.png)


【摘要】高级提示词工程,通过结构化、引导式方法,解锁大模型在复杂推理、问题解决和创意生成方面的潜力。本文深入探讨Chain-of-Thought、Tree-of-Thought、Self-Refine等核心技术,分析其机制、优势与局限,并展望未来发展。
引言
大语言模型(LLM)的崛起,无疑是人工智能领域的一场革命。它们展现出惊人的文本理解、生成和推理能力。但是,要真正让这些模型发挥出最大效用,仅仅输入一个简单的指令是远远不够的。这就好比给一位拥有百科全书知识的智者一个模糊的问题,他可能无法给出你真正想要的答案。我们需要更精妙的“魔法咒语”,也就是高级提示词工程,来引导模型,让它不仅知道“是什么”,更知道“怎么做”,甚至“如何做得更好”。
高级提示词工程,正是这样一种艺术与科学的结合。它通过精心设计的提示词,将人类的思维过程、问题解决策略以及自我优化机制,巧妙地“注入”到大模型中。这不仅仅是简单的指令,更是一种思维框架的构建,一种认知路径的引导。它让大模型从一个被动的响应者,转变为一个主动的思考者、探索者和改进者。
本文将深入剖析几种当前最前沿、最具影响力的提示词工程技术:Chain-of-Thought(CoT)、Tree-of-Thought(ToT)和Self-Refine。我们会逐一揭示它们的工作原理、各自的优势与适用场景,以及它们可能存在的局限。同时,我们也会探讨这些技术如何通过结构化和引导式提示词的基础,共同提升大模型在复杂推理、问题解决和创意生成方面的能力。最终,我们将展望这些技术未来的发展方向,以及它们如何共同塑造AI应用的未来。
一、✨结构化与引导式提示词:大模型能力提升的基石
%20拷贝.jpg)
大模型的能力,很大程度上取决于我们如何与它沟通。结构化和引导式提示词,就是这种沟通的基础。它们就像是给模型绘制了一张清晰的地图,指明了目的地,也规划了路线。
1.1 🗺️ 明确任务与流程引导
结构化提示词,核心在于将一个复杂的任务,拆解成一个个清晰的模块。它会明确告诉模型,你的角色是什么(比如,你是一个专业的法律顾问),任务目标是什么(比如,分析这份合同的风险点),以及你希望它如何输出(比如,以列表形式列出风险,并给出改进建议)。这种模块化、分层设计,让模型对任务的理解更加深入,也减少了它“跑偏”的可能性。
引导式提示词,则是在结构化的基础上,进一步提供具体的指引。它可能包含一些示例,告诉模型在类似情况下应该如何思考和回应。它也可能提供一些上下文信息,帮助模型更好地理解当前情境。这些具体的指令和信息,就像是给模型提供了一系列路标,让它在执行任务时,能够沿着正确的路径前进,避免不必要的弯路。
1.2 🎯 优势:清晰、可控、泛化
结构化和引导式提示词带来的好处是显而易见的。
减少误解与“跳步”:当任务被清晰地分解,并且每一步都有明确的指令时,模型就不太可能误解任务意图,也不会在推理过程中遗漏关键步骤。
输出规范、可控:通过设定明确的输出格式和约束条件,我们可以确保模型生成的内容符合我们的预期,便于后续的自动化处理和集成。比如,要求模型以JSON格式输出数据,或者要求它生成一段不超过100字的摘要。
支持多模态与动态适应:这些提示词设计理念,不仅适用于文本任务,也能扩展到多模态领域。比如,在处理图像生成任务时,我们可以通过结构化提示词,明确图像的风格、内容元素和构图要求。同时,它们也支持动态适应,可以根据不同的输入和场景,灵活调整提示词,提升模型的泛化能力。
提升复杂任务表现:实践表明,像LangGPT这样的模板化实践,通过预设的结构和引导,能够显著提升大模型在处理复杂任务时的表现。它将提示词工程的经验固化为可复用的模板,让更多人能够高效地利用大模型。
二、🔗 Chain-of-Thought(CoT):逐步推理的“思维链”
Chain-of-Thought(CoT),直译过来就是“思维链”。它是一种非常直观且强大的技术,旨在引导大模型像人类一样,一步一步地进行推理。想象一下,当你在解决一个复杂的数学题时,你不会直接写出答案,而是会先列出已知条件,然后一步步地推导,最终得出结论。CoT就是让大模型也这样做。
2.1 🧠 核心机制:分解与表达
CoT的核心在于,它将一个看似复杂的任务,分解成一系列逻辑上相互关联的中间步骤。这些中间步骤,会以自然语言的形式,清晰地表达出来。通过这种方式,模型不仅给出了最终答案,还展示了它是如何得出这个答案的。这就像是给模型提供了一个“思考过程的范本”。
比如,在解决一个数学应用题时,CoT会引导模型先识别问题中的关键数字和操作,然后逐步应用数学规则进行计算,最终得出结果。这种方法显著提升了模型在算术推理、常识推理和符号推理等任务上的表现。
2.2 🛠️ 实现方式:少样本与零样本
CoT的实现方式主要有两种:
Few-Shot CoT(少样本CoT):这种方式是在给模型的提示中,提供几个包含完整推理步骤的示例。模型通过学习这些示例中的逻辑和推理模式,来处理新的、类似的问题。这就像是给学生提供了几个解题范例,让他们依葫芦画瓢。
Zero-Shot CoT(零样本CoT):这种方式则更加简洁。它不需要提供任何示例,只需要在原始提示中,简单地添加一句指令,比如“让我们一步步思考”(Let's think step by step)。令人惊讶的是,对于足够大的模型来说,仅仅这一句话,就能激发模型自主生成推理步骤,从而显著提升其性能。这表明大模型本身就具备一定的“思考”能力,只是需要一个简单的触发器。
2.3 🌟 优势:增强推理与可解释性
CoT带来的优势是多方面的:
增强推理能力:通过强制模型进行多步推理,CoT显著提升了模型处理复杂逻辑和多步骤任务的能力。它让模型不再仅仅是“记忆”答案,而是真正地“理解”问题并进行“推导”。
提高可解释性:由于模型会输出完整的推理链,用户可以清晰地看到模型是如何得出结论的。这大大增强了模型输出的透明度和可信度,也方便用户进行错误排查和验证。
易于实现与广泛适用:CoT的实现相对简单,只需要在提示词中加入一些示例或指令。它的适用范围也非常广泛,从解决数学问题、编写代码,到进行法律分析、医疗诊断,甚至日常的问答系统,都能看到CoT的身影。
2.4 🚀 进阶变体:CoT的演化
CoT技术本身也在不断演进,出现了一些更高级的变体,进一步提升了其效果:
Self-Consistency(自洽性):这种方法的核心思想是“集思广益”。它会让模型针对同一个问题,生成多条不同的推理链,从而得出多个可能的答案。然后,通过对这些答案进行“投票”或“多数决定”,选择最一致的答案作为最终结果。这就像是让多个专家独立思考,然后综合他们的意见,从而提高决策的准确性和稳定性。
Least-to-Most(从少到多):这种策略是将一个复杂的、难以直接解决的问题,分解成一系列更小、更简单的子问题。模型会先解决最简单的子问题,然后利用这些子问题的答案,逐步解决更复杂的子问题,最终解决整个大问题。这模拟了人类解决复杂问题时“化整为零”的策略。
ReAct(推理与行动):ReAct是“Reasoning and Acting”的缩写,它将CoT的推理能力与外部“行动”结合起来。这里的“行动”可以是调用外部工具(比如搜索引擎进行信息检索、计算器进行数学运算、代码解释器执行代码),也可以是与用户进行交互。模型会根据当前的推理结果,决定下一步需要采取什么行动,然后执行行动,并将行动结果反馈回推理过程,形成一个闭环。这使得大模型不再仅仅是“思考”,还能“动手”,极大地增强了其任务执行能力。
2.5 🚧 局限性:并非万能
尽管CoT非常强大,但它并非没有局限:
对模型规模的依赖:CoT的效果,尤其是Zero-Shot CoT,对大模型的规模有一定要求。较小的模型可能难以生成高质量的推理链,甚至无法理解“一步步思考”的指令。
简单问题的冗余:对于一些非常简单、直接的问题,强制模型生成推理链可能会显得冗余,反而增加了响应时间和计算成本。这就像是问1+1等于几,却要求对方详细解释加法原理一样。
响应速度:由于需要生成额外的推理步骤,CoT的响应速度通常会比直接生成答案慢一些。在对实时性要求极高的场景中,这可能是一个需要权衡的因素。
三、🌳 Tree-of-Thought(ToT):多路径探索的“思维树”
%20拷贝.jpg)
如果说CoT是线性推理的“思维链”,那么Tree-of-Thought(ToT)就是多路径探索的“思维树”。它将CoT的理念进一步扩展,允许大模型在解决问题的过程中,不仅沿着一条路径思考,还能同时探索多个可能的推理分支,就像人类在做复杂决策时,会考虑多种方案一样。
3.1 🌲 核心机制:分解、生成与评估
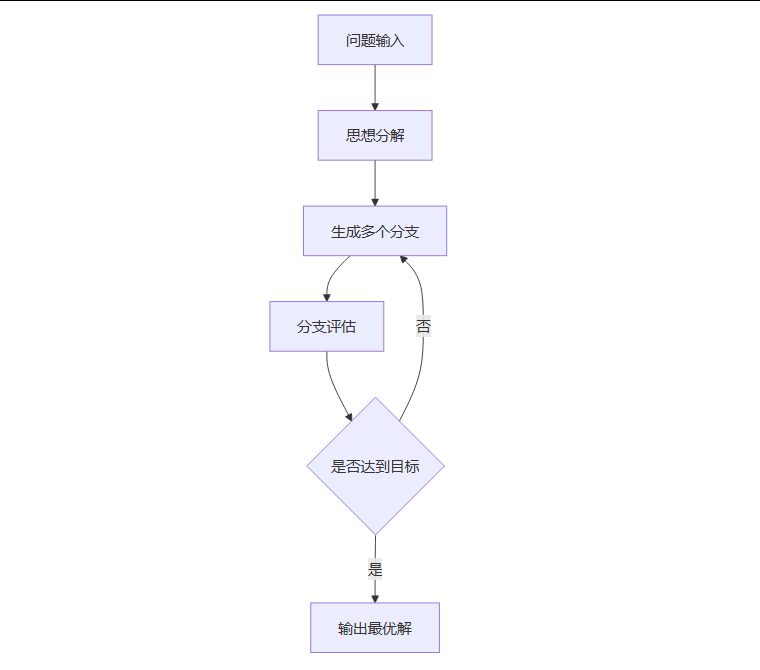
ToT的核心机制,可以概括为“分解-生成-评估”的循环:
思想分解:首先,ToT会将一个复杂的问题,分解成一系列更小、更易于管理的“思想节点”。每个思想节点都代表解决问题的一个中间步骤,它的规模既不能太大导致难以处理,也不能太小以至于失去意义。
思想生成:在每个思想节点上,模型会生成多个可能的“思想”或解决方案。这可以通过两种方式实现:
采样(Sampling):独立生成多个不同的思想。这种方式适用于思想空间非常丰富和多样的场景。
提议(Proposing):顺序生成思想,每个思想都建立在前一个思想的基础上。这种方式有助于保持思想之间的连贯性,并避免生成重复或无效的路径。
思想评估:生成多个思想后,模型需要对这些思想进行评估。它会判断每个分支的潜力,选择最有希望的路径继续探索。这个评估过程通常会结合一些搜索算法,比如广度优先搜索(BFS)或深度优先搜索(DFS),来高效地探索思维树,找到最优解。BFS会优先探索当前层的所有节点,而DFS则会沿着一条路径深入探索到底。
ToT通过主动维护一个思维树,其中每个“思维”都是一个连贯的语言序列,作为解决问题的中间步骤。它指导大模型生成、评估、扩展并在多个解决方案中做出决定,类似于人类在决策前评估各种潜在方案的方式。
3.1.1 🌳 ToT流程图
3.2 🚀 优势:多路径、纠错与鲁棒性
ToT相较于CoT,带来了显著的优势:
多路径并行推理:ToT最大的优势在于它能够同时探索多个推理路径。这意味着即使某个路径在早期出现了错误或死胡同,模型也可以回溯并尝试其他路径,从而避免陷入单一路径的局限。这大大增加了找到最优解的可能性。
支持自主纠错与回溯:在探索过程中,如果某个分支被评估为“死路”或“低效”,模型可以主动放弃该分支,并回溯到之前的节点,选择其他更有潜力的路径。这种自主纠错和回溯能力,提升了模型的鲁棒性和推理深度。
适用于复杂任务:ToT特别适用于那些需要多方案对比、复杂规划或开放性探索的任务,比如逻辑谜题、规划调度、开放性问答、创意写作等。在这些场景中,单一的线性推理往往难以找到最佳答案。
3.3 🚧 局限性:计算与效率的权衡
尽管ToT功能强大,但它也面临一些挑战:
计算复杂度高:由于需要生成和评估多个推理分支,ToT的计算成本通常比CoT更高。随着问题复杂度的增加,思维树的分支数量可能会呈指数级增长,对计算资源的需求也随之增加。因此,需要在推理质量和计算效率之间进行权衡。
无效或冗余路径:在生成多个思想分支时,模型可能会生成一些无效或冗余的路径。这需要有效的启发式剪枝策略来优化搜索过程,避免浪费计算资源。
评估机制的挑战:如何准确有效地评估每个思想分支的潜力,是ToT面临的一个关键挑战。一个不准确的评估机制可能会导致模型错过最优路径,或者在低效路径上浪费过多时间。
3.4 📊 ToT与CoT的对比
为了更清晰地理解ToT和CoT的区别,我们可以通过一个表格来对比它们的关键特性:
四、🔄 Self-Refine:自我批评与优化的“进化循环”
Self-Refine,顾名思义,就是“自我优化”。它是一种非常巧妙的提示词方法,让大语言模型能够通过自我批评和反思,不断提升自己的输出质量。最令人称奇的是,它不需要额外的训练,也不需要借助任何外部工具,仅仅通过精心设计的提示词,就能实现这种“自我进化”。
4.1 ♻️ 核心机制:生成、批评、优化
Self-Refine的核心是一个“自我循环提示法”。在这个循环中,单一的大模型同时扮演了三个角色:生成者、批评者和优化者。
初步生成:首先,模型会根据输入的提示,生成一个初步的输出结果。这就像是完成一份初稿。
自我评估:接下来,模型会“审视”自己生成的这份初稿。它会像一个严格的编辑一样,找出其中的不足之处,比如逻辑漏洞、表达不清晰、格式不规范等。
生成反馈:然后,它会给出具体的改进建议。这个过程是完全由模型自主完成的。
优化输出:模型会根据自己给出的反馈和改进建议,对初步的输出结果进行修改和完善。这个“生成-批评-优化”的循环会一直持续下去,直到模型认为输出结果已经达到了预设的“足够好”的标准,或者达到了预设的迭代次数上限。
4.1.1 📝 Self-Refine的流程表
为了更直观地理解Self-Refine的流程,我们可以将其总结为以下表格:
4.2 🌟 优势:自给自足与显著提升
Self-Refine的独特优势在于其自给自足的设计:
无需额外训练或外部工具:这是Self-Refine最吸引人的地方。它完全依赖于提示工程,不需要对模型进行微调,也不需要调用外部API或工具。这大大降低了其应用门槛和成本。
显著的性能提升:实践证明,Self-Refine能够显著提升模型的性能。在代码优化、对话生成、文本摘要、数学推理等多种任务中,该方法平均能让模型的表现提升约20%,有些任务的提升幅度甚至高达40%。这表明,通过简单的自我反思,模型就能实现质的飞跃。
支持多维度反馈:模型在自我批评时,可以从多个维度进行评估,比如逻辑的严谨性、情感的表达、语言的流畅度、格式的规范性等。这使得最终的输出结果能够更全面地贴合人类的需求。
适合资源受限场景:由于不需要额外的资源投入,Self-Refine特别适合那些资源受限的场景,它能够以最小的成本,最大化模型的输出质量。
4.3 🚧 局限性:基础能力与迭代成本
尽管Self-Refine非常有效,但它也有其局限性:
依赖基础模型能力:Self-Refine的效果,很大程度上取决于基础模型本身的质量。如果模型本身能力较弱,它可能难以生成有效的自我批评反馈,也难以根据反馈进行高质量的优化。一个“不懂”如何改进的模型,是无法通过自我反思来提升的。
迭代过程增加延迟和计算成本:Self-Refine是一个迭代过程,需要模型多次生成、评估和修改。这意味着它会增加模型的响应延迟和计算成本。在对实时性要求极高或计算资源非常有限的场景中,需要仔细权衡。
五、🤝 综合应用与未来趋势
%20拷贝.jpg)
CoT、ToT和Self-Refine这些高级提示词技术,并非孤立存在。它们可以相互结合,形成一个多层次、多路径的推理与优化流程,从而让大模型在处理复杂任务时,展现出前所未有的能力。
5.1 🧩 技术的融合与协同
想象一下这样的场景:
首先,我们可以利用结构化提示词,为整个任务设定一个清晰的框架,明确模型的角色、目标和输出格式。
接着,在解决问题的初期,可以运用CoT进行线性推理,快速生成一个初步的解决方案。
如果问题比较复杂,需要探索多种可能性,那么就可以引入ToT。模型可以在CoT生成的初步方案基础上,进一步探索多个推理分支,评估不同的解决方案,并选择最有潜力的路径。
最后,当模型生成了一个相对完整的答案后,可以启动Self-Refine机制。模型会像一个严谨的审稿人一样,对自己的答案进行自我批评和优化,确保最终输出的质量、准确性和流畅性。
这种多技术融合的策略,能够充分发挥每种技术的优势,弥补其局限,从而让大模型在复杂推理、问题解决和创意生成等领域,展现出更强大的能力。
5.1.1 🔄 综合应用流程图
以下流程图展示了这些技术如何协同工作,共同解决复杂任务:
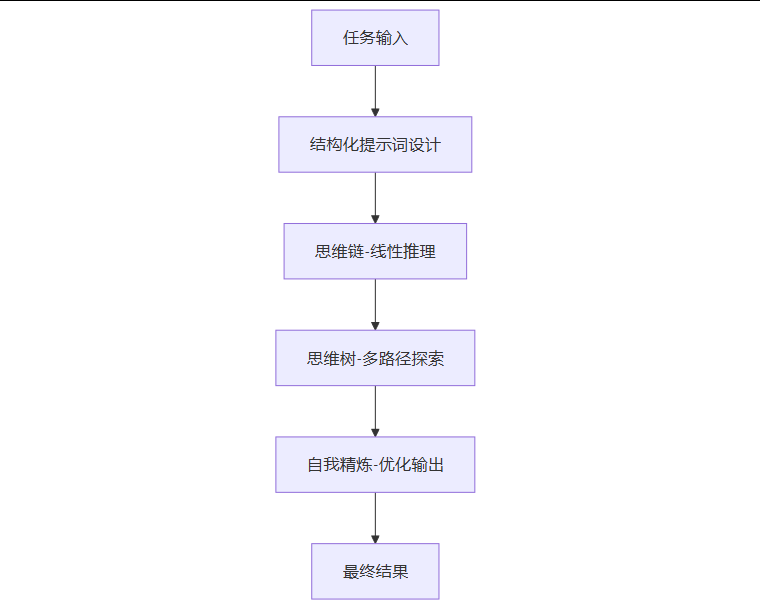
这个流程图清晰地描绘了从任务输入到最终结果的整个过程,其中结构化提示词作为起点,CoT、ToT和Self-Refine则在不同阶段发挥关键作用。
5.2 🚀 未来发展方向
高级提示词工程的未来,充满了无限可能:
自动化提示词生成与优化:目前,提示词工程仍然需要大量的人工经验和技巧。未来,我们可能会看到更多自动化工具的出现,它们能够结合深度学习和强化学习技术,动态地生成、调整和优化提示词的结构与参数,甚至根据任务的反馈,自动学习和改进提示词策略。
多模态与多轮对话协同:随着多模态大模型的兴起,提示词工程也将扩展到文本、图像、音频等多种模态的输入和输出。同时,在多轮对话场景中,如何维持推理的连贯性、上下文的准确性,以及如何让模型在长时间对话中持续优化其思考过程,将是重要的研究方向。像**Thread-of-Thought(思维线程)**这样的新技术,正是在强调多轮对话中持续推理和上下文维护的重要性。
人机协同与可解释性增强:未来的提示词工程,将更加注重人机协同。通过可视化推理链、思维树的分支结构,用户可以更直观地理解模型的思考过程,从而增强对模型的信任,也方便用户进行干预和指导。这种增强的可解释性,对于AI在关键领域的应用至关重要。
总结
高级提示词工程,无疑是解锁大语言模型潜能的“魔法咒语”。通过结构化、引导式提示词的基础,结合Chain-of-Thought的逐步推理、Tree-of-Thought的多路径探索,以及Self-Refine的自我优化,我们能够让大模型从一个强大的工具,蜕变为一个更智能、更可靠的伙伴。这些技术不仅提升了模型在复杂推理、问题解决和创意生成方面的能力,也为AI在医疗、金融、教育、创意等各行各业的深度应用,铺平了道路。随着这些技术的不断进化与融合,我们有理由相信,一个更加智能、高效的未来正在加速到来。
📢💻 【省心锐评】
高级提示词工程,是让大模型从“能用”到“好用”的关键。它不仅是技术,更是艺术,值得每个开发者深入钻研。

评论