.png)


【摘要】阿里通义千问开源两款4B小模型,兼顾端侧部署与卓越性能,推理与Agent能力超越同级别闭源模型,推动AI端侧智能化进程。
引言
在AI模型参数规模不断膨胀的今天,业界对于“小而强”的模型需求愈发迫切。2025年8月7日,阿里通义千问(Qwen)团队正式发布了两款4B参数量级的小模型——Qwen3-4B-Instruct-2507与Qwen3-4B-Thinking-2507。这一举措不仅为端侧设备带来了更高效的AI能力,也在模型性能上实现了对同级别闭源模型的超越。本文将围绕这两款模型的技术创新、性能表现、应用场景、行业意义等多个维度,深入剖析小模型在AI端侧落地中的价值与未来趋势。
一、🌟 小模型大突破:技术创新与产品定位
%20拷贝.jpg)
1.1 端侧友好,性能不妥协
1.1.1 轻量化设计,适配多样硬件
Qwen3-4B-Instruct-2507与Qwen3-4B-Thinking-2507均采用4B参数量级,模型体积小巧,极易部署于手机、笔记本等端侧设备。相比动辄数十亿、上百亿参数的大模型,这两款小模型在硬件资源受限的环境下依然能够高效运行,极大降低了AI应用的门槛。
1.1.2 超长上下文,支持复杂任务
两款模型均支持256K超长上下文窗口,能够处理长文档、复杂内容生成、跨段落推理等任务。这一能力在同级别小模型中极为罕见,为端侧AI应用带来了前所未有的灵活性和实用性。
1.1.3 开源开放,生态共建
Qwen3-4B系列模型已在魔搭社区与Hugging Face同步开源,开发者可自由下载、部署与二次开发。这一开放策略不仅加速了模型的普及,也为AI生态注入了新的活力。
1.2 产品定位:Instruct与Thinking双擎驱动
1.2.1 Qwen3-4B-Instruct-2507:全能型“小专家”
知识、推理、编程、对齐、Agent能力全面领先,在多项通用任务上超越同级别闭源模型GPT-4.1-nano,性能接近中等规模的Qwen3-30B-A3B(non-thinking)。
多语言长尾知识覆盖,主观与开放性任务对齐性更强,能提供更贴合实际需求的答复。
适合内容创作、工具调用等场景,是高效的执行专家。
1.2.2 Qwen3-4B-Thinking-2507:推理能力新标杆
推理能力媲美中等模型,在AIME25数学能力测评中以4B参数量取得81.3分高分,表现突出。
Agent能力超越更大尺寸模型,在BFCL-v3等评测中成绩优异。
适合复杂问题的逐步推理和深入分析,是严谨的学术专家。
二、📊 性能实测:小模型的“大能量”
2.1 基准测试全景对比
为全面评估Qwen3-4B系列模型的性能,本文选取了GPQA、AIME25、LiveCodeBench v6、Arena-Hard v2、BFCL-v3等主流基准测试,涵盖知识、推理、编程、对齐、Agent等多维度能力。
2.1.1 各模型基准测试成绩一览
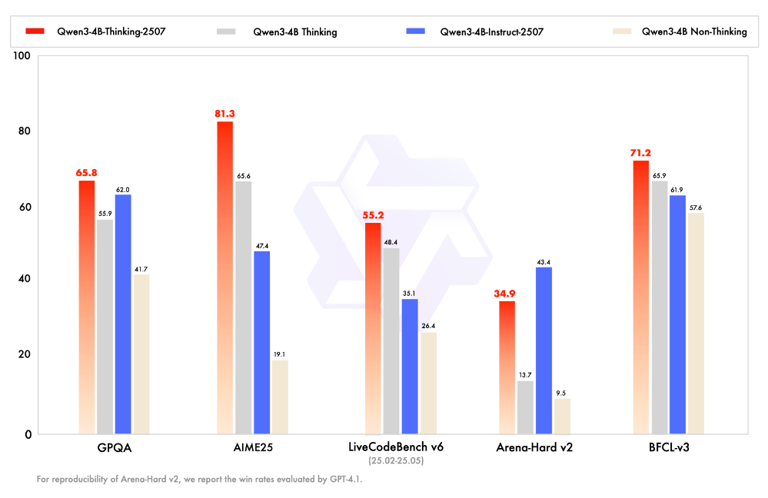
2.1.2 结论简述
Qwen3-4B-Thinking-2507在大多数基准测试中表现最好,尤其是在AIME25和BFCL-v3上优势明显。
Qwen3-4B Thinking整体表现也较好,部分基准(如Arena-Hard v2)得分最高。
Qwen3-4B-Instruct-2507和Qwen3-4B Non-Thinking整体表现略逊一筹,尤其是在AIME25和Arena-Hard v2上分数较低。
2.2 细分能力表现:Instruct与Thinking各擅胜场
2.2.1 Qwen3-4B-Instruct-2507能力分布
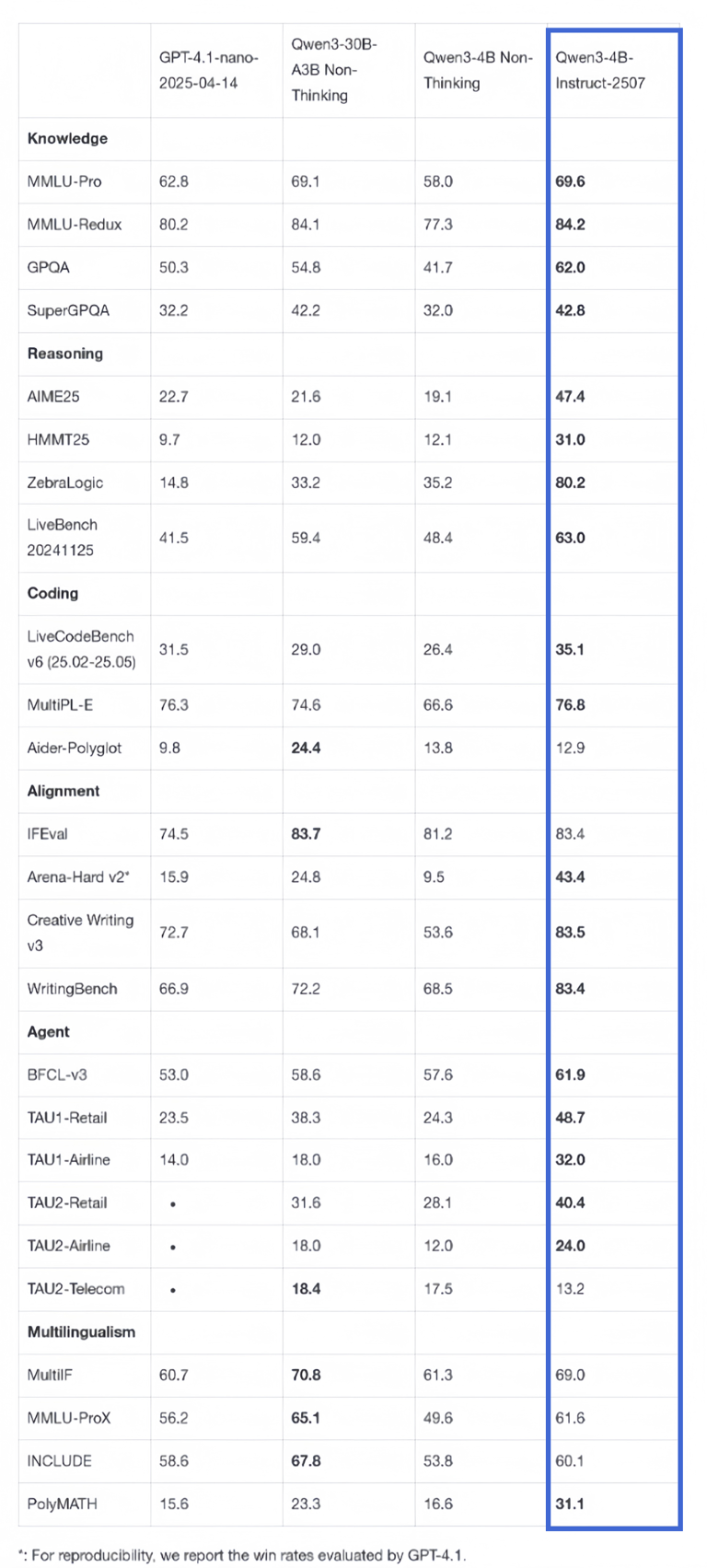
结论简述:
在大多数知识、推理、对齐、Agent、多语言等任务上表现优异,部分分数甚至超过了同类或更大参数量的模型。
在推理、对齐、多语言等任务上,分数普遍较高,显示出较强的综合能力。
在编程任务中的Aider-Polyglot得分相对较低,说明在多语言编程方面还有提升空间。
2.2.2 Qwen3-4B-Thinking-2507能力分布
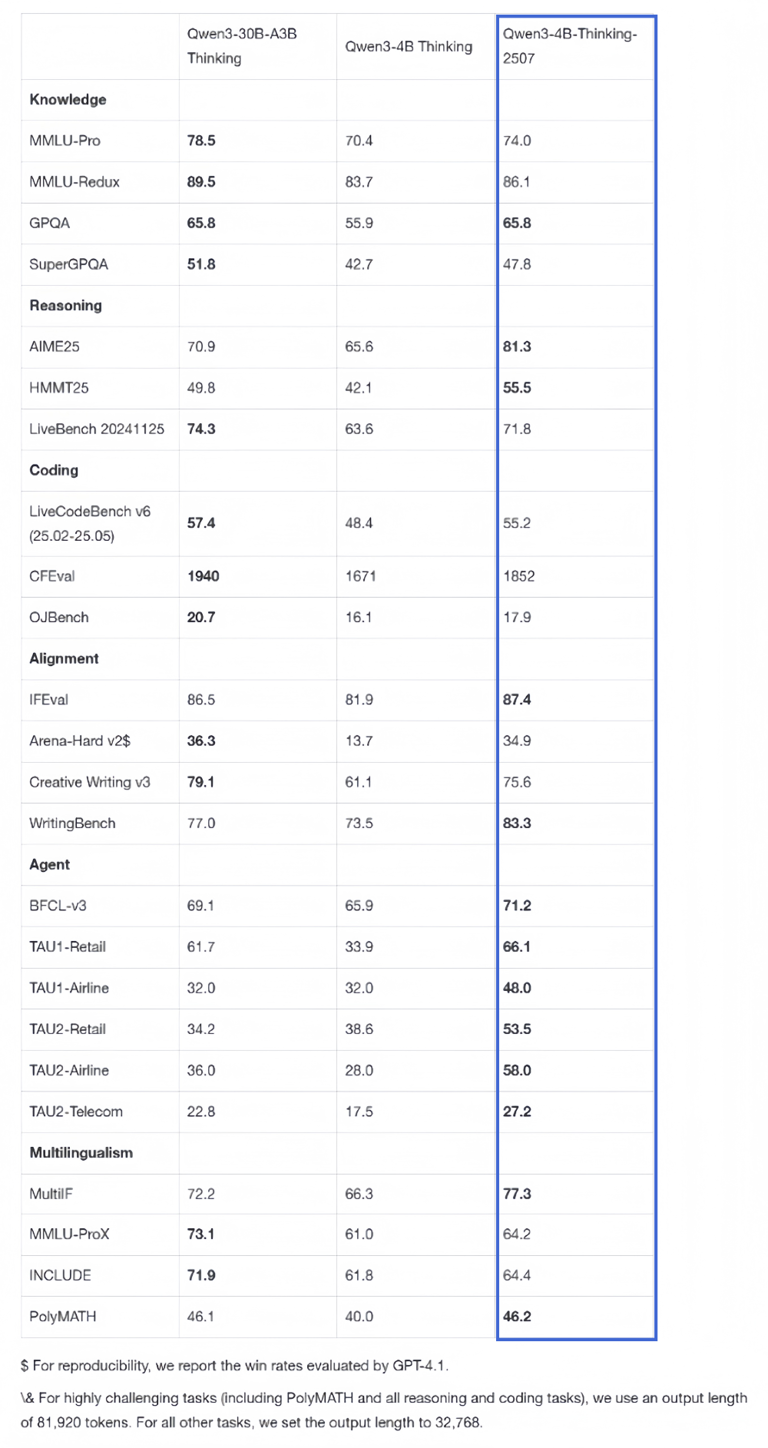
结论简述:
在大多数知识、推理、对齐、Agent、多语言等任务上表现优异,尤其在推理(AIME25、HMMT25、LiveBench)、对齐(IFEval、WritingBench)、Agent(BFCL-v3、TAU1/2系列)、多语言(MultiIF)等任务上分数较高。
在编程任务中的CFEval得分极高(1852),但OJBench得分相对较低,说明在部分编程任务上仍有提升空间。
综合来看,Qwen3-4B-Thinking-2507在同参数量模型中表现突出,尤其在推理和多语言能力上有明显优势。
2.3 关键能力对比与行业意义
2.3.1 推理与Agent能力的跃升
Qwen3-4B-Thinking-2507在推理能力上实现了对中等规模模型的逼近,AIME25测评高达81.3分,远超同级别模型。Agent能力方面,BFCL-v3等评测成绩也优于更大尺寸模型,显示出小模型在智能体场景下的巨大潜力。
2.3.2 通用能力与多语言支持
Qwen3-4B-Instruct-2507在知识、推理、编程、对齐、Agent等多项能力上全面领先,尤其在多语言任务中表现突出,能够覆盖更多语言的长尾知识,满足全球化应用需求。
2.3.3 端侧部署的现实意义
小模型的轻量化设计,使其能够在手机、PC等端侧设备高效运行,推动AI技术从云端向终端的普及。这不仅提升了用户体验,也为数据隐私与本地智能提供了坚实基础。
三、🧩 应用场景与生态价值
%20拷贝.jpg)
3.1 端侧智能的多元应用
3.1.1 移动设备上的AI助手
Qwen3-4B系列模型可在手机、平板等移动设备上流畅运行,实现智能助手、语音交互、实时翻译等功能,极大提升了移动端AI体验。
3.1.2 PC与IoT设备的智能升级
在笔记本、台式机、智能家居等IoT设备中,Qwen3-4B模型能够为本地应用提供强大的自然语言理解与生成能力,助力智能办公、家庭自动化等场景。
3.1.3 行业专用智能体
结合行业知识与定制化需求,Qwen3-4B模型可用于医疗、金融、教育等领域的专用智能体开发,实现自动问答、智能推荐、数据分析等高价值应用。
3.2 开源生态的推动力
3.2.1 开发者友好,创新加速
开源策略为开发者提供了丰富的模型资源与技术支持,降低了AI创新的门槛,促进了社区协作与知识共享。
3.2.2 生态共建,产业升级
Qwen3-4B模型的开源不仅推动了AI技术的普及,也为产业链上下游带来了新的机遇,助力AI产业生态的健康发展。
四、🔬 技术细节与创新亮点
4.1 架构优化与训练策略
4.1.1 高效参数利用
通过精细化的参数分配与结构优化,Qwen3-4B系列模型在有限参数量下实现了更高的表达能力与泛化能力。
4.1.2 多任务协同训练
模型在训练过程中引入多任务学习机制,兼顾知识、推理、编程、对齐等多维度能力,提升了模型的通用性与适应性。
4.1.3 长文本处理能力
256K超长上下文窗口的支持,使模型能够处理复杂文档、长篇内容生成与跨段落推理,满足实际应用中的多样需求。
4.2 性能优化与端侧适配
4.2.1 量化与剪枝技术
采用先进的模型量化与剪枝技术,进一步压缩模型体积,降低计算资源消耗,提升端侧部署效率。
4.2.2 硬件兼容性优化
针对主流移动芯片与PC平台进行深度适配,确保模型在不同硬件环境下均能高效运行,保障用户体验。
五、🌍 行业趋势与未来展望
%20拷贝.jpg)
5.1 小模型浪潮下的AI创新
5.1.1 SLM(Small Language Model)崛起
随着AI应用场景的多元化,小型语言模型(SLM)因其高效、低成本、易部署等优势,正成为行业新宠。Qwen3-4B系列的发布,正是这一趋势的有力注脚。
5.1.2 Agentic AI的加速发展
小模型在Agent能力上的突破,为Agentic AI的发展提供了坚实基础。无论是智能助手、自动化工具,还是行业专用智能体,小模型都展现出强大的生命力。
5.2 开源与普及的双轮驱动
5.2.1 开源推动技术进步
开源不仅加速了技术创新,也促进了知识共享与社区协作,为AI产业的可持续发展注入了新动能。
5.2.2 普及加速智能化落地
小模型的普及将推动AI技术在端侧设备的渗透,带来更多轻量化、场景化的智能应用,助力智能社会的到来。
结论
阿里通义千问Qwen3-4B-Instruct-2507与Qwen3-4B-Thinking-2507的发布,标志着小尺寸模型在通用能力和推理能力上已实现对同级别闭源模型的超越,部分能力甚至逼近中大规模模型。随着这类高性能小模型的开源与普及,AI技术将在端侧设备加速落地,推动更多轻量化、场景化的智能应用创新。未来,随着技术的不断进步与生态的持续完善,小模型将在AI产业中扮演越来越重要的角色,成为智能社会的基石。
📢💻 【省心锐评】
小模型大能量,端侧智能新纪元,AI普及再提速。

评论