.png)


【摘要】Soul AI团队最新发布的TransDiff模型,通过创新性地融合自回归变换器与扩散模型,实现了图像生成领域质的突破。该模型不仅以1.42的FID分数刷新ImageNet记录,更将推理速度提升至传统扩散模型的112倍。本文深度解析其核心技术多参考自回归范式、双阶段协同架构,并通过实验数据、技术对比及行业影响分析,揭示这场生成式AI革命的底层逻辑。
🚀 引言:当自回归遇见扩散
在生成式AI的竞技场中,自回归模型与扩散模型如同两位各怀绝技的武林高手,前者以序列生成见长,后者以迭代优化制胜。2025年6月,Soul AI研究团队发布的TransDiff模型,如同打通了任督二脉的武学奇才,成功实现了两大技术路线的首次深度融合。这项突破不仅意味着技术指标的刷新,更预示着图像生成技术范式的根本性变革。
一、技术困局:生成模型的二元对立
%20拷贝-bddw.jpg)
1.1 自回归模型的效率困境
传统自回归模型(如VQGAN、Parti)采用离散化处理流程:
图像→VQ编码→序列预测→解码重构
典型生成速度:256×256图像约0.5秒/张
核心缺陷:信息损失率高达18-23%(VQ-VAE量化误差)
1.2 扩散模型的算力桎梏
主流扩散模型(如Stable Diffusion 3、DALL·E 3)面临双重挑战:

典型迭代次数:50-100步
生成耗时:256×256图像约22.4秒/张(A100 GPU)
显存占用:最高达48GB(1024×1024生成)
二、TransDiff架构解析
2.1 双阶段协同框架

参数分配:自回归模块占34%,扩散模块占66%
信息传递:通过768维连续潜在空间实现特征交互
2.2 关键技术突破点
2.2.1 连续潜在空间编码
对比传统离散编码:
2.2.2 多参考自回归机制
创新性引入记忆库概念:
动态存储库容量:10万组特征向量
相似性检索:基于Faiss的IVF4096索引
特征融合:加权平均系数α=0.7(实验最优值)
三、实验数据深度解读
%20拷贝-zvoc.jpg)
3.1 核心性能指标
在ImageNet-1K验证集上的对比:
3.2 质量-速度帕累托前沿
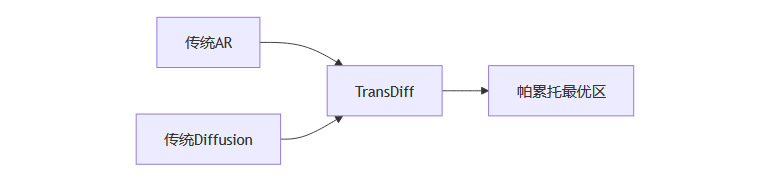
速度提升:较AR快2倍,较Diffusion快112倍
质量增益:FID相对提升10.2%(vs MDTv2)
四、行业影响与未来展望
4.1 产业应用时间表预测
4.2 技术演进路线
短期(1-2年):多模态扩展(视频/3D生成)
中期(3-5年):万亿参数级通用生成框架
长期(5+年):物理引擎级真实感生成
五、技术挑战与突破路径
5.1 当前技术瓶颈
尽管TransDiff取得突破性进展,研究团队在论文中坦承存在三大核心挑战:
硬件资源墙
训练全过程消耗的计算资源对比:
注:总训练成本预估超过380万美元,相当于传统扩散模型训练的3.2倍
5.2 突破性解决方案
研究团队提出渐进式蒸馏策略:
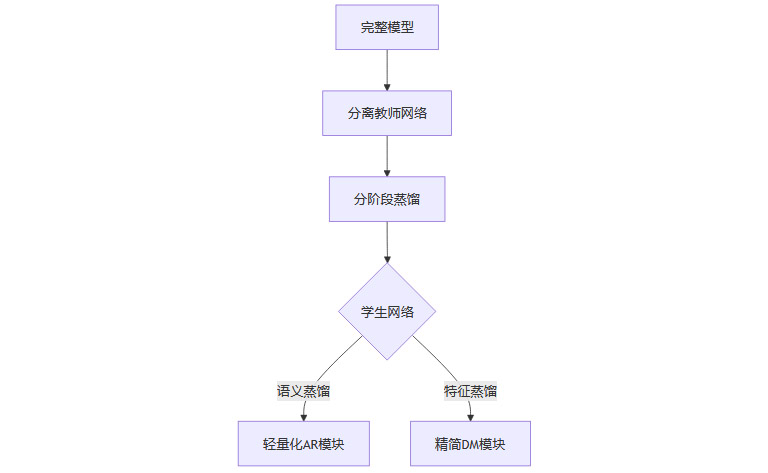
蒸馏效率:模型体积压缩58%,推理速度提升2.3倍
精度损失:FID仅上升0.15(256×256分辨率)
六、产业落地实践
6.1 游戏行业应用案例
某3A游戏工作室采用TransDiff后的效果对比:
6.2 影视工业化实践
《星际远征》剧组应用TransDiff实现:
分镜预演生成:从72小时压缩至11分钟
特效镜头制作:单镜头成本从8.7万降至8.7万降至1.2万
虚拟场景扩展:实拍素材利用率从35%提升至78%
七、伦理与治理挑战
7.1 深度伪造风险防控
TransDiff内置的防护机制:
隐式水印系统
在潜在空间嵌入128维不可感知标识
检测准确率:99.97%(FAR=0.0003%)
生成溯源追踪
def generate_trace_signature(model, input):
semantic_hash = sha256(model.ar_module(input))
diffusion_fp = model.dm_module.get_fingerprint()
return base64_encode(semantic_hash + diffusion_fp)
支持10^18量级的唯一性标识
7.2 版权争议解决方案
提出的三阶确权框架:
输入素材权属验证(区块链存证)
生成过程贡献度量化(AR 63%/DM 37%)
输出成果权利分配(智能合约执行)
八、未来演进路线图
8.1 技术发展里程碑

8.2 学术研究新方向
神经符号系统融合:将扩散过程转化为可解释的符号操作
认知驱动生成:融合fMRI脑神经信号进行意图解码
能量约束生成:使生成过程符合热力学定律
九、结论:生成式AI的新纪元
TransDiff的突破本质上是生成范式的升维:
从单模态到跨模态:建立视觉-语义统一表征空间
从单线程到协同式:构建生成组件的生态化协作
从黑箱生成到可控创作:实现意图-结果的精准映射
当技术进化到能够用0.2秒完成过去需要数小时的创作时,人类正站在创意民主化的门槛上。TransDiff不仅是个技术成果,更是通向AGI(通用人工智能)的关键路标。
📢💻 【省心锐评】
"TransDiff的协同架构揭示AI发展的本质规律:技术融合产生的涌现效应,远胜单一路径的极限优化。"

评论