.png)


【摘要】剖析Olive应用架构,揭示其利用公共数据库与本土化策略,在健康消费细分市场实现商业闭环的技术路径。
引言
在北美市场,一款名为「Olive」的食品扫描应用,上线仅10个月,便在全球积累了47.2万次下载,并创造了近80万美元的应用内收入。其高达99%的收入来自美国地区,每日活跃用户平均收入(ARPDAU)更是达到了惊人的0.84美元。这一系列数据,远超常规工具类应用的表现。
「Olive」的成功并非偶然。它精准地切入了美国3300万食物过敏人群的刚性需求,并巧妙地利用了现有技术栈与公共数据资源,构建了一个看似简单却商业逻辑闭环的产品。这篇文章将从市场需求、技术架构、数据策略、商业模式等多个维度,深度解码「Olive」的成功路径,分析其如何在成熟的赛道中,通过差异化的本土策略找到生存空间,并最终验证一个高价值细分市场的商业潜力。
💠 一、市场洞察与需求定义
%20拷贝.jpg)
任何成功的技术产品,都源于对市场需求的精准捕捉。「Olive」的崛起,建立在对北美健康消费市场深刻的洞察之上。
1.1 北美健康消费市场的宏观背景
美国拥有一个庞大且结构复杂的健康消费市场。根据FARE(美国食物过敏研究与教育机构)的数据,约有3300万美国人至少对一种食物过敏。这个数字背后,是无数个家庭在日常购物中面临的困扰与风险。其中,花生和坚果是主要的过敏原,而这些成分又被广泛应用于各类包装食品中。
这个庞大的用户基数,构成了食品成分识别类应用最基础的市场盘。用户的需求并非“锦上添花”的健康建议,而是“雪中送炭”的安全保障。这种需求的刚性,直接决定了其付费意愿的强度。
1.2 包装食品的“信息不对称”痛点
消费者面临的核心痛点,源于包装食品标签的**“信息不对称”**。尽管法律要求标注主要成分,但制造商常使用模糊或概括性的术语,这为消费者带来了巨大的识别障碍。
这种信息鸿沟,使得消费者即使仔细阅读标签,也难以做出百分之百安全的选择。每一次购物,都像是一次“赌博”。「Olive」正是瞄准了这一痛点,致力于将复杂、模糊的成分表,翻译成用户能瞬间理解的、明确的健康信号。
1.3 从痛点到产品价值主张
基于以上痛点,「Olive」构建了清晰的价值主张。它不把自己定位成一个卡路里计算器或营养师,而是一个“个人健康安全哨兵”。其核心任务非常聚焦,即帮助用户在购物时快速、准确地识别出包装食品中潜在的、对自己有害的成分。
这个定位决定了其产品设计的优先级。
速度优先。购物场景下,用户没有时间进行复杂操作。扫码即出结果是基本要求。
准确性优先。错误的判断可能导致严重的健康后果,因此数据的可靠性是产品的生命线。
个性化优先。通用的健康建议价值有限。只有结合用户自身的过敏原、饮食禁忌,信息才具备真正的决策价值。
这三大原则,贯穿了「Olive」后续的技术选型、功能设计和商业模式构建的全过程。
💠 二、技术架构与数据流解析
「Olive」的商业成功,离不开其务实且高效的技术架构。它没有追求前沿但复杂的AI技术,而是选择了成熟、可靠的技术路径,将重点放在数据整合与个性化逻辑处理上。
2.1 核心技术选型:条码扫描 vs. 图像识别
在食品识别领域,主要存在两种技术路径,即图像识别(OCR或模型识别)和条码扫描。
图像识别。通过手机摄像头拍摄食物或配料表,利用OCR技术提取文字,或通过图像识别模型直接判断食物种类。这种方式适用范围广,可以识别无包装的生鲜、餐馆菜品等。但其技术挑战巨大,识别准确率受光线、角度、字体、食物形态等多种因素影响,尤其在解析密集复杂的配料表时,错误率较高。
条码扫描。通过扫描商品包装上的条形码(如UPC、EAN),获取独一无二的商品ID。然后用这个ID去后台数据库中查询预先录入的、结构化的商品信息。这种方式的优点是速度快、准确率极高,因为条码本身就是为机器读取而设计的。其缺点是无法识别没有条码的商品。
「Olive」聚焦于包装食品,这个场景与条码扫描技术完美契合。选择条码扫描,是一个典型的“扬长避短”的工程决策。它放弃了对非标场景的覆盖,换来了核心场景下极致的稳定性和可靠性,这对于一个主打“安全”的应用至关重要。
2.2 数据层构建:双数据库驱动的信任基石
应用的核心资产是其背后的数据。数据的广度、深度和权威性,直接决定了产品的天花板。「Olive」的数据层主要依赖两大公开数据库,并通过自建系统进行整合与增强。
2.2.1 两大核心数据源
「Olive」聪明地站在了巨人的肩膀上,整合了两个业界公认的权威数据源。
通过将Open Food Facts的广度与FDA的权威性相结合,「Olive」构建了一个交叉验证的数据体系。前者提供了“是什么”(成分列表),后者提供了“安不安全”(法规标准)。这种组合拳,极大地提升了检测结果的可信度。
2.2.2 数据处理与整合架构
仅仅拥有数据源是不够的,如何清洗、整合、并高效地提供服务,是后端架构的关键。一个可能的简化架构如下。
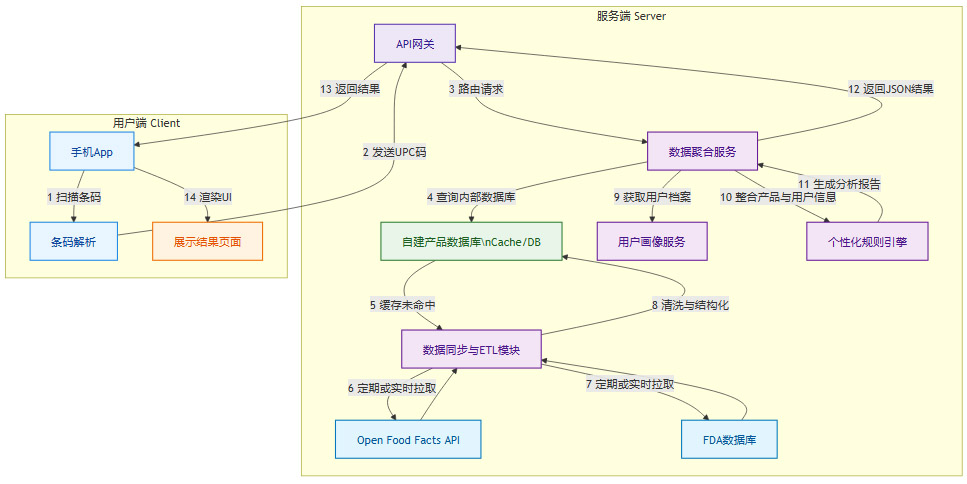
这个流程体现了几个关键设计。
自建数据库与缓存。直接请求外部API速度慢且不可靠。必须构建本地数据库作为一级数据源,并利用缓存(如Redis)加速高频查询。
异步ETL(提取、转换、加载)。数据同步模块是后台的“脏活累活”中心。它需要定期从Open Food Facts和FDA拉取更新,进行数据清洗(去除重复、修正错误)、结构化处理(将非结构化的成分文本解析为标签化的实体),然后加载到自建数据库中。
微服务架构。将数据聚合、用户画像、规则引擎等拆分为独立的服务,有利于独立开发、部署和扩展。
2.3 应用层逻辑:从数据聚合到个性化裁决
「Olive」最核心的竞争力,在于其应用层的个性化规则引擎。这个引擎完成了从“数据呈现”到“决策辅助”的关键一跃。
2.3.1 用户健康档案的建立
首次使用时,应用会引导用户建立一份详细的个人健康档案。这份档案是后续所有个性化分析的基础,可能包含以下维度。
过敏原 (Allergens)。多选列表,如花生、坚果、牛奶、鸡蛋、大豆、麸质等。
饮食偏好 (Dietary Preferences)。如素食 (Vegan)、纯素 (Vegetarian)、生酮 (Keto)、旧石器 (Paleo) 等。
特定规避成分 (Specific Ingredients to Avoid)。这是一个开放的标签系统,用户可以手动添加任何不希望摄入的成分,比如“籽油 (Seed Oils)”、“阿斯巴甜 (Aspartame)”、“人工色素 (Artificial Colors)”等。
这份档案被存储在用户画像服务中,并与用户的唯一ID关联。
2.3.2 规则引擎的工作流
当用户扫描一个商品时,规则引擎开始工作。
成分实体识别 (Named Entity Recognition, NER)。首先,引擎会从产品数据库中获取该商品的成分列表(一个长字符串)。然后,通过NER技术,将这个字符串解析成一个包含多个成分实体的集合。例如,将
"成分:水、小麦粉、植物油(含大豆油)、盐、天然香料"解析为["水", "小麦粉", "植物油", "大豆油", "盐", "天然香料"]。规则匹配与打分。引擎将解析出的成分实体集合,与用户的健康档案进行匹配。匹配逻辑可能非常复杂,包含多层规则。
一级规则(硬规则)。直接匹配过敏原。如果产品成分中含有用户档案中标记的过敏原,系统会发出最高级别的**“危险”**警报。
二级规则(偏好规则)。匹配饮食偏好和规避成分。如果产品含有肉类,而用户是素食者;或者产品含有“玉米油”,而用户规避“籽油”,系统会给出**“不推荐”**的标记。
三级规则(健康评分模型)。除了用户的个性化规则,引擎还会内置一个通用的健康评分模型。该模型会根据产品是否含有过多添加剂、合成成分、高糖、高钠等因素,给出一个综合评分。
结果聚合与输出。最后,引擎将所有规则的匹配结果进行聚合,生成一份简单易懂的分析报告。报告通常包含一个总分、一个明确的建议(如“适合您”、“请注意”、“不适合您”),以及详细的风险项说明。
2.4 前端交互设计:降低用户决策摩擦力
技术最终要通过交互呈现给用户。「Olive」的前端设计,严格遵循了“降低决策摩擦力”的原则。
即时反馈。扫描条码后,结果页面加载极快,几乎没有等待感。
视觉化信号。使用醒目的颜色(如绿色、黄色、红色)和图标来传达最终建议,用户一瞥即可了解核心信息。
信息分层。结果页面首先展示最重要的总分和一句话建议。用户如果想了解详情,可以点击展开,查看具体的成分分析和风险点。这种设计,既满足了快速决策的需求,也兼顾了深度了解的可能。
通过这一整套从数据到交互的精心设计,「Olive」成功地将一个复杂的数据查询与分析过程,包装成了一个用户体验流畅、价值传递清晰的产品。
💠 三、差异化突围:本土化策略的深度实践
%20拷贝.jpg)
在「Olive」进入市场之前,食品扫描赛道已有「Yuka」这样的全球性头部产品。「Yuka」在全球拥有数千万用户,产品模式已经相当成熟。作为一个后来者,「Olive」能够快速崛起,其核心在于精准且深度的本土化策略。
3.1 竞品分析:在Yuka的阴影下寻找缝隙
「Yuka」是一个来自法国的应用,其核心理念是“透明化健康消费”,通过扫描食品和化妆品,给出一个0-100的健康评分。它的评分体系主要关注营养质量、添加剂和有机认证。
「Olive」与「Yuka」的对比,体现了两种不同的产品哲学。
「Olive」没有选择与「Yuka」在通用健康评分上正面竞争,而是选择了一个更窄但更深的切口——个性化与本土化。
3.2 本土化切入点:“无籽油”饮食风潮
「Olive」最成功的本土化实践,莫过于其对美国市场新兴的**“无籽油(Seed Oil Free)”饮食风潮**的精准捕捉。
3.2.1 “无籽油”趋势的背景
所谓“籽油”,通常指从植物种子中提取并经过工业精炼的高油脂植物油,如大豆油、玉米油、菜籽油、葵花籽油等。近年来,在美国的健康论坛、社交媒体和播客中,一股反对工业籽油的风潮逐渐兴起。
其核心论点认为,这些精炼油富含Omega-6多不饱和脂肪酸,在现代饮食中摄入过量,且经过高温高压的工业处理,可能导致身体慢性炎症,并与多种现代疾病相关。虽然这一理论在主流医学界仍有争议,但它已经形成了一个强大的亚文化社群。
这个社群的用户有几个典型特征。
认知水平高。他们对营养学有一定了解,愿意为更“干净”的饮食付出研究成本。
行动力强。他们会主动阅读配料表,规避特定成分。
付费意愿强。他们愿意为符合其饮食理念的产品和服务支付溢价。
社交传播意愿强。他们乐于在社群中分享自己的发现和经验。
这正是**高价值、高粘性的“超级用户”**画像。
3.2.2 Olive如何将趋势转化为功能
「Olive」敏锐地将“无籽油”这一小众但高粘性的需求,融入了其核心产品逻辑。
纳入规避列表。在用户的健康档案中,将“籽油”作为一个重要的可选项。
增强成分识别。在后台的成分数据库中,为所有常见的籽油(如Soybean Oil, Canola Oil, Corn Oil等)打上“Seed Oil”的标签。
融入评分引擎。在规则引擎中,将“含有籽油”作为一个重要的扣分项或“不推荐”的触发条件。
通过这三步,「Olive」迅速成为了“无籽油”饮食社群的“官方指定App”。这个社群的用户发现,终于有一款工具能够帮助他们从繁琐的标签阅读中解放出来,极大地提升了购物效率。
3.3 功能延伸:从购物到餐饮的全场景覆盖
在服务好核心购物场景后,「Olive」进一步思考如何提升用户粘性,覆盖更多健康消费场景。其推出的**“查找无籽油餐厅”**功能,是又一次精准的场景延伸。
这个功能解决了一个核心痛点。对于严格执行“无籽油”饮食的用户来说,外出就餐是一个巨大的挑战,因为绝大多数餐厅都使用廉价的籽油进行烹饪。
「Olive」通过与餐厅合作或利用众包数据,建立了一个“无籽油”餐厅的数据库。用户可以在App内直接搜索附近的合规餐厅。这一功能,成功地将「Olive」的服务从“买什么”延伸到了“吃什么”,覆盖了用户从家庭到外出的完整饮食闭环。这种场景的延伸,极大地提升了产品的日活和用户粘性,使其从一个低频的购物工具,向一个更高频的生活助手转变。
3.4 用户画像细分:服务特定饮食社群
除了“无籽油”社群,「Olive」也通过其灵活的个性化配置,服务了其他各类特定饮食人群,如素食者、生酮饮食者、麸质过敏者等。它为每个社群都提供了精准的筛选和推荐服务,把自己打造成了一个服务于多个垂直健康社群的平台级入口。
这种策略,让「Olive」在每个细分领域都建立了强大的用户心智。当一个用户向朋友推荐时,他会说“如果你是素食者,你应该用Olive”,或者“如果你在避免籽油,你必须用Olive”。这种基于身份认同的口碑传播,远比泛泛的“健康App”推荐要有效得多。
💠 四、商业模式与变现策略
一款优秀的技术产品,最终需要通过有效的商业模式来实现其价值闭环。「Olive」在商业化上的表现尤为出色,其高ARPDAU和高付费转化率,为工具类应用提供了极具参考价值的范本。
4.1 订阅制:锁定高价值用户的必然选择
「Olive」采用了纯粹的订阅制(Subscription)模式,而没有选择广告或一次性买断。这是一个深思熟虑的战略选择。
用户价值匹配。产品的核心用户是那些对健康有严肃需求、愿意为之持续投入的人群。订阅制筛选出了这批高价值用户,并与他们建立了长期关系。
收入可预测性。订阅制带来了稳定、可预测的经常性收入(Recurring Revenue),这对于初创公司的健康发展至关重要。
产品迭代动力。为了让用户持续续费,团队必须不断优化产品、更新数据库、提供更多价值。这形成了一个正向的激励循环。
避免利益冲突。如果采用广告模式,App可能会推荐某些付费推广的“健康”产品,这会损害其作为中立、客观第三方工具的公信力。纯订阅制保证了其立场永远和用户站在一起。
4.2 定价与试用策略:降低决策门槛,彰显长期价值
「Olive」的定价策略,旨在引导用户选择长期订阅,从而最大化单用户生命周期价值(LTV)。
这个定价结构的设计非常巧妙。
高价月费。7.99美元的月费相对较高,其主要作用是锚定价值,让用户感知到这是一个严肃、专业的工具。同时,它也成为了年度订阅的“价格锚点”。
高折扣年费。39.99美元的年费,折合每月仅3.33美元,相比月费有超过58%的折扣。这个巨大的价差,强烈地激励用户选择年费方案。点点数据显示,年费订阅是销量最高的内购项目,证明了这一策略的成功。
差异化试用期。为年费订阅提供更长的7天试用期,进一步鼓励用户尝试这个选项。用户有更充足的时间来体验产品的价值,从而更有信心做出长期的付费承诺。
透明的取消政策。App明确强调“试用期内可随时取消”,打消了用户的后顾之忧,极大地降低了首次订阅的心理门槛。
通过这套组合拳,「Olive」成功地将大部分用户转化为了高LTV的年度订阅用户,为其带来了健康的现金流和稳定的用户基本盘。
4.3 商业价值的底层逻辑
「Olive」之所以能支撑起如此高的客单价和付费率,其底层逻辑在于它提供的价值,已经超越了一个普通工具。
时间价值。它为用户节省了大量在超市货架前研究配料表的时间。对于时间成本高昂的美国中产用户来说,每月花费几美元来节省数小时的时间,是一笔非常划算的买卖。
健康价值。它帮助用户避免了因误食过敏原或不健康成分而导致的潜在健康风险。这种“保险”的价值,在用户心中是无价的。
认知价值。它降低了用户践行复杂饮食理念(如无籽油、生酮)的认知门槛和执行难度。用户不再需要成为半个营养专家,只需跟随App的指引即可。
当一个产品能够同时提供这三重价值时,其高昂的订阅费就变得合情合理,用户付费也就成了水到渠成的事情。
💠 五、挑战与反思:在科学与焦虑之间走钢丝
%20拷贝.jpg)
尽管「Olive」在商业上取得了巨大成功,但它也面临着所有健康类应用共同的挑战,即如何在提供科学建议和制造用户焦虑之间,找到一个微妙的平衡。
5.1 “贩卖焦虑”的指责
在App Store的评论区和社交媒体上,不乏对「Olive」的批评声音。一些用户反馈称,应用将他们家中几乎所有的存货都标记为“不健康”或“不推荐”,甚至包括一些他们原本认为相当“干净”的有机食品。
这种体验,让部分用户感到沮丧和无所适从,认为“这更像是一种基于恐惧的营销,而不是实用的指导。”这种指责,触及了此类应用的核心伦理困境。
评分标准的严苛性。为了体现其专业性和差异化,「Olive」可能采用了比主流标准更严苛的评分模型。例如,任何含有添加剂或精炼糖的产品,都可能被直接打入低分。这种“一刀切”的做法,虽然立场鲜明,但可能脱离了普通消费者的现实生活。
信息呈现的方式。使用强烈的负面词汇(如“有毒”、“危险”)和刺眼的红色警告,虽然能起到警示作用,但也容易引发用户的恐慌和焦虑情绪。
科学依据的争议性。特别是对于“无籽油”这类新兴的、在科学界尚存争议的饮食理念,将其作为核心评分标准,可能会被一部分人视为“伪科学”或“过度解读”。
5.2 技术与数据的局限性
除了伦理困境,产品在技术和数据层面也存在固有的局限性。
数据库的完备性与时效性。尽管整合了Open Food Facts,但数据库仍然不可能覆盖市场上所有商品,特别是新品或小众品牌。制造商也可能随时更改产品配方。数据库的滞后,可能导致用户扫描到一个旧版本的产品信息,从而做出错误判断。
成分解析的准确性。NER技术虽然强大,但对于复杂、不规范的配料表文本,仍然可能出现解析错误,比如漏掉某个成分,或者将一个词错误地识别为另一个。
上下文的缺失。App的判断完全基于成分列表,它无法考虑**“剂量”和“食用频率”**这两个关键因素。一个含有微量添加剂、偶尔食用的零食,和一个含有同样添加剂、作为主食每天食用的产品,其健康影响是完全不同的。但App的评分系统,可能无法区分这种差异。
5.3 发展的平衡之道
面对这些挑战,「Olive」以及同类应用,需要在未来的发展中,思考如何走得更稳、更远。
提升信息透明度。不仅要给出“好”或“坏”的结论,更要清晰地解释**“为什么”**。比如,明确指出评分是基于哪个规则(是过敏原?是籽油?还是通用健康模型?),并提供相关科学文献或权威指南的链接,让用户自己做出最终判断。
引入分级与个性化阈值。可以允许用户自定义评分的“严格程度”。比如,一个只想避免致命过敏原的用户,和一个追求极致“干净”饮食的用户,应该看到不同层级的警报。
强调“辅助工具”定位。在产品文案和用户引导中,应反复强调App是一个“决策辅助工具”,而非“医疗建议”。特别是对于严重过敏者,应明确提示不能完全依赖App,仍需仔细阅读官方标签。
建立反馈与修正机制。应提供便捷的渠道,让用户可以报告错误信息、提交新产品数据。通过社区的力量,不断完善数据库的准确性和覆盖率。
一个负责任的健康应用,其目标应该是赋能用户(Empowerment),而不是恐吓用户(Fear-mongering)。如何在保持商业锐度的同时,坚守这份社会责任,将是「Olive」未来需要持续回答的问题。
结论
「Olive」的成功,为我们提供了一个在垂直赛道中实现商业突破的经典案例。它并没有发明全新的技术,而是将现有的技术(条码扫描、数据库技术、规则引擎)进行了巧妙的组合与应用,并深度融入了对目标市场文化的洞察。
其路径可以总结为以下几点。
精准切入。从庞大的健康市场中,识别出“食物过敏”和“成分透明度”这一刚性需求。
务实构建。选择成熟可靠的技术栈,站在公共数据库的肩膀上,快速构建出稳定、可信的核心产品。
深度本土化。超越竞品的通用模式,抓住“无籽油”等本土化趋势,构建了强大的差异化壁垒和用户心智。
价值变现。通过精准的订阅制和定价策略,成功锁定了高价值用户,实现了健康的商业闭环。
「Olive」的故事告诉我们,在技术日益同质化的今天,对用户需求的深刻理解、对细分文化的敏锐捕捉,以及将这些洞察转化为产品功能和商业模式的能力,正在成为越来越重要的核心竞争力。对于开发者而言,与其追逐下一个技术风口,不如静下心来,在我们熟悉的领域里,寻找那些尚未被完美解决的、具体的、真实的“痛点”。那里,或许就隐藏着下一个“Olive”。
📢💻 【省心锐评】
Olive的成功,是技术务实主义的胜利。它证明了,与其追求颠覆性创新,不如将成熟技术与深刻的本土化洞察相结合,精准解决一个高价值的细分问题,这同样能开辟出一条通往商业成功的康庄大道。

评论