.png)
%20%E6%8B%B7%E8%B4%9D-fgeq.jpg)

【摘要】打造A股量化投资RAG智能体,需贯穿数据准备到智能生成的全链路。通过精选数据源、构建高质量知识库、实施混合检索与多模态输出,可有效提升投研决策的专业性、时效性和可靠性。
引言
在A股市场这个信息高度密集、瞬息万变的竞技场中,量化投资者每天都在与海量数据进行着一场没有硝烟的战争。行情波动、公司财报、行业研报、宏观政策、市场情绪……这些数据如潮水般涌来,既是机遇的源泉,也是决策的挑战。传统的分析方法与工具,在处理这些多源异构、真伪难辨的信息时,常常显得力不从心。
大型语言模型(LLM)的出现,似乎为我们带来了曙光。它们强大的自然语言理解与生成能力,让我们看到了自动化投研的可能。但是,一个残酷的现实摆在面前,通用大模型如同一个博学的历史学家,其知识库停留在过去的某个时间点。它无法告诉你今天上午刚刚发布的最新财报数据,也可能对A股市场特有的交易规则和行业术语理解出现偏差。更致命的是,当信息不足时,它可能会产生“幻觉”,编造出看似合理实则谬误的结论,这在分秒必争、真金白银的投资决策中是绝对无法容忍的。
所以,我们需要一种新的范式。一种能够将大模型的“智慧大脑”与一个实时更新、专业可靠的“外挂知识库”完美结合的方案。这正是检索增强生成(Retrieval-Augmented Generation, RAG)技术的核心思想。RAG通过“先检索、再生成”的机制,让大模型在回答问题前,先从我们为其精心构建的金融知识库中查找最相关、最准确的依据。这不仅极大地提升了答案的时效性与专业性,更重要的是,它为模型的每一个结论都提供了可追溯的数据来源,从根本上解决了“幻觉”问题,为量化投资智能体注入了可靠性的灵魂。
本文将带您走过一段从0到1的旅程,详细拆解如何在A股量化投资场景下,一步步构建一个强大、可靠的RAG智能体。我们将从知识库的构建开始,深入探讨数据处理、模型选择、系统优化与应用落地的每一个环节。
一、RAG在A股量化投资中的核心价值
%20拷贝-bwgy.jpg)
在深入技术细节之前,我们必须清晰地认识到,RAG对于量化投资智能体而言,并非锦上添花,而是不可或缺的基石。它直接解决了传统LLM在金融领域应用的三大核心痛点。
1.1 解决知识时效性问题
A股市场是一个政策驱动与事件驱动特征非常明显的市场。一条新的监管政策、一份超预期的财报、一次突发的行业事件,都可能在短时间内引起市场的剧烈波动。依赖固化知识的LLM无法捕捉这些动态变化。而RAG系统通过接入一个可实时更新的知识库,能够确保智能体获取到最新的市场数据、公司公告、政策文件与新闻资讯,从而做出基于当下市场环境的精准判断。
1.2 增强领域专业性
金融领域充满了复杂的专业术语、会计准则与监管规则。通用大模型或许知道“市盈率”的基本概念,但可能无法深入理解不同行业市盈率的估值逻辑差异,或者特定会计准则调整对财报利润的影响。RAG允许我们构建一个高度定制化的金融知识库,其中可以包含会计准-则详解、行业研究框架、特定公司的历史数据分析等深度内容。这使得智能体能够提供远超通用模型的专业分析与见解。
1.3 提升决策可靠性
投资决策,可靠性是生命线。RAG的核心机制,就是强制模型基于检索到的真实数据生成答案。当用户提问时,系统首先从知识库中找到相关证据,然后将这些证据连同问题一起交给大模型,并明确指示“请仅根据以下资料回答”。这种方式极大地降低了模型凭空捏造信息的“幻觉”风险。并且,最终输出的答案可以附上明确的数据来源引用,例如“根据XX公司2024年第一季度财报第15页”,实现了决策的可追溯性与可解释性,这在合规要求严格的金融行业尤为重要。
1.4 支持多模态数据分析
现代金融数据远不止文本。K线图、财务报表中的图表、行业研报中的流程图,这些多模态信息蕴含着丰富的洞察。先进的RAG架构已经开始支持对图像、表格等多模态数据的理解与检索。这意味着未来的智能体不仅能读懂文字,还能“看懂”图表,从更丰富的维度进行综合分析,例如直接分析一张K线图的技术形态,或者解读财报中的营收构成饼图。
二、离线阶段:知识库构建流程
RAG系统的上限,取决于其知识库的质量。这个离线构建阶段,是整个工程中最耗时、最关键的一环,它决定了智能体最终能达到的高度。为了更直观地理解RAG系统构建流程,下图展示了从数据采集到最终输出的全链路步骤。
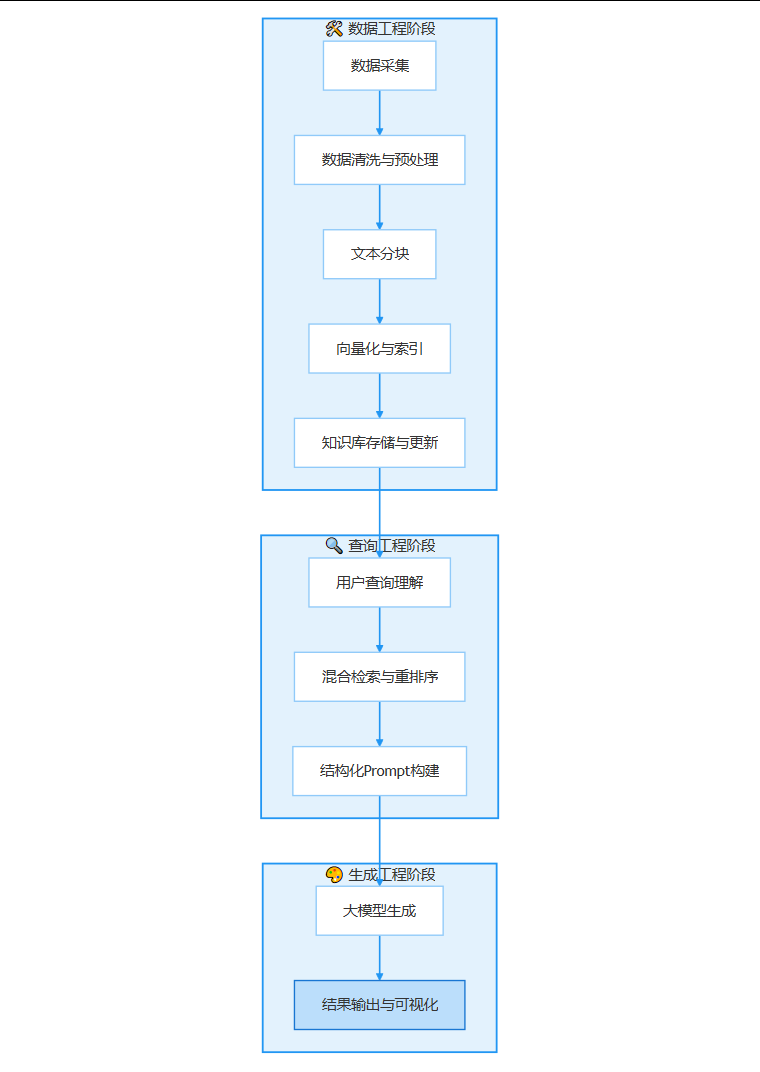
这个流程清晰地展示了每个环节的逻辑关系,我们将首先聚焦于离线阶段,即从数据采集到知识库存储与更新的环节。
2.1 数据源选择与采集
构建A股量化投资知识库,首要任务是进行全面的数据源规划。一个全面的数据策略是成功的起点。下表总结了A股量化投资中常用的数据源类型及其特点。
2.1.1 结构化数据
这是量化分析的基础,特点是格式规整、数据精确。
历史与实时行情数据。包括股票、指数、基金等的开盘、收盘、最高、最低价,以及成交量、成交额、换手率等。可以通过Tushare、Baostock等数据接口或付费数据服务商获取。
公司财务报表数据。资产负债表、利润表、现金流量表是分析公司基本面的核心。需要覆盖多年的历史数据,以便进行趋势分析。
宏观经济指标。GDP、CPI、PMI、利率、汇率等数据,是判断市场整体环境的重要依据。
因子数据。各类风格因子、技术因子、另类因子数据,是构建量化策略的基础。
2.1.2 非结构化数据
这部分数据为冰冷的数字赋予了背景、逻辑和情绪,是深度分析的关键。
上市公司公告。年报、季报、临时公告、招股说明书等,是获取公司一手信息的最权威渠道。特别是PDF格式的年报,其中包含了大量图表和管理层讨论与分析(MD&A)的宝贵信息。
券商研究报告。覆盖宏观、策略、行业、个股的深度分析报告,提供了专业的分析框架和观点。
财经新闻与资讯。来自主流财经媒体的实时新闻,帮助捕捉市场动态和热点事件。
社交媒体舆情。来自雪球、股吧、微博等平台的投资者讨论,可以作为市场情绪的辅助观测指标。
2.1.3 动态实时数据
这类数据通过API接口实时获取,保证了智能体的时效性。
实时行情API。提供分钟级甚至tick级的市场报价。
新闻推送API。实时推送重大财经新闻和公司公告。
政策发布监控。通过爬虫或专用接口监控证监会、交易所等官方网站的政策发布。
2.2 数据清洗与预处理
原始数据如同未经雕琢的璞玉,充满了杂质。我们需要通过一系列精细化的处理,才能让其绽放光彩。
2.2.1 多格式解析
面对PDF、Word、Excel、HTML等多种格式的数据,我们需要一个强大的解析层。
文档加载器(Loaders)。利用LangChain、LlamaIndex等框架中丰富的文档加载器,可以轻松处理不同格式的文件。
OCR技术。对于扫描版的PDF或图片格式的公告,需要使用OCR(光学字符识别)技术提取其中的文字。
表格解析。财报和研报中的表格是信息的金矿。需要采用专门的表格解析工具,将其转换为结构化的数据(如CSV或JSON),而不是简单地当成纯文本处理。
2.2.2 数据清洗
“垃圾进,垃圾出”是数据处理的黄金法则。
格式统一。将解析后的内容统一转换为Markdown或纯文本格式,便于后续处理。
去噪处理。坚决剔除文档中的广告、页眉页脚、导航链接、版权声明等无关内容。
数据去重。对于来自多个渠道的新闻或公告,需要进行内容去重,避免信息冗余。
2.2.3 元数据增强
这是提升RAG系统检索精度的关键一步。我们需要为每一个数据块(Chunk)都打上丰富的**元数据(Metadata)**标签。
基础元数据。包括数据来源(如“海通证券研报”)、发布日期、文件标题等。
实体元数据。标记出数据块中涉及的公司代码、公司名称、行业分类等。
内容元数据。例如,对于一份研报,可以标记出章节信息(如“财务分析”、“风险提示”),或者报告类型(如“深度报告”、“首次覆盖”)。
元数据的作用巨大。它让我们可以实现更复杂的过滤式检索。例如,用户可以提问“查找一下2024年第一季度关于宁德时代的风险提示内容”,系统可以通过元数据首先筛选出“时间=2024Q1”、“公司=宁德时代”、“章节=风险提示”的数据块,再在小范围内进行语义检索,准确率和效率都会大幅提升。
2.3 文本分块 (Chunking)
由于大模型处理的上下文长度有限(即Token限制),我们不能将整篇研报或财报直接扔给模型。必须将其切分成更小的、逻辑上独立的文本块(Chunk)。
2.3.1 分块策略
固定大小分块。最简单的方法,但容易在句子或段落中间切断,破坏语义完整性。
递归字符分块。一种更智能的方法,它会尝试按段落、句子等分隔符进行切分,尽可能保持语义的完整。
语义分块。更先进的策略,它会根据文本向量的语义相似度来决定切分点,确保每个块内的语义高度一致。对于金融文本,按逻辑单元(如财报的章节、研报的小标题)进行切分通常是效果最好的方式。
一个经验法则是,Chunk的大小通常设置在256到512个Token之间。同时,为了避免关键信息在切分处被割裂,可以在相邻的Chunk之间设置一定的重叠(Overlap),比如50个Token。
2.3.2 特殊结构处理
对于表格和图像,简单的文本化处理会丢失大量信息。
表格序列化。可以将表格转换为Markdown格式或JSON格式的字符串,并附上表格的标题和上下文描述。
多模态嵌入。采用支持多模态的嵌入模型(如CLIP),将图像和表格也转换为向量,使其可以和文本一起被检索。
2.4 向量化与索引
这是将文本世界的信息翻译成机器能够理解的数学语言的过程。
2.4.1 嵌入模型选择
嵌入模型(Embedding Model)负责将每个文本块转换为一个高维向量(Vector)。语义上相似的文本,在向量空间中的距离也更近。
模型选择。市面上有众多优秀的开源和闭源嵌入模型。对于中英文金融文本场景,BGE-M3、Qwen-Embedding、以及OpenAI的text-embedding系列都是不错的选择。选择时需要权衡模型的性能、向量维度、以及私有化部署的便利性。
2.4.2 向量数据库选型
向量数据库是专门用来存储和高效检索海量向量数据的。
主流选择。Milvus、FAISS、Pinecone、Elasticsearch等都是业界主流的向量数据库。选择时需要考虑数据规模、查询并发量、部署成本以及是否支持混合检索等因素。对于需要私有化部署的金融机构,开源的Milvus是一个非常好的选择。
2.5 知识库更新与管理
知识库不是一次性建成就万事大吉的,它需要持续的维护和更新,才能保持其价值。
2.5.1 持续更新机制
必须建立自动化的数据采集和更新流程。例如,设置定时任务,每天收盘后自动抓取最新的公司公告和研报,经过完整的处理流程后,增量更新到知识库中。
2.5.2 安全与合规
金融数据高度敏感。整个RAG系统,特别是知识库部分,必须支持私有化部署。同时,需要建立严格的权限控制和数据加密机制,确保数据在存储、传输和使用过程中的绝对安全,满足行业监管的合规要求。
三、在线阶段:检索增强与生成流程
%20拷贝.jpg)
当高质量的知识库构建完成后,就进入了在线服务阶段。当用户发起一个查询时,RAG系统将启动一套精密的“检索-增强-生成”流程,为用户提供精准的答案。以下流程图清晰地展示了这一在线响应过程。
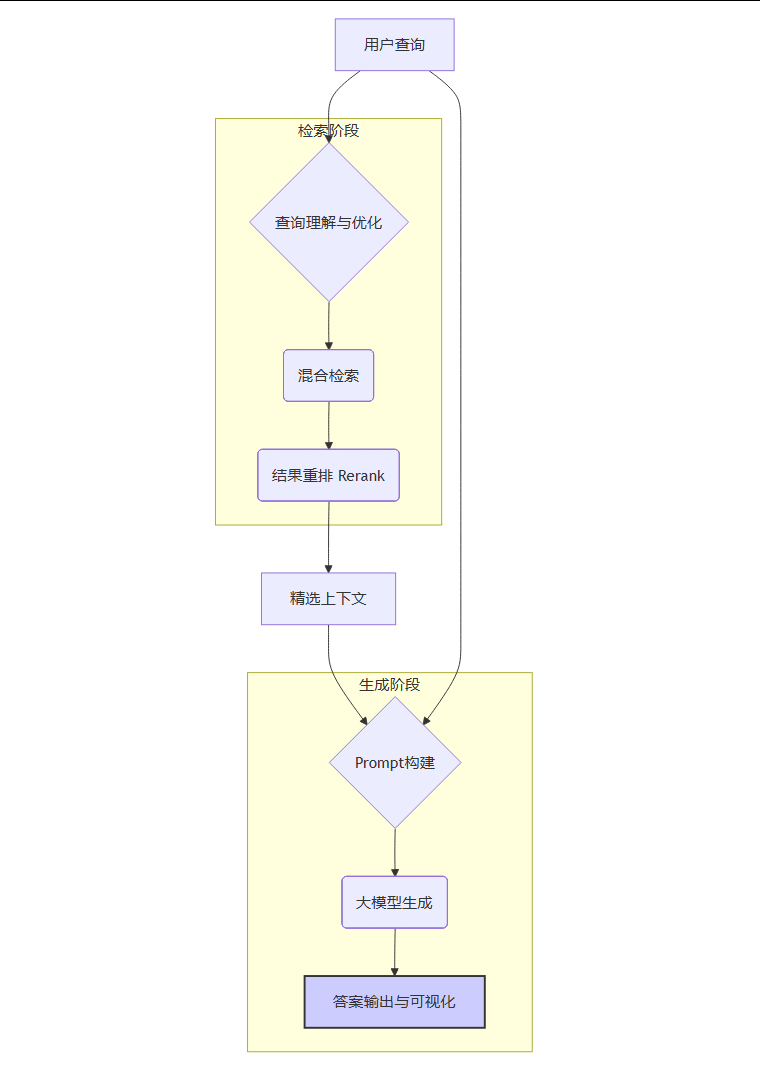
3.1 查询理解与优化
用户的提问往往是口语化、模糊的。为了提升检索效果,第一步是对查询本身进行优化。
3.1.1 查询重写
可以利用大模型的能力,先对用户的原始查询进行“预处理”。例如,用户问“茅台最近咋样?”,可以将其重写为更精确的检索语句,如“查询贵州茅台(600519)最近的股价表现、最新财报摘要、以及相关的市场新闻和券商研报观点”。
3.1.2 查询分解
对于复杂问题,如“对比分析宁德时代和比亚迪的电池业务,并评估它们各自的风险”,可以将其分解为多个子查询。
查询宁德时代的电池业务介绍和财务数据。
查询比亚迪的电池业务介绍和财务数据。
查询两家公司在财报中各自披露的风险。
分别对这些子查询进行检索,然后将所有检索到的信息汇总,再交给大模型进行综合分析和生成。
3.2 混合检索与重排序
单一的检索方式往往有其局限性。为了最大化召回率和准确率,**混合检索(Hybrid Search)**已成为工业级RAG系统的标配。
3.2.1 混合检索策略
向量检索(稠密检索)。这是RAG的核心。它将用户的查询也转换为向量,然后在向量数据库中寻找语义上最相似的文本块。它擅长理解用户的真实意图,即使查询的字面词语与原文不完全匹配。
关键词检索(稀疏检索)。对于股票代码(如“600519”)、专有名词(如“科创板”)等需要精确匹配的场景,传统的关键词检索算法(如BM25)依然不可或缺。
混合检索就是将这两种方式的结果进行融合。常用的融合策略是倒数排序融合(Reciprocal Rank Fusion, RRF),它能综合考虑两种检索方式的排序结果,给出更优的最终排序。
3.2.2 结果重排序 (Rerank)
初步检索召回的Top-K(比如前50个)结果中,可能仍然存在一些不那么相关的文档。为了进一步提升送入大模型的信息质量,我们需要一个“精炼”步骤。
重排序(Rerank)。使用一个更强大、更复杂的重排序模型(如Cross-Encoder),对初步召回的结果进行二次打分和排序。与嵌入模型不同,重排序模型会同时看到查询和文档,从而做出更精准的相关性判断。bge-reranker系列是目前效果非常好的开源重排序模型。这一步虽然会增加一点点延迟,但对最终生成质量的提升是巨大的。
3.3 Prompt构建
Prompt是连接检索到的上下文和最终生成答案的桥梁,其设计是一门艺术。
3.3.1 结构化Prompt设计
一个好的Prompt模板,应该清晰地告诉大模型它的角色、任务、可用的信息以及输出的要求。
角色设定。例如,“你是一位资深的A股金融分析师。”
任务指令。例如,“请根据以下提供的资料,回答用户的问题。回答必须简洁、专业,并分点列出。”
上下文注入。将经过重排序后最相关的几个文本块(Context)插入到Prompt中。
约束条件。例如,“禁止使用任何你自己的知识,只允许使用提供的资料。 如果资料无法回答问题,请明确告知‘根据现有资料无法回答’。”
格式要求。例如,“在引用资料时,请在句末用[来源]格式标注出处。”
3.3.2 LLM生成与控制
将构建好的Prompt输入给大模型(如GPT-4、GLM-4、Llama 3等),它就会生成最终的答案。在生成环节,我们还可以通过设置一些参数来控制输出质量,例如调整Temperature参数来控制答案的创造性与确定性。对于金融场景,通常会使用较低的Temperature以确保答案的严谨性。
3.4 结果输出与追溯
好的答案不仅要准确,还要易于理解和信任。
3.4.1 多模态输出
对于包含大量数据的分析,纯文本的输出是枯燥且低效的。一个优秀的量化投资智能体,应该具备多模态输出的能力。
数据可视化。将财务数据自动生成为折线图、柱状图,将持仓数据生成为桑基图,将相关性分析生成为热力图。
交互式仪表盘。将多个分析结果整合到一个可交互的Dashboard中,让用户可以自由探索。
3.4.2 来源追溯
这是建立用户信任的关键。在生成的答案中,每一个关键论点或数据点,都应该清晰地标注其来源。这不仅让用户可以验证信息的准确性,也体现了智能体的专业与严谨。
四、技术栈选型与工程实践
从原型到能够稳定服务的工业级系统,还需要在技术选型和工程实践上下功夫。
4.1 主流框架与工具
选择成熟的框架和工具,可以大大加快开发进程,避免重复造轮子。
4.2 金融领域定制化
通用RAG框架提供了骨架,但血肉需要我们自己填充。
构建金融专用词典。在分词和检索环节,引入金融领域的专用词典,可以提升对“降准降息”、“大小非解禁”等术语的识别准确率。
整合会计准则与监管规则。将这些规则性的知识也纳入知识库,可以让智能体在分析财报或解读政策时更加合规和专业。
4.3 工业级工程优化
为了保证系统的性能和稳定性,需要采用一系列工程优化手段。
缓存机制。对于一些高频、重复的查询,可以引入缓存层,直接返回结果,降低系统负载。
批量处理。在数据离线处理阶段,采用批量处理(Batch Processing)的方式进行向量化,可以大大提升效率。
向量量化。对于超大规模的向量数据,可以通过向量量化技术压缩向量大小,降低内存消耗和提升检索速度。
异步加载与流式输出。在在线服务时,采用异步加载模型和流式输出(Streaming)的方式,可以显著降低用户的等待时间,提升交互体验。
4.4 评估与迭代
RAG系统不是一成不变的。需要建立一套评估体系,持续监控其表现并进行优化。
评估指标。可以使用RAGAS等框架,从召回率(Faithfulness)、准确率(Answer Relevancy)等多个维度对系统进行量化评估。
用户反馈闭环。建立用户反馈机制,收集用户对答案的“赞”或“踩”,将这些反馈作为优化模型和检索策略的重要依据。
五、典型应用场景
%20拷贝.jpg)
一个构建完善的RAG智能体,可以在量化投资的多个环节中创造巨大价值。
5.1 机构投研
分析师面对一家公司,需要阅读几十份研报、多年的财报和公告。RAG智能体可以在几分钟内自动完成这些信息的整合,生成一份包含公司概况、财务摘要、核心竞争力、风险点、市场观点汇总的多维度尽职调查报告,将分析师从繁琐的信息收集中解放出来,专注于更高层次的判断与决策。
5.2 个人投资辅助
普通投资者可以通过自然语言与智能体交互。例如,输入“帮我分析一下我的持仓,有哪些风险?”,智能体可以结合用户的持仓数据和知识库中的最新信息,分析个股风险、行业集中度风险,并根据市场异动进行定制化的风险预警。
5.3 金融风控
风控部门可以利用RAG智能体,实时监控全市场的舆情、政策和关联公司的公告,一旦发现可能对持仓标的产生负面影响的事件,系统可以立即结合内部风控规则,自动生成风险评估报告和预警建议,大大提升风险响应的速度和广度。
5.4 应用案例
以某大型银行的信用风险预测系统为例。该系统原先主要依赖结构化的财务数据。在引入RAG技术后,系统整合了企业的财报(特别是附注中的细节)、相关新闻、社交媒体上的负面舆情等多源非结构化数据。当分析一笔贷款申请时,RAG系统能够自动挖掘出“该公司近期有核心技术人员离职”、“其下游主要客户出现经营困难”等财报数据无法直接反映的风险信号。最终,该系统将风险预测的准确率提升了15%-20%,并且能够将潜在的违约预警时间提前3-5天。
六、挑战与展望
构建RAG系统的道路并非一帆风顺,依然面临着挑战,但未来也充满了想象空间。
6.1 数据质量
知识库的质量是RAG系统的天花板。如何设计更高效、更智能的数据清洗、标注和更新流程,持续提升知识库的信噪比,是一个需要长期投入和优化的课题。
6.2 检索效率与准确性
更复杂的检索策略(如引入重排序)会提升准确性,但也会增加延迟。如何在保证结果质量的前提下,通过工程优化和算法创新,实现毫秒级的响应,是工业级应用必须面对的挑战。
6.3 多模态与知识推理
未来的投研智能体,将不仅仅是信息的检索和整合者。通过融合知识图谱,RAG系统可以建立起实体之间更深层次的关联,进行复杂的逻辑推理。例如,从“A公司是B公司的供应商”和“B公司发布盈利预警”这两条信息中,推理出“A公司的业绩可能受到负面影响”。结合更强大的多模态能力,智能体将能够实现更复杂的自动化投研任务。
6.4 安全与可扩展性
随着系统接入的数据源越来越多、服务用户越来越广,如何设计一个安全、可靠、易于扩展的分布式系统架构,将是保障RAG智能体长期稳定运行的基石。
总结
从0到1构建一个应用于A股量化投资的RAG智能体,是一项融合了数据工程、自然语言处理、大模型技术与金融领域知识的系统性工程。它始于对多源异构数据的精挑细选与深度处理,依赖于混合检索与重排序等先进技术提供的精准“弹药”,最终通过与大型语言模型的巧妙结合,将冰冷的数据转化为富有洞察力的、可信赖的决策支持。
这个过程的核心,不仅仅是技术的堆砌,更是一种思维范式的转变。它要求我们从过去依赖单一模型“记忆”的模式,转向构建一个动态、开放、可演进的“模型+知识库”生态系统。虽然前路依然有挑战,但可以预见,以RAG为代表的新一代AI技术,必将深刻地改变量化投资领域的生态,将投研人员的智慧与机器的效率以前所未有的方式结合起来,开启智能投研的新篇章。
📢💻 【省心锐评】
RAG不是给大模型打补丁,而是重塑了AI与真实世界数据的交互范式。在金融领域,谁能率先构建起高质量、高时效的专有知识库,谁就掌握了通往下一代智能投研的钥匙。

评论