.png)


【摘要】当前AI算力需求由真实工作负载驱动,与互联网泡沫时期基于投机预期的“暗光纤”现象存在本质区别。产业基础坚实,但资本市场波动需理性看待。
引言
人工智能浪潮正以前所未有的速度席卷全球。从大型语言模型到生成式视觉应用,技术突破的背后是资本市场的狂热追捧。英伟达市值屡创新高,相关产业链公司估值水涨船高。这种景象,让许多经历过世纪之交那场盛大烟火的从业者,不禁回想起“互联网泡沫”的岁月。历史是否会简单重演?我们是否正处在一场由代码和数据构筑的巨大泡沫之中?
针对这一普遍疑虑,英伟达CEO黄仁勋给出了一个清晰且强硬的回应。他认为,将当前的AI发展与互联网泡沫相提并论,是一个根本性的误判。其核心论据直指两者在基础设施层面最本质的差异。本文将深入剖析这一论断,解构AI时代的算力需求,并审视其与互联网泡沫时期的“暗光纤”现象究竟有何不同。我们将从技术、产业与资本三个维度,对这场关乎未来的辩论进行一次冷静的复盘。
一、 核心分野 “暗光纤”与“全亮GPU”的时代镜像
%20拷贝-pexk.jpg)
要理解黄仁勋的观点,必须先回到历史现场,看清“暗光纤”究竟是什么。它不仅是一个技术名词,更是一个时代的隐喻。
1.1 历史回溯 互联网泡沫的“暗光纤”隐喻
上世纪90年代末,互联网概念如日中天。市场普遍相信,网络流量将以不可思议的速度爆炸式增长。基于这种极度乐观的预期,全球电信运营商和基础设施公司展开了一场疯狂的“军备竞赛”。它们投入数千亿美元,在全球范围内铺设了海量光纤网络。
“暗光纤”(Dark Fiber),指的就是那些已经铺设但尚未被点亮(即没有激光信号通过)的备用光纤。建设者的逻辑很简单,一次性铺设远超当前需求的光缆,可以大幅降低未来的扩容成本。他们赌的是一个需求无限增长的未来。
然而,现实是残酷的。互联网应用的发展速度,远未跟上基础设施的扩张步伐。电子商务、在线视频等真正消耗带宽的应用,在当时仍处于萌芽阶段。结果,天量的光纤被铺设在地下、海底,却无人问津,长期闲置。这场豪赌最终以投资回报几乎为零告终。“暗光纤”也因此成为那个时代供给严重脱离需求、基于虚幻预期进行过度投资的标志性符号。
它的核心问题在于,基础设施的建设逻辑,是建立在对未来的投机之上,而非服务于当下已存在的真实工作负载。
1.2 现实观照 AI时代的“全亮GPU”
将视线拉回现在,黄仁勋用一个同样形象的对比来描述AI时代,那就是“全亮的GPU”。
与“暗光纤”的闲置状态截然相反,当前全球数据中心里的高端GPU,几乎都处于高强度、高利用率的运行状态。无论是云服务巨头亚马逊AWS、微软Azure,还是众多AI初创公司,都在疯狂抢购和部署以英伟达GPU为代表的算力资源。工程师们夜以继日地工作,不是为了满足未来的某个模糊预期,而是为了解决眼前迫在眉睫的计算任务。
这种现象背后,是AI工作负载的独特性质。
模型训练(Training)。训练一个类似GPT-4的 foundational model,需要数万块顶级GPU持续运行数月之久,这是一个极其消耗算力的“一次性”巨大工程。
模型推理(Inference)。模型训练完成后,每一次用户查询、每一次API调用,都需要算力进行实时计算。随着AI应用用户量的指数级增长,推理带来的算力消耗是持续且不断扩大的。
因此,今天的数据中心建设,其逻辑是由确定性的、正在发生的计算需求反向驱动的。企业购买GPU,是因为有明确的模型要训练,有海量的用户请求要处理。每一分钱的资本开支,几乎都能直接映射到具体的工作负载上。这与当年为“可能”的流量而铺设光纤,形成了鲜明对照。
1.3 本质差异的结构化对比
为了更清晰地展示两者的区别,我们可以通过一个表格进行结构化对比。
这个表格清晰地揭示了,尽管两个时代都表现出资本市场的狂热,但其产业根基截然不同。互联网泡沫的根基是沙土,而AI时代的根基,至少从算力需求来看,是岩石。
二、 算力需求的解构 真实工作负载的铁证
黄仁勋的论断并非空谈。AI算力需求的真实性,可以从其构成、来源和演进趋势中得到验证。它不是一个单一、模糊的概念,而是一个由多个层次、多种形态构成的复杂体系。
2.1 工作负载的双轮驱动 训练与推理
AI的算力消耗主要来自两个环节,训练和推理。它们共同构成了驱动算力需求增长的两个强大引擎。
2.1.1 训练(Training) 奠定能力的基石
模型训练是AI能力的源头。它通过向神经网络投喂海量数据,让模型学习和掌握规律。这个过程的算力消耗是惊人的。
计算密集度。训练一个参数量达千亿级别的大模型,涉及的浮点运算次数可达天文数字。例如,训练GPT-3级别的模型,据估算需要约3.14E23次FLOPs(浮点运算次数)。
时间跨度长。这类训练任务通常需要数周甚至数月才能完成,期间数千乃至上万块GPU必须协同工作,持续满负荷运转。
军备竞赛。各大科技公司为了在模型能力上取得领先,不断推高模型参数量和训练数据量,直接导致训练所需的算力呈指数级增长。
训练需求是AI产业的“固定资产投资”。它虽然不是持续性的,但每一次技术代际的跃迁,都会引发一波巨大的、确定性的算力采购潮。
2.1.2 推理(Inference) 释放价值的出口
如果说训练是十年磨一剑,那么推理就是每一次挥剑的瞬间。当模型被部署到实际应用中,响应用户请求的过程就是推理。
高并发性。像ChatGPT、Midjourney这样的应用,每天需要处理数以亿计的用户请求。每一个请求都需要一次独立的推理计算。
低延迟要求。用户无法忍受长时间的等待。推理必须在毫秒级内完成,这对算力平台的实时响应能力提出了极高要求。
成本敏感性。推理是持续性的运营成本。如何用更低的算力成本完成一次推理,是所有AI应用公司关注的核心问题。这也反向刺激了对更高能效比的推理芯片的需求。
推理需求是AI产业的“运营消耗”。随着AI应用渗透率的提升,推理产生的总算力需求将远超训练,成为算力市场长期增长的核心驱动力。黄仁勋提到的“产生的查询数量也在增加”,指的就是推理工作负载的持续攀升。
2.2 需求来源的广度 企业与研究的深层拉动
公众对AI的认知,往往停留在聊天机器人和AI绘画等消费级应用。但这只是冰山一角。在产业深处,更庞大、更具价值的算力需求正在被释放。
科学研究。AI正在成为继理论、实验之后的“第三种科学范式”。在生命科学领域,AI用于蛋白质结构预测(如AlphaFold);在材料科学领域,AI用于发现新材料;在天文学领域,AI用于分析星系数据。这些前沿研究对算力的需求几乎是无上限的。
工业制造。在智能工厂中,AI用于产品质检、设备预测性维护、供应链优化。这些任务需要处理大量的传感器数据和视觉信息,对算力的实时性和可靠性要求极高。
自动驾驶。训练一辆L4级别的自动驾驶汽车,需要在虚拟环境中进行海量里程的仿真测试,其背后是数据中心庞大的算力支撑。
金融服务。高频交易、风险控制、反欺诈等场景,都需要AI模型进行实时分析和决策。
黄仁勋所说的AI已发展到“能够通过研究进行有效思考和自我验证”的程度,正是指这些高价值的企业级和研究级应用。这些应用直接与企业的生产效率和核心竞争力挂钩,企业愿意为其带来的价值而支付高昂的算力成本。这进一步印证了需求的真实性和可持续性。
三、 算力架构的演进 从集中式到云边端协同
%20拷贝-ggnb.jpg)
AI算力需求的真实性,不仅体现在总量上,也体现在其架构的演进上。单一的、集中式的云计算已无法满足所有AI场景的需求,一个更加立体和复杂的“云—边—端”协同算力架构正在形成。这种结构性的演进,进一步巩固了长期算力需求的根基。
3.1 云端(Cloud) 算力的“中央厨房”
云端数据中心是当前AI算力的绝对主力,尤其是对于大规模模型训练。
超大规模集群。只有在云端,才可能汇集成千上万块GPU,形成强大的算力集群,以完成 foundational model 的训练。
弹性和可扩展性。云服务提供了按需使用、弹性伸缩的算力资源,降低了AI应用的准入门槛。
生态系统。云厂商不仅提供硬件,还提供了一整套围绕AI开发的软件栈、工具链和平台服务,构成了强大的生态壁垒。
云端算力是AI时代的“中央厨房”,负责处理最复杂、最庞大的计算任务。
3.2 边缘(Edge) 算力的“前置仓”
随着物联网、自动驾驶等应用的兴起,对数据处理的实时性要求越来越高。将所有数据都传回云端处理,不仅延迟高,带宽高,还可能涉及数据隐私问题。因此,边缘计算应运而生。
低延迟响应。在靠近数据源的边缘侧(如工厂车间、基站、路边单元)部署算力,可以实现毫秒级的实时推理,满足工业控制、车路协同等场景的需求。
数据隐私保护。本地化的数据处理,避免了敏感数据上传云端,满足了金融、医疗等行业的合规要求。
带宽成本优化。在边缘侧对原始数据进行预处理和筛选,只将有价值的结果上传云端,可以大幅节省网络带宽成本。
边缘算力是AI时代的“前置仓”,它将云端的能力延伸到业务现场,解决了“最后一公里”的计算问题。
3.3 终端(End-Device) 算力的“入户节点”
终端侧AI,即在智能手机、PC、智能汽车等个人设备上直接运行AI模型。
极致的个性化体验。终端AI可以利用用户的本地数据,提供高度个性化的服务,同时保护用户隐私。
离线运行能力。在没有网络连接的情况下,终端AI应用依然可以正常工作。
功耗与成本。对于一些轻量级AI任务,在终端上运行比调用云服务成本更低、功耗更小。
终端算力是AI时代的“入户节点”,它让AI能力变得无处不在,深度融入个人生活。
3.4 协同架构的价值与需求
“云—边—端”协同架构并非简单的算力叠加,而是一种有机协同。例如,模型的训练和优化在云端完成,然后部署到边缘和终端进行推理。边缘和终端设备在运行中产生的数据,又可以回传到云端,用于模型的持续迭代。
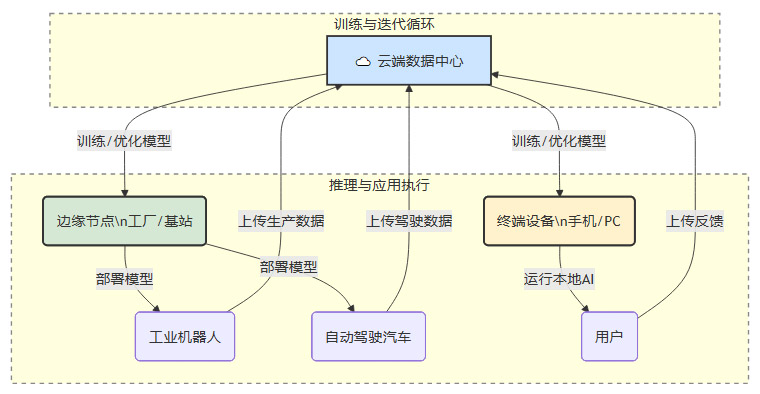
这种复杂的、多层次的算力架构,本身就说明了AI应用已经深入到产业的毛细血管。它所产生的算力需求是结构性的、系统性的,而非单一产品或概念所能支撑的。这与互联网泡沫时期单一依赖网络接入用户数增长的模式,有着天壤之别。
四、 资本市场的回响 泡沫担忧的理性审视
%20拷贝-josr.jpg)
尽管产业基本面坚实,但我们无法忽视资本市场的巨大波动和其中蕴含的风险。承认AI领域存在金融层面的“泡沫”成分,与肯定其技术和需求的真实性,并不矛盾。
4.1 金融层面的相似性
当前AI热潮与互联网泡沫在资本市场的表现,确实存在一些惊人的相似之处。
估值飙升。少数头部公司(如英伟达)的市值在短时间内急剧膨胀,市盈率远超传统行业。
散户狂热。大量散户投资者涌入AI相关股票,追逐“疯狂收益”,市场情绪化交易明显。
资本过度集中。大量风险投资涌向AI领域,尤其是大模型赛道,导致初创公司估值虚高。
这些金融现象,是引发欧洲央行、高盛等机构以及迈克尔·贝瑞等知名投资者发出泡沫警告的主要原因。他们担忧的,是资本开支的增长速度,是否超越了应用效率和实际商业回报的增长速度。
4.2 产业基础的根本不同
然而,金融市场的喧嚣,不应与产业基础的真实性混为一谈。如前文所述,AI产业的资本开支,主要投向了能够立即产生工作负载的算力基础设施。
投资与负载的强关联。数据中心和智算中心的建设,直接服务于可见的模型训练和推理任务,而非为“未来可能”而超前铺设。
价值创造的可度量性。AI应用在企业端的价值,可以通过效率提升、成本降低、收入增加等指标进行量化评估。这为资本投入提供了一个理性的“锚”。
互联网泡沫的破裂,是因为支撑高估值的“眼球经济”商业模式被证伪,无法转化为真实的利润。而当前AI产业,尤其是在B端,已经展现出清晰的商业模式和付费意愿。企业愿意为能够解决实际问题的AI能力买单。
4.3 潜在风险与观察点
理性的观察者,既要看到AI需求的真实性,也要警惕潜在的风险。
资源错配风险。在某些细分领域或特定阶段,可能出现资本过度涌入,导致同质化竞争和资源浪费。
回报周期风险。尽管AI的长期价值巨大,但部分应用的短期投资回报率可能不及市场预期,这可能引发资本市场的阶段性回调。
应用落地风险。AI技术要转化为普遍的生产力,还需要克服数据、安全、人才等多方面的挑战。如果应用落地速度不及预期,也可能影响市场信心。
因此,关键在于用真实的工作负载和单位算力的效率,来约束和评估资本开支的合理性。只要算力的利用率保持高位,应用场景持续拓宽,那么即便资本市场出现波动,产业向上的长期趋势也不会改变。
结论
回到最初的问题,AI是泡沫吗?答案是复杂的。
如果“泡沫”指的是资本市场的短期非理性繁荣和过高估值,那么AI领域无疑存在泡沫成分。金融市场的周期性波动,几乎是所有革命性技术在发展初期都无法避免的伴生现象。
但如果“泡沫”指的是产业基础的虚假和需求的虚幻,那么将AI与互联网泡沫时期的“暗光纤”相提并论,则是一个错误的类比。黄仁勋的论断抓住了问题的核心。AI时代的需求,植根于可度量的、正在发生的、遍布各行各业的真实工作负载。从模型训练到推理应用,从云端到边缘终端,一个立体而坚实的算力需求结构已经形成。
互联网泡沫是为了一群尚未到来的客人,修了太多空旷的路。而今天的AI,是为了一群已经排起长队的客人,在加急建造可以立即入住的房子。路可能会长期空置,但为真实需求而建的房子,很难长期闲置。理解这一本质区别,是穿越市场迷雾,把握AI未来发展的关键所在。
📢💻 【省心锐评】
AI的喧嚣在资本,根基在算力。互联网泡沫是为不存在的客人修路,AI是为排队的客人建房。路会空,房难闲。需求的真实性,是区分投机与革命的最终标尺。

评论