.png)


【摘要】RAG(检索增强生成)正成为企业智能化转型的核心技术。本文系统梳理RAG缓解幻觉、降本增效、提升可信度等优势,详解企业部署RAG的选型与方法,深度剖析关键挑战与未来趋势,助力企业高效落地RAG,驱动数字化升级。
引言
在人工智能技术飞速发展的今天,企业对大模型的应用需求日益增长。然而,传统大模型在实际落地过程中,常常面临“幻觉”问题、训练与推理成本高昂、知识更新滞后等诸多挑战。RAG(Retrieval-Augmented Generation,检索增强生成)技术的出现,为企业智能化转型带来了全新解法。数据显示,已有65%的企业在实际业务中采用RAG方案,以期降本增效、提升系统可信度,并实现知识的灵活管理。本文将从RAG的原理、优势、部署选型、关键挑战及未来趋势等多个维度,系统梳理RAG在企业级应用中的深度价值与落地方法,助力企业在数字化浪潮中把握先机。
一、RAG为何成为企业刚需
%20拷贝-hhcj.jpg)
1.1 缓解幻觉问题,提升可信度
1.1.1 原理与机制
RAG的核心在于将生成式大模型与外部知识库深度融合。在用户提问后,系统会首先检索权威知识库,将相关事实作为生成内容的依据。通过输入层过滤、生成层注入检索内容、输出层多文档交叉验证的三重纠偏机制,RAG显著降低了大模型“幻觉”——即生成虚假或不准确内容的概率。
1.1.2 效果数据
据Google DeepMind等权威研究,RAG在医疗问答场景中可将幻觉率从34.7%降至8.2%。这一数据不仅体现了RAG在高风险领域的可靠性,也为企业在金融、法律等专业场景的应用提供了坚实基础。
1.1.3 可解释性与信任度
RAG输出通常附带参考文献、置信度提示,便于溯源和人工复核。企业用户可直接追溯答案来源,增强了系统的可解释性和信任度。这一特性对于合规要求高、决策风险大的行业尤为重要。
1.2 降本增效,提升生产力
1.2.1 训练与推理成本
RAG通过外部知识检索,极大减少了对大模型全量微调的依赖。企业只需维护和更新知识库,无需频繁训练模型,训练成本降低30%以上,推理成本可降至传统方案的0.1%~10%。
1.2.2 效率提升
RAG系统的信息检索准确率提升80%,检索耗时缩短70%,员工生产力提升40%。实际案例显示,企业文档检索响应时间从5秒降至1秒,问题解决率提升至85%;客服机器人人工工作量减少30%,满意度达85%。
1.2.3 灵活性与时效性
知识更新只需维护知识库,无需频繁训练模型,极大提升了系统的灵活性和知识时效性,能够快速适应业务变化和新知识的引入。
1.3 适用场景广泛
1.3.1 智能问答/客服
RAG可大幅提升客户服务效率,减少人工干预,提升客户满意度。
1.3.2 医疗、法律、金融等专业领域
基于权威知识库,RAG显著降低幻觉风险,提升决策准确性,满足高合规、高风险行业的需求。
1.3.3 企业知识管理与自动化报告
RAG实现知识资产的高效管理和自动化内容生成,助力企业知识沉淀与创新。
1.3.4 多模态与多语种支持
RAG正逐步支持文本、图像、表格等多模态数据,适应全球化和复杂业务需求,拓展了应用边界。
1.4 弥补大模型数据时效性不足,提升实时性与前瞻性
1.4.1 大模型数据时效性滞后问题
当前主流大模型在训练时,往往依赖于大规模的历史数据集。由于数据清洗、标注、训练、评测等流程复杂,模型训练周期长,导致其知识库内容普遍滞后于现实世界。以GPT-4、ERNIE等为例,模型知识截止点通常落后当前时间至少6个月,甚至更长。这种时效性滞后,直接影响了模型在新闻、金融、科技、政策等对实时性要求极高场景下的应用效果。
1.4.2 RAG基于互联网检索的优势
RAG通过集成互联网实时检索能力,能够动态获取最新信息,极大弥补了大模型素材资源的不足。尤其在以下场景中,RAG展现出独特价值:
新闻与时事解读:用户可通过RAG系统获取最新新闻报道、政策解读,避免因模型知识滞后导致的误判。
金融市场分析:RAG可实时检索最新财经数据、市场动态,为投资决策提供及时参考。
科技与产品更新:技术迭代迅速,RAG可帮助企业和用户第一时间掌握行业新动态。
法律法规合规:法律条文、政策频繁更新,RAG可确保输出内容与最新法规保持一致。
1.4.3 互联网RAG部署与运维要点
在企业实际部署基于互联网的RAG系统时,需重点关注以下方面:
数据源选择与过滤:优选权威、可信的新闻、数据、政策等信息源,结合内容过滤机制,防止虚假、低质信息混入知识库。
实时性与缓存机制:合理设置检索频率与缓存策略,兼顾信息时效性与系统响应速度,避免频繁访问导致的性能瓶颈。
合规与版权保护:遵循数据采集与使用的法律法规,尊重内容版权,防止侵权风险。
多渠道融合:支持多种检索渠道(如主流搜索引擎、专业数据库、开放API等),提升信息覆盖面和多样性。
自动化知识库更新:通过定时任务、增量更新等方式,自动将最新检索内容纳入知识库,保持系统知识的鲜活性。
1.4.4 互联网RAG的技术流程示意
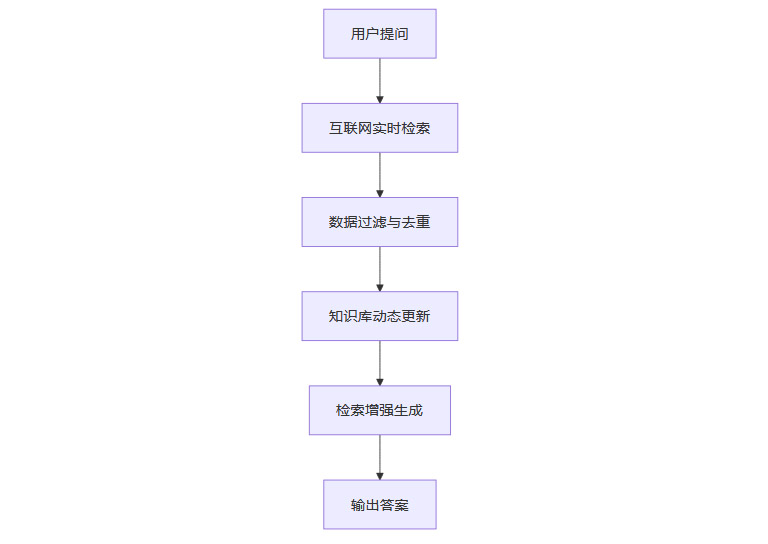
1.4.5 典型应用案例
某金融机构通过RAG集成主流财经网站、证券交易所API,实现对全球市场动态的分钟级追踪,极大提升了投研团队的决策效率。
某法律咨询平台利用RAG自动检索各地最新政策法规,确保法律咨询服务始终与最新法规同步,客户满意度显著提升。
1.4.6 互联网RAG的挑战与应对
信息噪声与虚假内容:需引入多层次内容过滤、可信度评估、人工审核等机制,确保输出内容的权威性与准确性。
检索速度与系统负载:通过分布式检索、智能缓存、异步处理等技术,提升系统吞吐能力。
数据安全与隐私保护:对敏感信息进行脱敏处理,严格控制数据访问权限,防止数据泄露。
二、企业部署RAG的选型与方法
2.1 技术架构与核心流程
2.1.1 基本流程
RAG系统的核心流程如下:

数据准备:包括数据清洗、分块、向量化、入库等步骤。
用户提问:用户通过前端界面或API发起问题。
检索召回:系统从知识库中检索相关内容。
生成增强:将检索结果与用户问题一同输入大模型。
LLM生成答案:大模型基于检索内容生成最终答案。
2.1.2 分块策略
分块策略直接影响检索效果和上下文完整性。常见分块方式包括:
语义分块和递归分块在实际落地中效果较好,能保留上下文完整性,需结合业务场景测试。
2.2 数据存储与检索方案
2.2.1 向量数据库
向量数据库如Milvus、Pinecone、Qdrant,适合大规模非结构化内容的语义检索,支持弹性扩展和高效相似性搜索。
2.2.2 知识图谱/图数据库
知识图谱和图数据库适合复杂关系和多跳推理场景,提升上下文理解和多实体关联能力。
2.2.3 混合架构
企业级RAG推荐向量数据库+知识图谱协同,兼顾高效检索与复杂语义推理,满足多样化业务需求。
2.3 嵌入模型与检索优化
2.3.1 嵌入模型选择
企业需根据业务场景选择通用或领域专用模型,如OpenAI、BGE、Sentence-BERT、nomic-embed-text等。中文领域可选BAAI/bge-large-zh-v1.5,确保语义理解的准确性。
2.3.2 检索优化
采用混合检索(向量+关键词+稀疏向量)、重排序(如BGE Reranker)、多轮检索等方式,提升召回率和相关性,确保检索结果的高质量。
2.4 框架与工具选型
2.4.1 开源框架
LangChain:灵活链式结构,适合快速原型开发。
Haystack:多模态支持,适合生产级应用。
DSPy:声明式编程,自动优化检索与生成流程。
Dify:可视化工作流,便于业务人员参与。
ChatWiki、AnythingLLM、Cherry Studio、RAGFlow:支持多级权限、企业级管理等功能。
2.4.2 企业级产品
如LazyGraphRAG(微软),索引成本仅为GraphRAG的0.1%,适合低成本轻量化部署,助力企业快速落地RAG方案。
2.4.3 选型建议
企业应结合自身规模、数据敏感性、业务复杂度、团队技术能力等因素,科学评估并选择合适的框架和部署方式。
2.5 安全与合规
2.5.1 数据安全
优先本地化部署敏感数据,采用端到端加密、基于角色的访问控制(RBAC)、常态化安全审计等措施,确保数据安全。
2.5.2 合规性
系统需符合GDPR、HIPAA等数据保护法规,尤其在金融、医疗等高敏感行业,保障合规运营。
2.6 部署与运维建议
2.6.1 小步快跑,迭代验证
建议企业先小范围试点,验证系统效能后再逐步推广,降低风险。
2.6.2 与业务深度集成
确保RAG系统与现有工作流、数据库、API等无缝对接,避免“信息孤岛”,提升整体业务协同效率。
2.6.3 持续优化与反馈
引入用户反馈、自动fact-check、人工审核等机制,持续提升系统准确性和用户体验。
2.7 互联网RAG的企业部署实践
2.7.1 部署架构建议
企业在部署互联网RAG时,推荐采用分层架构:
2.7.2 关键运维措施
监控与告警:对数据采集、检索、生成等关键环节设置实时监控与异常告警,保障系统稳定运行。
内容审核与溯源:对高风险内容引入人工审核,输出答案附带溯源链接,便于用户自查。
知识库健康管理:定期清理过时、冗余、低质内容,保持知识库高质量。
用户反馈闭环:收集用户对答案的反馈,自动优化检索与生成策略,持续提升系统表现。
2.7.3 互联网RAG与本地知识库的协同
在实际应用中,企业可将互联网RAG与本地知识库协同使用:
本地知识库:存储企业内部文档、专有数据,保障数据安全与业务专属性。
互联网RAG:补充外部最新信息,提升系统的时效性与广度。
智能融合:通过检索优先级、内容融合算法,实现本地与互联网知识的智能调度与整合。
三、关键挑战与应对策略
%20拷贝-stcg.jpg)
3.1 幻觉残留风险
即便RAG大幅降低了幻觉概率,但当检索库含有错误数据或信息不完整时,幻觉仍可能发生。企业应定期清洗知识库,自动化事实核查,并集成Self-RAG等技术自动检测幻觉并回退重检索,确保输出内容的准确性。
3.2 性能瓶颈
随着数据量和用户量的增长,RAG系统可能面临检索和生成的性能瓶颈。可通过索引优化(如增量更新、倒排索引+哈希索引)、模型压缩(剪枝/量化)、硬件加速(GPU/TPU)等手段提升系统性能,保障高并发场景下的稳定运行。
3.3 安全与隐私
数据安全与隐私保护是企业级RAG部署的底线。应实施RBAC、端到端加密,金融/医疗等行业优先本地化部署,防止数据泄露和合规风险。
3.4 互联网RAG的挑战与应对
信息噪声与虚假内容:需引入多层次内容过滤、可信度评估、人工审核等机制,确保输出内容的权威性与准确性。
检索速度与系统负载:通过分布式检索、智能缓存、异步处理等技术,提升系统吞吐能力。
数据安全与隐私保护:对敏感信息进行脱敏处理,严格控制数据访问权限,防止数据泄露。
四、未来趋势
%20拷贝-otmk.jpg)
4.1 多模态RAG
RAG正逐步支持文本、图像、表格等多种数据类型,适应更复杂的企业场景,拓展了应用边界。
4.2 低成本高性能RAG
如微软LazyGraphRAG等新技术,将RAG成本降至传统方案的0.1%,推动大规模普及,助力更多企业实现智能化升级。
4.3 模块化与自动化优化
RAG系统将更智能地动态选择检索策略、自动纠错和自我优化,提升系统的自适应能力和运维效率。
4.4 智能体生态与全球化
RAG将与多智能体系统深度融合,支持多语种和全球化运营,助力企业在全球市场中实现智能化协同。
4.5 互联网RAG的行业影响力
互联网RAG的普及,正在重塑企业知识管理与智能服务的格局:
提升企业决策速度:实时获取最新信息,助力企业快速响应市场变化。
增强创新能力:动态引入外部知识,激发企业创新活力。
优化客户体验:为用户提供更权威、及时、个性化的智能服务。
推动行业智能化升级:加速各行业数字化、智能化转型进程。
结论
RAG已成为企业智能化转型的核心技术。凭借其缓解幻觉、降本增效、灵活适配和高安全性的优势,RAG正广泛应用于各类行业,助力企业实现知识管理、智能问答、自动化报告等多元场景的创新突破。企业在部署RAG时,应科学选型、分步实施,注重数据治理与安全合规,并持续优化系统性能和用户体验。未来,随着多模态、低成本和智能化趋势的推进,RAG将在企业数字化升级中发挥更大价值,成为推动企业高质量发展的关键引擎。
📢💻 【省心锐评】
“RAG不是万能药,但拒绝它的企业将在AI竞赛中失血。核心在构建‘活知识库’——持续流动、精准过滤、安全可控。”

评论