.png)


【摘要】可信数据空间,被誉为“数据保险箱”,正成为破解数据孤岛与隐私安全困境的关键。它以“数据可用不可见”为核心理念,通过深度融合隐私计算、区块链、数据沙箱及分布式身份等四大技术支柱,构建了一个覆盖身份、数据、过程全链条的可信体系。这套机制在确保数据主权与隐私安全的前提下,实现了数据价值的安全、高效流通,为数字经济的基础设施建设提供了坚实的技术蓝图与实践路径。
引言
数字经济浪潮下,数据早已不是简单的信息记录,而是驱动创新与增长的核心生产要素。但一个巨大的悖论摆在面前,一方面,数据的价值在于流动与融合;另一方面,无序的流动极易引发隐私泄露、数据滥用与主权争议。这种矛盾使得大量高价值数据被束之高阁,形成了难以逾越的“数据孤岛”。企业和机构手握金矿,却不敢、不愿、也不能轻易分享。
如何才能打开这个结?我们需要一把既能释放数据价值,又能牢牢锁住安全与隐私的钥匙。
可信数据空间(Trusted Data Space,简称TDS),正是为这个时代难题给出的答案。它不像传统的数据汇集平台,要求各方交出原始数据。相反,它构建了一个全新的协作范式,一个如同“数据保险箱”的虚拟环境。在这个环境中,数据的“所有权”与“使用权”被清晰分离。数据提供方依然牢牢掌握着自己的数据主权,而数据使用方则可以在一个受控、可信的环境里,对数据进行计算和分析,获取价值,却自始至终接触不到原始数据。
这个范式的核心,就是那句精炼的总结,“数据可用不可见”。为了让这个理念从构想变为现实,背后需要一个严密而强大的技术体系支撑。这个体系并非单一技术的堆砌,而是一个由隐私计算、区块链与智能合约、数据沙箱与使用控制、分布式身份与接入标准化这四大核心技术协同构建的精密系统。
本文将逐层深入,为您解构这座“数据保险箱”的内部构造,看懂这四大技术是如何各司其职又紧密配合,共同支撑起数据要素安全流通的未来。
一、 核心理念升维:从“可用不可见”到“三重可信”闭环
%20拷贝.jpg)
在深入技术细节之前,我们必须先彻底理解可信数据空间的设计哲学。它的基石并不仅仅是“可用不可见”,而是围绕这个基石构建的一整套信任闭环。
1.1 “数据可用不可见”的内涵与价值
“数据可用不可见”听起来有些抽象,实际上它直击数据流通的核心痛点。
可用(Available for Use),指的是数据的计算价值可以被充分利用。数据使用方可以发起分析任务、运行机器学习模型、进行多源数据联合统计等操作,并获得有价值的计算结果。数据不再是静止的资产,而是可以参与到业务流程中创造价值的要素。
不可见(Not Visible),指的是原始数据本身对数据使用方是“黑盒”状态。使用方无法下载、拷贝、查看或以任何形式直接接触到明文的原始数据。所有计算过程都在一个受保护的环境中完成,最终只输出约定的结果,如一个模型、一个统计值或一个决策判断。
这种模式的价值是革命性的。它从根本上将数据的所有权与使用权进行了技术层面的解耦。数据持有方不再因担心数据失控而拒绝合作,数据需求方也能够合规地利用多方数据提升自身业务能力。这不仅保护了商业秘密和个人隐私,更重要的是,它为构建一个健康、可持续的数据要素市场铺平了道路。
1.2 解构“三重可信”:构建全链条信任
仅仅实现“可用不可见”还不够,因为在复杂的商业协作中,信任是一个多维度的问题。可信数据空间通过构建“三重可信”体系,为数据流转的每一个环节提供了确定性的保障,回答了三个关键问题,谁在用?用什么?怎么用?
1.2.1 身份可信(Trusted Identity)
这是信任的起点。在任何数据交互发生之前,系统必须能准确、可靠地验证每一个参与方的身份,无论是机构还是个人,甚至是运行任务的软件程序。传统的基于用户名密码或中心化认证的体系,在跨机构、去中心的协作场景中显得力不从心。可信数据空间引入了**分布式数字身份(DID)**等技术,确保每个参与者都有一个可自证、可验证、防篡改的数字身份凭证。这保证了数据只会被授权的、合法的实体访问和使用。
1.2.2 数据可信(Trusted Data)
这个问题关乎数据的真实性和合法性。数据使用方需要确信他们所用的数据确实来自声称的源头,并且没有被篡改。数据提供方也需要确保他们提供的数据是准确无误的。通过区块链等技术对数据来源、元数据、权属信息等进行存证,可以形成一条清晰的数据血缘链条。这保证了数据的来源可追溯、内容可校验,杜绝了“假数据”或来源不明的数据污染整个协作生态。
1.2.3 过程可信(Trusted Process)
这是信任闭环中最关键的一环,确保数据的使用方式严格遵守预设的规则。即便身份和数据都可信,如果使用过程不受控制,数据滥用的风险依然存在。可信数据空间通过智能合约、使用控制和全流程审计等技术手段,将数据使用协议(如使用目的、时长、频次、算法等)转化为可自动执行的代码。整个数据处理过程都在受控环境中进行,并且每一步操作都被不可篡改地记录下来,确保了数据“怎么用”这个问题完全透明、合规且全程留痕。
这“三重可信”共同构成了一个完整的信任与安全框架。下表清晰地展示了它们的内涵与对应的技术抓手。
这个闭环体系,使得可信数据空间超越了单纯的技术工具,成为一个集规则、技术、治理于一体的综合解决方案,为数据要素市场的建立提供了坚实的信任底座。
二、 🔑 隐私计算:驱动“可用不可见”的加密引擎
隐私计算是实现“数据可用不可见”这一核心理念的计算引擎,它不是单一技术,而是一系列技术的总称。其共同目标是在不暴露原始数据内容的前提下,完成对数据的分析和计算。在可信数据空间的实践中,主要有三大技术路径,它们各有所长,常常协同工作。
2.1 多方安全计算 (Secure Multi-Party Computation, MPC)
多方安全计算(MPC)可以说是隐私计算领域“最纯粹”的密码学方案。它的核心思想是,多个互不信任的参与方,能够在不泄露各自私有数据的情况下,共同完成一个计算任务,并得到最终结果。
2.1.1 工作原理简析
MPC的背后是一系列复杂的密码学协议,如混淆电路(Garbled Circuit)和秘密分享(Secret Sharing)。我们可以用一个经典的“百万富翁问题”来通俗理解。两个富翁想知道谁更有钱,但又不想告诉对方自己的具体财富。通过MPC协议,他们可以进行一系列加密交互,最终只得到一个“A比B有钱”或“B比A有钱”的结果,而整个过程中,双方的财富数据始终没有泄露。
在实际应用中,数据被拆分成多个加密的“秘密份额”,分发给不同的计算节点。每个节点只能看到无意义的乱码份额,只有当所有节点协同计算时,才能根据预设的算法,在密态下完成计算,最后将结果份额合并,解密得到最终答案。
2.1.2 优劣势与适用场景
优势,MPC提供了极高的安全性保障,其安全性基于严格的数学证明,不依赖任何硬件或特定的信任假设。
劣势,由于复杂的加密通信和计算开销,MPC的性能通常较低,通信延迟也比较高,不太适合处理海量数据或复杂的机器学习模型训练。
因此,MPC特别适合那些对隐私安全要求极高、计算逻辑相对简单的场景,例如,金融机构间的联合征信查询、政府部门间的敏感数据联合统计、以及多方联合的反洗钱调查。
2.2 联邦学习 (Federated Learning, FL)
如果说MPC是纯粹的密码学卫士,那么联邦学习则是为分布式机器学习量身打造的隐私保护框架。随着AI应用的普及,联合多方数据训练出更强大的模型成为刚需,联邦学习应运而生。
2.2.1 “数据不动,模型动”的核心范式
联邦学习的核心理念是**“数据不动,模型动”**。原始数据永远不会离开其所有者(如企业服务器或用户设备),从而最大限度地保护了数据隐私和主权。
它的工作流程通常如下,
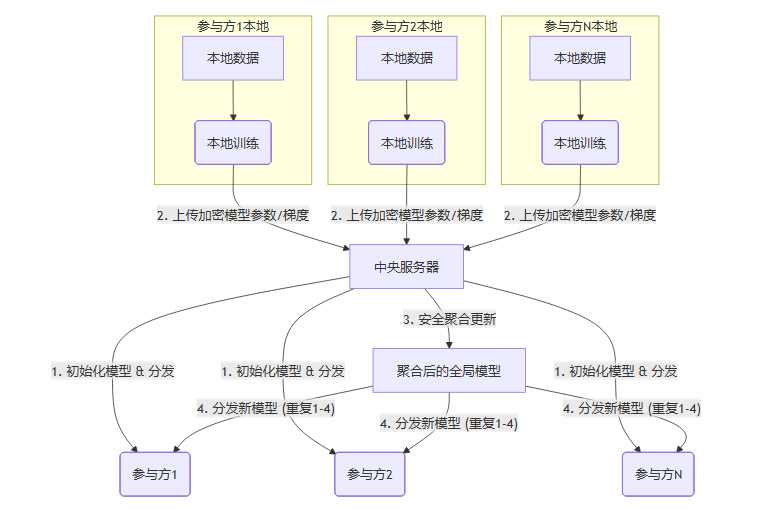
在这个循环往复的过程中,各参与方只交换不包含原始数据信息的模型参数(梯度或权重),并且这些参数在传输前通常还会经过同态加密、差分隐私等技术加固,防止被逆向推导出原始数据。
2.2.2 优劣势与适用场景
优势,联邦学习保留了数据的本地性,通信开销相对MPC较低,非常适合复杂的机器学习任务,扩展性也更好。
劣势,它的安全性依赖于模型的参数无法被轻易逆向破解,存在一定的模型反演攻击风险。此外,非独立同分布(Non-IID)的数据会给模型收敛带来挑战。
联邦学习的应用场景非常广泛,尤其是在AI建模领域。例如,多家银行联合训练反欺诈模型、多家医院联合进行疾病预测模型研究、以及手机输入法利用用户本地数据优化预测模型,都是联邦学习的典型应用。
2.3 可信执行环境 (Trusted Execution Environment, TEE)
可信执行环境(TEE)提供了一条与纯密码学方案不同的路径,它依赖硬件来构建一个安全的“保险箱”。
2.3.1 硬件隔离的“安全飞地”
TEE是CPU内部的一块物理隔离区域,通常被称为Enclave。进入这块区域的代码和数据,会受到CPU硬件级别的加密和保护。即便是操作系统(OS)、虚拟机管理器(Hypervisor)等拥有最高权限的软件,也无法窥探或篡改Enclave内部的运行状态。
工作流程大致是,应用程序将需要保护的代码和数据加载到Enclave中,CPU会对其进行加密。外界只能通过一个严格定义的接口与Enclave交互。同时,TEE还提供**远程证明(Remote Attestation)**机制,允许数据提供方远程验证在对方服务器上运行的代码确实是自己授权的、未经篡改的版本,从而建立信任。
2.2.2 优劣势与适用场景
优势,TEE的性能开销非常低,可以近乎原生速度运行任意复杂的计算任务,通用性极强。
劣势,它的安全性强依赖于硬件厂商(如Intel SGX, AMD SEV),用户必须信任硬件没有后门。此外,侧信道攻击(Side-Channel Attack)是TEE面临的一个持续挑战。
TEE非常适合那些对计算性能要求高、算法逻辑复杂的场景。例如,在公有云上运行敏感数据处理任务、构建高性能的数据分析沙箱、以及在区块链中执行保密的智能合约。
2.4 技术选型与融合
这三种技术并非相互排斥,在先进的可信数据空间方案中,它们往往是融合使用的,以取长补短。
例如,可以在TEE构建的安全沙箱中运行联邦学习的聚合服务器,这样既保护了各方的数据本地性,又确保了中心聚合过程的机密性。也可以用MPC来完成联邦学习中关键的梯度聚合步骤,以增强安全性。这种“混合动力”模式,正是可信数据空间技术发展的趋势,为不同安全等级和性能要求的场景提供了灵活的解决方案。
三、 🔗 区块链与智能合约:铸造不可篡改的信任契约
%20拷贝.jpg)
如果说隐私计算解决了“计算过程”的安全问题,那么区块链与智能合约则致力于解决“流通过程”的信任问题。它们共同为可信数据空间构建了一个不可篡改、可追溯、自动执行的信任底层,像一个全天候、不知疲倦的数字公证员。
3.1 区块链:数据流通的“公证处”与“历史书”
区块链的核心价值在于其提供的技术信任。通过密码学哈希、链式结构和分布式共识机制,它创造了一个几乎无法被篡改的分布式账本。在可信数据空间中,它扮演着两个至关重要的角色。
3.1.1 不可篡改的存证
数据流通的每一个关键环节,从数据注册、授权、调用,到计算结果的生成,其操作日志、时间戳、参与方身份等关键信息,都可以被哈希后记录在区块链上。每一次记录都会生成一个新的区块,并与前一个区块紧密相连,形成一条不可逆转的链条。
这意味着什么?这意味着任何人都无法在事后悄悄删除或修改一条使用记录而不被发现。这就为事后的审计、追责和争议解决提供了铁证。当数据提供方和使用方就“数据是否被超范围使用”产生分歧时,区块链上的记录就是最公正的裁判。
3.1.2 可追溯的数据血缘
数据的价值往往在多次加工和融合后才能最大化。一个模型可能使用了来自A、B、C三方的数据,而这个模型产生的结果又被D机构用于新的分析。当最终结果出现问题,或者需要进行收益分配时,如何理清这错综复杂的贡献关系?
区块链完美地解决了这个问题。通过将每一次数据的流转和加工关系上链,可以形成一条清晰、完整的数据血缘(Data Lineage)。我们可以从任何一个数据产品出发,向上追溯它的所有原始数据来源、中间处理步骤以及参与的算法,也可以向下追溯它被哪些下游应用所使用。这种端到端的透明性,对于确保数据合规性、进行价值评估和构建公平的利益分配机制至关重要。
3.2 智能合约:自动化执行的“规则引擎”
如果说区块链是记录历史的“历史书”,那么智能合约就是自动执行未来的“规则引擎”。智能合约是部署在区块链上的一段代码,它将传统合同的条款——如权利、义务、触发条件——程序化。一旦预设的条件被满足,合约代码就会自动执行,全程无需人工干预。
在可信数据空间中,智能合约将数据流通的商业规则和合规要求,从一纸文书变成了刚性的技术约束。
自动化授权与访问控制,数据提供方可以制定一个智能合约,规定“只有支付了1个以太币的B公司,才能在未来30天内访问我的数据集X”。当B公司完成支付后,合约自动为其开启访问权限;30天到期后,权限自动撤销。
精细化的使用规则执行,合约可以规定,“数据集Y仅可用于心脏病预测模型训练,禁止用于营销目的,且每日调用次数不得超过100次”。任何超出此范围的请求都会被智能合约自动拒绝。
自动化的计费与收益分配,每次数据被调用或使用,智能合约都可以根据链上记录的使用量,自动计算费用,并按照预设的比例(例如,数据方A占70%,平台方占30%)将收益实时或定期分配到各自的数字钱包中,极大地提高了清结算效率和透明度。
33.3 协同作用:构建“过程可信”的闭环
区块链与智能合约的结合,为“过程可信”提供了坚实的保障。区块链负责**“忠实记录”,确保所有行为都有据可查、无法抵赖。智能合约负责“严格执行”**,确保所有行为都严格遵守预设规则。二者协同工作,将人与人之间的商业信任,转化为机器与机器之间的技术信任,极大地降低了多方协作的摩擦成本和合规风险。
四、 🛡️ 数据沙箱与使用控制:构建可控可计量的“安全围栏”
有了隐私计算的加密引擎和区块链的信任契约,我们还需要一个安全可靠的“执行场地”。数据沙箱与使用控制技术,共同构建了这样一个物理上或逻辑上隔离的“安全围栏”,确保数据在实际使用环节的万无一失。
4.1 数据沙箱:隔离计算的“无菌室”
数据沙箱,顾名思义,是一个与外界隔离的、受控的计算环境。它的核心目标是,让数据可以在这个“沙箱”内被充分计算和分析,但原始数据本身永远不会离开这个环境。这就像一个高科技的“无菌室”,研究人员可以穿着防护服在里面操作珍贵的样本,但绝不能将样本带出实验室。
实现数据沙箱的技术路径多样,
基于虚拟化/容器化技术,通过创建虚拟机(VM)或容器(Docker),为每个数据处理任务提供一个独立的、资源受限的运行空间。这是目前最主流的实现方式。
基于可信执行环境(TEE),如前文所述,利用硬件隔离能力构建一个“硬沙箱”。这提供了更高级别的安全性,因为连云服务商本身也无法窥探沙箱内的计算过程。
在沙箱内,数据通常以脱敏或加密形态存在。外部用户只能通过特定的API接口提交计算任务(如一段SQL代码或一个Python脚本),沙箱在内部执行任务后,只返回经过审核的、不含敏感信息的结果。这种机制,是“所有权与使用权分离”理念在执行层面的最直接体现。
4.2 使用控制:从“合同条款”到“技术策略”的精细化革命
如果说数据沙箱管住了“环境”,那么使用控制则管住了“行为”。它是一种更为精细和动态的数据管理技术,旨在将数据共享协议中的法律和商业条款,转化为可被机器理解和强制执行的技术策略。这超越了传统的、静态的访问控制(Access Control),实现了对数据出域后的使用过程控制(Usage Control)。
使用控制可以对数据使用的多个维度进行约束,
这些策略可以动态配置和调整,确保数据始终在其生命周期的每个阶段,都处于“可控、可计量”的状态。
4.3 沙箱与控制的共舞:管环境,也管行为
数据沙箱和使用控制是天作之合。沙箱提供了一个安全的执行环境,防止数据本体泄露。使用控制则在这个环境中,对具体的计算行为进行精细化约束。二者结合,为数据提供方提供了强大的信心,他们知道自己的数据不仅不会被“偷走”,更不会被“滥用”。这种确定性,是促使数据持有方从“不愿共享”到“放心共享”转变的关键一步。
五、 🏛️ 治理与标准:从技术孤岛到国家级基础设施
%20拷贝-ixxe.jpg)
可信数据空间要真正发挥作用,光有强大的技术还不够,必须要有统一的标准和治理框架,才能避免各自为战,形成“新的技术孤岛”。幸运的是,从国家层面,可信数据空间正被提升到前所未有的战略高度。
5.1 分布式数字身份与接入连接器:统一的“身份卡”与“标准接口”
在“三重可信”中,“身份可信”是基础。**分布式数字身份(DID)**体系为网络世界的每个实体(人、机构、设备)提供了一个全局唯一的、可自控的身份标识。这套体系确保了身份的验证过程不依赖于任何中心化的第三方,为跨主体、跨地域的数据流通奠定了坚实的身份根基。
而接入连接器(Access Connector),则可以看作是各个参与方进入可信数据空间的“标准化入口”或“适配器”。它封装了与数据空间交互所需的标准协议,承载了数据目录注册、数字合约协商、使用控制策略执行等关键功能。通过统一的接入连接器,可以极大地降低不同技术背景、不同系统的参与方之间的对接成本,提升整个生态的可运维性和可监管性。
5.2 对标国家标准:权威的技术框架指引
我国在可信数据空间领域的标准化工作走在了世界前列。2024年初,经国家数据局同意,全国数据标准化技术委员会(全国数标委)正式发布了《可信数据空间 技术架构》文件。
这份文件的发布意义重大,
明确定位,它首次在国家层面明确将可信数据空间定位为国家数据基础设施的重要组成部分。
规范架构,它系统性地规范了可信数据空间的技术架构、核心功能和业务流程,为产业界的建设和运营提供了权威指引。
凝聚共识,文件强调,可信数据空间需具备可信管控、资源交互、价值共创和安全管理等核心功能,并明确指出隐私计算、区块链、智能合约、使用控制、身份管理等技术是实现这些功能的核心支撑。
国家标准的出台,意味着可信数据空间的发展有了统一的“度量衡”和“施工图”,将有力地指导地方政府、行业龙头和科技企业开展相关实践。
5.3 政策协同与试点推进:从蓝图到现实
顶层设计正在加速落地。国家数据局发布的**《“数据要素×”三年行动计划(2024—2026年)》**等一系列政策,都在鼓励和支持可信数据流通技术的应用。可以预见,围绕城市治理、金融科技、医疗健康、工业制造等重点行业,将会涌现出一大批可信数据空间的创新试点和示范项目,逐步形成多层级、广覆盖的全国一体化数据要素流通网络。
六、 典型应用场景:技术价值的商业落地
理论最终要服务于实践。可信数据空间的技术组合,已经在多个关键领域展现出巨大的应用价值。
总结
可信数据空间,这个“数据保险箱”,远非单一技术的代名词,它是一个深度融合了**“规则、技术、治理”**的复杂系统。它通过隐私计算、区块链与智能合约、数据沙箱与使用控制、分布式身份与接入标准化这四大技术支柱的协同作用,巧妙地在数据安全与价值释放之间找到了一个精妙的平衡点。
它所构建的**“数据可用不可见、全程可追溯、身份与过程可信”**的新范式,不仅是对现有数据共享模式的一次颠覆性创新,更是对未来数字社会信任基石的一次重要奠基。随着国家标准的引领和产业实践的深化,可信数据空间必将从一个前沿的技术理念,演变为支撑数字经济高质量发展的关键基础设施,真正让数据这一核心生产要素,安全、高效地流动起来,创造出前所未有的价值。
📢💻 【省心锐评】
可信数据空间的核心,是把对“人”的信任,转变为对“技术规则”的信任。它标志着数据要素市场正从野蛮生长的1.0时代,迈向合规、可控、可计量的2.0时代。

评论