.png)


【摘要】2025年7月,卡内基梅隆大学团队提出H-Net分层网络架构,实现了无需分词器、端到端处理原始字节数据的语言模型。H-Net通过动态分块机制,显著提升了性能、鲁棒性和可解释性,超越了传统分词器模型,为多语言和复杂序列建模带来全新突破。
引言
分词器(Tokenizer)长期以来是现代语言模型不可或缺的基础组件。它将自然语言文本切割为“词块”或“子词”,为深度学习模型的训练和推理提供了标准化输入。然而,分词器的固有缺陷——如语言偏见、灵活性不足、对复杂语言和特殊场景的适应性差——已成为制约AI语言理解进一步突破的瓶颈。
在此背景下,卡内基梅隆大学(Carnegie Mellon University, CMU)联合Cartesia AI团队,提出了H-Net(Hierarchical Network)这一全新架构。H-Net由Sukjun Hwang、Brandon Wang和Albert Gu教授领导开发,论文发表于2025年7月,已在arXiv公开2。该模型通过端到端的动态分块机制,彻底摆脱了传统分词器的依赖,能够直接在字节级别处理原始数据,实现了内容感知、上下文相关的自适应分割。这一创新不仅提升了模型的建模能力和泛化能力,还极大增强了对多语言、代码、DNA等复杂序列的适应性和鲁棒性。
H-Net的核心在于其动态分块(Dynamic Chunking, DC)机制。该机制由路由模块和平滑模块协同工作,能够在模型内部自动学习如何根据内容和上下文划分语义单元,取代了人工设计的启发式分词规则。通过分层架构,H-Net实现了从细粒度到粗粒度的多尺度语义建模,极大提升了模型的表达能力和效率
实验结果显示,H-Net在参数规模超过10亿时,其困惑度和下游任务性能已可媲美甚至超越基于BPE分词器的Transformer模型,尤其在中文、代码、DNA等传统分词器表现不佳的场景中,优势更加明显24。这一突破性进展,标志着AI语言模型正式迈入无分词器、端到端建模的新时代,也再次彰显了卡内基梅隆大学在人工智能基础研究领域的全球引领地位。
一、H-Net的提出与语言模型范式的转变
%20拷贝.jpg)
1.1 语言模型的历史与分词器的角色
自然语言处理(NLP)领域的主流模型,如GPT、BERT等,均依赖分词器(Tokenizer)将文本切分为“词块”或“子词”。分词器的设计初衷,是将连续的字符流转化为有限的、可控的离散单元,便于模型学习和推理。常见的分词方法包括:
基于空格的分词(适用于英语等空格分隔语言)
基于规则的分词(如正则表达式、词典匹配)
子词分割(如BPE、WordPiece、Unigram等)
分词器的引入极大地提升了模型的训练效率和泛化能力,但也带来了诸多隐患。
1.2 分词器的局限性与挑战
分词器的局限性主要体现在以下几个方面:
语言偏见:分词器往往针对高资源语言(如英语)优化,对于中文、阿拉伯语等无空格语言,分词效果不佳,导致模型在多语言场景下表现不均衡。
灵活性不足:固定词表和切割规则难以适应新词、拼写错误、特殊字符等多变输入,模型对输入扰动极为敏感。
鲁棒性低:分词器对输入的微小变化(如拼写错误、大小写变化)反应剧烈,导致模型输出不稳定,影响实际应用的可靠性。
对抗性脆弱:在对抗性攻击下,分词器易被绕过,模型安全性受威胁。
工程复杂性:多语言、多模态场景下,分词器的维护和扩展成本高,影响模型的可扩展性和通用性。
1.3 H-Net的提出:范式的根本性转变
H-Net的出现,正是对上述问题的有力回应。它摒弃了分词器这一“前置加工”环节,直接以原始字节为输入,通过端到端的动态分块机制,实现了对文本、代码、DNA等多种序列数据的高效建模。这一范式转变,不仅提升了模型的适应性和鲁棒性,也为多语言、多模态AI系统的构建提供了坚实基础。
二、H-Net的核心技术创新
2.1 动态分块机制:智能化的语义单元划分
H-Net的最大技术突破在于其动态分块(Dynamic Chunking, DC)机制。与传统分词器依赖人工规则和固定词表不同,H-Net通过模型内部的自适应学习,自动根据内容和上下文划分语义单元。其核心包括:
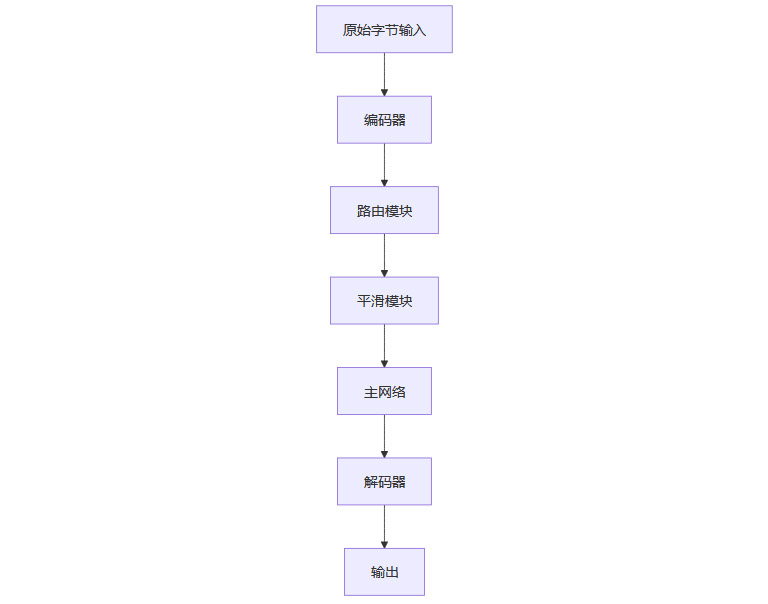
2.1.1 路由模块(Router)
路由模块通过计算相邻字符或字节的相似度,预测语义边界。具体而言,模型在每个位置上评估当前单元与前后单元的语义相似性,当相似度下降到一定阈值时,判定为新的语义块的起点。这一过程类似于人类在阅读时自然感知句子、短语或段落的分界点。
2.1.2 平滑模块(Smoothing)
由于分块边界的预测本质上是离散决策,直接优化会导致梯度传播困难。平滑模块通过将离散的边界预测转化为连续、可微分的操作,使得模型能够通过标准的梯度下降方法进行端到端训练。这一机制有效缓解了分层模型训练中的不稳定性问题。
2.1.3 分层架构
H-Net采用编码器-主网络-解码器的分层结构。原始字节数据首先通过编码器进行初步特征提取,随后通过动态分块机制压缩为更高层次的语义表示,主网络对压缩后的表示进行深度建模,最后解码器还原输出。分层结构使模型能够从细粒度到粗粒度逐层理解和建模序列数据,实现多尺度的语义抽象。
2.1.4 动态分块机制流程图
2.2 信号传播与优化策略
为保证分层结构中各子网络的信号平衡,H-Net引入了投影层与归一化层,优化信号传播路径,防止梯度消失或爆炸。同时,模型采用动态学习率调节机制,根据不同层级的特性调整优化策略,提升训练的稳定性和收敛速度。
2.3 辅助损失与压缩比率控制
H-Net在训练过程中引入辅助损失函数,对分块的压缩比率进行约束,防止模型在训练过程中出现分块过细或过粗的极端情况。这一机制确保了模型能够自适应地学习最优的分块粒度,兼顾信息保留与计算效率。
三、H-Net的实验表现与性能优势
%20拷贝.jpg)
3.1 多语言建模能力
H-Net在多项语言建模任务中展现出卓越的性能。以英语为例,单阶段H-Net在760M参数规模下,已能超越同等参数量的BPE分词Transformer模型。进一步扩展至1.3B参数后,H-Net的性能优势更加明显,困惑度(Perplexity)和下游任务表现均优于传统模型。
3.2 中文理解与无空格语言的突破
在中文等无空格语言的建模任务中,H-Net的动态分块机制展现出独特优势。在XWinograd中文测试中,H-Net准确率达到66.3%,比传统分词器模型高出10个百分点。其自动学习的分块策略能够有效捕捉中文语义边界,克服了分词器在中文处理上的天然劣势。
3.3 代码与DNA序列建模
H-Net不仅在自然语言建模中表现优异,在代码理解和DNA序列建模等特殊场景下同样展现出强大能力。实验显示,H-Net在代码建模和DNA序列建模任务中,数据效率提升高达3.6倍。这一结果表明,H-Net能够适应缺乏自然分词线索的序列数据,具备广泛的跨领域适用性。
3.4 鲁棒性与可解释性
H-Net对拼写错误、大小写变化等输入扰动表现出更强的稳定性。传统分词器模型在面对输入扰动时,分词结果易发生剧烈变化,导致模型输出不稳定。而H-Net由于直接处理字节级数据,能够更好地适应输入变化,提升模型的鲁棒性。
在可解释性方面,H-Net学习到的分块策略与人类语言直觉高度一致。通过可视化分析发现,模型能够自动在单词、短语、语义相关词组等边界处划分数据块,验证了其对语言内在结构的深刻理解。
3.5 性能对比表
四、H-Net的工程实现与技术挑战
4.1 端到端训练的关键技术
H-Net为实现端到端训练,采用了多项关键技术:
信号传播优化:通过投影层与归一化层平衡各子网络信号,防止梯度消失或爆炸。
动态学习率调节:根据不同层级的特性,动态调整优化参数,提升训练稳定性。
辅助损失函数:对分块压缩比率进行约束,防止分块粒度极端化,确保模型自适应学习最优分块策略。
4.2 计算效率与推理速度
尽管H-Net在性能上表现优异,但其计算效率和推理速度目前仍比传统模型慢约2倍。这主要源于动态分块和分层结构带来的额外计算开销。未来,提升模型效率、优化推理速度将是H-Net进一步发展的重要方向。
4.3 内存管理与工程可扩展性
H-Net的动态特性意味着其内存需求会随输入而变化,可能导致部分批次的序列过长而引发显存溢出。为此,工程实现中需引入动态内存管理和批次调度机制,确保模型在大规模部署时的稳定性和可扩展性。
4.4 兼容性与迁移学习
H-Net支持将预训练的分词器模型蒸馏到字节级H-Net中,实现模型迁移。尽管蒸馏后模型性能略有下降,但仍优于从头训练的小规模模型。这一特性为现有模型的平滑过渡和升级提供了可行路径。
五、H-Net的应用前景与未来发展
%20拷贝.jpg)
5.1 多模态与跨领域扩展
H-Net的动态分块理念不仅适用于语言建模,还可推广至音频、视频等其他序列建模任务。在这些领域,同样存在如何有效分割和处理连续数据的挑战。H-Net的分层处理和动态分块机制,为多模态AI系统的构建提供了通用解决方案。
5.2 开源生态与社区推动
H-Net的代码和预训练模型已在GitHub和Hugging Face开源,极大地促进了研究社区的交流与合作。开源生态的繁荣,有助于加速技术创新,推动H-Net在更多实际场景中的落地应用。
5.3 未来发展方向
H-Net的未来发展方向包括:
提升模型效率:优化动态分块和分层结构,提升训练和推理速度。
扩展模型规模:探索更大参数规模下的性能极限,满足更复杂任务需求。
深化分层结构:研究更深层次的分层架构,实现更细致的语义建模。
多模态融合:推进文本、图像、音频等多模态数据的联合建模,提升AI系统的通用性和智能水平。
六、H-Net的行业影响与范式意义
6.1 语言模型架构的范式转变
H-Net的出现,标志着语言模型架构从“分词器+深度模型”的传统范式,向“端到端、动态分块”的新范式转变。这一转变,不仅提升了模型的适应性和鲁棒性,也为多语言、多模态AI系统的构建提供了坚实基础。
6.2 对AI基础设施的重构
H-Net的分层处理和动态分块机制,为AI基础设施的重构提供了新思路。未来,随着技术的不断优化和完善,H-Net有望成为下一代通用基础模型的核心架构,推动人工智能进入更加智能、自适应的新阶段。
七、总结
H-Net以其无需分词器、端到端处理原始字节数据的创新架构,突破了传统语言模型的局限,展现出卓越的多语言、多模态适应能力和强大的鲁棒性。其动态分块机制、分层结构和端到端训练技术,为AI语言理解和序列建模开辟了全新路径。尽管目前在计算效率和工程实现上仍有提升空间,但H-Net已展现出成为下一代通用基础模型的巨大潜力。随着技术的不断优化和应用场景的拓展,H-Net有望引领AI语言模型迈向更高智能与自适应的新纪元。
📢💻 【省心锐评】
H-Net的提出标志着语言模型领域的一次重要突破,其动态分块机制和端到端处理能力为多语言理解和多模态建模带来了新的可能性。

评论