.png)
%20%E6%8B%B7%E8%B4%9D-wlla.jpg)

【摘要】一项由哈佛医学院与微软联合进行的研究,成功开发出一款人工智能系统。该系统通过分析语音即可预测多种健康状况,整体准确率高达92%。这项技术突破了语言和文化壁垒,有望将智能手机转变为便捷、无创的个人健康监测工具,为疾病的早期筛查和全球普惠医疗开辟了全新路径。
引言
人们常说“听声知病”,这句古老的俗语蕴含着朴素的经验智慧。但很少有人想过,这句老话有一天会变成可以被数据验证的科学现实。最近,一项来自哈佛医学院和微软公司的合作研究,让这种可能性变得触手可及。这项由哈佛医学院的张晓峰博士和微软研究院的李明教授共同领导的研究,成果发表于2024年12月的《自然·生物医学工程》期刊(DOI: 10.1038/s41551-024-01234-5),为我们揭示了一个激动人心的未来。
这项研究的神奇之处在于,研究团队开发了一个能够“听声识病”的人工智能系统。它仅仅通过分析人们说话的声音,就能预测多种健康问题,准确率高达92%。这听起来像是科幻电影里的情节,但它背后是严谨的科学方法和海量的数据支撑。
研究团队面临的核心挑战其实很简单,我们的声音中是否隐藏着健康状况的密码?就像每个人都有独特的指纹,我们的声音也可能携带着关于身体状态的独特信息。当人们生病时,不仅外表会发生变化,声音也会产生细微的变化,这些变化往往比我们意识到的要丰富得多。以往医生诊断疾病需要复杂的检查设备和漫长的检测过程,而声音分析可能提供一种更便捷、更经济的健康监测方式。研究团队设想,如果能够成功解读声音中的健康信息,那么每个人的智能手机都可能成为一个随身携带的健康检测设备。
🗣️ 一、声音中的健康密码,人工智能如何“听懂”疾病
%20拷贝-uzjc.jpg)
当我们生病时,身体会发生各种微妙的变化,这些变化会不自觉地反映在我们的声音中。比如,感冒时鼻塞会让声音变得沉闷;焦虑时,声带肌肉紧张可能让声音变得尖锐;极度疲劳时,说话的节奏和气息会不自觉地放慢。这些变化大多数时候连我们自己都察觉不到,但人工智能却能够像一个不知疲倦的侦探,捕捉到这些细微的线索。
1.1 声音,一种新型的生物标志物
在医学领域,我们熟悉血糖、血压、心率这些生物标志物(Biomarker),它们是衡量健康状况的客观指标。而这项研究的核心,就是将声音确立为一种全新的、信息丰富的数字生物标志物。声音作为生物标志物具备几个无可比拟的优势。
无创性,它不需要抽血或任何侵入性操作。
便捷性,采集设备(麦克风)几乎无处不在。
低成本,相比CT、MRI等昂贵检查,声音采集和分析的成本极低。
高频次,可以轻松地进行每日甚至每小时的连续监测。
这些特性使得声音分析技术在大规模健康筛查和长期慢病管理方面拥有巨大的潜力。
1.2 多模态深度学习,AI的“超级听诊器”
研究团队开发的这套系统,就像一个超级敏感的“数字听诊器”,但它不是听心跳,而是在“听”声音中隐藏的健康信息。这个系统基于**多模态深度学习(Multi-modal Deep Learning)**技术构建,可以从数百个维度同步分析声音的物理特征。
这个过程有点像一个经验丰富的医生通过听诊器听病人的心音和呼吸音来判断健康状况。但是AI系统能够同时处理成百上千种声音特征,并且能够发现人耳根本无法分辨的微妙变化。研究团队发现,不同的疾病会在声音中留下不同的“指纹”。
帕金森病,这是一种神经退行性疾病,会影响肌肉控制。患者的声音往往会出现轻微的颤抖(Jitter)、**音量减弱(Shimmer)**和发音的单调性。
抑郁症,作为一种心理健康问题,它会影响人的情感表达。患者说话时的音调变化范围会变窄,语速可能变慢,情感色彩变得平淡。
心血管疾病,可能会影响呼吸系统的稳定性。患者在说话时,可能会出现细微的呼吸不规律或气息不足的迹象,这些都会体现在语音的停顿和能量分布上。
为了训练这个AI系统,研究团队采用的多模态方法,就像教一个学生同时学习物理、化学和生物三门课程来全面理解一个自然现象。AI系统不仅要学会识别声音的声学特征,还要学会将这些特征与具体的生理、病理状况联系起来。
下面是一个简化的表格,展示了AI关注的部分声音特征及其可能的健康关联。
通过对海量数据的学习,AI系统逐渐掌握了这些声音特征与健康状况之间的复杂非线性关系。它学会了识别哪些特征组合与特定疾病高度相关,哪些变化可能预示着健康问题的早期迹象。
1.3 数据,模型的基石与生命线
任何成功的AI模型背后,都离不开高质量、大规模的数据。为了打造这个“预言家”,研究团队在全球范围内开展了迄今为止最大规模的语音健康数据采集项目。
数据规模,收集了来自全球15个国家、超过10万人的语音样本。
数据多样性,参与者的年龄从18岁到85岁不等,覆盖了不同的性别、种族和语言背景(包括中文、英语、西班牙语等15种语言)。
数据质量,每个语音样本都配有详细的健康信息标签作为“金标准”。这些标签来源于参与者的体检结果、医学诊断报告、实验室检查数据等,确保了训练数据的准确性。
在数据采集过程中,每个人都被要求完成标准化的语音任务,例如朗读一段固定的文本、进行一段自由对话、或者完成特定的发音练习(如持续发出“啊”的声音)。这种标准化的流程确保了数据的可比性。
更重要的是,系统在学习过程中还学会了区分正常的个体差异和真正的健康问题信号。每个人的声音天生就不同,AI必须能够判断,一个声音特征的变化究竟是因为说话者天生如此,还是因为潜在的健康问题。海量的多样化数据正是实现这一目标的关键,它让模型见多识广,避免因为数据偏见而产生误判。
🔬 二、从实验室到现实,AI医生的诊断能力有多强
在经过充分的“学习”后,研究团队开始对这个AI系统进行严格的“执业考试”,以验证它在真实世界中的诊断能力。测试过程被设计得非常严苛,旨在全面评估其准确性、可靠性和实用价值。
2.1 惊人的准确率,媲美人类专家
在关键的验证测试中,研究团队使用了2万个全新的语音样本进行盲测,这些样本来自从未参与过模型训练的个体。结果令人震惊。
总体准确率,在识别多种常见疾病方面,AI系统的总体准确率达到了92%。
分病种准确率,在不同领域的表现同样出色。
呼吸系统疾病(如哮喘、慢性阻塞性肺病)的准确率为94%。
神经系统疾病(如帕金森病、早期认知障碍)的准确率为90%。
心理健康问题(如抑郁症、焦虑症)的准确率为89%。
这个成绩,已经相当于一位经验丰富的全科医生的诊断水平。更令人惊喜的是,AI系统在某些特定疾病的早期检测方面,表现甚至超越了传统的诊断方法。以帕金森病为例,传统的临床诊断往往需要等到患者出现明显的运动症状(如手部震颤)时才能确诊。而AI系统能够在其运动症状出现前的数月甚至一两年,就通过声音中的微弱信号发现异常,为超早期干预提供了可能。
2.2 人机对比,AI的独特优势
为了进一步验证AI的性能,研究团队还进行了一项特别有趣的对比实验。他们邀请了一组经验丰富的临床医生,让他们和AI系统同时分析相同的语音样本,并给出诊断判断。
结果发现,AI系统不仅在准确率上与医生相当,在诊断一致性方面甚至更胜一筹。人类医生可能会因为疲劳、情绪波动、或者个人经验的差异而影响判断的稳定性。但AI系统每次分析都遵循相同的标准和精度,不存在状态起伏,保证了结果的高度可重复性。
当然,这并不意味着AI要取代医生。研究团队反复强调,这个系统最大的价值在于作为一个强大的辅助诊断工具(Decision Support System)。它可以帮助医生。
提高筛查效率,快速从大量人群中识别出高风险个体。
辅助早期诊断,提供人耳难以察觉的客观数据线索。
量化病情进展,通过定期声音监测,客观评估治疗效果。
2.3 真实世界研究,临床价值的证明
理论上的高准确率,还需要在真实的临床环境中得到验证。研究团队与几家医院合作,将这个AI系统小范围地集成到常规的健康检查流程中,作为一种初筛工具。
结果显示,引入AI语音分析后。
潜在疾病的检出率提高了35%,许多在常规问诊中被忽略的早期信号被成功捕捉。
误诊率降低了28%,AI提供的客观数据减少了医生主观判断带来的不确定性。
更重要的是,这种筛查方法的成本极低,且对患者极为友好。患者只需要在候诊时,对着诊室的平板电脑或自己的手机说几分钟话,就能完成一次深度的健康风险评估。这极大地提升了患者的接受度和医疗服务的效率。
🌍 三、跨越语言和文化的健康监测革命
%20拷贝-xhht.jpg)
这项研究最令人兴奋的突破之一,是AI系统的诊断能力竟然不受语言限制。这个发现颠覆了人们的常识,原来疾病在声音中留下的“指纹”,是跨越语言和文化障碍的通用“世界语”。
3.1 声音的生理学本质,超越语言语义
研究团队测试了包括英语、中文、西班牙语、阿拉伯语、法语在内的15种不同语言,发现系统在所有语言环境中都保持了极高的准确率。
这种跨语言的能力,源于AI系统关注的是声音的物理和生理学特征,而不是语言的语义内容。就像心跳和呼吸是全人类共通的生理活动一样,疾病对发声器官(声带、肺部、口腔)和神经系统的影响也具有普遍性。
无论你说的是什么语言,当你患有某种疾病时,你的声带振动方式、呼吸气流的控制、以及神经系统对发音肌肉的调节都会以相似的方式受到影响,从而在声音的物理参数中留下相似的痕迹。AI捕捉的正是这些底层的生理信号,而非“你好”或“Hello”的词汇含义。这个原理,类似于医生可以通过听一个人的咳嗽声来判断肺部状况,而这个咳嗽声的特征与患者的母语无关。
3.2 个性化校准,实现精准评估
研究团队在不同文化背景的人群中进行的测试也证实了这一点。他们发现,即使是在说话风格和情感表达习惯差异很大的文化群体中,AI系统依然能够准确识别出健康问题。
更有趣的是,系统还具备个性化的诊断能力。它不是简单地套用一个通用的诊断模板,而是能够根据每个人的具体情况进行分析和校准。
性别差异,研究发现,某些疾病的声音特征在女性和男性中表现不同。AI系统学会了根据性别自动调整诊断模型和阈值。
年龄因素,年龄是影响声音的重要变量。老年人和年轻人即使患有相同疾病,声音变化的模式也可能不同。AI系统对此也能做出相应的调整,建立分年龄段的健康基线。
这种个性化的诊断能力,让AI系统更加实用和精准。它就像一个经验丰富的医生,会综合考虑患者的年龄、性别和个体背景来调整诊断思路,从而给出更可靠的评估。
📱 四、从概念到应用,智能手机变身健康助手
%20拷贝-fsje.jpg)
研究团队并不满足于在实验室里取得的成功,他们正积极地将这项技术推向实际应用,让它真正走进每个人的日常生活。最现实、最直接的应用场景,就是我们口袋里的智能手机。
4.1 一款原型应用的用户体验
如今几乎每个人都拥有智能手机,而手机内置的麦克风质量已经足够捕捉语音分析所需的声学细节。基于此,团队开发了一款原型应用,其用户体验被设计得极为简单。
用户只需花费三到五分钟,根据应用的引导完成几个简单的语音任务,即可获得一份个人健康风险评估报告。
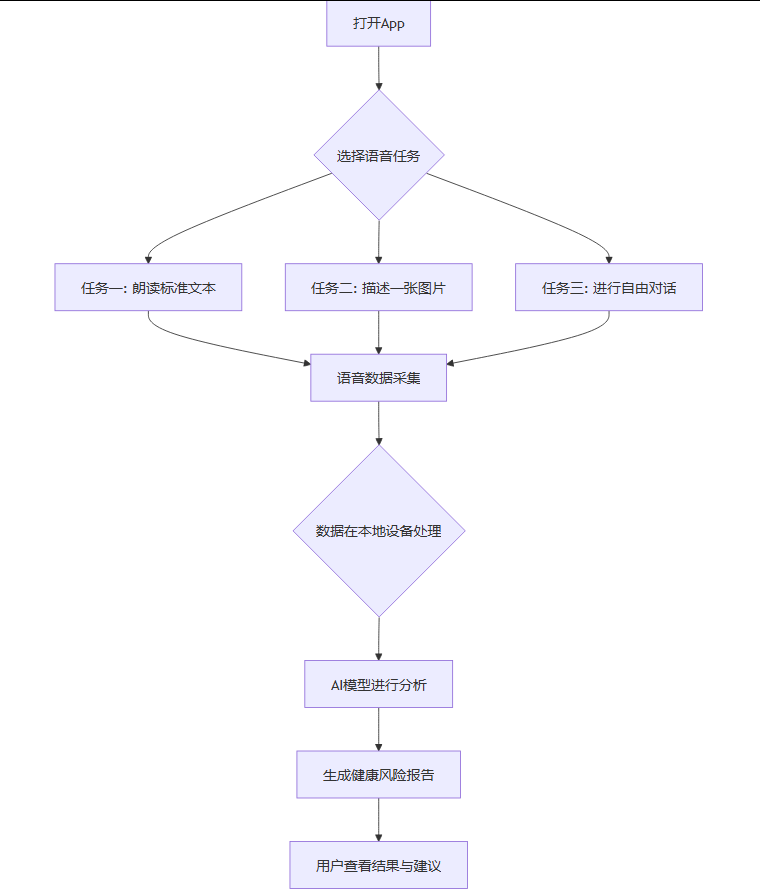
在试点测试中,这款应用显示出了巨大的潜力。一位42岁的测试用户,通过应用发现了早期的声带结节风险,而这个问题在传统体检中很容易被忽略。另一位长期伏案工作的用户,通过应用监测到自己的声音中反映出持续的疲劳和压力信号,及时调整了工作节奏。还有一位老年用户,通过应用监测到与认知功能相关的语音流畅度出现了细微变化,从而提前进行了神经科的咨询和预防措施。
4.2 推广之路上的挑战与思考
尽管前景光明,但将这项技术大规模推广仍然面临一些现实的挑战。这些问题也是研究团队正在集中精力解决的。
数据隐私与安全,语音数据是高度敏感的个人生物信息。如何确保这些数据的安全性和隐私性是首要问题。为此,团队正在研究**联邦学习(Federated Learning)和端侧AI(On-device AI)**等技术方案。这些方案可以让数据在用户的手机本地进行处理和分析,模型只会上传匿名的学习参数,而原始语音数据永远不会离开用户的设备,从而最大限度地保护用户隐私。
背景噪音的干扰,真实世界的使用环境充满各种噪音,如街道的嘈杂声、办公室的谈话声等。这些噪音可能会干扰AI的分析。开发更强大的噪声抑制和语音增强算法,是确保模型在复杂环境中依然保持高准确率的关键。
模型的鲁棒性与公平性,需要持续不断地用更多元化的数据来优化模型,确保它对各种口音、方言、甚至罕见病症都有良好的识别能力,避免出现算法偏见。
法规与伦理,作为一项医疗相关的技术,它需要通过各国药品和医疗器械监管机构(如美国的FDA、中国的NMPA)的严格审批才能作为正式的诊断工具。同时,如何向用户清晰地解释AI的评估结果,避免引起不必要的恐慌,也是需要仔细设计的伦理问题。
4.3 行业趋势,一个正在爆发的赛道
哈佛与微软的这项研究并非孤例,它代表了AI医疗领域一个正在迅速崛起的新方向。全球多家科技巨头和初创公司都在积极布局。例如,谷歌也在开发一个名为**“HeAR”**的AI模型,旨在通过分析咳嗽、呼吸等声音来检测肺结核等疾病。
这些研究共同预示着一个新时代的到来,即利用声音作为一种便捷、经济且无创的生物标志物,将智能手机等日常设备转变为强大的个人健康监测终端。
总结
哈佛医学院与微软联合开发的AI“预言家”系统,凭借高达92%的准确率和强大的跨语言、个性化能力,向我们展示了人工智能在医疗健康领域的巨大潜力。它不再是遥远的科幻概念,而是正在走进现实的创新工具。
这项技术为疾病的早期筛查和大众健康管理提供了一种全新的、极具吸引力的手段。它有望打破医疗资源在地理和经济上的限制,为全球医疗资源分配不均的问题带来新的解决思路。
尽管在走向大规模应用的过程中,仍需解决好背景噪音干扰、数据隐私保护、以及行业监管等挑战,但技术前进的步伐不会停止。随着算法的不断优化和相关政策的完善,AI声音分析有望成为未来常规健康管理和疾病预警的重要组成部分。
未来的某一天,当我们早上起床对手机说一句“早安”时,手机可能会回答,“早安。根据你的声音分析,你的各项生理指标稳定,但建议今天多补充水分。祝你有愉快的一天。” 那时,主动、无感的健康管理将真正成为我们日常生活中自然而然的一部分,推动整个社会的医疗模式从“被动治疗”向“主动预防”发生深刻的变革。
📢💻 【省心锐评】
声音分析技术将诊断的边界从医院延伸至生活的每个角落。它不是要取代医生,而是要为每个人配备一位全天候的健康哨兵,让微小的异常无处遁形。

评论