.png)


【摘要】ByteDance Seed团队提出的AttentionInfluence方法,首次让小模型为大模型筛选高质量训练数据,突破传统AI数据筛选思路。该方法无需人工标注,依靠模型内部注意力机制,显著提升大模型推理与泛化能力,开启AI自举式进化新纪元。
引言
在人工智能的世界里,数据是燃料,模型是引擎。我们都知道,训练一个强大的大语言模型(LLM),就像培养一位博学多才的学者,离不开海量且优质的“精神食粮”——训练数据。然而,互联网浩如烟海,优质内容与噪声杂质混杂,如何高效、精准地筛选出真正有营养的数据,始终是AI领域的核心难题。
过去,数据筛选要么靠人工标注、专家审核,要么依赖复杂的分类器。这些方法不仅成本高昂、效率低下,还容易带入主观偏见。更让人头疼的是,随着模型规模和数据量的爆炸式增长,传统方法已难以为继。
就在大家以为“数据筛选只能靠大力出奇迹”时,ByteDance Seed团队带来了令人眼前一亮的创新:让小模型为大模型当“质检员”!他们提出的AttentionInfluence方法,利用小模型内部的注意力机制,自动识别高质量数据,显著提升大模型的推理和泛化能力。这一突破不仅颠覆了“强者为师”的传统认知,更为AI训练开辟了全新路径。
本文将带你深入剖析这一革命性方法的原理、实验、技术细节与行业意义,全面解读小模型如何成为大模型的“良师益友”,以及这背后对AI未来的深远影响。
一、🌟 颠覆认知:小模型如何成为大模型的“质检员”?
%20拷贝-boke.jpg)
1.1 传统数据筛选的困境
1.1.1 人工标注与专家审核的局限
高成本:需要大量人力,尤其是领域专家,费用高昂。
低效率:面对数百亿、数千亿词汇级别的数据,人工审核几乎不可能完成。
主观偏见:不同标注者标准不一,容易引入偏见,影响数据多样性。
1.1.2 传统分类器的瓶颈
依赖标注数据:训练分类器本身就需要高质量标注集,形成“先有鸡还是先有蛋”的悖论。
过拟合风险:分类器容易对特定风格、主题产生偏好,导致数据单一。
迁移性差:不同领域、不同语言需单独训练,适应性有限。
1.2 AttentionInfluence:让AI自己当“质检员”
1.2.1 方法核心
AttentionInfluence的核心思想是:利用小模型内部的“注意力机制”,自动评估每条数据对模型推理能力的影响,无需人工标注或更大模型的指导。
1.2.2 关键创新
无需人工标注:完全自监督,省去繁琐的人工审核。
模型自举:小模型通过自身“直觉”判断数据质量,打破“强者为师”的传统。
关注推理能力:优先筛选能激活模型“检索头”的数据,提升推理与泛化。
1.2.3 颠覆性意义
成本大幅降低:小模型即可完成大规模数据筛选,极大节省算力与人力。
泛化能力提升:筛选出的数据更有助于大模型复杂推理能力的提升。
自举式进化:AI系统可自我优化,迈向更高层次的智能。
二、🔍 技术原理深剖:AttentionInfluence的工作机制
2.1 注意力机制与“检索头”揭秘
2.1.1 什么是注意力机制?
类比人脑聚焦:模型在处理文本时,会自动“关注”最相关的词句,类似人类阅读时的聚焦能力。
多头注意力:Transformer架构中,每一层有多个“注意力头”,各自负责不同的信息提取任务。
2.1.2 “检索头”的特殊作用
信息检索专家:部分注意力头专门负责在长文本中定位、提取关键信息,称为“检索头”。
推理链条激活:当文本需要跨句、跨段推理时,检索头尤为活跃。
2.1.3 检索头识别方法
代理任务设计:构建JSON格式的“密码本”+查询任务,测试模型能否准确检索目标信息。
复制粘贴评分:统计注意力头在生成目标词时,是否将最高权重分配给正确位置,量化检索能力。
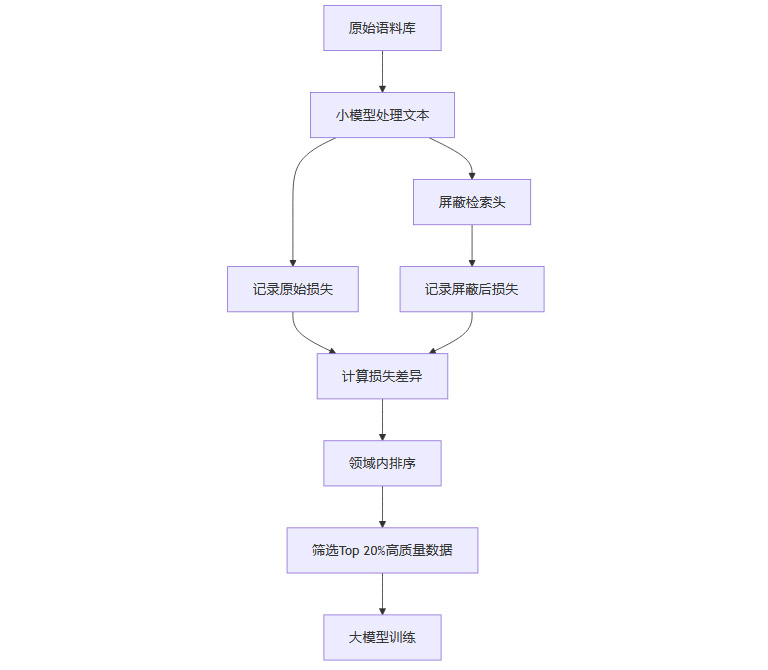
2.2 AttentionInfluence评分流程
2.2.1 损失差异法
正常推理:小模型处理文本,记录交叉熵损失(困惑度)。
屏蔽检索头:关闭检索头后再处理同一文本,记录新损失。
评分公式:
AttentionInfluence Score=损失屏蔽−损失原始损失原始AttentionInfluence Score=损失原始损失屏蔽−损失原始评分解读:差异越大,说明该文本对推理能力依赖越强,质量越高。
2.2.2 领域内归一化
避免领域偏差:不同领域(如数学、代码、对话)损失分布不同,评分仅在同领域内排序,确保公平。
2.2.3 高质量数据筛选
Top 20%原则:每个领域选取评分最高的20%文本,作为高质量训练数据。
2.3 技术流程图
三、🧪 实验设计与结果:小模型筛选,大模型飞跃
%20拷贝.jpg)
3.1 实验设置
3.1.1 语料库与模型
SmolLM语料库:共2410亿词,涵盖教育、百科、代码、数学等多领域。
小模型:13亿参数,用于数据筛选。
大模型:70亿参数,最终训练与评测。
3.1.2 数据筛选与训练流程
小模型为每条数据打分,筛选出730亿词(Top 20%)。
大模型用“精选数据+原始数据”共1万亿词训练,采用WSD学习率调度。
3.1.3 基准测试
知识问答:MMLU、MMLU-Pro、AGIEval-en
数学推理:GSM8K、OpenWebMath
代码生成:HumanEval
常识理解:BBH等
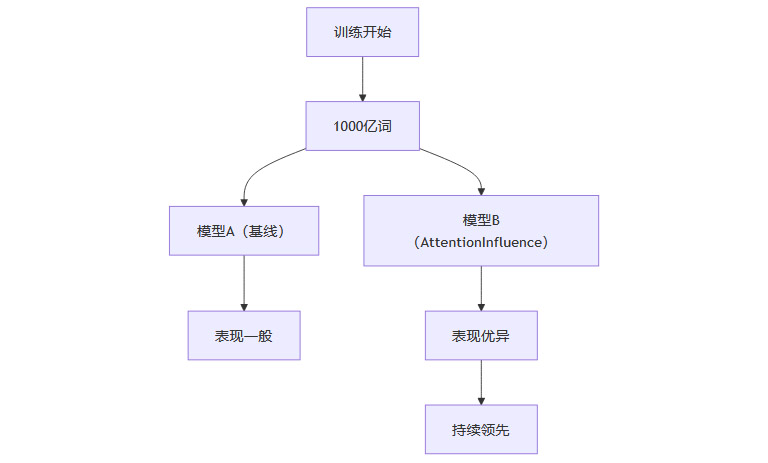
3.2 实验结果
3.2.1 整体性能提升
3.2.2 训练过程动态
早期即见优势:训练到1000亿词时,优势已显现。
持续领先:整个训练周期内,损失值与各项任务表现均优于基线。
推理任务提升显著:数学、代码等复杂推理任务提升尤为突出。
3.2.3 直观类比
就像两个学生同时学习,一个用普通教材,一个用“精选好书”,后者从一开始就领先,且优势不断扩大。
3.3 结果可视化
四、🧠 深度解析:为何小模型能指导大模型?
4.1 检索头的“超能力”
4.1.1 早期即具推理识别力
检索头在小模型训练早期就已形成,能敏锐捕捉推理链条。
类比:有经验的图书管理员,虽不如教授博学,但能精准识别“好书”。
4.1.2 屏蔽实验验证
屏蔽检索头后,模型在推理任务上性能大幅下降。
随机屏蔽其他注意力头,影响微弱。
说明检索头是推理能力的“核心部件”。
4.2 “弱到强”的泛化机制
4.2.1 小模型的“直觉”可迁移
小模型虽弱,但其对推理数据的敏感性可为大模型提供有力指导。
这种“弱到强”的泛化,打破了“强者为师”的传统AI训练范式。
4.2.2 镜像效应
小模型屏蔽检索头后表现下降最明显的任务,恰是大模型用筛选数据训练后提升最大的任务。
形成“弱点-强项”镜像,验证方法有效性。
4.3 可扩展性与未来潜力
用更大模型筛选,数据质量进一步提升,最终模型表现更佳。
方法可随算力与模型规模扩展,具备持续进化潜力。
五、📊 数据分析:AI筛选的数据有何独特之处?
%20拷贝-rixv.jpg)
5.1 GPT-4o辅助评估
5.1.1 教育价值与推理强度双维度评分
AttentionInfluence筛选数据在推理强度上显著优于传统分类器。
教育价值评分与传统方法相当,说明新方法并未牺牲内容质量。
5.1.2 领域表现差异
5.2 文本长度与结构偏好
AttentionInfluence偏爱更长、结构更复杂的文本,尤其在代码和数学领域。
选择样本平均长度几乎为传统分类器的两倍,反映对内容完整性和推理链条的偏好。
5.3 具体案例对比
5.3.1 编程教育领域
AttentionInfluence倾向选择包含问题描述、解题思路、代码实现和注释的完整样本。
传统分类器更关注代码语法和主题相关性,易忽略上下文完整性。
5.3.2 数学领域
新方法偏好完整推导过程,传统方法偏好格式规范但推理简单的内容。
5.4 词频与主题分布分析
5.4.1 词汇偏好
AttentionInfluence更青睐“method”、“procedure”、“sklearn”等方法论词汇。
传统分类器偏好“19th”、“dimensional”等数值和历史性词汇。
5.4.2 聚类与PCA可视化
AttentionInfluence筛选数据主题分布更均衡,覆盖更广语义空间。
传统分类器数据集中于特定主题,分布较窄。
六、🛠️ 技术细节全解:小模型如何成为大模型的“良师”
6.1 检索头识别的精巧设计
6.1.1 代理任务构建
样本设计:每个测试样本包含一个JSON格式的上下文(多个键值对)和一个查询任务。
键值生成:键为32位随机字母数字串,值为真实网络文档采样句子,确保多样性与真实性。
任务目标:模型需根据查询键,准确检索并输出对应值,模拟真实信息检索场景。
6.1.2 控制变量
长度限制:每个样本不超过4096词,避免长度对注意力分布的干扰。
3-shot设置:每个查询任务配备三个示例,帮助模型理解任务格式。
6.1.3 检索评分算法
复制粘贴判定:当模型生成目标词时,若某注意力头最高权重指向上下文中该词位置,计为一次成功复制。
评分公式:检索评分 = 成功复制次数 / 总词数。
筛选标准:取平均检索评分最高的5%注意力头,作为“检索头”。
6.2 AttentionInfluence评分的实现细节
6.2.1 损失计算
完整模型损失:对每条文本,先用完整小模型计算交叉熵损失。
屏蔽检索头损失:将检索头的注意力权重均匀化(非置零),再计算损失。
评分归一化:用损失相对变化率衡量影响力,避免绝对损失受文本长度等因素干扰。
6.2.2 屏蔽策略的技术考量
均匀化而非置零:防止信息完全丢失,保证模型仍能“读懂”文本,只是失去检索能力。
领域内排序:每个领域单独排序,确保不同类型文本评分可比性。
6.2.3 数据筛选比例
Top 20%原则:在效果与效率间权衡,既保证数据量充足,又确保质量显著提升。
可调节性:比例可根据实际需求调整,适应不同训练规模。
6.3 代码实现与开源
代码已开源:研究团队已在arXiv论文中公开方法与代码,便于社区复现与扩展。
模块化设计:检索头识别、评分计算、数据筛选等环节均可独立替换或优化,便于集成到不同训练流水线。
七、🧩 多维验证与对比:方法有效性的全方位证明
%20拷贝-oayv.jpg)
7.1 与传统方法的直接对比
7.1.1 FineWeb-Edu分类器对比
重叠度分析:在教育和百科领域,两种方法筛选数据重叠度高达70%;在代码和数学领域,重叠度低于60%,显示出明显互补性。
主题分布:AttentionInfluence筛选数据主题更均衡,传统分类器则在特定主题上过度集中。
7.1.2 词频与内容差异
方法论词汇:AttentionInfluence更偏好“method”、“procedure”等词,反映对推理链条的重视。
数值与历史词汇:传统分类器更关注“19th”、“dimensional”等,偏向描述性内容。
7.2 消融实验:检索头的不可替代性
7.2.1 屏蔽检索头 vs. 随机屏蔽
推理任务表现:屏蔽检索头,模型在推理密集型任务上性能大幅下降;随机屏蔽其他头,影响微弱。
理论验证:证明检索头是推理能力的关键,AttentionInfluence方法理论基础扎实。
7.3 可扩展性测试
7.3.1 更大模型筛选
70亿参数小模型筛选:用更大模型筛选数据,最终训练出的大模型在多个基准测试中表现更佳。
方法可扩展:随着筛选模型规模提升,数据质量和最终模型性能同步提升。
7.4 人工与自动化评估
7.4.1 GPT-4o双盲评估
评估维度:教育价值、推理强度。
结果:AttentionInfluence在推理强度上显著优于传统方法,教育价值持平。
7.4.2 训练过程动态追踪
早期优势:训练初期即显现性能提升,且优势持续扩大。
系统性改进:数据质量提升带来的是全周期、全任务的系统性进步。
7.5 架构无关性
LLaMA2为主:主要实验基于LLaMA2架构。
初步泛化:在其他Transformer架构上也显示出类似效果,方法具备广泛适用性。
八、🚀 实际应用与未来展望:AI训练范式的变革
8.1 成本与效率的革命
8.1.1 低成本高效率
无需人工标注:极大降低人力与时间成本。
小模型即可大规模筛选:算力消耗远低于传统大模型或分类器方法。
8.1.2 多语言与多领域适应性
无需为每种语言/领域单独训练分类器:只要有预训练小模型即可直接应用。
适应性强:新领域、新语言快速迁移,极大提升数据筛选灵活性。
8.2 数据质量与多样性的提升
8.2.1 发现“隐藏的好数据”
模型内在“直觉”:能发现人类或传统分类器难以察觉的高价值数据模式。
避免人类偏见:减少人为主观标准对数据多样性的限制。
8.2.2 与传统方法互补
特征空间分布互补:两种方法选出的数据在语义空间分布不同,结合使用可获得更全面的数据覆盖。
未来混合筛选:有望通过加权融合等方式,进一步提升数据质量。
8.3 可扩展性与创新空间
8.3.1 随模型规模提升
更大筛选模型=更优数据:方法可随算力和模型技术进步持续进化。
适应超大规模训练:为未来百亿、千亿参数级模型训练提供可行路径。
8.3.2 针对性数据筛选
代理任务可定制:可为数学、代码、常识等不同能力设计专属筛选任务。
专用模型训练:为垂直领域AI模型提供更精准的数据支持。
8.4 局限性与未来挑战
8.4.1 规模与文本长度
当前实验规模有限:在更大规模、超长文本场景下效果有待进一步验证。
长文本处理能力:需优化AttentionInfluence在超长文本上的评分与筛选策略。
8.4.2 注意力机制的进一步挖掘
检索头之外的作用:其他类型注意力头的协同效应尚未充分研究。
多模态扩展:方法能否迁移到图像、音频等多模态数据筛选,值得探索。
8.4.3 后训练阶段应用
强化学习等后训练环节:AttentionInfluence在RLHF等后训练阶段的潜力尚待开发。
8.5 AI自举式进化的曙光
AI自我优化:让AI系统参与自身改进,形成“自举”式进化机制。
范式转变:从“人类主导”到“AI自我提升”,推动AI迈向更高智能。
结论
ByteDance Seed团队提出的AttentionInfluence方法,首次让小模型为大模型筛选高质量训练数据,彻底颠覆了AI数据筛选的传统范式。通过巧妙利用模型内部的注意力机制,尤其是“检索头”的推理能力,这一方法无需人工标注、无需大模型指导,极大降低了数据筛选的成本与门槛。
实验结果显示,AttentionInfluence不仅能显著提升大模型在推理、代码、数学等复杂任务上的表现,还能在训练早期即展现出持续优势。更重要的是,这一方法展现了“弱到强”的泛化能力,为AI自举式进化提供了现实路径。
未来,随着方法的不断完善与扩展,AttentionInfluence有望成为AI训练流水线的标配工具,推动AI系统实现更高效、更智能的自我优化。对于AI研究者与工程师而言,这不仅是一次技术突破,更是一次思维方式的革新。让我们共同期待,AI在自我进化的道路上,走得更远、更快、更稳。
📢💻 【省心锐评】
“小模型撬动大智能——AttentionInfluence用‘自省式筛选’重构数据价值评估体系,这可能是继Transformer之后最重要的训练范式突破。”

评论