.png)
%20%E6%8B%B7%E8%B4%9D-vbdu.jpg)

【摘要】AGI实现路径正分裂为两大阵营。规模定律派主张通过算力与数据扩张逼近智能,而世界模型派则倡导重构认知架构,以应对物理理解与因果推理的根本挑战。
引言
人工智能领域正处在一个关键的十字路口。通用人工智能(AGI)从一个遥远的哲学概念,迅速演变为一个严肃的工程议题。驱动这一转变的核心力量,无疑是过去数年间由“规模定律”(Scaling Law)所主导的技术范式。它以一种近乎蛮横的姿态,证明了计算资源与智能水平之间存在着惊人的正相关性。然而,当这条道路的拥护者们高歌猛进,试图用更大的模型、更多的数据冲向AGI的终点线时,另一股思潮也在悄然集结。这股力量对规模的普适性提出了深刻质疑,并试图开辟一条全新的航道,一条更侧重于认知架构与世界理解的航道。
这场争论的核心人物,分别是谷歌DeepMind的德米斯·哈萨比斯(Demis Hassabis)与图灵奖得主杨立昆(Yann LeCun)。他们分别代表了通往AGI的两条技术主航道。一条是基于现有Transformer架构的持续规模化,另一条是探索全新认知框架的范式革新。这并非简单的技术路线分歧,它关乎未来十年AI领域的资源配置、研究方向乃至最终的智能形态。本文将深入剖析这两条主航道的技术内涵、现实瓶颈与战略分野,并探讨它们未来可能的融合路径。
💠 一、规模定律:AGI的“暴力美学”与工程主轴
%20拷贝-caxp.jpg)
规模定律是当前大模型时代最底层的信仰。它并非一个严谨的物理定律,而是一个通过大量实验总结出的经验性规律。这个规律精准地刻画了模型性能与三个核心变量之间的关系。
1.1 规模定律的技术内涵
规模定律的本质是一种幂律关系(Power Law)。它指出,在模型架构、算法等其他因素保持不变的前提下,模型的损失(Loss,可以理解为模型的“错误率”)会随着三个因素的增加而稳定下降。
模型参数规模(N):即模型中可训练参数的数量,通常以十亿(Billion)为单位。
训练数据量(D):用于训练模型的数据集大小,通常以Token数量衡量。
计算资源投入(C):即用于训练的总计算量,通常用FLOPs(每秒浮点运算次数)来度量。
这个关系可以用一个简化的公式来描述:
L(N, D, C) ≈ E_min + A/N^α + B/D^β + G/C^γ
其中 L 代表模型最终的损失值,E_min 是理论上可能达到的最低损失。A, B, G 和 α, β, γ 都是通过实验拟合出的常数。这个公式告诉我们,只要持续增加N、D、C中的任何一个或多个变量,模型的性能就会不断逼近理论最优值。
这种简单而强大的关系,为AI研发提供了一种前所未有的确定性。它让AI的进步从依赖天才灵感的“炼丹”,变成了一项可以被规划、被预算、被执行的大规模工程。谷歌、OpenAI、Meta等头部科技公司正是基于这一定律,制定了清晰的路线图,将数百亿美元的资金投入到算力集群和数据中心的建设中。可以说,规模定律就是AI时代的“摩尔定律”,它为整个行业提供了未来数年的发展惯性。
1.2 哈萨比斯的观点:规模化是核心路径
德米斯·哈萨比斯是规模定律最坚定的支持者之一。他领导的DeepMind在AlphaGo、AlphaFold等项目上早已展现了其对大规模计算和强化学习的深刻理解。在他看来,当前的大语言模型和多模态模型远未达到其能力的上限。
他的核心观点可以概括为以下几点:
智能是规模的涌现:许多高级能力,如上下文学习(In-context Learning)、思维链(Chain-of-Thought)推理,并非被直接设计出来的,而是在模型规模跨越某个阈值后“自然涌现”的。因此,有理由相信,更复杂的智能形态,甚至自我意识的雏形,也可能通过进一步扩大规模而涌现。
现有架构潜力未尽:Transformer架构本身仍然非常强大且灵活。在触及其根本性天花板之前,通过持续扩大规模,并辅以工程上的优化(如更高效的注意力机制、更优化的训练策略),足以在未来5-10年内持续推动AI能力的飞跃。
规模化是AGI的必要组成:哈萨比斯并不认为规模化是AGI的全部。他承认,最终可能还需要一到两次范式级别的创新来补足短板。但这并不妨碍将规模化视为通往AGI的核心路径和关键组成部分。就好比建造一座摩天大楼,即使最终需要一个巧妙的穹顶设计,也必须先打下坚实且庞大的地基。
下表总结了近年来主流大模型在规模上的演进趋势,直观地展示了规模定律在实践中的应用。
从这张表中可以清晰地看到,模型参数规模和数据量的增长与模型能力的质变几乎是同步发生的。这正是哈萨比斯及其代表的“规模派”信心的来源。
💠 二、规模路线的三重枷锁:数据、算力与能耗的物理极限
尽管规模定律的指引清晰有力,但这条看似笔直的康庄大道并非没有尽头。随着模型规模的持续膨胀,整个行业正逐渐逼近三堵由物理世界和经济规律构筑的“高墙”。
2.1 瓶颈一:高质量数据的枯竭
大模型的性能高度依赖于高质量、多样化的训练数据。然而,地球上由人类创造的高质量数据是有限的。
存量见底:根据Epoch AI Research等机构的估算,全球高质量的文本数据总量大约在10万亿到100万亿Token之间。目前顶级的模型训练已经消耗了其中的相当一部分。预计在2026年左右,高质量的公开文本数据将被全部“喂”完。
质量下降:当高质量数据源(如维基百科、高质量书籍、经过筛选的网页、GitHub代码)被用尽后,研究人员不得不转向质量更低的数据源。这些数据可能包含更多的噪声、偏见甚至错误信息,继续使用它们可能会“污染”模型,导致模型性能提升的边际效益快速递减,甚至出现能力退化。
合成数据的困境:一个看似可行的解决方案是使用模型自己生成的数据(即合成数据)来继续训练。但这带来了“模型近亲繁殖”的风险。如果一个模型持续学习由前代模型生成的数据,它可能会不断放大已有数据中的偏见和错误,最终导致思维僵化和创造力枯竭,陷入一种“数字马尔萨斯陷阱”。
2.2 瓶颈二:算力与成本的失控
模型规模的增长与所需算力的关系并非线性,而是超线性的。根据OpenAI的研究,从2012年到2018年,顶级AI模型训练所用的算力每3.4个月就翻一番,这是一个远超摩尔定律的指数级增长。
训练成本:训练一个GPT-4级别的模型,据估算需要消耗数千万甚至上亿美元的算力成本。未来更大规模的模型,其单次训练成本可能达到数十亿美元。这使得AI研发成为一场只有少数科技巨头才能参与的“资本游戏”,中小企业和学术界被彻底排挤出局。
硬件瓶颈:尽管NVIDIA等公司在不断推出更强大的GPU,但芯片制造本身也受限于物理定律。此外,构建和维护超大规模的算力集群,还需要解决网络通信带宽、内存墙、存储I/O等一系列复杂的工程挑战。
推理成本:除了训练,模型的日常运行(推理)也需要巨大的算力。一个拥有数十亿用户的AI应用,其推理成本可能远超训练成本,成为商业模式能否成立的关键。
下图展示了模型规模与训练成本的指数级增长关系。
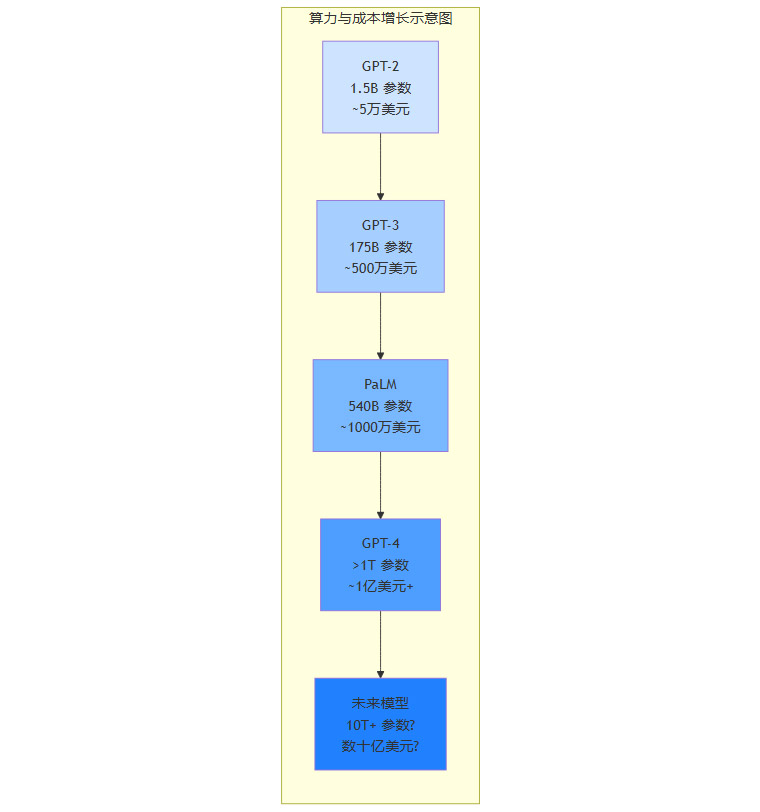
2.3 瓶颈三:能源与碳排放的压力
大规模AI计算是一个高能耗的过程。一个大型数据中心的耗电量堪比一座中型城市。
直接能耗:训练一次GPT-3所消耗的电量,足以供应一个美国家庭使用数十年。其产生的碳排放量,相当于一辆汽车环绕地球数十圈。随着模型规模的增长,这个问题会愈发严重。
间接能耗(水资源):数据中心需要大量的水来进行冷却。据报道,微软为训练GPT-4所消耗的淡水就高达数万吨。在水资源日益紧张的今天,这构成了严峻的环境挑战。
可持续性与监管风险:日益增长的能耗和碳足迹,不仅推高了运营成本,也带来了巨大的社会和监管压力。未来,政府和环保组织可能会对AI行业的碳排放施加更严格的限制,这将直接制约规模化路线的推进。
这三重瓶颈共同构成了一道“物理天花板”,迫使业界开始严肃思考:在抵达天花板之前,我们能否找到一条更高效、更可持续的路径通往AGI? 杨立昆和他的“世界模型”理论,正是在这个背景下,提供了一个截然不同的答案。
💠 三、世界模型:认知架构的范式革命
%20拷贝-jmwf.jpg)
与哈萨比斯对规模定律的乐观态度形成鲜明对比,杨立昆对当前主流的大语言模型(LLM)路线持强烈的批判态度。他认为,无论LLM的规模做得多大,其本质缺陷决定了它永远无法通向真正的智能。他所倡导的“世界模型”(World Model),则代表了一种根本性的范式转变。
3.1 杨立昆的批判:LLM的根本局限
杨立昆的反对意见并非简单的修修补补,而是直指LLM架构的根基。他认为LLM存在几个无法通过扩大规模来解决的根本性问题。
缺乏对物理世界的理解:LLM的训练数据绝大部分是互联网上的文本。它们学习的是词与词之间的统计关系,而不是词所指代的现实世界中的实体和规律。因此,LLM不理解重力、不懂物体永存性、不明白液体会流动。它们可以生成关于这些概念的文本,但那只是基于模式匹配的“鹦鹉学舌”,而非真正的理解。
无法进行真正的因果推理:由于缺乏世界模型,LLM难以区分相关性与因果性。它们可以从数据中学会“闪电之后通常有雷声”,但无法理解“闪电是雷声的原因”。这种缺陷使得它们在需要进行复杂规划、反事实推理和科学发现的任务中表现不佳。
被动的、自回归的生成模式:LLM的核心机制是“自回归预测”,即根据前面的文本预测下一个最可能的词。这是一种被动的、反应式的系统。它没有内在的目标、没有长期的规划能力,也无法主动地与环境交互来获取新知识。它更像一个功能强大的“文本补全引擎”,而不是一个拥有自主心智的智能体。
常识的缺失与脆弱性:人类的常识大多是非语言的,是通过与物理世界互动获得的。比如,我们知道杯子打碎了就无法复原。LLM很难从文本中学到这类隐性知识,导致它们在处理常识性问题时常常会犯一些匪夷所思的错误。
杨立昆用一个生动的比喻来形容LLM的局限性:“给AI读完人类所有的书,它也学不会自己打开一扇门。” 这句话精准地道出了从语言数据到物理理解之间存在的巨大鸿沟。
3.2 “世界模型”的技术构想
为了克服LLM的这些局限,杨立昆提出了以“世界模型”为核心的全新AI架构。这个构想的目标,是让AI像人类婴幼儿一样,通过观察和与世界的互动来学习。
其核心理念可以分解为以下几个部分:
学习世界的可预测性:世界模型的核心任务是学习一个关于世界如何运作的内部模拟器。这个模型接收当前世界状态的表征(例如,一段视频帧),并预测未来的世界状态。例如,模型看到一个球在空中,它应该能预测出球接下来会沿着抛物线落下。
多模态感知输入:与LLM主要依赖文本不同,世界模型的输入是丰富的多模态数据,尤其是视觉和空间数据。它通过“看”和“听”来感知世界,而不是通过“读”。这使得模型能够直接学习物理规律和空间关系。
自监督学习:训练世界模型的主要方式是自监督学习。AI通过观察大量的视频,不断地预测视频的下一帧会是什么样子,并与真实情况进行对比,从而修正自己的内部模型。这个过程不需要昂贵的人工标注。
分层与抽象:一个强大的世界模型应该是分层的。底层模型负责预测像素级别的细节,而高层模型则在抽象的表征空间中进行预测和规划。例如,高层模型可能只关心“球的位置和速度”,而不需要关心球的具体纹理。
基于模型的规划与推理:一旦拥有了一个可靠的世界模型,AI就可以在“脑海”中进行模拟和规划。在采取任何实际行动之前,它可以先在内部世界模型中预演多种可能性,评估不同行动序列的后果,然后选择最优的方案。这就是所谓的“系统2思维”,一种深思熟虑的、基于推理的决策过程。
下图是一个简化的世界模型架构示意图,展示了其与LLM的根本不同。
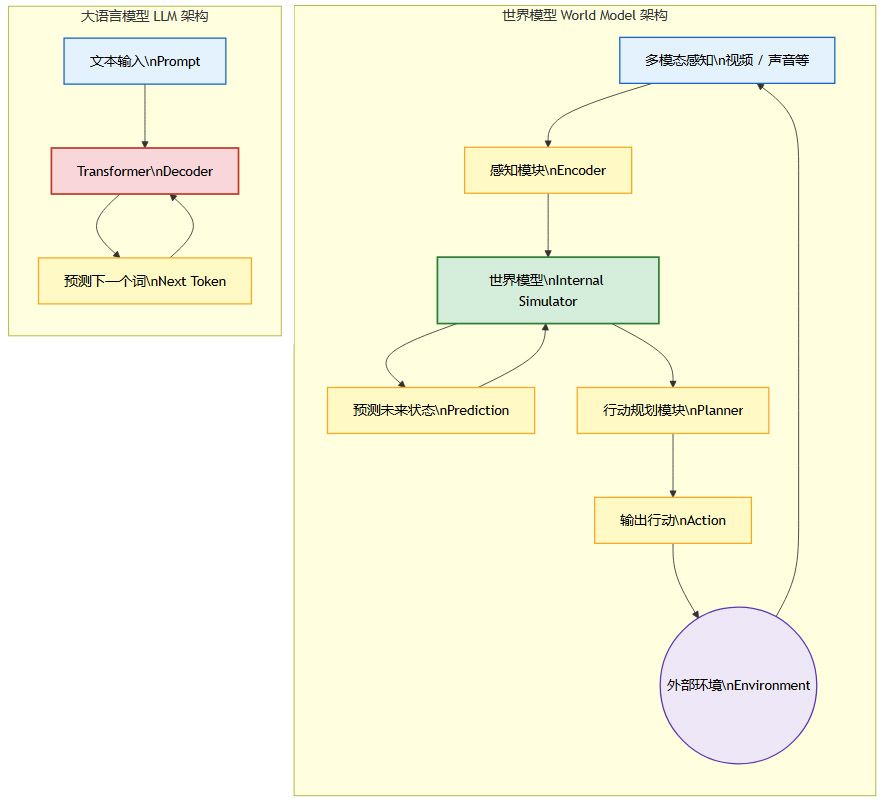
从图中可以看出,世界模型是一个闭环的感知-预测-规划系统,它主动地与世界交互。而LLM则是一个开环的文本生成系统。
3.3 杨立昆的产业行动
杨立昆不仅在学术上倡导世界模型,更在产业界采取了实际行动。他近期从Meta的首席AI科学家职位上部分抽身,投身于一家新的创业公司,其核心目标就是将世界模型的理论架构工程化,并构建出能够与物理世界交互的智能体。这一举动被视为“范式派”吹响的反攻号角,试图在由LLM主导的行业格局中,开辟出一条全新的、可能更具根本性突破的技术路径。
💠 四、两大主航道:战略分歧与潜在融合
%20拷贝-jajl.jpg)
哈萨比斯的“规模派”与杨立昆的“范式派”之间的争论,并非简单的技术细节之争,而是关乎AI未来5-10年发展方向的根本性战略分歧。
4.1 两大技术阵营的战略分野
我们可以将两大阵营的核心战略主张总结在下表中。
这场争论的实质,是关于资源分配的战略抉择。未来数万亿美元的投资,是应该继续砸向更大规模的GPU集群,还是应该分出一部分,去支持那些看起来更遥远、但可能更具颠覆性的认知范式研究?
4.2 融合之路:并非零和博弈
尽管双方的观点看似尖锐对立,但未来的AGI很可能不是某一个路线的单独胜利,而是两条路线的融合。
大规模基础模型作为“知识库”:通过规模定律训练出的超大规模模型,已经证明了其作为通用知识库的巨大价值。它们吸收了人类几乎所有的公开知识,具备了强大的语言理解和生成能力。这个“系统1”式的快速、直觉反应系统,可以作为未来更复杂智能体的基础。
世界模型作为“推理引擎”:在强大的基础模型之上,可以叠加一个显式的世界模型。当遇到需要深度理解、物理推理或长期规划的任务时,系统可以调用世界模型进行模拟和推演。这相当于为AI装上了一个负责深思熟虑的“系统2”。
工具调用与强化学习的粘合:通过工具调用(Tool Use)和强化学习(Reinforcement Learning),可以将大规模语言模型和世界模型有机地结合起来。语言模型负责理解任务、分解目标,并生成调用世界模型或其他外部工具的代码。世界模型则负责执行模拟,并将结果反馈给语言模型。智能体通过与环境(无论是真实的还是模拟的)的交互,不断学习和优化自身的策略。
一个可能的融合架构如下所示:
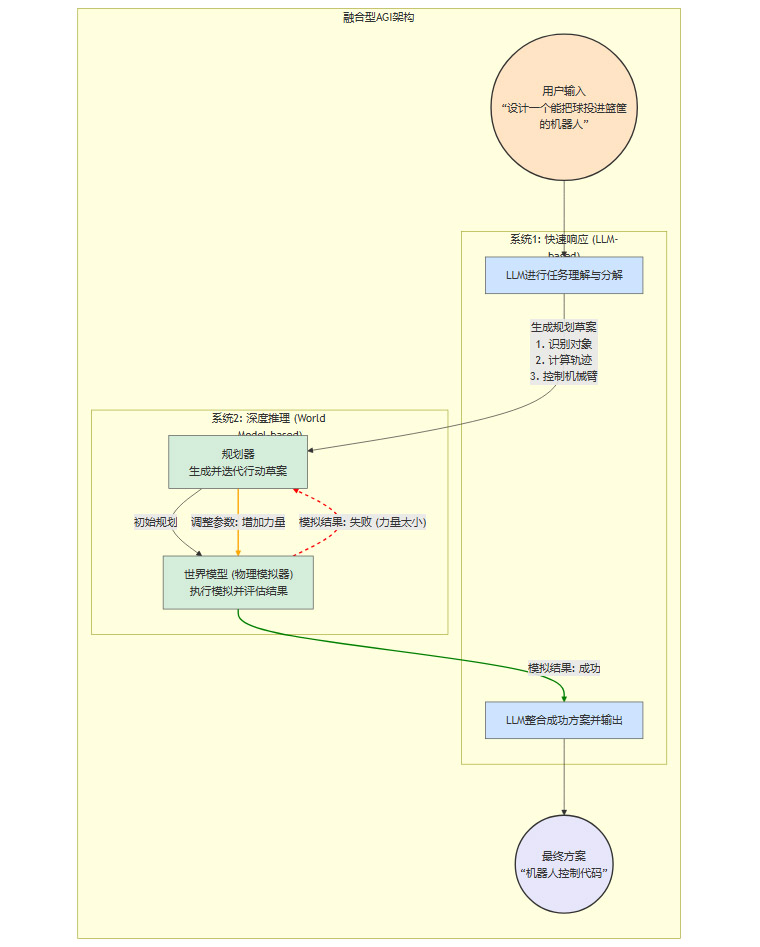
这种混合形态的系统,既能利用大规模模型的广博知识,又能借助世界模型的深度理解能力,从而实现更鲁棒、更通用的智能。这要求业界在继续优化算力利用效率的同时,必须加大对基础理论、认知架构和模型安全性的投入。
结论
人工智能的发展已经驶入一片深水区。曾经清晰的“规模定律”航道,虽然仍在发挥主导作用,但其前方的浓雾——数据瓶颈、成本失控与能耗危机——也已肉眼可见。边际收益递减的担忧,正在迫使整个行业重新审视这条路径的可持续性。
与此同时,以“世界模型”为代表的范式革新思潮,为我们揭示了通往AG-I的另一条可能航道。这条路更加崎岖,充满了理论和工程上的不确定性,但它直面了当前AI在深度理解、因果推理和自主规划上的核心短板,指向了一个可能更接近人类智能本质的未来。
规模定律与世界模型之争,并非简单的“对”与“错”,而是“快”与“远”的战略取舍。在算力军备竞赛与认知范式创新的十字路口,行业尚未形成共识。技术风险、经济成本与社会影响的多重压力,将倒逼从业者们做出更清晰的长期规划。未来,最有可能胜出的,或许不是任何单一航道的拥护者,而是那些能够巧妙地融合两条路线优势,在工程的确定性与科学的颠覆性之间找到最佳平衡的探索者。AGI的时代,或许就将在这种竞合与交融中,比我们预想的更早到来。
📢💻 【省心锐评】
AGI之路正从“大力出奇迹”的算力竞赛,转向“认知架构”的深层博弈。规模定律是地基,世界模型是蓝图,二者融合而非对立,才是通往真正智能的钥匙。

评论