.png)
.png)

【摘要】Gemini Robotics On-Device是谷歌DeepMind发布的首个可在机器人本地独立运行的视觉-语言-动作(VLA)模型,彻底摆脱云端依赖,实现离线智能。其多模态融合、极强泛化与迁移能力、开发者友好生态和双重安全机制,正推动机器人行业迈向“去中心化”与“设备即大脑”的新纪元。
引言
2025年6月,谷歌DeepMind正式发布Gemini Robotics On-Device——全球首个可在机器人本地独立运行的视觉-语言-动作(VLA)模型。这一突破不仅是机器人智能化进程的里程碑,更是具身智能(Embodied AI)从“云端依赖”迈向“本地自主”的关键转折点。它让机器人在断网、弱网等极端环境下依然能精准理解自然语言指令、感知复杂环境并完成高难度操作,极大拓展了机器人在工业、医疗、家庭、灾难救援等领域的应用边界11034。
本文将从技术原理、核心优势、开发者生态、行业影响与未来挑战等多维度,深度剖析Gemini Robotics On-Device如何重塑机器人行业规则,推动“设备即大脑”的新生态加速成型。
一、🚀 技术突破:从云端依赖到本地智能的跨越
%20拷贝-jauk.jpg)
1.1 首个本地化VLA模型的诞生
Gemini Robotics On-Device是谷歌DeepMind基于Gemini 2.0架构打造的首个可在机器人本地独立运行的VLA(视觉-语言-动作)模型。它集成了视觉感知、自然语言理解与动作规划三大能力,彻底摆脱了对云端算力和网络连接的依赖11034。
1.1.1 关键特性
本地运行:在算力受限的机器人硬件上高效推理,无需数据上传云端,极大降低延迟。
离线智能:即使在无网络或网络极不稳定环境下,依然能独立完成复杂任务。
多模态融合:视觉、语言、动作三大模块深度集成,支持自然语言指令到物理动作的全链路闭环。
高精度操作:可完成如“将魔方装入袋子”“拉开饭盒拉链”“墙面固定水平仪”等高难度任务。
1.1.2 技术架构
Gemini Robotics On-Device采用多模态Transformer为核心,融合视觉编码器、语言理解模块和动作生成器。其推理流程如下:
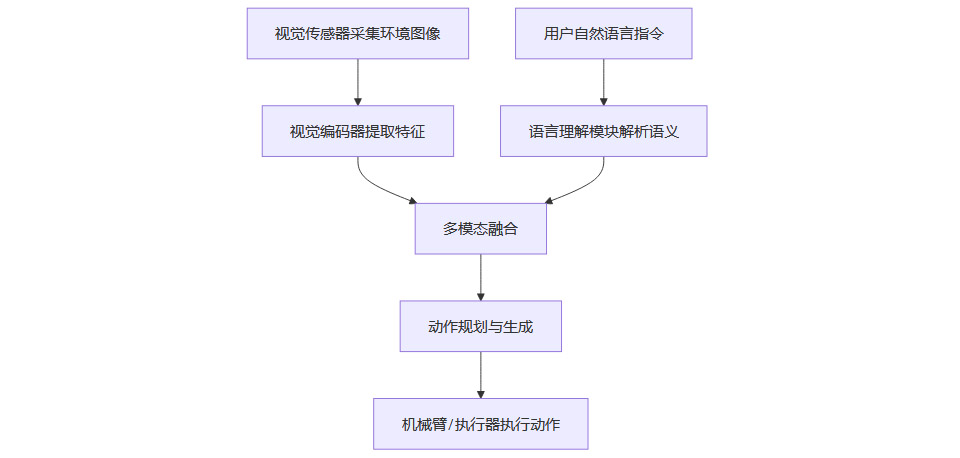
1.2 VLA模型的多模态融合
Gemini Robotics On-Device的最大创新在于将视觉、语言、动作三大AI能力深度融合,形成端到端的智能闭环513。
视觉感知:实时捕捉环境细节,识别物体、空间关系、动态变化。
语言理解:解析复杂、多步骤的自然语言指令,支持上下文推理。
动作规划:结合视觉与语言信息,生成精准的机械控制信号,实现高精度操作。
例如,面对“将桌上水果放入碗中”指令,模型会自动识别水果种类、定位空间位置、规划机械臂路径并完成抓取与放置,全程无需云端干预,响应延迟降至毫秒级110。
二、💡 核心优势:性能与适应性的双重革新
2.1 碾压级性能:重新定义本地模型标杆
Gemini Robotics On-Device在多项行业基准测试中展现出远超前代本地模型的性能1319:
泛化能力:能识别训练中未见过的物体、场景,支持复杂多步骤指令。
鲁棒性:在施加干扰、光照变化、物体遮挡等复杂环境下,依然能稳定完成任务。
低延迟:本地推理极大缩短响应时间,适用于对实时性要求极高的工业、医疗等场景。
任务完成率提升:在网络受限场景下,任务完成率较云端方案提升70%1。
2.2 轻量化适配:50-100次演示解锁新技能
Gemini Robotics On-Device具备极强的迁移学习与适应能力,开发者仅需50-100次人工演示即可让机器人掌握全新任务11316。
2.2.1 迁移学习流程
人工演示:开发者通过遥操作或手动示范目标任务(如折叠衣物、装配皮带)。
模型微调:模型自动学习演示数据,调整参数以适应新任务。
跨平台适配:即使机器人硬件结构差异巨大(如从工业机械臂到人形机器人),也能通过微调动力学参数实现高效迁移。
2.2.2 典型应用场景
工业机械臂(Franka FR3):精准装配、复杂抓取、流水线操作。
人形机器人(Apollo):家庭服务、物品整理、辅助护理。
多机器人协作:同一模型可在不同机器人间迁移,极大降低开发与部署成本20。
三、🛠️ 开发者生态:工具链赋能产业落地
%20拷贝-cmbi.jpg)
3.1 Gemini Robotics SDK:降低技术接入门槛
谷歌同步推出的Gemini Robotics SDK为开发者提供了一站式开发平台11319:
本地部署:支持在本地环境快速部署模型,无需复杂配置。
性能评估:实时监控识别准确率、动作完成度等关键指标。
可视化调试:图形化界面直观调试指令解析与动作规划,无需底层算法知识。
快速原型:大幅缩短从创意到原型的周期,助力创新加速落地。
3.1.1 SDK功能模块一览
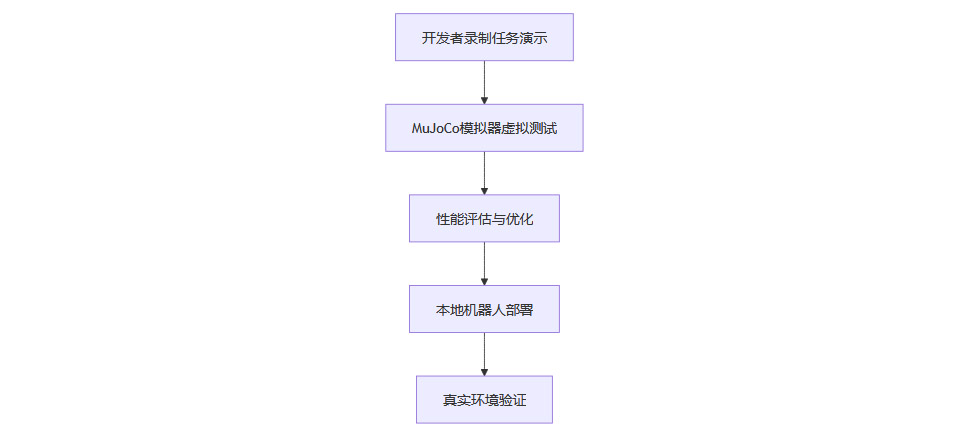
3.2 MuJoCo物理模拟器:虚拟验证降低试错成本
SDK集成的MuJoCo物理模拟器为开发者提供了高精度虚拟测试环境1335:
高保真物理仿真:模拟不同摩擦力、物体形状、环境干扰等复杂工况。
虚拟任务验证:在部署前可反复测试任务流程,避免真实硬件损耗。
开发成本降低:将试错成本降低60%以上,加速产品迭代。
3.2.1 典型应用流程
四、🌐 挑战与未来:从技术突破到生态构建
%20拷贝-foxb.jpg)
4.1 安全与伦理:为智能加装“双重保险”
随着机器人自主性提升,安全与伦理风险成为行业关注焦点8914。
4.1.1 双重安全机制
语义安全审查:通过与Gemini Live API联动,先对指令进行安全性校验,自动识别并拒绝执行如“拆除安全装置”等危险指令。
物理限位保护:在硬件层设置动作力度、运动范围等物理限制,防止机器人因误操作造成伤害。
4.1.2 行业安全基准
开放安全基准测试框架:开发者可自定义安全测试用例,进行“红队演练”暴露潜在风险。
多层AI管理:底层VLA模型负责动作生成,上级VLA模型负责推理与安全判断,实现“AI管理AI”2325。
4.2 行业影响:开启机器人“去中心化”时代
Gemini Robotics On-Device的发布,标志着机器人从“云端附庸”向“独立智能体”转型120。
4.2.1 行业变革趋势
工厂产线:无需依赖稳定网络,实现24小时自动化生产。
灾难救援:断网灾区机器人可自主执行搜救任务。
家庭服务:离线完成复杂家务,保护用户隐私。
医疗护理:在高隐私、高安全要求场景下独立作业。
4.2.2 生态构建展望
“设备即大脑”新范式:每台机器人都可拥有独立智能,摆脱中心化云端调度。
开发者创新加速:SDK与模拟器工具链降低门槛,激发千行百业创新活力。
标准化与普及:随着硬件与软件标准趋同,机器人行业有望迎来“安卓时刻”1。
结论
Gemini Robotics On-Device的横空出世,彻底打破了机器人智能“云端依赖”的技术天花板。其多模态融合、极强泛化与迁移能力、开发者友好生态和双重安全机制,不仅让机器人在极端环境下也能独立作业,更为行业带来了“去中心化”“设备即大脑”的全新范式。未来,随着开发者生态的繁荣和应用场景的不断拓展,具身智能有望从实验室走向千行百业,推动人机协作迈入全新时代。
📢💻【省心锐评】
当 “断网即失效” 成为历史,当机器人能通过少量演示快速掌握新技能,我们正迎来一个设备端智能爆发的黄金时代。随着 Gemini Robotics SDK 的开放,这场由 “离线大脑” 引发的机器人革命,即将在开发者手中催生更多颠覆性应用。

评论