.png)


【摘要】腾讯微信AI团队在ICML 2025发表的连续视觉自回归生成(EAR)研究,突破了传统图像生成的“离散翻译”瓶颈,实现了无需离散token、直接连续建模的高效高质图像生成。本文深度解析其理论、技术、实验与应用前景,全面剖析该方法对AI视觉生成领域的革命性意义。
引言
在AI视觉生成领域,如何让机器像人类画家一样“自由挥洒”,一直是科学家们孜孜以求的目标。过去,AI生成图像的方式更像是“拼马赛克”——先把连续的画面拆成有限的“色块”,再用这些色块拼出新画。这个过程不可避免地丢失了细腻的色彩和渐变,生成的图像总有一层“数字味”。而腾讯微信AI团队的邵晨泽、孟凡东和周杰三位研究者,带来了一项令人振奋的突破:他们让AI不再需要“翻译”成离散token,而是直接在连续空间中作画,极大提升了生成质量和效率。这项成果已发表于ICML 2025,并开源了完整代码(https://github.com/shaochenze/EAR),为业界和学界带来了全新思路。
本文将以通俗生动的语言,结合严谨的技术分析,带你全面了解这项划时代的研究。从理论创新到工程实现,从实验对比到未来展望,既有技术深度,也有行业广度。无论你是AI研究者、开发者,还是对AI艺术感兴趣的普通读者,都能在这里找到属于你的“知识彩蛋”。
一、连续视觉自回归生成的前世今生
%20拷贝.jpg)
1.1 传统图像生成的“翻译困境”
1.1.1 离散token化的本质
在过去的主流AI图像生成方法中,几乎都离不开“tokenization”——即把连续的图像像素信息,量化成有限的离散token。比如VQ-VAE、DALL·E等模型,都是先把图片切分成小块,每块用一个“代币”编号,然后用这些编号来训练和生成。这个过程就像让AI用有限的色块拼出一幅画,细腻的渐变和丰富的色彩难以还原。
1.1.2 “翻译”带来的损失
这种“翻译”机制,虽然让AI可以借鉴自然语言处理的成功经验(如Transformer架构),但也带来了不可避免的信息损失:
细节丢失:连续的色彩和纹理被粗糙地切分,难以还原真实画面。
量化误差:token数量有限,无法覆盖所有可能的像素组合。
生成受限:模型只能在“已知token”范围内组合,创新性受限。
1.1.3 传统方法的代表
1.2 腾讯EAR的“连续革命”
1.2.1 直接在连续空间作画
腾讯团队提出的“连续视觉自回归生成”方法,彻底跳过了离散token这一步,让AI像画家一样,直接在连续的色彩空间中作画。每一步生成的不是“编号”,而是连续的像素向量,理论上可以调出任何需要的色彩和细节。
1.2.2 理论基础:严格适当评分规则
这一突破的核心,是引入了“严格适当评分规则”(Strictly Proper Scoring Rules)作为训练目标。简单来说,这是一种“只奖励诚实”的评分系统,只有当模型生成的分布完全贴合真实分布时,才能获得最高分。任何偏离都会被“扣分”,极大提升了生成的真实性和多样性。
1.2.3 能量分数:概率之外的新评分
在连续空间中,直接计算概率密度极其困难。腾讯团队巧妙地采用了“能量分数”(Energy Score)作为训练损失,这是一种不依赖概率密度、只需采样的评分方式。它既能衡量生成样本与真实样本的接近程度,又能鼓励生成的多样性。
1.2.4 EAR方法的独特优势
跳过离散token,保留更多细节
训练和推理效率高,生成速度快
理论上可统一解释多种生成方法(如GIVT、扩散损失)
二、EAR方法的技术原理与创新
2.1 “连续视觉自回归”框架详解
2.1.1 自回归生成的基本思想
自回归(Autoregressive)模型,是指AI一步一步地生成图像的每一部分,每一步都依赖于前面的内容。就像画家一笔一笔地完成画作,AI每次生成一个“token”或一个像素块,直到整幅画完成。
2.1.2 连续tokenizer的设计
与传统的离散tokenizer不同,连续tokenizer直接输出连续向量,每个向量代表一个图像patch的特征。这样,模型可以在理论上生成无限种不同的patch,极大提升了表达能力。
2.1.3 能量变换器架构
EAR的核心是“能量变换器”(Energy Transformer),其结构与传统Transformer类似,但输出层用一个小型MLP生成器替代了softmax。MLP生成器接受随机噪声作为输入,通过采样隐式建模预测分布,类似于GAN的生成器,但更简洁高效。
2.1.4 掩码自回归与双向注意力
传统自回归多为“从左到右”因果生成,EAR支持“掩码自回归”——即模型可以随机顺序预测被掩盖的patch,允许双向注意力。这种方式能更好地捕捉全局信息,提升生成质量。
2.2 严格适当评分规则的理论基础
2.2.1 什么是严格适当评分规则?
严格适当评分规则是一类特殊的损失函数,只有当模型预测的分布与真实分布完全一致时,才能取得最优值。常见的如对数评分(log-score)、能量分数(energy score)、Hyvarinen评分等。
2.2.2 能量分数的定义与优势
能量分数的数学定义如下:
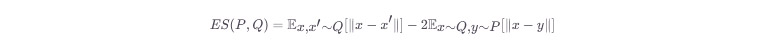
其中PP是真实分布,QQ是模型分布。能量分数不需要概率密度,只需能从模型采样即可,极大简化了实现难度。
2.2.3 统一解释多种生成方法
腾讯团队发现,许多看似不同的生成方法,其实都可以用严格适当评分规则统一解释:
这种统一视角,有助于理解不同方法的本质联系,为后续创新提供理论基础。
2.3 EAR的工程实现与关键技术细节
2.3.1 能量损失函数的直观含义
EAR的能量损失函数,鼓励模型生成的样本既要接近目标图像,又要保持多样性。就像训练一个画家,既要画得像,又不能千篇一律。
2.3.2 温度机制与生成多样性
EAR引入了“温度机制”,允许在训练和推理时调节生成的多样性与准确性。训练时可降低多样性提升质量,推理时可调节创意水平,适应不同应用需求。
2.3.3 无分类器引导技术
在条件生成任务中,EAR采用“无分类器引导”——即同时考虑有条件和无条件的预测,提升生成质量。这一技术已在扩散模型中被验证有效。
2.3.4 MLP生成器的学习率调优
实验发现,MLP生成器需要比主干网络更小的学习率(约0.25倍),否则训练不稳定。这一细节为后续模型调优提供了重要经验。
2.3.5 噪声类型与维度选择
EAR支持不同类型和维度的随机噪声输入。实验表明,64维均匀噪声效果最佳,优于高斯噪声和其他维度选择。
三、EAR的实验验证与性能评估
%20拷贝.jpg)
3.1 实验设置与对比基线
3.1.1 数据集与评测指标
数据集:ImageNet 256×256(计算机视觉标准基准)
评测指标:FID(Frechet Inception Distance)、Inception Score、推理延迟
3.1.2 对比方法
3.2 EAR的性能亮点
3.2.1 生成质量与效率兼得
EAR在同等参数规模下,FID分数与最优扩散模型接近,但推理速度快近10倍。生成一张高质量图像仅需约1秒,极大提升了实际应用的可行性。
3.2.2 掩码自回归的优势
实验显示,掩码自回归(双向注意力)显著优于传统因果自回归:
无引导时,FID从17.83降至7.95
有引导时,FID从8.10降至3.55
3.2.3 分类器自由引导的效果
通过线性增加引导尺度,Inception Score持续提升,FID在尺度为3.0左右达到最优。过高的引导尺度会损害生成多样性,需权衡选择。
3.2.4 温度机制的调优
训练温度设为0.99,推理温度设为0.7时,质量与多样性达到最佳平衡。用户可根据实际需求灵活调整。
3.2.5 噪声类型与维度的实验结论
均匀噪声优于高斯噪声
64维噪声效果最佳
3.3 消融实验与理论验证
3.3.1 严格适当性的重要性
实验验证,能量损失的指数系数α需在(0,2)范围内,α=2时训练效果显著下降,印证了理论分析。
3.3.2 表达能力对比
能量变换器相比预定义分布(如高斯分布)方法,生成质量更高,能更好地建模连续token分布的复杂性。
3.3.3 连续tokenizer的优势
在相同架构下,连续tokenization配合能量损失始终优于离散tokenization配合交叉熵损失,凸显了连续视觉自回归的潜力。
3.3.4 学习率与训练稳定性
MLP生成器学习率需为主干网络的0.25倍,否则模型难以收敛。该经验为后续研究提供了实践指导。
四、EAR的理论意义与未来展望
4.1 统一的理论框架
4.1.1 不同生成方法的统一解释
通过严格适当评分规则,EAR将GIVT、扩散模型等不同方法纳入同一理论框架,便于理解和比较。
4.1.2 理论指导实践的良性循环
理论创新为工程实现提供方向,实践验证又反哺理论完善,推动AI生成领域持续进步。
4.2 应用前景与行业影响
4.2.1 高质量图像生成的多场景应用
艺术创作与AI绘画
内容生成与广告设计
数据增强与虚拟环境构建
实时或近实时生成需求(如游戏、AR/VR)
4.2.2 降低创意门槛,赋能大众
随着EAR等技术的成熟,未来AI绘画、内容创作工具将更快更美,普通用户也能轻松创作专业级视觉作品。
4.2.3 对AI生成领域的深远影响
EAR的出现,标志着AI视觉生成从“拼马赛克”向“油画技法”进化,推动整个行业向更高质量、更高效率迈进。
4.3 局限性与未来改进方向
4.3.1 架构优化空间
现有能量变换器架构仍有提升空间,未来可探索更适合连续生成的网络结构。
4.3.2 评分规则的多样化
不同严格适当评分规则在特定任务上或有不同优势,值得进一步研究。
4.3.3 跨模态扩展
EAR理论可推广到视频、音频等连续模态,甚至通过潜在向量将离散文本建模为连续空间,拓展应用边界。
4.3.4 理论与实践的持续融合
理论创新需与工程实践紧密结合,持续优化模型性能与应用体验。
五、Q&A:你关心的问题都在这里
%20拷贝.jpg)
5.1 什么是连续视觉自回归生成?它和传统方法有什么不同?
连续视觉自回归生成让AI直接处理连续图像信息,像画家用调色板调色。传统方法需先“翻译”为离散token,丢失细节。新方法跳过“翻译”,保留更多精细信息,生成质量更高。
5.2 EAR方法会不会取代现有的图像生成技术?
EAR在生成速度和质量上有明显优势,尤其适合需要快速生成的场景。但不会完全取代所有方法,不同技术各有适用场景,未来将多种方法并存。
5.3 普通人能使用这种技术吗?有什么实际应用?
目前EAR仍处于研究阶段,普通人暂时无法直接使用。但随着技术成熟,预计会集成到AI绘画、内容创作、游戏开发等工具中,未来有望应用于手机拍照美化、社交媒体内容生成等日常场景。
结论
腾讯微信AI团队的EAR方法,打破了AI图像生成领域长期以来的“离散翻译”桎梏,让AI像真正的画家一样,在连续空间中自由创作。其理论创新、工程实现和实验验证,均展现出极高的科学价值和应用潜力。EAR不仅提升了生成质量和效率,更为AI视觉生成领域提供了统一的理论框架和广阔的发展空间。随着技术的不断优化和普及,未来我们有望见证AI创作力的又一次飞跃,让每个人都能轻松释放自己的艺术想象力。
📢💻 【省心锐评】
“连续自回归是生成领域的引力波探测,理论优美但工程化艰难。腾讯证明了可行性,下一步需降低算力门槛才能颠覆行业。”

评论