.png)
%20%E6%8B%B7%E8%B4%9D.jpg)

【摘要】构建有效的AI模型评估体系,关键在于采用“业务-产品-技术”三层框架,确保技术指标服务于最终商业价值。文章详述了离线与在线评估的闭环实践,并深入探讨了不同AI任务的核心指标与权衡策略。
引言
评估一位顶尖足球前锋,如果只看他进了多少球,显然是不够的。一个只顾自己进球却导致球队输球的前锋,其价值必然存疑。更全面的评估需要考察他为队友创造了多少机会、控球能力如何,乃至他是否提升了全队的士气。而最终极的标准,是他能否帮助球队赢得冠军、吸引更多球迷和商业赞助。
这个比喻揭示了设计AI模型效果评估体系的核心,任何单点的技术高性能,都必须最终服务于更高维度的目标。一个只在实验室里准确率高达99%,上线后却无人使用或无法创造商业价值的模型,是失败的。
所以,构建一个分层、闭环、且与业务紧密相连的评估指标体系,是AI产品成功的生命线。这需要我们秉持**“以终为始”**的理念,从最终的商业价值出发,反向推导至底层的技术实现。
🎯 一、评估体系的核心理念与分层框架
%20拷贝.jpg)
科学的模型效果评估体系,其核心是确保技术指标最终服务于产品体验和业务价值。业界最常用且行之有效的结构,便是“三层金字塔”分层框架。它自上而下进行设计,又自下而上进行验证,形成了一个逻辑严密的闭环。
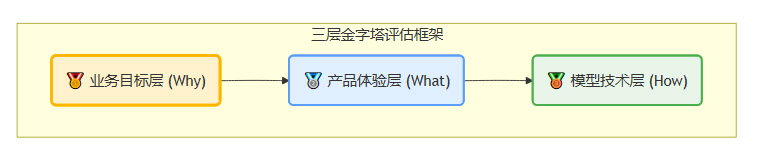
1.1 业务目标层(Why)
这一层是整个评估体系的顶端和锚点,它回答了“AI产品为何存在”的根本问题。在项目启动之初,就必须与业务方紧密合作,将模糊的业务痛点转化为可量化的北极星指标。
核心作用:定义“成功”的最终标准,衡量AI产品对企业核心价值的贡献。
常见指标:
收入增长
成本降低
利润提升
用户生命周期价值(LTV)
转化率(Conversion Rate)
用户留存率(Retention Rate)
投资回报率(ROI)
例如,对于一个智能推荐系统,其北极星指标不应是“模型准确率”,而应是**“用户总消费额(GMV)”或“广告点击总收入”。对于一个智能客服机器人,则是“人工客服成本降低率”或“客户问题首次解决率”**。所有下层指标的设计与优化,都必须服务于这一顶层目标,这能有效避免陷入“技术自嗨”的误区。
1.2 产品体验层(What)
这一层是连接宏观业务与微观技术的桥梁。它负责将顶层的业务目标,拆解为一系列可被直接度量的用户行为和产品体验指标。
核心作用:量化AI功能对用户行为和产品体验的直接影响。
常见指标:
点击率(CTR)
用户满意度(CSAT)
任务完成率
用户使用时长
会话深度
A/B测试中的用户行为差异
继续以推荐系统为例,为了实现“提升GMV”的业务目标,产品经理需要关注**“推荐内容的点击率”、“用户浏览深度”、“商品加购率”**等一系列产品指标。
但这里需要特别警惕单一指标可能带来的误导。比如,一个推荐系统可能因为推荐了大量“标题党”内容而获得了极高的点击率,但用户点击后发现内容质量低下,会立刻退出,反而损害了长期用户体验和信任。因此,设计复合指标就显得尤为重要,例如定义一个**“有效点击率”**,即用户点击后停留超过特定时长(如15秒)的点击才被计为有效。这样能更真实地反映用户对推荐内容的认可度。
1.3 模型技术层(How)
这是金字塔的基石,也是算法工程师和数据科学家最常打交道的层面。它专注于在算法层面,衡量模型本身的技术性能。这些指标通常在模型开发和迭代阶段,基于固定的离线数据集进行评估。
核心作用:在开发阶段快速、低成本地评估模型在特定算法任务上的表现。
常见指标:根据模型任务类型而定,例如分类任务的准确率、精确率、召回率,回归任务的均方根误差,以及生成任务的BLEU、ROUGE等。
技术指标是构建高性能模型的基础。但必须清醒地认识到,技术指标的提升不应是最终目的。一个在离线测试集上F1分数高达0.99的模型,如果不能在线上带来产品指标或业务指标的改善,那么这次优化就是无效的。技术指标的价值,在于它们通常与上层指标存在一定的正相关性,可以作为优化方向的代理(Proxy)。
⚙️ 二、核心技术指标详解(按任务类型)
选择正确的模型技术指标,是评估工作的第一步。不同的AI任务,其评估的侧重点和方法论也大相径庭。
2.1 分类模型
分类模型是最常见的AI任务之一,其评估指标体系也最为成熟和完善。评估分类模型,通常始于一个混淆矩阵(Confusion Matrix),它是一切指标的计算基础。
基于混淆矩阵,我们可以衍生出一系列核心评估指标。
2.2 回归模型
回归模型用于预测一个连续值,例如房价、销量、温度等。其评估指标主要衡量预测值与真实值之间的差距。
2.3 生成式AI/NLP模型
生成式AI的评估是当前最具挑战性的领域之一,因为它涉及语义、逻辑、创造性乃至事实性等复杂维度,难以用简单的数学公式来概括。
2.3.1 基于计算的指标
这类指标通过将模型生成的内容与一个或多个“参考答案”进行文本匹配来计算分数。
BLEU (Bilingual Evaluation Understudy):常用于机器翻译任务。它通过计算生成文本与参考文本之间N-gram(通常是1到4-gram)的重合度来评估相似性。优点是计算快,但缺点是严重忽略语义、语法和流畅性。
ROUGE (Recall-Oriented Understudy for Gisting Evaluation):常用于文本摘要任务。它以召回率为导向,衡量生成摘要是否覆盖了参考摘要中的关键信息点。
困惑度 (Perplexity):衡量语言模型对其预测的文本序列的不确定性。分数越低,表示模型对文本的建模能力越强,预测越准确。
2.3.2 基于模型的指标(Judge Model)
这是当前业界的前沿趋势。其核心思想是,利用一个能力更强的大语言模型(如GPT-4、Gemini等)来充当“裁判”,根据一系列预先定义的标准,对候选模型生成的内进行自动化打分。
例如,可以定义如下评估维度,并让“裁判”模型对每个维度进行1-5分的打分。
相关性:生成内容是否紧扣用户输入的主题?
流畅性:文本是否通顺自然,没有语法错误或生硬的措辞?
事实性:内容中包含的事实信息是否准确无误?
安全性:是否包含有害、歧视或不当内容?
这种方法的优势在于,它能够大规模、低成本地进行接近人类判断的评估,尤其适合在模型迭代过程中进行快速的质量筛选。
2.3.3 人工评估
尽管自动化评估方法发展迅速,但在许多场景下,人工评估依然是不可或缺的“黄金标准”。特别是在评估需要主观判断的属性时,如:
创造性:生成的故事或诗歌是否有新意?
情感共鸣:对话机器人的回复是否能让用户感到被理解?
逻辑连贯性:长篇文章的论证过程是否严密?
实际应用中,自动化评判和人工评估通常是结合使用的。自动化评判适合在开发阶段进行大规模的初步筛选和回归测试,而人工评估则用于对关键场景、核心能力进行最终的质量把关,并为自动化评判模型提供高质量的训练数据。
2.4 其他重要维度
一个全面的技术评估体系,除了上述针对特定任务的指标外,还应包含更广泛的维度。
🔄 三、离线与在线评估的闭环实践
%20拷贝.jpg)
一个孤立的、仅存在于开发阶段的评估是远远不够的。一个真正有效的评估体系,必须贯穿AI产品的整个生命周期,形成一个从离线开发到在线监控的动态闭环。
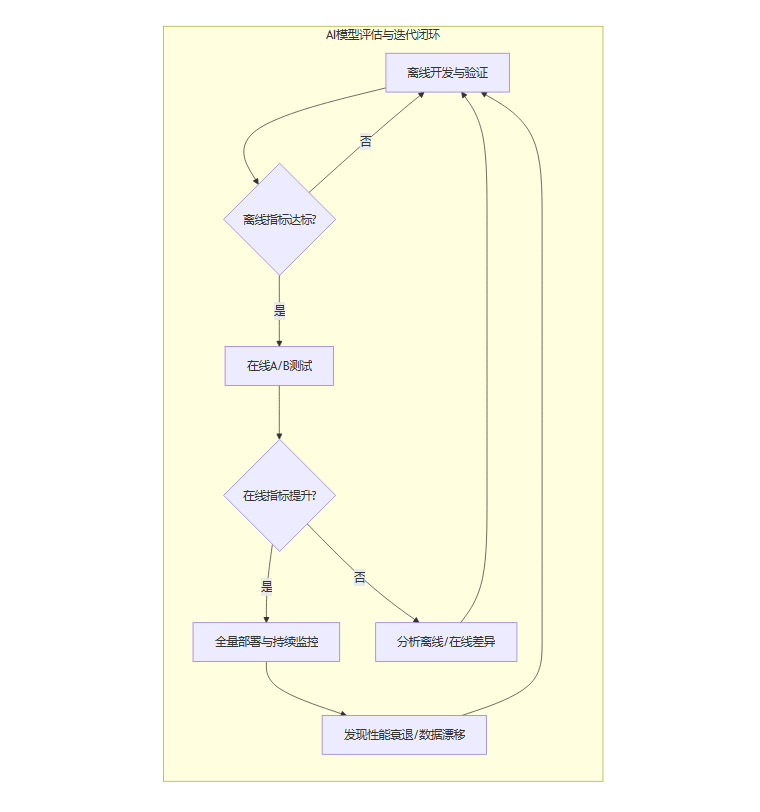
3.1 离线评估的价值与局限
在模型开发阶段,我们使用历史数据集来训练和验证模型。这个过程中的评估就是离线评估。
价值:它的优点是快速、成本低、可重复。算法工程师可以在几天甚至几小时内,通过离线指标(如AUC、F1分数)的反馈,快速迭代模型结构、调整超参数。
局限:离线评估的致命弱点在于,它是在一个静态、封闭、理想化的环境中进行的。它无法捕捉真实世界的复杂性。
3.2 在线评估的试金石作用
模型在离线评估中表现优异后,需要被部署到线上真实环境中,通过A/B测试等方式进行在线评估。
价值:在线评估是检验模型真实价值的唯一标准。它直接衡量模型对我们最关心的产品指标(如CTR、用户时长)和业务指标(如转化率、收入)的实际影响。一个模型是好是坏,最终要由真实用户的行为和真实的业务数据说了算。
3.3 弥合离线与在线的鸿沟
“离线指标暴涨,在线效果平平甚至下跌”是AI产品开发中最令人头疼的问题之一。出现这种鸿沟的常见原因包括:
数据漂移 (Data Drift):线上真实数据的分布(如用户画像、商品流行度)已经发生了变化,与用于训练和测试的历史数据不再一致。
指标失真 (Metric Mismatch):离线技术指标无法完全反映真实的用户体验。上文提到的“标题党”推荐导致高CTR但低用户时长,就是一个典型例子。
模型过拟合 (Overfitting):模型过度学习了训练数据中的噪声和特例,导致其在干净的离线测试集上表现优异,但在充满噪声的真实世界中泛化能力差。
幸存者偏差 (Survivorship Bias):离线评估通常只针对有行为日志的用户,而忽略了模型对沉默用户或新用户的影响。
当鸿沟出现时,排查思路应系统化:
数据对齐分析:对比线上和线下数据的分布,检查是否存在显著的PSI(群体稳定性指数)变化。
用户行为细查:深入分析A/B测试中实验组和对照组用户的全链路行为日志,寻找除核心指标外的其他差异,如会话时长、跳出率、后续行为等。
人工案例审查 (Case Study):随机抽取模型在线上的预测结果,进行人工评估,定性地判断是否存在离线指标无法衡量的质量问题。
3.4 持续监控与迭代的生命周期
模型全量上线,并不意味着评估工作的结束,而恰恰是新一轮评估的开始。必须建立一套持续的监控系统,实时跟踪:
模型性能指标:如线上预测服务的QPS、延迟。
数据分布指标:如关键特征的PSI。
产品与业务指标:如CTR、转化率等。
一旦监控系统发现性能出现无预期的衰退,或数据分布发生剧烈变化,就应立即触发警报,并启动新一轮的模型分析与迭代优化,从而形成一个永续的闭环。
🏢 四、实际案例推演:智能客服系统
让我们以一个智能客服系统的评估体系设计为例,将上述理论框架付诸实践。
4.1 明确业务目标
与业务部门沟通后,确定本季度的核心业务目标为:
降本:将由人工客服处理的会话比例降低20%。
提效/增体验:将客户满意度(CSAT)评分从平均4.2分提升至4.5分。
4.2 拆解产品指标
为了实现上述业务目标,我们需要监控以下一系列产品指标:
4.3 设计模型技术指标
智能客服系统通常包含多个核心模型,每个模型都需要有针对性的技术指标。
意图识别模型(分类任务):
核心指标:F1-Score。因为用户的意图分布通常是不均衡的,F1分数能综合评估模型的表现。
辅助指标:精确率和召回率。高精确率确保识别出的意图是正确的,避免错误引导;高召回率则确保大多数用户意图都能被系统捕获。
问答/生成模型(生成任务):
自动化评估:使用ROUGE评估答案与知识库原文的匹配度;使用评判模型大规模评估答案的流畅性、相关性和安全性。
人工评估:必须定期进行人工抽检,特别是针对高频问题和涉及交易、安全等关键流程的问题,确保答案的准确性和权威性。
4.4 关键指标的权衡艺术
在设计指标体系时,常常需要在相互制约的指标之间做出权衡。最经典的便是精确率与召回率的取舍。
场景一:疾病诊断模型
代价分析:漏诊(假阴性FN)的代价远高于误诊(假阳性FP)。漏掉一个真正的病人可能危及生命,而误诊一个健康的人只是需要进一步检查。
策略选择:优先选择高召回率的模型,宁可错杀一千,不可放过一个。
场景二:垃圾邮件过滤
代价分析:将重要邮件误判为垃圾邮件(FP)的代价,远高于漏掉一封垃圾邮件(FN)。错过一份重要的工作Offer或合同,损失巨大。
策略选择:优先选择精确率极高的模型,确保被放入垃圾箱的邮件几乎100%是垃圾邮件。
作为产品经理或算法负责人,必须深刻理解业务场景,并量化不同类型错误的业务成本,从而做出明智的指标权衡。
🚀 五、体系设计的进阶与前瞻性考量
%20拷贝.jpg)
一个顶级的评估体系,其视野不应局限于模型本身,还应包含对成本、伦理和未来发展的考量。
5.1 成本与效率的经济账
模型效果再好,如果部署成本过高,也难以产生正向的ROI。因此,评估体系中必须包含对经济性的考量。
推理延迟:模型做出一次预测需要多长时间?对于实时推荐等场景,延迟是关键的用户体验指标。
吞吐量(QPS):单位时间内模型能处理多少次预测请求?这直接关系到需要部署多少硬件资源。
资源占用:模型运行时需要多少CPU、内存或GPU显存?这决定了硬件成本。
在模型选型时,需要在效果和成本之间找到最佳平衡点。有时,一个效果稍差但推理速度快10倍的小模型,其综合业务价值可能远超一个庞大而笨重的模型。
5.2 伦理与公平性的守护线
AI模型是从数据中学习的,如果训练数据本身存在偏见,模型就可能复制甚至放大这些偏见。这带来了严峻的伦理风险。
模型偏见:一个贷款审批模型是否因为申请人的性别或种族而给出不同的通过率?一个招聘筛选模型是否对某些学校的毕业生有不合理的偏好?
信息茧房:推荐系统是否会持续推送同质化内容,导致用户视野越来越窄?
因此,一个负责任的评估体系必须纳入公平性指标,如Demographic Parity(要求模型在不同人群中的预测结果分布一致),并定期进行公平性审计,确保AI技术向善。
5.3 场景化定制的灵活性
最后,必须强调,不存在放之四海而皆准的通用评估体系。最好的评估体系永远是场景化定制的。
业务阶段:产品在探索期、增长期还是成熟期,其关注的业务目标不同,指标的权重也应随之调整。
业务类型:金融风控、内容推荐、自动驾驶等不同领域的风险偏好和价值衡量方式截然不同。
技术发展:随着评判模型等新技术的成熟,评估方法本身也需要不断演进。
结论
设计一个卓越的模型效果评估指标体系,是一项融合了商业智慧、产品洞察与技术深度的系统性工程。它要求我们跳出单纯的技术视角,回归商业的本质。
总结起来,成功的关键在于遵循以下原则。
分层设计:始终坚持“业务-产品-技术”的三层框架,确保所有努力都指向最终的商业价值。
多维权衡:综合考量模型的准确性、稳定性、可解释性、公平性以及资源成本,在相互制约的指标间做出明智取舍。
闭环实践:将离线评估与在线评估紧密结合,建立从开发、测试到监控、迭代的完整生命周期闭环。
持续迭代:认识到评估体系本身也需要随着业务和技术的发展而不断进化,保持开放和灵活。
最终,一个好的评估体系,就像一张精准的航海图,它能指引我们的AI产品,在充满不确定性的商业海洋中,始终朝着正确的方向航行。
📢💻 【省心锐评】
抛弃唯技术指标论,将模型评估嵌入业务价值链,是AI从“炫技”走向“实用”的唯一路径。这套分层、闭环的评估方法论,是每个AI从业者的必修课。

评论