.png)
%20%E6%8B%B7%E8%B4%9D-rzlu.jpg)

【摘要】探讨在线学习作为大型语言模型智能进化的终极路径。文章超越强化学习与元学习的传统边界,深入解析其核心挑战、架构选择与评估范式变革,为实现更高阶人工智能提供系统性思考。
引言
人工智能领域正处在一个密集的发布周期。OpenAI 在推出其 o1 模型后,紧接着上线了 ChatGPT 的即时支付功能。几乎同时,Anthropic 也发布了号称最强编程模型的 Claude Sonnet 4.5。这些产品的迭代有一个共同的指向,那就是推动模型在复杂、长程任务上的表现,让 AI 更直接、更实时地参与到人类的社会经济活动中。
这背后隐藏着一个根本性的转变。AI 不再仅仅是一个静态的知识库,而是一个需要与真实世界持续交互、不断适应的动态系统。要真正走向通用人工智能(AGI),甚至超级智能(ASI),模型必须突破现有人类知识的边界,学会自主探索和持续进化。
这引出了一个关键问题,如何构建一条更高效的模型进步路径?Online Learning(在线学习),极有可能就是这个问题的答案。
尽管今天 AI 社区对于 Online Learning 的具体定义和实现路径还存在诸多非共识,但它所代表的一种全新交互与推理范式,已经成为一线研究者和顶尖 AI 实验室关注的焦点。它不仅关乎实现极致的个性化,更关乎整个 AI 系统智能的动态迭代。这篇文章将系统性地梳理和讨论 Online Learning 的战略意义、核心概念、技术挑战与未来路径,试图在这场范式之争中,探寻 LLM 智能进化的终极方向。
一、🚀 战略意义:从静态知识库到动态学习体
%20拷贝-upci.jpg)
Online Learning 的价值远不止于让模型“学到最新知识”。它的战略意义在于,它可能从根本上改变 AI 智能的生成和增长方式,甚至带来全新的规模法则(Scaling Law)。
1.1 突破人类知识的边界
当前的大多数模型,其能力上限被牢牢锁定在训练数据所包含的人类知识范围内。它们在已有知识的海洋里循环,却无法创造出真正意义上的新知识。从 AGI 走向 ASI 的本质,恰恰是模型要具备突破人类知识上限的能力。
这就要求模型必须具备强大的自主探索(Exploration)能力。在探索过程中,模型需要能够发现超越人类既有认知的小突破,并且通过自我奖励(Self-rewarding)机制来确认和巩固这些新发现。Online Learning 提供了一个框架,让模型可以在与环境的持续交互中,平衡探索与利用(Exploit),从而逐步实现自主生成新知识。
1.2 开启新的“规模法则”
LLM 的成功很大程度上归功于 Scaling Law,即模型性能随着数据、参数和计算量的增加而可预测地提升。但是,这条路径可能正面临瓶颈。单纯堆积静态数据,带来的边际效益正在递减。
Online Learning 的长期预期,是让模型在执行长程、复杂任务时,展现出一种全新的 Scaling Law。这种新的规模法则,其变量可能不再仅仅是数据量或参数量,而是交互的深度、环境的复杂性或模型在线学习的时间。一个在动态环境中持续学习和适应的模型,其智能增长曲线可能会远超静态训练的模型。
1.3 成为真正的“动态学习体”
从撰写一篇开创性的研究论文,到证明一个复杂的数学定理,人类的高级智能活动无不体现出“在线学习”的特质。研究者需要不断学习新知识、调整研究方向、拆解子问题,并通过探索逐步推进。
未来的 AI 系统也必须具备这种能力。它不应该是一个一次性训练完成、能力固化的“静态知识库”,而应该是一个能够与环境共生、在交互中持续进化的“动态学习体”。
一个更高级的 Online Learning 模式可能是这样,我们给模型一天时间,不指定任何任务,让它自主生成目标、规划学习路径,并在结束时接受测试。这种自我驱动的学习能力,是通往 L4 级别以上智能的关键。
二、🧩 概念边界与技术路径之争
“Online Learning”这个词目前在社区中被广泛使用,但其内涵却相当模糊,常常与 Online RL、Lifelong Learning 等概念混淆。要深入讨论,首先必须厘清这些概念的边界,并理解它们背后的技术路径分歧。
2.1 Lifelong Learning vs. Meta Online Learning
在当下的讨论中,Online Learning 并非一个单一概念,它至少包含了两种不同层次的目标和路径。
Lifelong Learning 更关注“活到老,学到老”。它的目标和手段都相对明确,比如代码助手 Cursor 通过持续收集用户对其补全结果的采纳与否,来不断迭代模型。这里的关键是怎么设计奖励(Reward)和怎么高效收集数据。
Meta Online Learning 的目标则更为宏大,它追求的是“学会学习”的能力,即 Fast Adaptation。它希望模型在接触一个全新任务时,能够通过少量交互就快速掌握要领。这要求模型具备更底层的学习能力,而不仅仅是对特定任务的优化。
2.2 两条并行的技术路径
基于上述两种目标,社区中逐渐浮现出两条并不完全重合的技术实现路径。
直接路径,直接通过在线强化学习(Online RL)和环境交互来实现 Lifelong Learning。这条路更务实,专注于解决特定问题,比如优化一个推荐系统或聊天机器人。
间接但更具潜力的路径,先致力于实现 Meta Learning,让模型具备快速适应的能力,然后再以此为基础,更轻松地实现 Lifelong Learning。
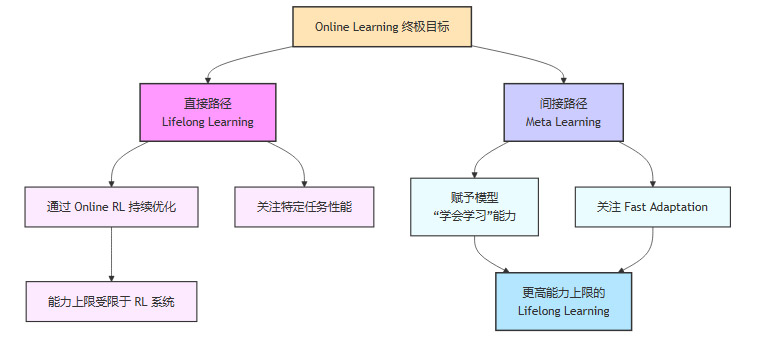
许多研究者认为,Meta Learning 很可能是 Lifelong Learning 的前置条件。一个具备了元学习能力的模型,在进行终身学习时,能够更高效地从数据中汲取知识,更快地适应环境变化,从而拥有更高的能力上限。在 LLM 时代,Meta Learning 的一个重要体现就是 In-context Learning(上下文学习),模型在推理时利用上下文信息快速适应当前任务,这本身就是一种元学习能力的展现。
2.3 Online Learning 不是 Online RL
将 Online Learning 与 Online RL 划等号,是一个普遍存在的误解。这种概念混淆,类似于在“Agent”兴起时,所有能调用 API 的程序都被称为 Agent,这会妨碍领域的健康发展。
简单来说,Online RL 只是实现 Online Learning 的一种可能手段,但并非全部。Online Learning 的范畴更广,它强调的是一种系统在与环境交互中持续改变自身行为的能力。这种改变,可以通过更新模型权重(Training)实现,也可以通过更新记忆、调整上下文等非参数化的方式实现。
Online Learning 的最终目标,是让模型本身拥有强大的 In-context Learning 能力,学习过程由模型自己完成。而 Online RL 的上限在于,系统的更新始终由外部的 RL 框架驱动,其更新频率和对环境的理解深度都受到限制。
三、⚙️ 核心挑战与机制选择
%20拷贝-xbjl.jpg)
要将 Online Learning 从概念变为现实,必须直面两大核心瓶颈,并在不同的学习机制之间做出权衡。
3.1 核心瓶颈:稀疏的奖励与脆弱的环境
Online Learning 的运转极度依赖从环境中获取的奖励(Reward)信号。但现实是,高质量的奖励信号非常稀缺。
简单场景 vs. 复杂场景
在一些简单场景中,奖励是明确且高密度的。比如在 Cursor 的代码补全中,用户采纳或拒绝建议,就是一个清晰、即时的二元反馈。在推荐系统中,用户的点击行为也是有效的反馈。这些场景因此更适合率先应用 Online Learning。但在更复杂的场景中,奖励信号的获取变得异常困难。在通用的 Chatbot 对话中,用户很少有强烈的意愿去提供“点赞”或“点踩”的反馈,即便给了,反馈也往往是模糊和稀疏的。在多步 Agent 任务中,一个最终的成功或失败结果,很难归因到中间的某一个具体步骤,这使得奖励的分配(Credit Assignment)成为巨大难题。
奖励模型(Reward Model)的局限
为了解决奖励稀疏的问题,研究者们提出了奖励模型。但奖励模型本身也存在问题,它只是对人类偏好的一个模拟,其定义的奖励与任务的最终目标之间可能存在偏差(Alignment Gap)。过度优化一个有偏的奖励模型,容易导致学习过程偏离预期方向,甚至被模型“钻空子”(Reward Hacking)。
未来的发展方向,必须是让模型具备自我生成奖励的能力,减少对外部显式、人工设计的奖励的依赖。这可能是实现真正高水平智能的关键一步。
3.2 机制之争:In-context Learning vs. In-weights Learning
当奖励信号到来时,系统该如何“学习”?这里存在两种主流的技术机制选择,它们各有优劣。
从实用主义角度出发,完全依赖 In-weights Learning 来做大规模个性化并不可行。In-context Learning 在商业落地和可解释性上更具优势。
但这两种机制并非完全对立,而是可以结合的。Fast Weights 负责让模型在短时间内快速适应新环境,而 Slow Weights 则为模型提供持久的记忆和能力的稳定提升。
Online Learning 的关键,其实不在于是否更新权重,而在于如何将奖励信号有效地注入模型,并让模型能够理解和使用它。如果模型具备强大的 In-context RL 能力,能够直接在上下文中理解奖励的含义(例如,知道一个负反馈意味着需要调整策略),那么它就不一定需要更新权重。但如果模型“不懂”奖励的含义,那就必须通过 In-weights Learning(如传统的 RL 训练)将这些信息“烧录”到模型参数中。
3.3 被忽视的中间地带:Memory 的作用
在 In-context 和 In-weights 之间,还存在一个重要的、常被忽视的组成部分,那就是 Memory(记忆)。
将 Agent 系统视为一个整体的学习目标,那么 Online Learning 的实现,不一定非要更新模型参数,也可以通过更新外部的 Memory 组件来实现能力提升。
即使模型参数保持不变,随着记忆的不断积累和更新,模型的行为策略(Policy)也会发生变化。这非常类似于人类的学习方式,我们并不会因为参加了一场讨论会就重构自己的神经网络,而是依靠形成的记忆来指导未来的行为。
理想状态下,AI 系统应该拥有自主的上下文工程(Context Engineering)和记忆管理能力。它应该能自己决定哪些信息是重要的、需要长期存取,哪些是暂时的、可以遗忘。
通过为每个用户维护一个独立的 Memory Slot(外部记忆单元),并在每次交互后直接改写这个 Memory,系统可以在不进行昂贵的全参数微调的情况下,实现高效的个性化和持续学习。这比单纯依赖有限的上下文窗口,或进行成本高昂的权重更新,是一条更具实用价值的中间路径。
当然,这条路径也有挑战。如何保证模型在与环境多次交互时,前后计算的连贯性?如果模型只是被动地读取 Memory,而不能根据交互结果主动更新 Memory,那么学习效率依然低下。理想的模式是,模型完成一次交互,根据结果更新 Memory,再依赖更新后的 Memory 进行下一次交互,形成一个高效的学习闭环。
四、🏗️ 架构、算力与工程实践
%20拷贝-htwb.jpg)
理论的先进性最终需要通过工程实践来检验。Online Learning 的落地,对系统架构、算力利用和工程能力都提出了新的要求。
4.1 来自推荐系统的启示:端到端架构的必要性
推荐系统是 Online Learning 的早期实践者,很多系统已经能够实现分钟级的模型更新。然而,它们的实践也揭示了一个深刻的教训,非端到端的系统,Online Learning 的效果会大打折扣。
过去,推荐系统大多采用多模块拼接的架构,例如“召回 -> 粗排 -> 精排”。在这种架构下,用户的最终行为(如点击、购买)只能直接反馈给最后的“精排”模块。前端的“召回”模块,其产出的候选集质量对最终效果至关重要,但它却无法从最终的用户反馈中直接学习,因为它的行为与最终奖励之间缺乏端到端的关联。
这导致了两个问题:
信用分配困难:无法确定最终的好/坏结果,应该归功/归咎于哪个模块。
局部最优:系统很容易在优化某个单一模块时陷入局部最优,难以实现全局性能的持续提升。
LLM 的巨大成功,很大程度上就受益于其端到端的架构。因此,对于未来的 Agent 系统,要想真正实现有效的 Online Learning,端到端架构是实现更高迭代天花板的理想选择。尽管出于商业和工程复杂度的考虑,短期内 Agent 系统可能会模块化,但其核心模块必须力求端到端,以确保学习信号能够顺畅地在整个系统中流动。
4.2 算力挑战:长上下文的陷阱
在实现个性化和持续学习时,一种看似简单的路径是不断扩展模型的上下文长度(Context Length),把所有的历史交互都塞进去。但这条路在算力上可能是一个陷阱。
假设总交互历史有 100 万个 token,每次新交互需要处理 1 万个 token。如果系统只是简单地将新交互拼接到历史交互之后再进行一次完整的推理,那么大量的计算被用于重复处理已经处理过的信息。这些计算彼此独立,并没有对下一次推理产生增益,计算结果也没有被“留存”下来。这造成了巨大的算力浪费。
相比之下,通过 In-weight Learning 或 Memory 更新,让每一次交互的计算结果都能以某种形式被留存下来,从而对后续模型的表现产生影响,是算力效率更高的范式。
不过,也需要认识到,当前 Online Learning 的主要瓶颈可能还不在于 GPU 算力,而在于高质量数据和高保真环境的缺乏。在没有跑通基本流程、没有合适的数据和环境支撑的情况下,过早地进行大规模的 Scaling 是非常危险的。
4.3 工程落地建议
将 Online Learning 应用于实际产品,需要一套系统的工程方法论。
五、📊 评估范式的变革
一个新范式的出现,必然要求一套新的评估方法。传统的基于固定训练集和测试集的评估方式,已无法衡量 Online Learning 系统的真实能力。
5.1 从“最终分数”到“学习斜率”
在 Online Learning 场景下,测试(Testing)本身就包含了训练(Training)的过程。因此,评估的重点不应再是模型在某个静态测试集上的最终分数,而应该是模型在与环境交互过程中的学习速度和进步幅度。
一个理想的测试框架是,将 AI 系统置于一个它从未见过的新环境或新任务中,比如一个新游戏、一个陌生的房间(对于机器人)。然后,观察其性能如何随着交互次数的增加而提升。
在这个过程中,关键的观测指标不是最终它玩得有多好,而是性能提升曲线的斜率。一个陡峭的斜率,意味着系统具备强大的在线学习能力,能够快速适应新环境。这个指标能够量化模型真正的 Online Learning 能力。
5.2 Meta Learning 视角的测试流程
从 Meta Learning 的视角出发,Online Learning 的测试可以设计成如下流程:
交互与适应:让 AI 系统与一个(或一批)用户进行多轮互动。这个互动过程本身就是 Online Learning 的过程。
能力测试:在互动结束后,专门设计任务来测试系统对该用户偏好、习惯或特定任务的理解程度。
形成奖励:根据测试结果,形成对系统“适应能力”的最终奖励。
这个流程的目标,与 Meta Learning 的逻辑高度一致,即检验系统通过少量交互快速适应新需求的能力。
未来的评估体系,必须将交互、适应、奖励设计以及 Memory 的使用方式都重新纳入考量,才能真实地反映一个系统的学习能力。
结论
Online Learning 不仅仅是一种新的训练技术,它更代表了 AI 系统从“被动响应”向“主动服务”、从“静态知识库”向“动态学习体”的根本性范式转变。它关乎 AI 如何与世界交互,如何实现自我进化,是通往更高阶智能的必由之路。
当前,关于其具体定义和最佳实践的“范式之争”仍在继续。无论是 Lifelong Learning 还是 Meta Learning,无论是 In-context 还是 In-weights,这些路径和机制的选择,都指向一个共同的目标,即构建一个能够在与环境的持续交互中不断变强的智能系统。
要实现这一目标,依赖于高质量的反馈信号、合理的奖励机制、端到端的系统架构、高效的记忆管理和全新的评估体系。短期内,从代码补全、推荐系统等高密度反馈场景和端到端架构切入,是务实的选择。中长期,则需要通过提升模型的元学习和自我奖励能力,来追求更高的智能上限和通用性。
随着 OpenAI、Anthropic 等公司的前沿实践不断推进,Online Learning 的轮廓正变得日益清晰。这场关于 LLM 智能进化终极路径的探索,才刚刚开始。
📢💻 【省心锐评】
Online Learning 的本质,是让模型从一个封闭的“计算器”变成一个开放的“学习者”。别再纠结于更新频率,真正的突破在于系统能否在交互中,自主地、高效地完成“观察-归因-决策-迭代”的闭环。

评论