.png)
%20%E6%8B%B7%E8%B4%9D.jpg)

【摘要】谷歌翻译借助Gemini AI的强大能力,实现了实时对话功能的革命性突破。新功能不仅支持超70种语言的即时互译,更在嘈杂环境、语调识别和多模态交互上表现卓越,几乎实现了零延迟的同声传译体验。同时,新增的AI语言练习功能,标志着其正从翻译工具向综合性语言服务平台演进。
引言
语言,是文明的基石,也是沟通的桥梁。但在全球化浪潮席卷的今天,这座桥梁时常因语言不通而出现断裂。长久以来,我们依赖各种工具试图弥合这道鸿沟,从笨拙的纸质词典,到初代的机器翻译,再到后来的神经网络翻译(NMT),每一步都凝聚着科技的进步。然而,真正的无缝交流,那种如同母语者对话般的自然与流畅,始终是悬在空中的一个梦想。
直到现在,这个梦想的轮廓开始变得清晰。谷歌翻译,这个我们早已熟悉的名字,近期迎来了一次脱胎换骨的升级。这次升级的核心驱动力,正是谷歌自家的王牌——Gemini AI模型。通过深度整合,谷歌翻译不再仅仅是一个“翻译”工具,它正在演变为一个口袋里的“同声传译专家”和一个智能的“语言私教”。
这篇文章将带你深入剖析这次升级背后的技术细节、产品逻辑以及它为我们描绘的未来图景。我们将一同见证,当强大的基础模型与成熟的应用场景相遇,会碰撞出怎样颠覆性的火花。这不仅是关于一个App的更新,更是关于AI如何重塑人类沟通方式的深刻变革。
🔮 一、实时对话翻译(Live Translate)的重生与飞跃
%20拷贝.jpg)
传统的实时翻译,更像是一个“你一句,我一句”的机械传话筒。它在处理连贯对话、理解言外之意以及应对真实世界复杂环境时,总是显得力不从心。而新版的“实时翻译”(Live Translate)功能,则彻底改变了这一局面。它追求的不是简单的信息转码,而是有温度、有语境、有节奏的真实对话复现。
1.1 语言覆盖的广度与交流的深度
新功能一出手,便展现了其惊人的覆盖范围。它支持的语言数量超过了70种,囊括了全球绝大多数人口使用的主要语言。
主流语言全面覆盖:中文、英语、西班牙语、法语、德语、日语、韩语、俄语、阿拉伯语等。
区域性重要语言:印地语、葡萄牙语、孟加拉语、印度尼西亚语等。
小众但关键的语言:涵盖欧洲、亚洲、非洲的多种语言,为跨文化交流提供了极大便利。
这意味着,无论你是在东京的街头问路,还是在开罗的市集讨价还价,或是在硅谷与来自不同国家的工程师进行头脑风暴,手机都能成为你可靠的翻译官。但数量只是基础,真正的突破在于交流深度的提升。系统会同步生成语音译文和双语文字记录,这看似是一个小细节,却解决了两个核心痛点。
即时确认:听觉接收信息的同时,视觉上的文字可以帮助用户快速确认翻译的准确性,避免因发音或听力问题导致的误解。
对话回溯:在一段较长的对话结束后,用户可以方便地回顾聊天记录,这对于商务谈判、学术交流等需要记录关键信息的场景至关重要。
1.2 用户体验的极致打磨
谷歌在设计新版Live Translate时,显然将用户体验放在了首位。整个交互流程被设计得极为简洁直观,几乎没有学习成本。
我们可以用一个流程图来展示其工作流程:
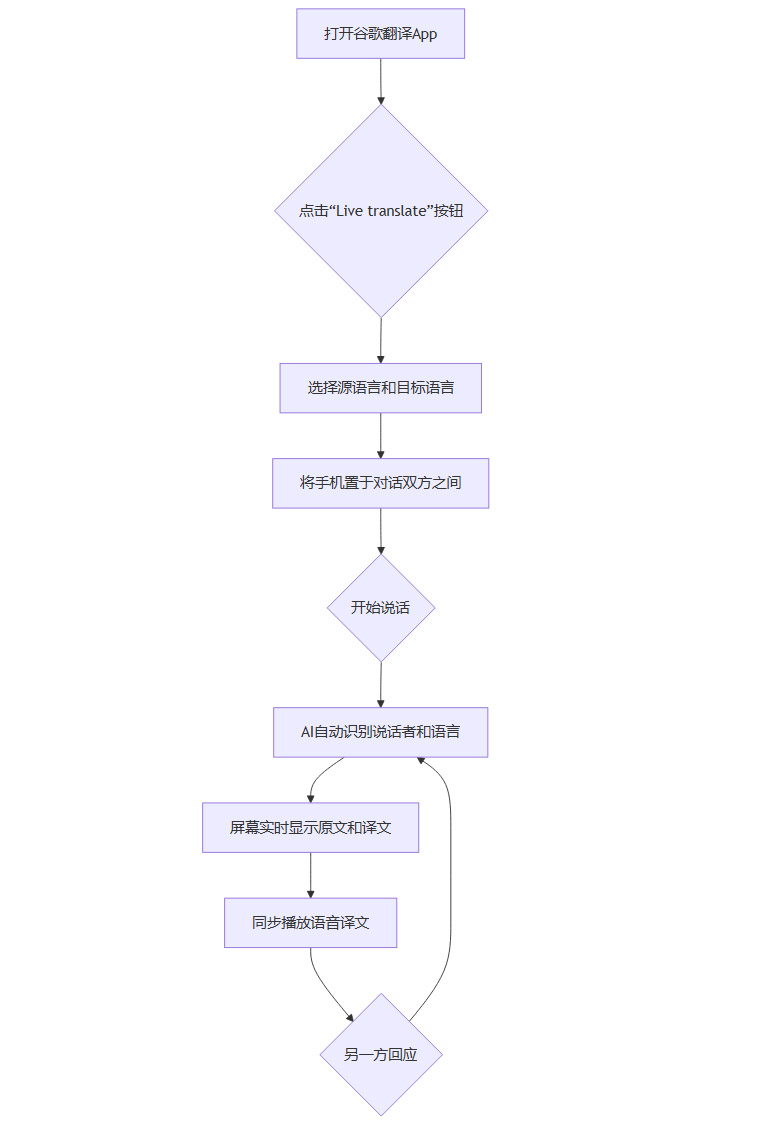
这个流程的核心在于**“无感”和“自动”**。用户不再需要频繁地手动切换语言按钮,AI能够智能判断当前是谁在说话,并自动进行相应语言的翻译。这种“无缝切换”的体验,让对话的节奏更接近自然交流,减少了科技介入带来的中断感和尴尬。
1.3 Gemini AI驱动下的三大技术支柱
新功能的惊艳表现,离不开背后Gemini AI模型的强大支撑。我们可以将其拆解为三个关键的技术支柱。
1.3.1 深度语境理解与自然度提升
传统的NMT模型虽然强大,但有时会因为缺乏对更广泛语境的理解而产生“直译尴尬”。比如,它可能很难准确翻译出蕴含文化背景的俚语或双关语。
Gemini作为一个大型多模态模型,其优势在于它被海量的文本、图像和音频数据训练过,拥有了更接近人类的常识和推理能力。
口音与语调识别:AI能够捕捉到说话者语气中的细微差别。一句“Great”,根据语调的不同,可以被理解为真诚的赞美,也可以是敷衍或反讽。新版翻译能够更好地识别这些弦外之音,从而给出更贴切的翻译。
停顿与节奏处理:人类对话充满了自然的停顿、犹豫和重复。旧的翻译系统可能会将这些视为噪音或独立的词语,导致翻译结果支离破碎。而Gemini能够理解这些语言现象在沟通中的作用,智能地进行平滑处理,使译文更连贯、更自然。
多模态交互:屏幕上实时滚动的双语字幕,与口中听到的语音译文完美同步。这种视听结合的多模态体验,极大地降低了用户的认知负荷,让交流变得更加轻松。
1.3.2 复杂声学环境下的“听风者”
现实世界的交流很少发生在安静的录音棚里。机场的广播、咖啡馆的背景音乐、街道上的车流声,这些都是机器翻译面临的巨大挑战。
谷歌为此专门研发了先进的语音分离模型。这项技术类似于人耳的“鸡尾酒会效应”,即我们能在一片嘈杂中专注于某一个人的声音。
它的工作原理可以简化为以下几步:
声源识别:麦克风捕捉到混合了人声和噪音的音频流。
特征提取:AI模型分析音频的频谱特征,区分出人类语音和背景噪音的不同模式。
目标语音增强:模型会像一个滤波器一样,放大目标说话者的语音信号。
背景噪音抑制:同时,模型会主动抑制或消除已识别的背景噪音。
这项技术的应用,使得谷歌翻译在真实场景中的可用性实现了质的飞跃。用户不再需要大声喊叫,或者寻找一个绝对安静的角落才能使用翻译功能。
1.3.3 战略性部署与市场考量
新功能首批上线的地区是美国、印度和墨西哥。这个选择并非偶然,背后有着深刻的市场和技术考量。
通过在这些具有代表性的市场进行首发,谷歌可以有效地验证技术在不同语言、不同文化、不同网络环境下的表现,为后续的全球推广打下坚实的基础。
💡 二、AI驱动的语言学习(Practice)新范式
如果说Live Translate是帮助人们“跨越”语言障碍,那么新增的“Practice”功能,则是帮助人们“拆除”这道障碍。这是谷歌翻译从“工具”向“伙伴”转型的关键一步,标志着其产品哲学的深刻演变。
2.1 从被动查询到主动练习
传统的语言学习App,大多遵循着“记单词-学语法-做练习”的固定模式。这种模式虽然有效,但往往缺乏趣味性和实用性,学习内容与真实生活场景脱节。
“Practice”功能则试图打破这一僵局。它基于一个核心理念:语言是在使用中学会的,而不是在记忆中学会的。
它将AI的能力运用到了极致,创造出一种全新的**“沉浸式场景模拟”**学习法。
个性化起点:系统会首先评估用户的语言水平和学习目标。你是为了下个月的法国旅行,还是为了准备一场英文商务演示?不同的目标,会开启完全不同的学习路径。
动态场景生成:这可能是最酷的部分。AI可以根据你的需求,动态生成一个对话场景。例如,你设定目标为“为去北海道滑雪做准备”,AI可能会为你生成以下练习模块:
场景一:租赁装备。AI扮演店员,你需要用目标语言询问滑雪板尺寸、雪靴价格等。
场景二:购买缆车票。你需要询问不同种类票价的区别,以及开放时间。
场景三:在雪场求助。模拟摔倒后,如何向巡逻员描述情况。
这种高度定制化的学习内容,确保了你所学的每一个单词、每一个句子,都是你真正需要用到的,极大地提升了学习效率和动力。
2.2 智能反馈与正向循环
学习最怕的,是“无效练习”和“错误固化”。“Practice”功能内置了一套完善的实时反馈机制,像一个耐心的私人教师,随时纠正你的错误。
发音纠正:当你读出一个句子后,AI会分析你的发音,并指出哪些单词的发音不够标准,甚至可以提供正确的口型示范。
语法建议:如果你使用了错误的语法结构,系统会高亮显示,并给出修改建议和解释。
更地道的表达:除了修正错误,AI还会告诉你“虽然你的说法没错,但当地人更倾向于这样说”,帮助你学习更地道的表达方式。
此外,系统还会每日追踪你的学习进度,通过可视化的图表让你看到自己的进步,形成一个“练习-反馈-进步-激励”的正向学习循环。
2.3 专家知识与AI技术的融合
值得一提的是,这些练习场景和课程并非完全由AI凭空生成。其背后是语言习得专家(language acquisition experts)设计的课程框架。专家们负责构建科学的学习体系和知识图谱,而AI则负责在这个框架内,进行个性化的内容填充和互动生成。
这种“人机结合”的模式,确保了学习内容的科学性和权威性,同时又兼具AI带来的灵活性和趣味性。
目前,该功能尚处于测试阶段,初期支持的语言组合有限,主要面向英语母语者学习西班牙语和法语,以及部分其他语言组合。但可以预见,随着模型的不断完善和数据的积累,它将很快扩展到更多语言,成为一个颠覆性的语言学习平台。
⚙️ 三、技术引擎与平台化野望
%20拷贝.jpg)
无论是Live Translate的流畅体验,还是Practice功能的智能互动,其背后都指向同一个名字——Gemini。这次升级,是Gemini模型在消费级应用中一次教科书式的落地展示。
3.1 Gemini:不止于语言的“通才”模型
要理解这次升级的深刻性,我们必须先简单了解一下Gemini与它的前辈们有何不同。
过去的AI翻译模型,如基于NMT的模型,本质上是“专才”。它们在文本到文本的翻译任务上表现出色,但对于处理声音、图像等多模态信息则力不从心。
而Gemini生来就是一个原生多模态(natively multimodal)模型。这意味着它从训练之初,就在同时学习和理解文本、代码、音频、图像和视频。这种能力赋予了它几项关键优势:
跨模态推理:它能理解声音和文字之间的关联,这对于实现语音和字幕的完美同步至关重要。
更强的语境感知:通过理解世界的多维度信息,它能更好地把握语言背后的真实含义,而不仅仅是字面意思。
灵活的输入输出:它可以接收语音输入,同时输出语音、文本甚至未来可能的图像化解释,为功能创新打开了想象空间。
在谷歌翻译的场景中,Gemini的能力被充分释放。它不仅负责核心的翻译任务,还深度参与了语音识别(ASR)、文本转语音(TTS)以及自然语言理解(NLU)的各个环节,将原本分散的技术模块,整合成一个高效协同的有机整体。
3.2 从工具到平台的战略转型
这次升级,清晰地揭示了谷歌翻译的未来野心。它不再满足于做一个“用完即走”的翻译工具,而是要打造一个围绕语言服务的综合性平台。
我们可以看到一条清晰的演进路径:
翻译1.0(工具时代):提供基础的文本和语音翻译,解决“看不懂、听不懂”的问题。核心价值是信息传递。
翻译2.0(助手时代):以Live Translate为代表,提供流畅的实时对话支持,解决“无法交流”的问题。核心价值是沟通赋能。
翻译3.0(平台时代):以Practice功能为开端,提供学习、交流、文化理解等一系列服务,解决“我想融入”的问题。核心价值是能力培养与文化连接。
这个平台化的转型,意味着谷歌翻译将拥有更强的用户粘性。用户不再只在出国旅行时才会想起它,而可能在日常的学习、工作和社交中频繁使用。这为谷歌带来了更丰富的数据维度和更广阔的商业化前景。
⚔️ 四、行业坐标与未来图景
%20拷贝.jpg)
谷歌翻译的这次进化,无疑在平静的翻译软件市场投下了一颗重磅炸弹。它不仅提升了自身产品的天花板,也为整个赛道树立了新的标杆。然而,身处一个巨头林立、创新不止的领域,前路并非一片坦途。
4.1 翻译赛道的“权力的游戏”
当前的机器翻译市场,早已不是一家独大的局面。各大科技巨头和垂直领域的佼佼者,都在凭借各自的优势,构建自己的护城河。
从这张对比表中,我们可以清晰地看到各家的战略分野。
DeepL 走的是“小而美”的专业路线,它用极致的文本翻译质量,赢得了专业人士和对翻译精度有苛刻要求的用户。
微软和Apple 则充分发挥了其强大的生态优势,将翻译能力作为其操作系统和办公套件的底层赋能工具,主打无缝体验。
科大讯飞 则深耕中文市场,通过“软硬结合”的方式,在特定场景下(如商务会议、出国旅游)提供了非常成熟的解决方案。
而谷歌的策略则更为宏大。它不满足于仅仅做好翻译这一件事。通过整合Gemini,它试图定义下一代翻译产品的形态。Live Translate的流畅体验和Practice的创新学习模式,是其他竞争对手在短期内难以复制的。谷歌的优势在于,它拥有最顶尖的AI模型、最海量的数据、最广泛的应用场景和最庞大的用户基础,这四者结合,形成了一个强大的飞轮效应,让其创新和迭代的速度远超他人。
4.2 硬币的另一面:挑战与隐忧
尽管前景光明,但通往“巴别塔”倒塌的道路上,依然布满了荆棘。这项技术在带来便利的同时,也伴随着一系列不容忽视的挑战。
4.2.1 技术的“最后一公里”
文化与情感的鸿沟:AI可以翻译语言,但很难翻译语言背后深嵌的文化、历史和情感。一个精妙的讽刺、一句饱含深情的诗句、一个特定文化圈才懂的笑话,在机器翻译下往往会变得索然无味甚至产生误解。这是纯粹技术难以逾越的障碍。
低资源语言的困境:对于那些在互联网上数据量稀少的语言(Low-Resource Languages),AI模型的训练效果会大打折扣。这可能导致一种“数字语言霸权”,即主流语言的翻译质量越来越高,而小众语言则被边缘化,加剧了文化多样性的流失。
性能与功耗的平衡:在移动设备上进行如此复杂的实时AI计算,对处理能力和电池续航都是巨大的考验。如何在保证流畅体验的同时,控制好设备的功耗和发热,是一个亟待解决的工程难题。
4.2.2 伦理与社会的审视
数据隐私的达摩克利斯之剑:我们的每一次对话,都可能被作为数据上传到云端用于模型训练。这些极其私密的语音数据如何被存储、使用和保护?是否存在被滥用或泄露的风险?这是每一个用户都必须关心的问题。
算法偏见的放大器:AI模型是从现实世界的数据中学习的,因此它也会不可避免地学到数据中存在的偏见,比如性别歧视、种族偏见等。翻译系统可能会在无意中强化这些刻板印象,造成负面的社会影响。
对人类职业的冲击:“同声传译”这个职业,长期以来被视作人类智力活动的顶峰之一。当AI能够以接近甚至超越人类的水平完成这项工作时,人类译员的价值何在?这不仅是对一个行业的冲击,更是对“何为人类独特价值”这一哲学问题的追问。我们是会被AI取代,还是会进化为与AI协作的“超级译员”?
4.3 语言的“巴别塔”将如何倒塌?
抛开挑战,让我们将目光投向更远的未来。谷歌翻译所展示的,仅仅是冰山一角。在AI的驱动下,人类的沟通方式正迎来一场深刻的革命。
近未来:无缝的增强现实(AR)翻译
想象一下,你戴上一副轻便的AR眼镜,走在异国的街头。路牌、菜单、海报上的文字,都会被实时翻译并叠加在你的视野中。当你与当地人交谈时,对方的话会以字幕的形式实时显示在你眼前,就像看一部自带字幕的电影。这种体验将彻底消除陌生环境带来的隔阂感,让旅行和跨文化交流变得前所未有的轻松。中未来:深度个性化的“语言化身”
未来的翻译系统,将不仅仅是翻译你说的话,它还会学习你的个人语言风格、口头禅、专业术语,甚至你的幽默感。它会为你生成一个“语言化身”(Linguistic Avatar),当你需要用外语沟通时,这个化身可以用你的风格和口吻,地道地表达你的思想。这将使得跨语言沟通不仅准确,而且“像你”。远未来:走向“心灵感应”的终极沟通
当技术发展到极致,我们甚至可能不再需要通过“说”和“听”来进行翻译。脑机接口(Brain-Computer Interface)技术或许能直接捕捉我们大脑中的语言信号,并将其翻译成另一种语言,再传递给对方。这听起来像是科幻小说,但它所代表的,是人类对跨越一切障碍、实现最纯粹思想交流的终极向往。
总结
从最初的词汇查询,到如今由Gemini驱动的实时对话与智能学习,谷歌翻译走过了一条漫长而深刻的进化之路。这次升级,不仅仅是技术参数的提升,更是一次产品哲学的跃迁。它清晰地告诉我们,AI时代的语言工具,其使命不再是简单地转换文字,而是要赋能沟通、促进理解、辅助成长。
Live Translate功能让我们得以一窥未来无障碍沟通的雏形,它将深刻改变旅游、商务、教育和日常社交的面貌。而Practice功能的出现,则开辟了AI在个性化教育领域应用的全新可能性,预示着一个人人都能轻松掌握多门语言的时代的到来。
当然,前路依然充满挑战,技术的局限、伦理的拷问、社会的适应,都是我们需要认真面对的课题。但无论如何,那座阻碍人类相互理解的“巴别塔”,在AI这股强大力量的冲击下,已经出现了第一道裂缝。而我们,正有幸站在这场伟大变革的起点,亲眼见证它的崩塌与重塑。
📢💻 【省心锐评】
谷歌此举,意不在翻译本身,而在抢占AI时代人机交互的底层入口。语言是终极场景,Gemini是钥匙,真正的棋局是生态。

评论