.png)
%20%E6%8B%B7%E8%B4%9D-tptw.jpg)

【摘要】OpenAI正以GPT-5为起点,推动AI从即时响应向深度推理与智能体行为转型。通过重塑评估体系、强化学习与编程双轮驱动,并坚守算力核心,其终极目标是构建能自主发现新知的“自动化研究者”,彻底变革科研范式。
引言
科技圈的聚光灯,近来再次牢牢锁定在OpenAI身上。这一次,焦点并非某款惊艳世人的产品发布,而是其内部思想的深刻演变。OpenAI的两位核心人物,首席科学家Jakub Pachocki与首席研究官Mark Chen,通过多次深度对话,系统性地揭开了GPT-5之后的研究蓝图。这幅蓝图的核心,是一个极具雄心的远期目标——构建“自动化研究者”(Automated Researcher)。
这个概念的提出,标志着OpenAI的叙事正在发生根本性转变。它不再仅仅满足于让AI回答问题或生成内容,而是要让AI具备提出问题、设计实验、验证假设、并最终推动科学边界的能力。这不只是一次技术迭代,更是一场关乎科研范式、评估标准、人才培养乃至组织文化的全面革命。从GPT-5对“快思考”与“慢思考”的整合,到评估体系从“刷榜”向“真实发现”的迁移;从强化学习与编程成为实现路径的双轮,到算力依旧是不可动摇的资源基石。OpenAI正在为我们描绘一个AI与人类科学家并肩探索未知的未来。这篇文章将深入剖析这一宏大愿景的各个层面,详解其背后的技术逻辑、组织哲学与未来图景。
一、🧩 GPT-5的哲学重塑:告别分裂,拥抱一体化智能
%20拷贝-vrnp.jpg)
GPT-5的诞生,并非简单的性能提升,它承载着一次底层的设计哲学变革。这次变革的核心,是解决过去模型体系中存在的内在矛盾,实现从分裂到一体化的关键跨越。
1.1、历史的十字路口:即时响应与深度思考的内在矛盾
在GPT-5之前,OpenAI的模型路线图上存在着一种显而易见的分裂。
一方面,是以GPT-2、GPT-3、GPT-4为代表的GPT系列。它们的核心优势在于**“即时响应”**。用户提出问题,模型几乎瞬间就能给出答案。这种模式极大地降低了AI的使用门槛,使其成为日常工作和生活中的高效助手。但它的缺点也同样明显,即为了追求速度,有时会牺牲答案的深度和准确性,尤其是在处理复杂、多步骤的推理问题时,表现往往不尽如人意。
另一方面,是内部探索的o系列(o-models)推理模型。这类模型的设计初衷恰恰相反,它们追求的是深度思考和答案质量。它们可以花费更长的时间,调动更多的计算资源,进行复杂的逻辑链条推演,以期获得更可靠、更精确的结果。这种“慢思考”模式在专业领域表现优异,但其高昂的成本和较长的响应时间,使其难以成为普惠性的日常工具。
这种“快”与“慢”的分离,直接导致了用户体验的割裂和选择的困惑。用户常常需要自行判断,当前的任务究竟是该用一个“聪明的快枪手”,还是一个“深思熟虑的专家”。Mark Chen坦言,这种局面是他们迫切希望改变的。
1.2、一体化架构的诞生:GPT-5如何融合快与慢
GPT-5的核心任务,就是终结这种分裂。它采用了一种**“一体化”的系统架构**,旨在将即时响应的流畅性与深度推理的可靠性无缝地融合在一起。
这个新架构可以被理解为一个智能的“调度中心”。当用户输入一个请求时,系统不再是简单地调用单一模型,而是会首先对任务的复杂性进行预判。
对于简单、直接的请求,系统会路由到类似传统GPT模型的“快速响应”子系统,确保用户获得即时的反馈。
对于复杂、需要多步推理的请求,系统则会自动激活“专家级深思”的推理子系统。这个子系统会调动更多的资源和时间,进行严谨的逻辑推演,然后返回一个高质量的答案。
整个过程对用户是透明的。用户无需再纠结于“该用哪种模式”,因为系统已经默认内置了这种智能判断和调度能力。Mark Chen强调,“我们希望用户默认就能获得推理能力和智能体行为。” 这意味着,未来的AI交互,将不再是简单的“一问一答”,而是根据任务难度,动态调整其“思考深度”的智能过程。
1.3、智能体行为(Agentic Behavior)的崛起:从工具到伙伴
GPT-5的一体化设计,不仅仅是技术架构的升级,它更是通往更高级AI形态——智能体(Agents)——的关键一步。
传统的语言模型,更像一个被动的“信息查询工具”。你问,它答。而一个真正的智能体,应该具备更主动的行为能力。它能够理解一个更宏大的目标,然后自主地将这个目标分解成一系列子任务,并依次执行,最终达成目标。
GPT-5内置的推理能力,正是实现这种智能体行为的基础。当一个模型具备了深度思考和规划能力,它就不再只是一个语言复读机。
例如,用户可以给出一个模糊的目标,比如“帮我规划一次为期五天的东京家庭旅行,需要考虑有老人和小孩”。一个具备智能体行为的模型,会主动进行如下操作:
目标分解:将任务分解为机票查询、酒店预订、行程规划、餐厅推荐、交通安排等子任务。
信息搜集:调用工具或内部知识,查询航班信息、适合家庭入住的酒店、儿童友好的景点和餐厅。
逻辑推理:根据老人的体力、小孩的兴趣,合理安排每日行程,避免过于紧凑。
方案生成:最终输出一份包含多种选项、图文并茂的完整旅行计划。
这种主动规划和执行任务的能力,就是智能体行为的核心。GPT-5将推理能力作为默认配置,正是为了让模型从一个被动的“工具”,向一个主动的“伙伴”或“助理”演进。这是通往“自动化研究者”愿景的逻辑起点。如果一个AI连一次旅行都无法自主规划,那么让它自主进行科学研究就更是天方夜谭。
二、📊 评估体系的范式革命:从“刷分”到“真实发现”
模型能力在飞速提升,但衡量这种提升的“尺子”却开始显得陈旧和乏力。OpenAI敏锐地意识到了这个问题,并开始推动一场评估体系的深刻革命,其核心思想是,放弃在饱和的传统基准上“刷分”,转而追求模型在真实世界中的“发现能力”。
2.1、传统基准的黄昏:边际效益递减的困境
多年以来,AI研究领域习惯于使用一套标准化的评估基准(Benchmarks)来衡量模型的进步,例如MMLU、GSM8K等。这些基准在AI发展的早期阶段起到了重要的指引作用。但现在,情况变了。
OpenAI研究员Yaka Pohotsky指出,许多顶级模型在这些基准上的得分已经非常高,接近饱和。从96%提升到98%的边际效益极为有限。这种提升,很多时候只是模型“应试技巧”的增强,而未必代表其通用智能或真实世界问题解决能力的实质性飞跃。
更严重的是,传统的“预训练-泛化评估”模式,难以适应新方法带来的能力变化。特别是强化学习(RL)的应用,使得模型可以在特定领域内通过大量试错,展现出超凡的专业能力。但这种“专才”式的表现,不一定能很好地泛化到其他领域。一个在代码生成上表现优异的模型,可能在数学推理上依然平庸。
Yaka Pohotsky坦言,“我们确实认为自己正处于一种优秀评估方法的‘赤字’状态。” 继续沿用旧的“尺子”,就像用小学生的量角器去测量天体物理学的参数,不仅不精确,甚至会产生误导。AI社区需要一套全新的、更能反映模型真实价值的评估范式。
2.2、新评估的黎明:三大支柱的崛起
为了摆脱“分数陷阱”,OpenAI将未来的评估重心转向了三个更贴近真实世界的方向。这三大支柱共同构成了一个新的评估框架,旨在衡量模型发现新知识、创造新价值的实际本领。
2.2.1、支柱一:可验证的竞赛领域
第一个支柱,是那些规则明确、结果可被客观验证的顶级人类智力竞赛。这就像是AI的“奥林匹克”。
国际数学奥林匹克(IMO):这是衡量机器逻辑推理和抽象思维能力的终极试炼场。解决一道IMO级别的难题,需要深刻的洞察力、创造性的解题思路和严谨的证明过程。模型在这上面的任何一点进步,都标志着其“原始智能”的真实提升。
编程竞赛(如AtCoder、Codeforces):这类竞赛考验的不仅是算法知识,更是将复杂问题转化为高效、正确代码的工程实现能力。模型在编程竞赛中的表现,直接反映了它作为生产力工具的潜力。
选择这些领域作为评估标准,是因为它们无法被“死记硬背”。每一道题都是全新的,考验的是模型真正的问题解决能力,而非知识储备。
2.2.2、支柱二:具有经济价值的真实任务
第二个支柱,是衡量模型在真实工作场景中创造经济价值的能力。学术考试和智力竞赛固然重要,但它们与普通人的日常工作仍有距离。
为此,OpenAI推出了像GDPval这样的新评估基准。GDPval专注于那些贴近真实工作、具有明确经济价值的任务。这些任务可能包括:
撰写一份专业的市场分析报告。
为初创公司设计一套可行的商业计划。
担任客服角色,高效解决用户的复杂问题。
自动化完成繁琐的数据清洗和整理工作。
GDPval的目标,是补齐学术考试与真实生产力之间的评估缺口。一个模型在GDPval上表现越好,意味着它越能作为“数字员工”,在经济活动中创造实实在在的价值。
2.2.3、支柱三:有意义的科学推动
第三个,也是最宏大、最核心的支柱,是衡量模型能否在科学研究上做出有意义的真实发现和推动。这直接指向了“自动化研究者”的终极目标。
这里的“推动”不是指写一篇格式正确的论文综述,而是指:
在海量实验数据中发现新的模式或关联。
提出一个前人未曾想过的新颖科学假设。
设计一个能够验证该假设的关键实验。
甚至,在数学或理论物理领域,给出一个新的定理或证明。
这要求模型具备极高的创造力、长时程推理能力和对复杂领域的深刻理解。这无疑是三者中最难的,但也是最有价值的。
2.3、从“更高分”到“更多发现”的叙事转变
这三大支柱的建立,标志着OpenAI的研究叙事正在发生根本性的转变。
这个转变意义深远。它将引导AI研究从一场“军备竞赛”式的刷分游戏,回归到服务于人类知识拓展和经济社会发展的本质目标上来。未来的AI,其价值将不再由排行榜上的一个数字定义,而是由它为世界带来的真实改变来衡量。
三、🚀 技术双轮驱动:通往“自动化研究者”之路
%20拷贝-rikf.jpg)
宏大的愿景和全新的评估体系,需要坚实的技术路径来支撑。在OpenAI看来,强化学习(RL)和编程,正是驱动AI从“问题解答者”进化为“自动化研究者”的两个核心引擎。它们如同一对强劲的齿轮,相互啮合,共同推动着AI能力的飞轮加速旋转。
3.1、强化学习(RL):在语言世界中开辟无限试验场
强化学习本身并非新技术,但它与现代大规模预训练模型的结合,却爆发出惊人的能量。Yaka Pohotsky解释说,这种结合,为AI研究提供了一个近乎无限的试验场。
在过去,应用强化学习的一大难题是构建环境(Environment)。无论是训练AI下围棋(AlphaGo),还是玩星际争霸,研究人员都需要耗费巨大精力去搭建一个高度逼真的模拟环境。这个过程成本高昂且缺乏通用性。
但大规模预日志模型的出现,彻底改变了游戏规则。Pohotsky认为,“预训练为我们提供了一个极其稳健、丰富的环境,即对人类语言的理解。” 换句话说,人类语言本身,以及由语言所描述的整个世界,构成了一个现成的、包罗万象的RL环境。
在这个环境中:
状态(State):可以是当前的对话历史、一篇待修改的文档、一段未完成的代码,或是任何可以用语言描述的情境。
动作(Action):是模型生成的下一段文本。这个动作可以是一个回答、一句代码、一个指令,或是一个追问。
奖励(Reward):可以来自多方面。它可以是人类的反馈(这个回答好不好),可以是代码编译是否通过,可以是数学题的答案是否正确,甚至可以是后续与模型交互的流畅度。
这种“RL on Language Model”的范式,解决了过去环境构建的根本难题。研究人员不再需要为每个任务都手动搭建一个模拟器。他们可以在语言这个通用环境中,设定各种目标(Goals),让模型通过不断的试错和学习,去探索达成这些目标的最佳路径。这为训练模型进行长时程规划、复杂任务分解等高级智能行为,打开了前所未有的可能性。
3.2、编程的再定义:从写代码到“氛围编程”
如果说强化学习提供了方法论,那么编程领域则提供了最理想的实践场和最强大的工具。编程的本质,就是将一个模糊的人类意图,转化为精确、可执行的机器指令。这个过程,与AI的推理和规划过程高度同构。
OpenAI在编程领域的探索,早已超越了简单的代码补全。Mark Chen透露,新版GPT-5 Codex的目标,是将推理模型的“原始智能”,转化为真实世界编程中的实用工具。这不仅关乎代码的功能性,更关注其**“软性”层面**。
3.2.1、GPT-5 Codex的“软性”目标
新一代编程助手关注的,是那些传统静态分析工具难以触及的维度:
代码风格:生成的代码是否符合团队的编码规范?可读性如何?
模型的主动性与懒惰程度:模型是仅仅完成你要求的最小任务,还是会主动思考并提出更好的实现方式?它会不会“偷懒”,用一些不优雅但能跑通的“脏代码”?
代码重构与维护:模型能否理解一个庞大的、包含数十个文件的旧项目,并安全、高效地进行重构?
Yaka Pohotsky,一位前编程竞赛选手,分享了他的亲身经历。他曾非常抗拒使用AI工具,认为这会削弱自己的能力。但GPT-5的最新能力让他彻底改变了看法。他亲眼见证了模型在短短15分钟内,完美地完成了一个涉及30个文件的复杂代码重构。这种效率是纯靠人力难以想象的。
3.2.2、“氛围研究”的未来图景
这种人机协作的新模式,正在催生一种全新的编程文化。Mark Chen将其称为**“氛围编程”(vibe coding)**。对于年轻一代的程序员来说,不借助AI进行编码,反而是一件奇怪的事情。他们习惯于给出一个高层次的“氛围”或“感觉”,然后由AI来填充具体的实现细节。
这种趋势,可能很快就会从编程领域,延伸到更广泛的科学研究领域,演变为**“氛围研究”(vibe researching)**。
下面的流程图展示了这一演化路径:
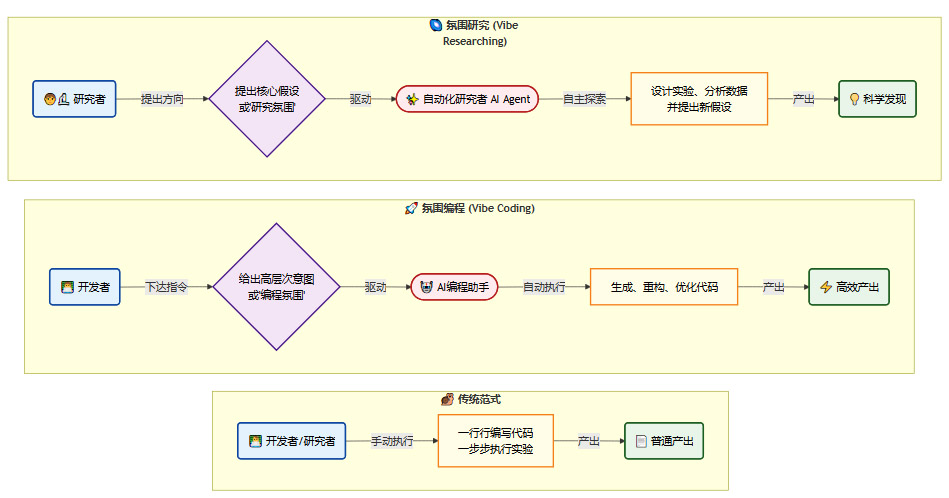
在“氛围研究”的模式下,人类科学家的角色将发生转变。他们不再是繁琐实验操作的执行者,而是更高层次的思想者、提问者和方向把控者。他们负责提出最关键、最富创造性的科学问题(即研究的“氛围”),而AI则作为强大的“自动化研究者”,负责将这些思想火花转化为严谨的实验方案、海量的数据分析和最终的科学洞见。
3.3、双轮如何协同:一个具体案例的想象
让我们想象一个药物研发的场景,看看强化学习和编程这两个轮子如何协同工作,驱动“自动化研究者”:
人类科学家提出“氛围”:研究一种能够抑制特定癌细胞蛋白活性的新药。
AI(RL环境)设定目标:目标是找到一个分子结构,它能与目标蛋白强力结合,同时毒副作用最小。
AI(编程能力)生成工具:AI首先编写一系列Python脚本,用于调用分子动力学模拟软件、对接化学数据库、以及分析模拟结果。
AI(RL试错)开始探索:
动作:AI生成一个候选分子结构(Action)。
执行:AI调用自己编写的脚本,对该分子进行模拟(Execution via Code)。
反馈:模拟结果(结合强度、毒性预测)作为奖励信号(Reward)。
循环优化:AI根据奖励信号,不断调整其生成分子结构的策略,进行成千上万次快速迭代。这个过程远超人力所能及的范围。
最终产出:AI最终提出几个最有潜力的候选分子结构,并附上完整的模拟数据和分析报告,供人类科学家进行最终决策和湿实验验证。
在这个过程中,强化学习提供了探索未知化学空间的强大方法,而编程能力则为这种探索提供了具体、高效的执行工具。二者结合,构成了“自动化研究者”进行科学发现的核心技术回路。
四、🏛️ 组织与文化:为“硬核”研究打造的“保护区”
一个宏大目标的实现,离不开独特的组织文化和人才理念。OpenAI深知,要攀登“自动化研究者”这座险峰,必须构建一个能够吸引、激励并保护顶尖人才的环境。这种环境的核心,是对基础研究的坚定信念和对挑战难题的执着追求。
4.1、人才观:寻找曾在任何领域解决过难题的人
OpenAI在招募人才时,有着非常明确的画像。他们寻找的,是那些曾在任何领域解决过难题的人。Yaka Pohotsky表示,这些人的背景可能五花八门,完全不局限于计算机科学。
物理学家:他们习惯于处理高度抽象的模型和复杂的数学工具。
理论计算机科学家:他们擅长严谨的逻辑推演和算法复杂度分析。
金融量化分析师:他们精通在充满噪声的数据中寻找信号,并构建预测模型。
数学或编程竞赛的顶尖选手:他们拥有在巨大压力下快速解决全新问题的实战经验。
这些不同背景的人才,共同具备一些OpenAI极为看重的核心品质。
Yaka Pohotsky认为,“坚持”是优秀研究员最核心的特质。研究之路充满了不确定性,绝大多数尝试都会以失败告终。只有那些能够清晰地提出假设,从失败中汲取教训,并持续迭代的人,才有可能最终触及科学的边界。
Mark Chen则补充了**“经验”**的重要性。他认为,经验能帮助研究员培养一种宝贵的“品味”(Taste),即判断一个研究课题是否值得投入。一个好的研究课题,应该处在一个微妙的平衡点上——既不太难,以至于毫无进展;也不太简单,以至于缺乏价值。这种品味,需要通过大量阅读优秀论文、与顶尖同事频繁交流来慢慢培养。
4.2、使命驱动:基础研究的“护城河”
在商业竞争日益激烈的AI行业,许多公司被迫将研发重心转向短期可见的产品迭代。而Mark Chen认为,OpenAI的一大优势,在于其始终坚守的**“基础研究”使命感**。
这种使命感,像一条“护城河”,保护着公司的核心研究团队。它激励着团队成员去探索真正前沿、可能改变未来的技术,而不是简单地模仿竞争对手或满足于眼前的产品需求。
为了将这种使命落到实处,OpenAI建立了一套机制,来保护其基础研究团队。
设立“研究保护区”:公司努力确保核心研究人员不受短期产品方向和需求的干扰。他们被给予充足的时间和空间,去思考和探索那些可能需要一到两年甚至更长时间才能看到结果的重大问题。
容忍多元化探索:在通往“自动化研究者”的漫长道路上,具体的路径尚不清晰。因此,公司内部鼓励多个研究方向并存,比如扩散模型、代码推理、强化学习理论等。这些看似分散的探索,被认为在长远来看,最终都会汇集到核心目标上。Yaka Pohotsky坦言,“虽然长期目标清晰,但具体的技术路径仍需探索和学习。”
鼓励挑战“硬骨头”:Yaka Pohotsky强调,选择一个你真正关心且认为重要的问题至关重要。他所敬佩的许多研究者,都以勇于挑战那些公认的“硬骨头”问题而著称。他们会不断追问:“实现这个目标的最大障碍是什么?”然后将全部精力投入到攻克这个核心障碍上。
这种对基础研究的制度性保护和文化性鼓励,使得OpenAI能够持续吸引那些渴望做出颠覆性创新而非渐进式优化的顶尖人才,为实现“自动化研究者”的宏伟蓝图储备了最宝贵的智力资本。
五、🔋 资源与瓶颈:算力,依然是那个绕不开的话题
%20拷贝-dpod.jpg)
在AI的世界里,算法、数据和算力被誉为“三驾马车”。尽管近年来关于数据重要性的讨论不绝于耳,甚至有观点认为AI领域将从算力约束转向数据约束,但OpenAI的核心团队对此给出了一个毫不含糊的、斩钉截铁的回答。
当被问及如果拥有无限资源,会投向哪里时,Jakub Pachocki和Mark Chen异口同声地选择了——“计算”(Compute)。
Jakub Pachocki明确表示,他不认可“AI领域将从算力约束转向数据约束”的观点。基于他长期的观察,结论非常直接:“我们能做多少事,就是计算力决定的”。这句话简洁而有力地道出了前沿AI研究的残酷现实。模型的规模、训练的深度、探索的广度,几乎所有关键变量的上限,都由可用的计算资源来划定。
Mark Chen的回答则更具画面感:“任何说这话(指算力不再是瓶颈)的人,都应该来我的岗位上待一个周末。没有人会说‘我有我需要的所有计算力’。” 这句略带调侃的话,生动地揭示了身处AI研究第一线的资源焦虑。对于他们来说,算力不是一个抽象的数字,而是决定下一个实验能否启动、下一个模型能否训练、下一个想法能否验证的命脉。
在他们看来,算力的约束,并非一个短期问题,而是AI前沿研究中一个长期存在的核心瓶颈。无论是训练更大规模的基础模型,还是在强化学习中进行海量的环境交互,抑或是支撑“自动化研究者”进行复杂的科学模拟,每一个环节都是计算资源的“吞金巨兽”。
可以预见,在通往通用人工智能(AGI)和“自动化研究者”的道路上,对算力的争夺将愈发激烈。这不仅是技术公司之间的竞争,更可能成为决定国家和地区科技竞争力的关键因素。OpenAI对此的清醒认知,也解释了其在构建和优化大规模计算集群上不遗余力的投入。算力,就是他们探索未知宇宙的望远镜口径,口径越大,能看到的宇宙就越深远。
总结
OpenAI通过其核心团队的系统性阐述,为我们描绘了一幅清晰而宏大的后GPT-5时代路线图。这不再是一个关于模型跑分和参数数量的线性故事,而是一个关于科研范式革命的立体蓝图。
从GPT-5融合快慢思考的一体化设计,到评估体系从追求分数转向奖励真实发现;从确立强化学习与编程为技术双轮,到坚守基础研究的组织文化和对算力瓶颈的清醒认知,所有线索最终都指向一个共同的终点——“自动化研究者”。
这个终极愿景,意味着AI将不再仅仅是人类知识的延伸和放大器,而可能成为一个独立的知识发现引擎。它预示着一个“氛围研究”时代的到来,人类科学家的角色将升华为提出最具洞察力的“问题”,而AI则负责执行繁复的“求解”过程。这无疑将极大地加速科学探索的步伐,甚至可能在物理、生物、化学等基础科学领域催生出我们今天难以想象的突破。
当然,前路依然漫长且充满未知。如何构建真正鲁棒的强化学习系统,如何让AI具备真正的创造性而非简单的模式组合,如何确保算力资源的可持续增长,这些都是摆在OpenAI乃至整个AI社区面前的巨大挑战。但无论如何,OpenAI已经明确了它的航向。它正驾驶着AI这艘巨轮,驶离“即时响应”的浅滩,向着“自主发现”的深海,全速前进。
📢💻 【省心锐评】
OpenAI的棋局已然明朗:以GPT-5为车马,算力为粮草,直指“自动化研究”这一帅帐。这不仅是技术的跃迁,更是对科研生产关系的重塑。

评论