.png)


【摘要】 探讨了结合SNARK/STARK证明系统与可撤回隐私设计的零知识技术栈。文章分析了不同证明系统的技术权衡,详述了通过递归与组合策略优化性能的工程实践,并阐述了如何构建选择性披露与审计通道,以在强隐私保护和现实合规需求之间取得平衡,为隐私计算的规模化应用提供可行路径。
引言
在数字世界里,隐私与透明似乎是一对永恒的博弈对手。我们渴望交易的隐秘性与数据的自主权,但现实世界的商业与法律框架又要求某种程度的可见性与可追溯性。传统的隐私方案往往走向极端,要么是彻底的匿名黑箱,要么是完全的公开透明,两者都难以适应复杂的现实需求。零知识证明(Zero-Knowledge Proofs, ZKP)技术的成熟,为我们打破这种二元对立提供了可能。
ZKP允许一方(证明者)向另一方(验证者)证明某个论断为真,却不泄露任何超出“该论断为真”之外的额外信息。这听起来像魔法,但它已成为构建下一代隐私保护系统的基石。然而,单一的ZKP技术并非万能药。不同的证明系统,如SNARK和STARK,在效率、安全性与信任假设上各有取舍。更重要的是,纯粹的技术性隐私可能会与金融合规、数据监管等现实需求产生冲突。
因此,一个真正可落地、可扩展的隐私解决方案,必须是一个精心设计的“技术栈”。这个栈不仅要选择最优的密码学工具,更要构建一套灵活的治理框架。它需要在默认情况下提供坚不可摧的隐私保护,又能在特定、授权的条件下,如同一扇精巧的窗,向合规方选择性地“撤回”隐私,展示必要的信息。本文将深入剖析这个零知识隐私栈的核心构成,探讨SNARK与STARK的组合艺术,以及如何设计一套稳健的可撤回与选择性披露机制,最终在隐私的理想国与合规的现实世界之间,架起一座坚实的桥梁。
一、⚔️ 技术架构的权衡:SNARK与STARK的博弈与融合 ⚔️
%20拷贝-cixa.jpg)
构建零知识隐私栈的第一步,是选择合适的证明系统。这就像为一栋大厦选择承重结构,不同的选择决定了它的成本、性能与安全性。当前,zk-SNARK和zk-STARK是两条主流的技术路线,它们之间的差异与权衡,是每个系统设计者必须面对的核心问题。
1.1 两大流派的核心特征与挑战
理解SNARK和STARK,需要从它们各自的核心优势与固有的挑战入手。它们的设计哲学截然不同,导致了在应用层面的巨大差异。
1.1.1 zk-SNARK:为简洁而生
zk-SNARK全称为“简洁非交互式知识论证”(Zero-Knowledge Succinct Non-Interactive Argument of Knowledge)。它的名字已经点明了其最大特点,“简洁”(Succinct)。
极致的证明大小。一个SNARK证明可以小到几百字节。这在区块链这类对存储和带宽极度敏感的环境中是巨大的优势。更小的证明意味着更低的链上存储成本和更少的Gas消耗,对于高频交易或移动端应用场景尤其重要。
飞快的验证速度。SNARK的验证过程通常只需要几毫秒,这使得链上智能合约或轻客户端能够快速确认证明的有效性,降低了计算延迟。
但是,这种极致的简洁性并非没有代价。
可信设置的阴影。大多数经典的SNARK协议,如应用最广的Groth16,依赖于一个“可信设置”(Trusted Setup)过程。这个过程会生成一套公共参考字符串(Common Reference String, CRS),用于证明生成和验证。在此过程中会产生一些被称为“有毒废物”(Toxic Waste)的秘密参数。如果这些秘密参数被泄露,攻击者将能够伪造任何证明,从而摧毁整个系统的安全性。虽然可以通过多方安全计算(MPC)仪式来分散风险,但信任假设的根源依然存在。
量子计算的威胁。SNARK的安全性通常基于椭圆曲线配对(Elliptic Curve Pairings)的困难问题。这些问题在理论上可以被未来的量子计算机破解,因此SNARK不具备后量子安全性。
通用性的限制。一些SNARK协议的CRS是与特定计算(电路)绑定的。这意味着每次程序逻辑变更,都需要重新进行一次昂贵且复杂的可信设置。不过,像PLONK和Halo2这样的新型协议引入了通用或可更新的设置(Universal or Updatable SRS),大大缓解了这个问题,降低了开发和运维的门槛。
1.1.2 zk-STARK:为透明与安全而战
zk-STARK,即“可扩展透明知识论证”(Scalable Transparent Argument of Knowledge),则走向了另一条道路,它将**“透明性”(Transparent)和“可扩展性”(Scalable)**放在了首位。
无需可信设置。这是STARK最引人注目的优势。它完全依赖于公开可验证的随机性(通过哈希函数生成),从根本上消除了“有毒废物”和信任假设。这使得系统更加去中心化,也更符合区块链的无信任精神。
后量子安全性。STARK的安全性基于抗碰撞的哈希函数(Collision-Resistant Hash Functions)。目前,这类函数被认为是能够抵御量子计算机攻击的,为系统提供了更长远的安全性保障。
优越的可扩展性。对于非常大规模的计算,STARK的性能表现更优。其证明生成和验证时间的增长,相较于计算规模,呈现出更温和的多对数关系(polylogarithmic)。这使得它特别适合处理批量交易、大规模数据处理等链下计算场景。
当然,STARK的优势也伴随着一些现实的挑战。
庞大的证明体积。STARK证明的大小通常要大得多,可以达到几十甚至几百KB。这在链上环境中是一个显著的缺点。巨大的证明体积直接转化为高昂的Gas费用和存储成本,限制了其在资源受限场景下的直接应用。
1.2 技术选型的深度权衡
选择SNARK还是STARK,不是一个简单的“谁更好”的问题,而是一个基于具体场景需求的复杂权衡。我们可以通过一个表格来直观地对比它们的核心特性。
这个表格清晰地揭示了,SNARK像是为链上效率“特化”的利器,而STARK则是为链下计算规模和未来安全“定制”的重盾。
1.3 🚀 组合与递归:鱼与熊掌兼得的工程艺术
既然SNARK和STARK各有千秋,那么一个自然而然的想法是,我们能否将它们组合起来,取长补短?答案是肯定的,而实现这一点的关键技术就是递归证明(Recursive Proofs)。
递归证明允许一个零知识证明去“证明”另一个证明的正确性。这就像一个无限套娃,为我们提供了极大的灵活性。
1.3.1 混合递归架构:“STARK-in-a-SNARK”
这是目前最流行和最强大的组合策略之一,其核心思想是:用STARK处理计算,用SNARK压缩证明。整个流程如下:
链下大规模计算与STARK证明。首先,在链下(off-chain)服务器集群中执行大量的、复杂的计算任务,比如处理数千笔交易或运行一个复杂的机器学习模型。针对这些计算,生成一个STARK证明。这个证明体积很大,但不影响,因为它还不需要上链。
链下STARK验证与SNARK证明。接着,在链下运行一个STARK验证器程序,这个程序的作用是验证上一步生成的STARK证明是否有效。关键在于,我们将这个“验证STARK证明”的过程本身,也作为一个计算任务,并为之生成一个SNARK证明。
链上SNARK验证。最后,我们只需要将这个小巧的SNARK证明提交到区块链上。链上智能合约只需验证这个SNARK证明。如果SNARK证明有效,就等价于间接确认了那个庞大的STARK证明是有效的,进而确认了最初的大规模链下计算是正确的。
这种“STARK-in-a-SNARK”的递归封装,巧妙地结合了两者的优点。
我们享受了STARK处理大规模计算的可扩展性和无需可信设置的安全性。
我们利用了SNARK证明体积小、验证快的优势,极大地降低了与区块链交互的成本。
许多知名的以太坊Layer 2扩容方案,如StarkNet(早期版本)和Polygon Hermez,都采用了类似的思想来平衡性能与成本。
1.3.2 选型原则的实践指南
在实际工程中,选择何种策略或组合,可以遵循以下决策路径。
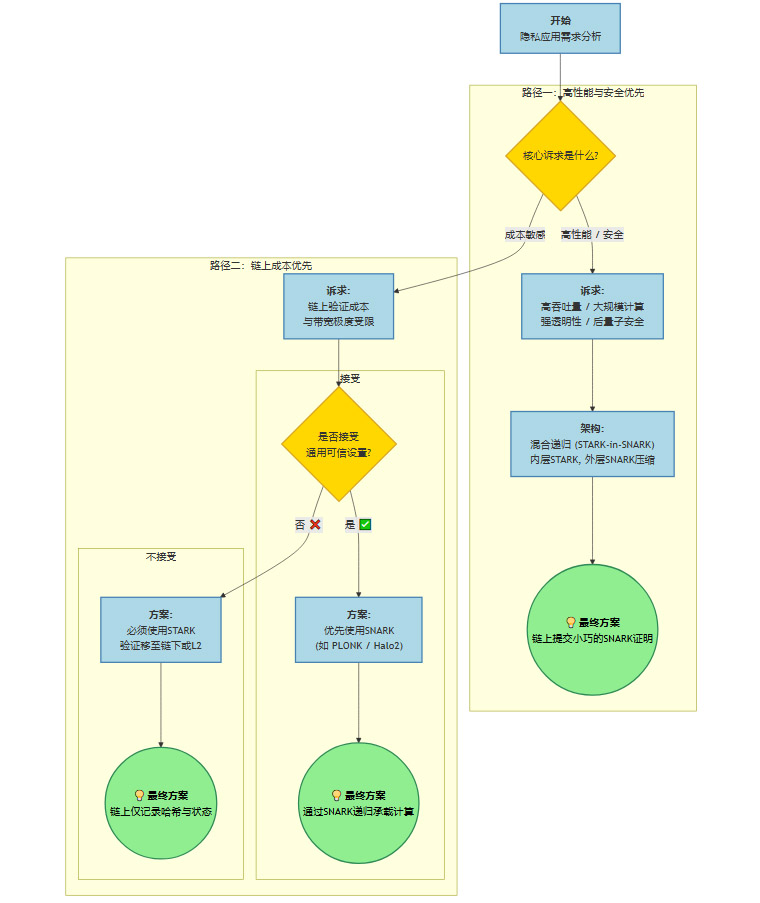
这个流程图展示了,技术选型不是一次性的静态决策,而是一个动态的、与业务需求紧密耦合的过程。
1.4 🛠️ 从理论到落地:工程化的挑战
将这些密码学理论转化为稳定、高效的生产系统,还需要克服一系列工程挑战。
计算的“翻译”工作。业务逻辑需要被转换成ZKP系统能够理解的数学形式。对于SNARK,这通常是**R1CS(Rank-1 Constraint System)或类似的电路表示。对于STARK,则是AIR(Algebraic Intermediate Representation)**和执行轨迹(Execution Trace)。这两种范式有很大差异,开发者需要为不同的证明系统学习不同的抽象方式,开发成本较高。
证明生成与聚合的流水线。在链下,需要构建一套高效的证明生成系统。这通常涉及将大量的交易或计算任务进行批量处理(Batching),用STARK生成一个聚合证明。然后,再通过递归封装,最终生成一个适合提交到链上的SNARK证明。这个过程需要精细的资源调度和错误处理。
链上与跨链的优化。即使是小巧的SNARK证明,在以太坊这样拥堵的公链上,Gas成本依然不可忽视。因此,需要对链上验证合约进行极致的优化。同时,随着多链生态的发展,如何安全、高效地在不同链之间传递和验证ZKP,也成为一个新的研究方向。
总而言之,选择并组合SNARK与STARK,是一门充满权衡的艺术。它要求我们不仅理解密码学原理的深度,还要洞察业务场景的广度,最终在性能、成本、安全和去中心化之间,找到那个精妙的平衡点。
二、🔍 可撤回设计:在隐私黑箱上开一扇合规的窗 🔍
我们已经探讨了如何用SNARK和STARK构建一个坚固的隐私“地基”。但一个纯粹封闭的、无法与现实世界规则互动的隐私系统,注定只能是空中楼阁。真正的挑战在于,如何在不破坏隐私核心的前提下,建立一个受控的、可审计的通道,以满足合规、监管和协作的需求。这就是“可撤回设计”(Revocable Design)的用武之地。
需要强调的是,这里的**“可撤回”并非指撤销一笔已经发生的交易,而是指在特定、授权的条件下,有选择性地“撤回”交易的隐私保护层**,使其对特定方透明。它是在绝对隐私和完全透明之间,开辟了一个精细调控的中间地带。
2.1 选择性披露与审计:只说必要的话
零知识证明的魅力不仅在于“隐藏”,更在于“证明”。它可以被设计用来证明某个复杂陈述中的特定属性,而无需暴露陈述的全部内容。这为选择性披露提供了强大的技术基础。
属性证明,而非数据暴露。假设一个去中心化借贷协议需要验证借款人的信用状况。传统方式下,借款人需要提交完整的财务报表。但在零知识栈中,借款人可以生成一个ZKP,证明“我的资产负债率低于30%”或“我的收入来源符合反洗钱(AML)规定”,而无需透露具体的资产数额、负债细节或收入来源。监管方或协议方验证这个证明即可,整个过程实现了合规验证,但未发生敏感数据泄露。披露的粒度可以根据政策需求进行精细定制。
聚合审计,而非逐笔审查。在财务审计场景中,一个更高级的应用是聚合审计。账本上的每一笔交易和用户余额都可以通过密码学承诺(Cryptographic Commitment,如Pedersen Commitment)进行隐藏。一个承诺就像一个上了锁的保险箱,你无法看到里面的东西,但可以验证箱子里的东西没有被篡改。审计方可以要求系统生成一个ZKP,证明“所有账户承诺的总和等于银行公开声明的总储备金”,或者“过去24小时内所有交易承诺的方差在正常范围内”。这种方式实现了“指标可证、明细不泄”,既满足了审计目的,又保护了每个用户的交易隐私。
2.2 可撤回机制的三重境界
为了实现上述选择性披露,系统需要一套明确的机制来管理隐私的“撤回”权限。这套机制通常被设计成一个分层、渐进的体系,遵循最小权限原则,确保每一次隐私揭示都是必要且可控的。
2.2.1 软撤回:用户授权的只读视图
这是最基础、最常见的一种隐私撤回方式,其控制权主要掌握在用户手中。
核心机制。系统可以为用户的加密数据设计一个“查看密钥”(Viewing Key)。这个密钥独立于用户管理资金的私钥,它只具备解密和读取相关交易数据的权限,无法动用资产。当用户需要向第三方(如会计师、审计员)披露自己的账务时,可以主动分享这个查看密钥。
增强设计。为了防止查看密钥被滥用,可以引入更复杂的设计。例如,使用门限密钥(Threshold Key),需要多个参与方(如用户本人、合规官、受托人)共同协作,才能生成一个临时的、有时效性的查看权限。所有通过查看密钥进行的读取操作,其事件哈希都将被记录在链上,形成不可篡改的审计日志。这确保了每一次信息披露都是双方同意且全程留痕的。
2.2.2 渐进式撤回:层层深入的调查路径
对于更复杂的合规调查场景,一次性的完全披露可能是不必要的,甚至是有害的。渐进式撤回为此设计了一条逐级深入的信息披露路径。
这个过程可以用下面的流程图来清晰地展示。
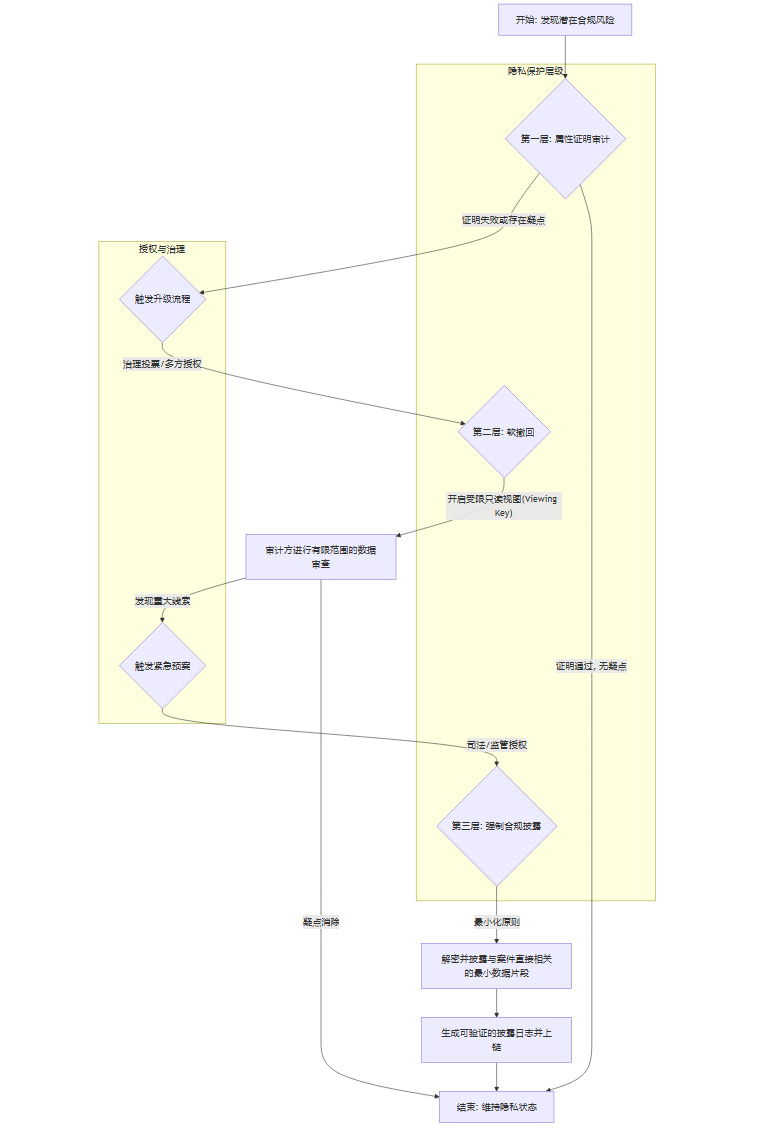
这个流程确保了调查总是从侵入性最小的方式开始。只有在前一级别的审查发现确凿疑点,并通过严格的治理程序授权后,才能进入下一级别的披露。这极大地防止了权限滥用,保护了绝大多数无辜用户的隐私。
2.2.3 强制合规:司法框架下的“红线”机制
在极端情况下,如涉及重大金融犯罪或国家安全威胁,系统需要一个机制来响应合法的司法或监管指令。这通常是隐私技术中最具争议、也最难设计的部分。
一个稳健的设计需要平衡合规义务与防止滥用的需求。
最小可行揭示。即使在强制披露的情况下,也应遵循**“最小可行揭示”(Minimal Viable Disclosure)**原则。系统不应全盘托出用户的所有数据,而应设计成只能解密与特定案件、特定时间范围、特定地址相关的最小化数据片段。
强治理与可追责。触发强制披露的权限绝不能掌握在任何单一实体手中。它必须通过一个去中心化的、多机构参与的门限治理框架来控制。例如,一个解密请求可能需要同时获得法院、监管机构和系统治理委员会中多个独立成员的签名才能执行。
透明的审计日志。每一次强制披露操作,都必须生成一份详细、可公开验证的审计日志,记录操作的发起者、授权者、披露的数据范围摘要以及时间戳。这份日志将被永久记录在链上,确保每一次“破例”都在阳光下进行,有据可查,有责可追。
2.3 合规与治理:将规则写入代码
上述技术机制的有效性,最终依赖于一个强大的治理框架。零知识隐私栈通过将合规规则与治理流程代码化,实现了前所未有的自动化与透明度。
合规即代码(Compliance-as-Code)。利用智能合约和ZKP,可以将复杂的KYC/AML规则(如“用户必须来自非制裁国家”、“单笔交易额不能超过1万美元”)转化为可被机器验证的数学电路。新用户加入或进行交易时,系统可以自动要求其提交一个ZKP来证明自己符合这些规则,实现实时、自动化的合规校验,而无需人工审核敏感信息。这形成了一座连接传统金融世界与加密世界的“合规桥梁”。
门限密钥的治理艺术。控制信息披露的“钥匙”(如查看密钥的生成权限)必须被妥善保管。最佳实践是采用多方门限签名方案(Threshold Signature Scheme, TSS)。例如,一个
m-of-n的门限方案意味着,在n个独立的密钥持有者(可以是机构或个人)中,必须至少有m个合作签名,才能执行某个敏感操作。这从密码学层面保证了权力的分散,防止了单点故障和恶意行为。
通过这套精心设计的分层机制与治理框架,零知识隐私栈成功地回答了那个棘手的问题:如何在拥抱未来的同时,与现在共存。它既为用户提供了坚实的隐私盾牌,也为合规世界保留了一扇必要时可以打开的窗,一扇有严格开启程序、且每一次开启都会被记录在案的窗。
三、🌐 应用场景与未来趋势:隐私栈的星辰大海 🌐
%20拷贝-apmr.jpg)
一个强大的技术栈,其价值最终体现在它能解决多少现实问题,以及它为未来开辟了多大的想象空间。集成了SNARK/STARK组合策略与可撤回设计的零知识隐私栈,正从理论的象牙塔走向广泛的实际应用,其影响力远远超出了加密货币的范畴。
3.1 金融合规:在透明与隐私间跳舞
金融行业是受监管最严格的领域之一,也是对隐私和效率需求最高的行业之一。零知识隐私栈恰好能满足这种看似矛盾的需求,成为推动DeFi(去中心化金融)走向主流,以及改造传统金融(TradFi)基础设施的关键技术。
偿付能力证明(Proof of Solvency)。加密货币交易所或银行等金融机构,可以定期使用ZKP向公众或监管机构证明其储备金充足,能够覆盖所有用户负债。它们可以生成一个证明,证实“所有用户存款承诺的总和小于我们公开地址上的资产总额”,而无需透露任何单个用户的余额或机构自身的详细账目。这在提升市场信心的同时,完美保护了商业机密和客户隐私。
隐私交易与合规审计。在支持隐私交易的区块链(如Zcash)或Layer 2网络上,用户可以享受匿名的转账服务。同时,借助我们前文讨论的可撤回设计,用户可以在需要时向税务机关提供其交易历史的只读视图,以完成税务申报。监管机构也可以在获得合法授权后,对可疑交易链条进行穿透式审计,追踪非法资金流动,实现了隐私保护与反洗钱(AML)、反恐怖主义融资(CTF)要求的兼容。
去中心化信用评分。用户可以整合自己在不同平台(链上和链下)的数据,生成一个ZKP来证明自己的信用评分高于某一阈值,或者满足特定贷款的风控要求。这使得用户在申请金融服务时,只需证明自己“合格”,而无需交出所有个人数据的主权,为构建更公平、更保护隐私的信用体系铺平了道路。
3.2 数据主权与跨境流通:解锁数据金矿
在数据成为新石油的时代,如何在利用数据价值的同时保护个人隐私和数据主权,是一个全球性的难题。零知识隐私栈为此提供了一种全新的范式——“可用不可见”。
可信数据空间(Trusted Data Spaces)。不同企业或国家之间可以在不共享原始数据的情况下,进行联合数据分析或模型训练。例如,多家医院可以共同训练一个AI医疗诊断模型。每家医院只需提交关于其本地数据满足模型训练算法特定步骤的ZKP,而无需将敏感的病人病历传输到中央服务器。这既保护了病人隐私,又打破了数据孤岛,促进了协作创新。
合规的跨境数据流动。随着GDPR等数据保护法规日益严格,跨境数据传输面临巨大挑战。利用ZKP,一家公司可以向海外监管机构证明其处理的数据“已获得用户同意”且“处理方式符合当地法规”,而无需将数据本身传输出境。这为构建安全、合规的全球数据网络提供了技术基础。
3.3 去中心化身份(DID)与Web3应用:重塑数字自我
零知识证明是实现真正去中心化身份的核心组件。它让用户能够自主控制自己的身份信息,并以最小化披露的方式与世界互动。
身份认证与访问控制。用户可以向网站或应用证明“我已成年”、“我是某大学的学生”或“我持有某项资格证书”,而无需透露自己的出生日期、姓名或身份证号码。这种基于选择性属性披露的登录方式,极大地减少了个人信息的泄露风险。
隐私投票与链上治理。在去中心化自治组织(DAO)中,成员可以使用ZKP来证明自己“拥有投票资格”并投下有效的一票,但投票内容本身保持匿名。这既保证了投票过程的公平、可验证,又保护了投票者的隐私,避免了因投票立场而可能遭受的压力或报复。
Web3游戏与社交。在链游中,玩家可以证明自己拥有某个稀有道具,但无需暴露自己的钱包地址,防止被别有用心者盯上。在去中心化社交网络中,用户可以证明自己属于某个特定社群(例如,某个NFT项目的持有者),才能访问专属频道,同时保持匿名身份。
3.4 未来趋势:更快、更易用、更智能
零知识隐私栈的技术边界仍在不断拓展,未来的发展将主要集中在以下几个方向。
未来,我们或许能看到,生成一个复杂的ZKP证明就像今天进行一次API调用一样简单快捷。开发者将能使用自己熟悉的语言,轻松地将隐私保护功能集成到任何应用中。零知识证明将不再是少数密码学专家的“黑魔法”,而是每个软件工程师工具箱里的标准组件。
总结
我们从SNARK与STARK的技术权衡出发,走过了一条从底层密码学选择,到上层架构设计,再到具体应用场景的探索之旅。零知识隐私栈的核心思想,在于**“组合”与“平衡”**。
它通过SNARK与STARK的灵活组合与递归,在链上效率与链下可扩展性之间找到了工程上的甜点。这不仅仅是两种技术的简单拼接,而是一种深刻理解各自优劣后,进行系统性优化的设计哲学。
它通过设计精巧的可撤回与选择性披露机制,在绝对的隐私保护与现实的合规需求之间架起了一座桥梁。这让隐私技术不再是游离于主流社会规则之外的“法外之地”,而是能够融入并赋能现有体系的建设性力量。
这个技术栈并非一个僵化的模板,而是一个持续演进的、适应性强的框架。面对不同的业务需求、性能瓶颈和安全考量,设计者需要像一位经验丰富的建筑师,精心挑选材料、优化结构,最终构建出既坚固又美观的隐私大厦。随着相关技术的不断成熟和标准化,零知识隐私栈必将成为构建下一代可信互联网的基石,为数字世界带来更深层次的隐私、安全与公平。
📢💻 【省心锐评】
抛开“不可能三角”的迷思,ZKP组合拳与可控披露,不是妥协,而是隐私技术走向成熟、拥抱现实的成年礼。

评论