求“最强大脑”,99%的需求最终会涌向最顶尖的SOTA模型。而这些顶尖模型的推理成本,始终居高不下。
AI越“聪明”,似乎就越昂贵。一次简单的聊天问答可能只消耗几百个Token,但一项复杂的代码生成或法律文书分析,消耗的Token数量可能飙升至数十万甚至上百万。这种成本压力已经实实在在地传导到了应用层,一些公司的利润率因此受到挤压,一些AI工具也不得不调整定价策略。
“争夺最智能模型的竞赛,已经演变成了争夺最昂贵模型的竞赛。” T3 Chat首席执行官的这句感叹,正是行业困境的真实写照。
如何破解这个成本与性能的“魔咒”?答案,正指向一个共同的方向——混合推理(Hybrid Inference)。这不仅是一项技术,更是一种全新的设计哲学。它让AI系统学会了“量体裁衣”,根据任务的复杂程度,智能地选择最合适的计算资源。这标志着AI大模型的发展,正式告别了“杀鸡用牛刀”的蛮力时代,迈入了一个更加精细、高效的智能调度新纪元。
一、拨云见日:到底什么是混合推理? 🎯
%20拷贝.jpg)
混合推理,这个词听起来可能有些抽象,但它的核心思想却异常直观。它指的是AI在进行推理(即生成答案)的过程中,不再死板地依赖单一的巨大模型,而是像一个高度协同的智慧团队,智能地融合多种模型、多种推理方式和多种计算资源。
这个“智慧团队”会根据用户请求的复杂性和类型,动态地选择一条最优的解题路径,最终目标是在性能、效率和成本之间找到那个完美的平衡点。
我们可以从两个层面来理解它。
1.1 系统层面:智能的交通指挥官
在系统架构层面,混合推理的核心是一个**“路由器”(Router)或者叫“调度器”(Dispatcher)**。它本身通常是一个轻量级的AI模型,扮演着交通指挥官的角色。当一个用户请求进来时,路由器会第一个接手。
它的工作不是直接回答问题,而是快速判断这个问题的“斤两”。
这个问题简单吗?
它属于哪个领域?
需要动用多少“脑力”才能完美解决?
判断之后,它会将请求精准地分发给后台最合适的执行单元。
为了更形象地理解,我们可以把它比作一个顶级的咨询公司。
前台(路由器):客户带着问题上门。前台接待员会快速评估,这是一个常规咨询还是一个复杂的战略项目。
初级助理(小型模型):如果是“下午三点的会议室在哪”这类简单问题,前台会直接交给助理。助理反应迅速,处理成本极低,几秒钟就能给出答案。
资深合伙人(大型专家模型):如果问题是“如何为公司制定未来五年的全球市场扩张战略”,前台会立刻将客户引荐给资深合伙人团队。他们虽然“出场费”高昂,但能确保提供最高质量的解决方案。
资料库与外部顾问(RAG与符号推理):在解决复杂问题时,合伙人可能还需要查阅公司的知识库(检索增强),或者调用外部的法律、财务顾问(符号/规则推理)。
这个流程,就是混合推理在系统层面的生动写照。它确保了每一分宝贵的计算资源,都用在了刀刃上。
1.2 推理范式层面:十八般武艺融会贯通
在更深的推理范式层面,混合推理则体现为一种“博采众长”的智慧。它不再局限于单一的神经网络推理,而是将多种推理范式有机地融合在一起,取长补短。
神经网络推理:这是当前大模型的主流,擅长处理模式识别、语言理解和内容生成,具有强大的泛化能力。
符号推理:基于逻辑、规则和知识图谱进行推理。它的过程清晰、可解释性强,在数学、逻辑推导等领域表现出色。
检索增强推理(RAG):通过动态查询外部知识库(如互联网、专业数据库),来获取实时、准确的信息,有效缓解模型的“幻觉”问题。
多模态推理:能够同时理解和处理文本、图像、音频、视频等多种信息源,构建对世界更全面的认知。
混合推理将这些范式巧妙地编织在一起。一个复杂的任务可能首先由神经网络进行初步解析,然后调用符号推理模块进行严谨的逻辑校验,同时通过RAG获取最新的外部信息,最终生成一个既有创造性又事实准确的答案。
所以,混合推理既是系统架构层面的宏观调度,也是核心算法层面的微观融合。这两者共同构成了这项技术的完整图景,推动AI从一个“偏科生”成长为一个“全能选手”。
二、势在必行:混合推理的目标与深远意义 🧭
为什么混合推理会成为行业顶尖玩家的共同选择?因为它精准地瞄准了当前AI发展中最核心的几个痛点,并提供了一套行之有效的解决方案。它的目标和意义,远不止降低成本那么简单。
2.1 破解不可能三角:性能、速度与成本的三重平衡
长期以来,AI大模型服务似乎陷入了一个“不可能三角”的困境。你想要极致的性能(如GPT-4的智能水平),就必须忍受高昂的推理成本和较慢的响应速度。反之,如果追求低成本和高速度,又不得不在模型能力上做出妥协。混合推理的出现,正是为了打破这个僵局。
2.1.1 极致的性价比
绝大多数用户在日常使用中提出的问题,比如闲聊、简单问答、文本摘要,并不需要一个千亿甚至万亿参数的“核武器”来解决。用一个巨型模型去回答“你好”,就像开着航空母舰去钓鱼,性能严重过剩,资源极大浪费。
混合推理的核心价值在于,让90%以上的简单、高频任务,由一个极小、极快、极便宜的模型来处理。只有当系统识别到真正棘手的复杂任务时,才会唤醒那个昂贵但强大的“专家模型”。以DeepSeek V3.1为例,官方数据显示它能用一个小模型处理掉98%的常见请求。这种智能分流,使得整体服务的平均成本被大幅拉低,实现了前所未有的性价比。
2.1.2 最佳的用户体验
大模型响应慢,是用户体验中的一个普遍痛点。在等待答案生成的过程中,每一秒的延迟都是对用户耐心的考验。
混合推理带来了体验上的跃升。简单问题,秒速响应,让交互如行云流水。复杂问题,虽然耗时可能稍长,但用户知道系统正在进行“深度思考”,并且最终能得到一个高质量的答案。这种“快慢结合、张弛有度”的体验,远胜于所有问题都只能“慢慢来”的单一模式。
2.1.3 高效的资源利用与绿色AI
数据中心的GPU资源是有限且昂贵的。让成千上万张GPU时刻满负荷运行一个巨型模型,不仅耗电巨大,能效比也很低。
混合推理实现了计算资源的动态按需分配。在请求量大但多为简单的时段,系统可以只激活小型模型集群,让大部分GPU处于低功耗或休眠状态。这不仅为企业节省了大量的能源和算力开销,也符合全球对“绿色AI”和可持续发展的倡导。
2.2 超越简单问答:推理能力与可解释性的双重提升
混合推理的意义不止于降本增效,它还为提升AI的核心智能开辟了新的路径。
2.2.1 攻克复杂推理的堡垒
单一大模型在处理多步推理、事实验证、数学推导、复杂代码生成等任务时,常常会遇到瓶颈。通过融合多种推理范式,混合推理能够显著增强这方面的能力。例如,面对一个复杂的数学题,系统可以先用神经网络理解题意,然后调用符号推理引擎进行公式推导和演算,最后再用自然语言生成详细的解题步骤。这种协同作战的方式,远比单个模型“闭门造车”要强大得多。
2.2.2 增强AI决策的可解释性
“黑箱”问题一直是神经网络的阿喀琉斯之踵。我们往往只知道输入和输出,却不清楚模型内部的决策过程。混合推理通过引入符号推理、规则引擎等模块,为AI的决策过程打开了一扇窗。在某些关键应用领域(如医疗、金融、法律),部分推理过程可以变得更加透明、可控、可追溯,这对于建立人与AI之间的信任至关重要。
2.3 拥抱万物互联:适应多场景与多模态的未来
未来的AI必然是无处不在的。混合推理的架构,使其天然具备了极强的适应性和扩展性。
多模态融合:通过专门的多模态理解与生成模块,系统可以轻松支持文本、图像、音频等多种信息的输入和输出,适应更加丰富和自然的人机交互场景。
广泛部署:混合推理的理念,使得AI能力可以更灵活地下沉。在云端,可以部署完整的“模型矩阵”提供顶级服务。在边缘设备或资源受限的场景中,可以只部署轻量级的路由器和小型模型,实现本地化的快速响应。这为AI能力的普惠化提供了可能。
三、庖丁解牛:混合推理的技术原理与实现路径 🛠️
%20拷贝.jpg)
理解了混合推理的目标,我们再来深入其内部,看看这个精密的系统是如何运转的。它的实现,主要依赖于几大核心组件和关键技术的协同工作。
3.1 核心大脑:路由器与调度机制
路由器是整个混合推理系统的“神经中枢”,它的性能直接决定了整个系统的效率和体验。
3.1.1 路由器的角色与挑战
路由器本身通常是一个经过特殊训练的轻量级AI模型。它的唯一使命,就是**“预测任务的复杂性与类型”**。当一个用户请求(Prompt)进来时,它会快速分析文本的语义、结构、指令的复杂度等特征,然后输出一个决策,比如“这个任务交给7B小模型处理”或“这个任务必须启动180B大模型,并调用RAG模块”。
这个决策过程对准确性的要求极高,因为一旦出错,后果很严重。
错判一(高风险):将复杂任务误判为简单。这会导致用户得到一个质量低劣、甚至完全错误的答案,严重损害用户体验和信任。这是系统需要极力避免的。
错判二(低风险):将简单任务误判为复杂。这会造成计算资源的浪费,削弱了混合推理的成本优势,但通常比第一种错误的后果要轻。
3.1.2 路由器的训练之道
训练一个优秀的路由器是技术上的关键难点。这通常需要构建一个庞大的、高质量的标注数据集。数据集中,每一个Prompt都需要被精心地标注上它“应该由哪个模型或哪条路径处理才能达到最佳效果”。这个标注过程本身就需要大量的专家知识和实验验证。从技术上讲,这属于**元学习(Meta-learning)**的范畴,即“学习如何学习”或“学习如何分配任务”。
3.2 执行团队:专家模型与模型矩阵
路由器的背后,是一个由能力各异的模型组成的“专家团队”,我们称之为模型矩阵(Model Matrix)。这个矩阵至少包含以下角色。
在更高级的架构中,路由器可以根据任务类型,进行更精细化的调度,比如将一个编程问题直接发送给代码专家模型,将一个数学问题发送给数学专家模型,实现专业问题专业解决。
3.3 组合拳:多种推理范式的深度融合
一个强大的混合推理系统,不仅要有优秀的模型团队,还要让他们掌握多种“武功”,即融合多种推理范式。
3.3.1 神经推理(Neural Reasoning)
这是基石。所有深度学习模型都基于此,负责感知、表征和生成。它赋予了系统强大的模式识别和自然语言处理能力。
3.3.2 符号推理(Symbolic Reasoning)
这是严谨的逻辑家。通过引入规则库、逻辑引擎、知识图谱等,系统可以进行显式的知识推理。这在需要精确性和可解释性的场景中至关重要,比如验证一个数学证明的每一步是否正确。
3.3.3 检索增强推理(RAG)
这是博闻强记的图书管理员。当模型需要回答一个涉及最新事实或专业领域知识的问题时,RAG模块会先去外部知识库(如维基百科、公司内部文档、实时新闻源)进行检索,然后将最相关的信息提供给模型作为上下文,辅助它生成更准确、更与时俱进的答案。
3.3.4 推理链与自我反思(Reasoning Chain & Self-Reflection)
这是系统进行深度思考的方式。
思维链(Chain-of-Thought, CoT):引导模型在回答复杂问题前,先一步步地拆解问题、进行中间推理,就像人类打草稿一样,显著提升了复杂任务的准确率。
自我反思/修正:更高级的系统会让模型生成初步答案后,再启动一个“批判者”或“验证者”模块来检查答案的逻辑、事实和完整性,如果发现问题,则进行修正和迭代,直到输出一个高质量的最终结果。
3.4 流程可视化:一个请求的完整旅程
为了更清晰地展示整个工作流程,我们可以使用一个流程图来描绘。
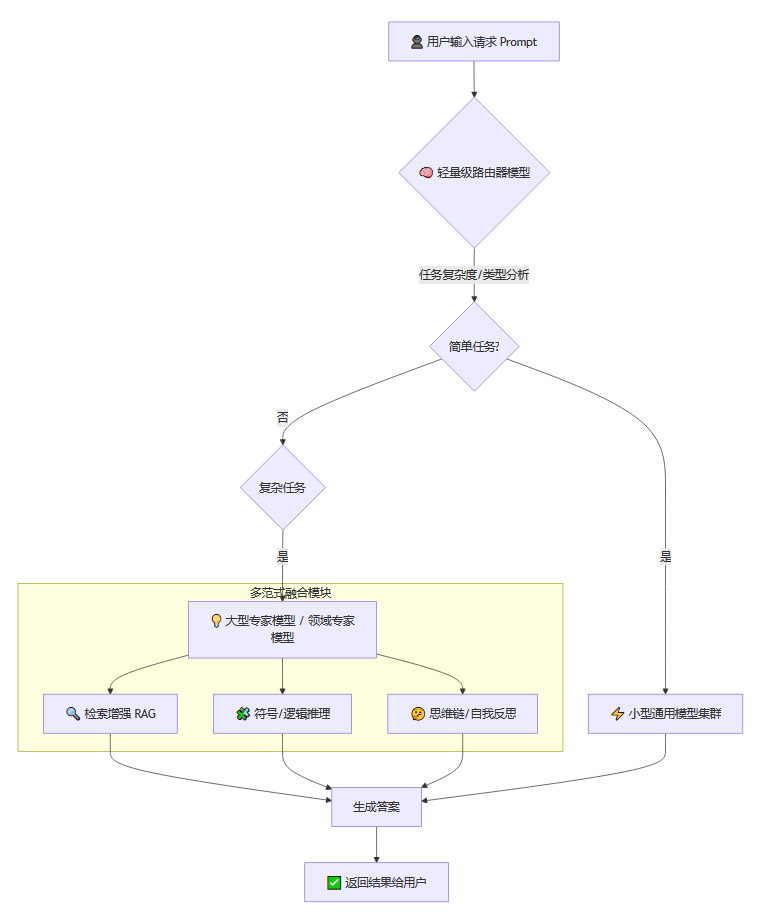
3.5 其他关键技术:润滑与加速
除了上述核心组件,还有一些关键技术在幕后默默工作,确保整个系统高效运转。
渐进式推理/早期退出(Progressive Inference / Early Exiting):对于一些简单的生成任务,模型可能在生成过程的中间步骤就已经得到了足够确信的结果。此时,系统可以提前终止计算,直接输出答案,从而节省大量的计算资源。
硬件-软件协同优化:顶级的混合推理系统会在硬件层面进行深度优化,结合CPU、GPU、专用AI芯片(NPU/TPU)等异构硬件的优势,并将部分计算任务下沉到边缘设备,实现云-边协同,进一步提升效率和响应速度。
结果融合(Result Fusion):在某些高风险或高要求的场景下,路由器可能会将同一个请求发送给多个不同的模型并行处理,然后通过一个融合模块对多个结果进行比较、投票或整合,以输出一个准确率和鲁棒性都更高的最终答案。
四、溯本求源:与MoE等相关技术的关系 🔗
谈到混合推理,很多人会立刻联想到另一个热门技术——专家混合模型(Mixture of Experts, MoE),例如Mixtral 8x7B模型。这两者是什么关系?
简单来说,它们是同一思想在不同层级上的体现。
MoE(专家混合模型):它是一种模型内部的架构。在一个巨大的模型中,存在多个“专家”子网络(通常是前馈神经网络)。当模型处理**每一个Token(词元)时,一个微型的门控网络(Gating Network)会动态地选择激活其中一两个专家来参与计算。这是一种“微观层面”**的资源调度,旨在用更少的计算量完成单次前向传播,让模型在保持巨大知识容量的同时,降低训练和推理的实际开销。
混合推理(Hybrid Inference):它是一种系统层面的架构。它在多个独立的、完整的模型之间进行选择。它的调度单位是整个用户请求(Prompt),而不是单个Token。这是一种**“宏观层面”**的智能调度,旨在优化整个AI服务的成本、延迟和资源分配。
我们可以用一个比喻来区分。
MoE 就像一个大脑内部的运作机制。当你思考一个词时,大脑的不同神经元区域会被激活。这是微观的、内部的。
混合推理 就像一个公司的决策机制。面对一个项目,公司高层决定是让市场部独立完成,还是让研发部牵头,或者成立一个跨部门的联合项目组。这是宏观的、系统级的。
所以,混合推理可以看作是MoE思想在系统架构层面的延伸和升华。它们并不互斥,反而可以完美结合。一个混合推理系统中的那个“大型专家模型”,其本身完全可以采用MoE架构来实现。这种“宏观调度+微观优化”的组合,能够将资源效率推向极致。
五、前沿观察:顶尖玩家的实践与探索 🌐
%20拷贝.jpg)
混合推理并非纸上谈兵,它已经成为行业领导者们正在积极部署的战略方向。
DeepSeek V3.1 的实践最为典型和透明。它明确提出了单模型双模式的架构,通过特定标记,让系统在处理简单对话和复杂推理之间切换。其“98%请求由小模型处理,2%复杂请求交由大模型”的策略,为业界提供了一个极具性价比的开源选择范本。
OpenAI的下一代模型(如传闻中的GPT-5) 据信也深度采用了“路由器”机制。对于“天空为什么是蓝色”这类常识问题,系统会调用轻量级模型快速作答。而对于需要深度思考的复杂任务,则会启动高算力的核心模型。据称,这种模式能以比前代少50-80%的输出Token完成同等质量的任务,并通过持续学习用户反馈来不断优化路由策略。
美团的“龙猫”(LongCat-Flash) 则展示了另一种巧妙的思路。它创新的“零计算”专家机制,能智能识别输入中的非关键部分(如常见词、标点符号),并让一个不进行复杂运算的特殊“专家”直接返回输入,从而在细粒度上节省了大量算力。
其他头部玩家,从Anthropic的Claude系列、Google的Gemini系列,到国内的阿里Qwen、快手KwaiCoder、字节豆包以及智谱GLM等,几乎都在探索自己的混合推理或自适应计算方案。虽然具体实现路径各不相同,但核心目标高度一致,即在性能与成本之间找到那个最佳的黄金分割点。
六、未来图景:通往通用智能的智慧之路 ✨
混合推理为我们描绘了一幅激动人心的未来图景。AI大模型的发展,将不再是单一维度的线性增长,而是向着一个更加立体、智能、高效的生态系统演进。
更智能的“元模型”调度器:未来的路由器将不再是简单的分类器,而是一个强大的“元模型”。它能够通过强化学习等方式,从海量的服务日志中自动学习最优的路由策略,甚至可以根据当前系统的负载、能源价格等因素,动态调整资源分配,实现全局最优。
更丰富的模型库与推理范式:模型矩阵将变得空前丰富,涵盖成百上千个不同领域、不同大小、不同功能的模型和算法组件。系统将能够像搭积木一样,为每一个独特的任务,动态地“组装”出一个临时的、最优的解决方案。
硬件-软件的深度融合:AI推理将与异构计算硬件进行更深度的协同演进。未来的AI芯片可能会内置任务调度的逻辑,实现硬件层面的“混合推理”,将效率提升到新的数量级。
自适应与持续学习的闭环:整个系统将形成一个完美的自适应学习闭环。它能精准地自我评估任务难度,在无人干预的情况下,以最低的计算代价,在最恰当的时机启动深度思考。用户的每一次交互,都在帮助这个系统变得更聪明、更高效。
结论
混合推理的兴起,标志着AI大模型行业正在经历一次深刻的范式转移。我们正从一个崇尚“暴力美学”、不计成本追求模型规模的1.0时代,迈向一个注重“智慧调度”、追求极致效率与可持续发展的2.0时代。
这不再是一个关于“更大”的故事,而是一个关于“更聪明”的故事。未来的顶尖AI,将不再是一个孤立的、庞大的“数字大脑”,而是一个由无数智慧单元协同作战、高效运转的复杂生态系统。它通过智能地调度多种模型、融合多种推理范式和高效地利用计算资源,实现了性能、效率、成本和可解释性的多重突破。
这不仅是技术的进步,更是思想的成熟。它为AI的普惠化、智能化和可持续发展铺平了道路,将推动人工智能在更广泛、更复杂的真实世界场景中,释放出前所未有的巨大潜力。这条路,通向的不仅是更强大的AI,更是一个更智慧、更高效的未来。
📢💻 【省心锐评】
告别算力内卷,回归价值创造。混合推理不是技术捷径,而是AI走向成熟的必然选择。它让每一瓦电力都服务于真正的智能,而非模型的虚荣。

评论