.png)


【摘要】谷歌最新视频模型Veo 3.1的发布,标志着其在专业化视频生成领域的深入探索。通过对新增的音画同步、首尾画面控制及三图定人设三大核心功能的深度实测与分析,揭示了其在提升视频可控性与沉浸感方面的显著进步。同时,文章将其与行业标杆Sora 2进行多维度对比,剖析了其在市场定位、定价策略以及社区反馈中的优势与不足,最终评估了这次“0.1步”升级在AI视频生成赛道上的真实分量与未来潜力。
引言
AI视频生成赛道的热度,从未像今天这样炙手可热。这片曾经由少数技术巨头开垦的处女地,如今已是硝烟弥漫的战场。每一个新模型的发布,都可能重塑行业的格局,改变内容创作的未来。就在不久前,OpenAI的Sora 2以其惊艳的效果和亲民的姿态,在全球范围内掀起了一场AI视频创作的狂欢。而现在,谷歌带着它的最新力作Veo 3.1,正式踏入了这片聚光灯下的竞技场。
北京时间10月16日,谷歌在Gemini API中悄然上线了Veo 3.1及其加速版Veo 3.1 Fast的付费预览。这不仅仅是一次常规的版本迭代,更是谷歌在AI视频领域战略意图的一次集中体现。它紧随Sora 2的脚步,同样将音频生成作为核心卖点,但更进一步,将重心放在了视频生成的可控性与专业化应用上。这引发了一个核心问题,谷歌这次是想在Sora 2开辟的道路上走得更远,还是试图开辟一条全新的、更偏向专业创作者的赛道?
本文将不仅仅停留在对新功能的简单罗列。我们将深入Veo 3.1的内核,通过详尽的实测数据、与Sora 2的横向对比、以及对社区反馈的细致梳理,尝试描绘出Veo 3.1的全貌。我们将探讨,这被外界戏称为“0.1步”的升级,究竟是谷歌在技术上的一次审慎微调,还是一次足以撼动市场格局的重磅出击。它究竟是能够硬刚Sora 2的真材实料,还是仅仅虚张声势的“纸老虎”?让我们一层层揭开Veo 3.1的神秘面纱。
一、🚀 Veo 3.1的核心进化,三大支柱重塑视频生成
%20拷贝-egpd.jpg)
Veo 3.1的升级并非大刀阔斧的重构,而是基于前代模型,在三个关键维度上进行了精准而深入的优化。这三大支柱共同构成了Veo 3.1的核心竞争力,旨在将AI视频生成从随机的“灵感迸发”推向可控的“工业生产”。
1.1 音画统一,从默片到有声世界的跨越
过去,AI生成的视频大多是“优美的哑剧”。声音的缺失,让视频少了一半的灵魂。Veo 3.1的首要突破,就是让视频开口说话,拥有自己的声音。
1.1.1 不只是配乐,更是环境的呼吸
Veo 3.1的音画统一功能,远不止于为视频添加一段背景音乐那么简单。它的核心在于场景理解与事件驱动的声音生成。
智能配乐,模型能够分析视频画面的整体情绪基调。比如,一个阳光明媚的午后场景,它可能会匹配轻快悠扬的音乐;而一个风雨交加的夜晚,则可能配上紧张悬疑的旋律。这种能力让AI视频的叙事感和情感表达能力得到了质的飞跃。
环境音效,这是更见功力的地方。模型能够识别画面中的具体元素和动态事件,并生成与之匹配的环境音。实测中“纽约街头下雨”的案例就是最好的证明。雨滴落在不同表面的声音、车辆驶过积水溅起水花的“哗啦”声、远处隐约的城市噪音,这些细节共同构建了一个可信的声场,极大地增强了视频的沉浸感。
动作音同步,当画面中出现关键动作时,比如一道闪电划破天际,Veo 3.1能够确保雷声几乎在同一时间响起。这种对时空一致性的精准把控,是衡量一个视频生成模型是否成熟的关键指标。
1.1.2 当前的局限与未来的想象
但是,目前用户还无法主动选择或上传自己想要的音频。所有声音均由AI自动生成,这在一定程度上限制了创作者的自由度。对于需要特定音效或品牌音乐的专业制作来说,这无疑是一个短板。
未来的发展方向,可能是允许用户输入音频提示词(如“添加鸟鸣声”),或者上传参考音轨,让AI在此基础上进行融合与再创作。一旦实现,AI视频的创作自由度将再次被解放。
1.2 首尾画面设定,掌控叙事的“导演权”
AI视频生成的一大痛点在于其“不可控性”,用户往往像在开盲盒,无法预知最终结果。Veo 3.1的首尾画面设定功能,正是为了解决这个问题,将一部分“导演权”交还给用户。
1.2.1 运镜的艺术,从A点到B点的优雅过渡
这个功能允许用户上传两张图片,分别定义视频的起始帧和结束帧。随后,AI会自动计算并生成中间所有的过渡画面。
解决了短视频拼接的难题。过去,创作者如果想制作一个稍长的故事,需要生成多个短片再手动拼接,但往往会因为场景、光影、主体的细微变化而显得不连贯。现在,通过将前一个视频的结尾帧作为下一个视频的起始帧,可以理论上实现无限长度的视频拼接,且过渡更为自然。
实现了对镜头运动的精准控制。比如,你可以设定一个从人物特写(起始帧)拉远到全景(结束帧)的镜头,AI会自动模拟出“拉镜头”的效果。这对于需要精确运镜的叙事性视频创作来说,是一个极其强大的工具。它让AI不再是随机画面的生成器,而是一个可以执行明确指令的虚拟摄影师。
1.2.2 “伪长视频”的巧妙解法
在当前技术下单次生成长视频仍有巨大挑战的背景下,谷歌用这种“视频接龙”的方式,巧妙地绕开了难题。它虽然不是真正的端到端长视频生成,却为实现连续性叙事提供了一个非常实用且聪明的解决方案。这背后考验的是模型对画面内容的高度理解,以及在潜在空间中进行流畅插值的能力。
1.3 三图定人设,角色一致性的关键一步
在系列视频或故事片中,保持角色的外观一致性是基本要求,但这恰恰是AI视频生成最难攻克的堡垒之一。Veo 3.1的“三图定人设”功能,正是为了攻克这一难题。
1.3.1 拆解角色的三要素
该功能允许用户最多上传三张参考图片,分别定义一个角色的核心要素。
通过这种多模态的输入方式,Veo 3.1试图将一个抽象的角色概念,解构成具体的、可供AI理解和执行的视觉指令。理论上,这可以大大提升角色在连续镜头中的一致性和稳定性,为创作系列短剧、动画片,甚至虚拟人视频提供了可能。
1.3.2 理想丰满,现实骨感
正如我们将在后续的实测部分看到的,这个功能目前的效果还远未达到理想状态。但它指明了一个非常重要的方向,即通过解耦(Disentanglement)的方式来控制生成内容。将人物、服装、场景分离开来再进行组合,是实现复杂可控内容生成的必经之路。
二、🔬 实测体验,在惊艳与失望之间
理论上的强大功能,必须经过实践的检验。我们在第三方平台Lovart上对Veo 3.1的三大核心功能进行了快速体验。结果显示,Veo 3.1的表现就像一枚硬币的两面,既有令人惊艳的亮点,也存在无法忽视的短板。
2.1 音画同步测试,细节拉满但格局受限
我们给出的指令是“纽约街头正在下雨,突然一道闪电伴随雷声而来。”
优点,声画同步性极佳。闪电亮起和雷声响起的时机基本吻合,没有出现明显的延迟。更令人印象深刻的是声音的细节。每一辆车开过水坑时,声音会有一个从远到近、从小到大的变化,这种空间感和层次感处理得相当到位,极大地提升了真实感。
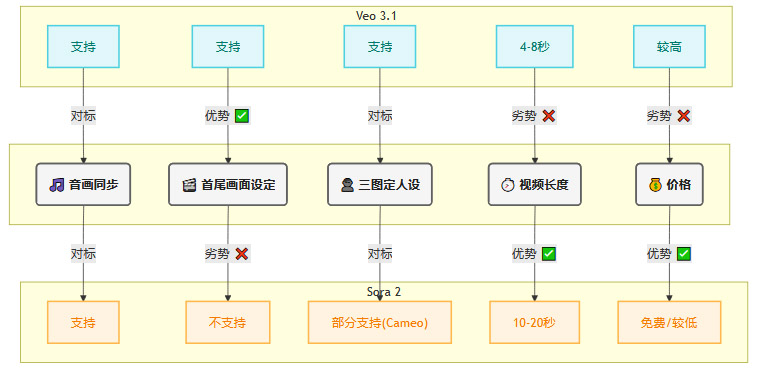
不足,问题同样突出。首先是视频时长过短,生成的片段基本都在6秒左右,与Sora 2动辄10-20秒的生成能力相比,明显不占优势。其次,画面的动态范围有限。整个视频中,只有车辆、雨滴和闪电是动态的,而两旁的行人、树木几乎完全静止,如同“世界静止,唯我独动”,这种违和感让人一眼就能看出这是AI生成的视频。这暴露了模型在处理复杂动态场景时的局限性,可能会为了保证核心元素的质量而牺牲背景的动态性。
2.2 首尾画面设定测试,叙事连贯但逻辑偶有“魔法”
我们测试了用两张图片(猫在地上和猫在桌上)生成猫跳上办公桌的视频。
优点,叙事连贯性得到保证。模型成功地生成了从起点到终点的完整动作,并且在我们将两个连续生成的视频拼接后,场景和主体猫的形象保持了很好的连贯性,确实实现了场景拓展的效果。这证明了该功能在实现连续叙事上的可行性。
不足,过程中出现了令人啼笑皆非的**“魔法感”**。在小猫跳到电脑后面时,画面中似乎凭空出现了另一只猫,破坏了物体的唯一性。此外,视频后半段的光线有突兀的变化,仿佛突然开了一盏灯。这些问题说明,虽然模型能够理解首尾状态,但对中间过程的物理逻辑和时空一致性把控仍不稳定,偶尔会出现“脑补”过度的现象。
2.3 三图定人设测试,期望最高,失望最大
我们提供了女性头像、服装参考和场景参考三张图,要求生成一段人物在场景中漫步的视频。
优点,理论上,这个功能为个性化角色创作提供了无限可能。
不足,实际效果堪称灾难。这是本次所有测试中表现最差的一项。生成的人物建模感严重,面部僵硬,与参考头像相去甚远。服装和场景也几乎与参考图片毫无关系,完全是AI自由发挥的结果。整个视频的AI生成痕迹极重,完全没有达到官方宣传中那种自然、一致的效果。这表明,Veo 3.1在理解并融合多个独立视觉信息源的能力上,还存在巨大的技术鸿沟。
三、🥊 市场对决,谷歌的自信与社区的冷静
%20拷贝-edeb.jpg)
在官方宣传中,谷歌毫不掩饰其对Veo 3.1的自信,甚至直接将其与Sora 2 Pro等一众顶级模型进行对标,并宣称在多个维度上“完胜”。然而,市场和技术社区的反馈却显得更为冷静和审慎。
3.1 谷歌的“官方战报”
谷歌官网展示的对比图表显示,Veo 3在整体观感、提示词对齐度、视觉质量等方面,全面超越了Sora 2 Pro、海螺2.0、Seedance 1.0 Pro和Renway Gen 3。尤其是在音画一致性方面,Veo 3的“视频素材”功能在内部基准测试中名列前茅。
但是,这种宣传也存在一些值得玩味的地方。比如,谷歌在对比中似乎有意模糊了Veo 3和Veo 3.1的模型边界,所有图表显示的都是Veo 3,而文字描述则指向Veo 3.1。此外,在图像转视频测试中,谷歌以“Sora 2 Pro目前不支持人像生成”为由,直接将其排除在对比之外。这种选择性的对比,让这份“战报”的客观性打上了一个问号。
3.2 社区的“冷水”
尽管谷歌自我感觉良好,但AI领域的专家和开发者们却给出了不尽相同的评价。
Otherside AI的创始人Matt Shumer直接在社交媒体上表示,他对Veo 3.1感到“有些失望”,认为其效果明显逊于Sora 2,价格却高出不少。Sora 2目前免费使用,而Veo 3.1的高昂定价让其性价比备受质疑。
3D数字艺术家Travis David则指出了更具体的技术瓶颈。他提到Veo 3.1并没有突破AI视频生成的**“8秒定律”**,且用户无法自己选择生成什么样的音频,这让创作的自由度大打折扣。
普通用户和开发者则对一些期待已久的功能,如**“自动化分镜”**的缺席感到失望。这表明,市场对AI视频模型的期待,已经从单纯的“生成画面”,转向了更高级的“自动化叙事”和“智能编排”。
四、💰 定位与定价,瞄准专业赛道的阳谋
%20拷贝-anax.jpg)
Veo 3.1的定价策略和应用案例,清晰地揭示了谷歌的市场野心,它瞄准的并非是大众娱乐市场,而是对视频质量、可控性和一致性有更高要求的专业化赛道。
4.1 “昂贵”的专业工具
Veo 3.1的定价在当前市场中处于较高水平,这本身就是一种市场筛选。它试图吸引那些愿意为更高控制力和潜在的商业价值付费的用户。
值得注意的是,谷歌在价格表下还补充说明,“在某些情况下,音频处理问题可能会导致视频无法生成。只有在成功生成视频后,系统才会向您收取费用。” 这也从侧面印证了,该模型的音频生成功能目前仍处于不太稳定的状态。
4.2 专业化应用案例的背书
谷歌给出的应用场景案例,进一步印证了其专业化定位。
GenAI电影工作室Promise Studios已经开始在其MUSE平台中使用Veo 3.1,目的是增强生成AI视频的故事性,并尽可能达到导演希望的制作质量。
AI生成内容公司Latitude也正在其生成叙事引擎中测试Veo 3.1,希望能够将用户创作的故事立即变为现实。
这些案例表明,Veo 3.1正试图撬动专业影视制作领域,通过降低高质量视频创作的门槛和成本,赋能个人创作者或小团队,让他们有机会独立制作出一系列风格统一的迷你短片或系列视频内容。
总结
Veo 3.1的发布,无疑是AI视频生成领域的一次重要事件。它并非一场颠覆性的技术革命,而更像是一次精准、务实的“战术升级”。谷歌通过在音画同步、首尾画面控制和角色一致性这三个方向上的深入探索,清晰地表达了其向专业化、可控化视频生成迈进的决心。
从实测结果来看,Veo 3.1在音画同步的细节处理和首尾画面的叙事连贯性上,确实展现出了令人惊喜的实力,为视频内容的精细化创作提供了强大的新工具。但是,它在视频生成时长、背景动态性,尤其是在“三图定人设”这一核心功能上的表现不尽如人意,暴露出其在物理逻辑一致性和多模态信息融合方面仍有很长的路要走。
与Sora 2相比,Veo 3.1选择了一条差异化的竞争路线。它放弃了在生成时长和大众娱乐性上与Sora 2硬碰硬,转而深耕专业用户对“控制力”和“一致性”的核心需求。这或许是谷歌在当前技术条件下做出的最明智的选择。
五个月的时间,谷歌在Veo视频模型上仅仅往前走了“0.1步”。这一步虽小,但方向明确。在与Sora 2的激烈竞争中,Veo 3.1目前更像是一个追赶者和补充者,而非颠覆者。它为高质量视频创作降低了门槛,但要实现真正的行业变革,仍需在角色一致性、物理逻辑和自动化叙事等核心难题上持续突破。未来,随着模型的不断优化,Veo 3.1有望成为专业创作者手中一把锋利的“手术刀”,精准地雕琢出他们想要的视觉故事。
📢💻 【省心锐评】
谷歌用工程化的严谨,试图解决AI创作的“可控性”难题。Veo 3.1是工具属性的极致体现,但离艺术创作的“灵性”尚有距离。专业赛道的一小步,却是通往AI影视工业化的一大步。

评论