.png)


【摘要】一项名为Repair-R1的突破性研究,通过“先测试后修复”的创新范式,利用强化学习教会AI像医生一样诊断代码病因,显著提升了自动化程序修复的成功率与智能化水平,推动AI编程助手进入“理解优先”的新时代。

引言
想象一下,你是一位经验丰富的医生,面对一个症状复杂的病人。传统的治疗方式可能是直接根据最明显的症状开药,期待药到病除。但是,一位真正高明的医生,会先安排一次全面体检,通过各种仪器和化验单,深挖病灶,找出真正的病根,然后再对症下药。这样的治疗,效果无疑会更好,也更彻底。
在软件开发的世界里,程序就是一台台精密而复杂的机器,而bug则是时不时出现的“故障”。程序员们长期以来都在探索如何让计算机自动修复这些故障,这个领域被称为自动化程序修复(APR)。随着人工智能大模型的崛起,这个领域迎来了新的曙光。AI就像一个越来越聪明的助手,开始学习如何识别并修复代码中的问题。
但是,现有的大多数方法,都更像是那位急于开药的医生。当遇到一个有问题的程序时,这些智能系统会直接尝试给出修复方案,然后再用一系列测试来验证修复是否成功。这种**“先修后测”**的做法,让系统严重依赖于过去见过的相似问题,就像医生只会治疗自己熟悉的病症。一旦面对全新的、复杂的“疑难杂症”,这种方法就常常显得力不从心。
更关键的是,这种传统流程浪费了软件开发中最宝贵的资源之一——测试用例。测试用例如同医生的诊断工具,能够精确地揭示问题所在。可现有方法却只是在修复完成后,才用这些“诊断工具”来验收结果,而不是在修复之前,用它们来诊断问题的根源。这好比医生放着听诊器、CT机不用,仅在治疗结束后用它们来检查病人是否康复,其不合理性显而易见。
正是基于这样的洞察,来自阿里巴巴云计算公司的胡海川、浙江大学的谢晓晨以及南京理工大学的张全军等研究人员,提出了一个具有革命性的解决方案——Repair-R1。这项于2025年7月发表在arXiv预印本服务器上的研究(论文名"Repair-R1: Better Test Before Repair",编号arXiv:2507.22853v1),其核心思想就是颠覆传统,实现**“测试在前,修复在后”**。它要求AI首先扮演一名优秀的诊断专家,生成能够准确识别问题的测试用G例,然后才基于对病因的深刻理解,去制定修复方案。
为了实现这一宏伟蓝图,研究团队设计了一套精巧的强化学习框架,通过“试错学习”和“双重奖励”机制,让AI同时提升“诊断”和“治疗”的能力。在四大主流编程数据集上的实验结果令人振奋,Repair-R1在修复成功率上实现了高达48.29%的提升。
这篇文章将带你深入剖析Repair-R1的技术内核,从它颠覆性的新思路,到背后驱动的强化学习机制,再到详实的实验数据和深刻的理论基础,全面解读这项研究如何让代码修复变得前所未有的聪明,以及它为智能编程的未来开启了怎样一扇新的大门。
一、💡 智能修复的新范式:从“盲修”到“诊断”
%20拷贝-kgeh.jpg)
自动化程序修复的发展历程中,一直存在一个核心矛盾,即修复的“广度”与“深度”之间的平衡。传统方法更侧重于利用模型见过的海量数据进行模式匹配,追求快速给出看似合理的修复方案,但在理解bug本质的深度上有所欠缺。Repair-R1的出现,正是为了打破这一僵局。
1.1 传统APR的困境:“头痛医头”的局限
传统的自动化程序修复流程,就像一个经验丰富但思维固化的老师傅。当面对一台出故障的机器时,他会凭借过去的经验,猜测可能出问题的零件,然后直接动手更换或修理。修复完成后,再开机测试机器是否恢复正常。
这种方法的弊端在于,老师傅的判断很可能被表面现象误导。他可能修复了导致当前症状的直接原因,却没有触及引发这一系列问题的根本性缺陷。
让我们用一个具体的编程例子来说明。
假设有一个简单的计算器程序,其中一个函数本应计算a + b,但由于代码错误,它实现成了a + b + 1。当输入为1+1时,程序错误地输出了3,而不是正确的2。
一个传统的、基于监督学习的APR模型,在看到这个错误后,可能会在其庞大的知识库中搜索类似场景。它可能会找到很多“输出结果比预期大1”的例子,并从中学习到一个修复模式,比如“将结果减1”。于是,它可能会将代码修改为return a + b + 1 - 1,或者更聪明一点,直接修改为return a + b。对于1+1=2这个特定测试,修复成功了。
但是,如果这个bug的真实情况更复杂呢?比如,代码的本意是计算两个数的按位异或a ^ b,但被错误地写成了加法。对于输入1+1,正确结果应为0,错误输出是2。此时,传统的修复模型很可能依然会尝试进行数值调整,而几乎不可能猜到需要将+操作符更换为^。
这就是“先修后测”模式的根本缺陷。它将测试用例仅仅视为一个“裁判”,在修复动作完成后才登场,判断修复是否“碰巧”通过了测试。模型在修复过程中,并没有从测试用例本身获得任何关于bug本质的深层信息。它只是在进行一种基于概率和模式匹配的“猜测”。
1.2 Repair-R1的革命性思路:“测试先行,修复在后”
Repair-R1彻底颠覆了上述流程。它要求AI在动手修复之前,先成为一名出色的“诊断师”。它不再把测试用例当作事后裁判,而是将其视为诊断问题的核心工具。
继续用计算器的例子。Repair-R1会首先驱动AI生成各种各样的测试用例来全面“体检”这个出问题的函数。它不仅会测试1+1,还可能生成2+3、10+5、0+0,甚至是-1+1等各种组合。通过观察函数在这些不同输入下的行为模式,AI能够更准确地推断出问题的根源。如果它发现对于所有输入,结果总是比正确的加法结果大1,那么它就能高置信度地判断问题出在“多加了1”上。
这种**“先诊断,后修复”**的理念,将修复过程从一个模糊的搜索问题,转变为一个有明确指引的推理问题。
我们可以用一个流程图来清晰地对比两种模式的差异。
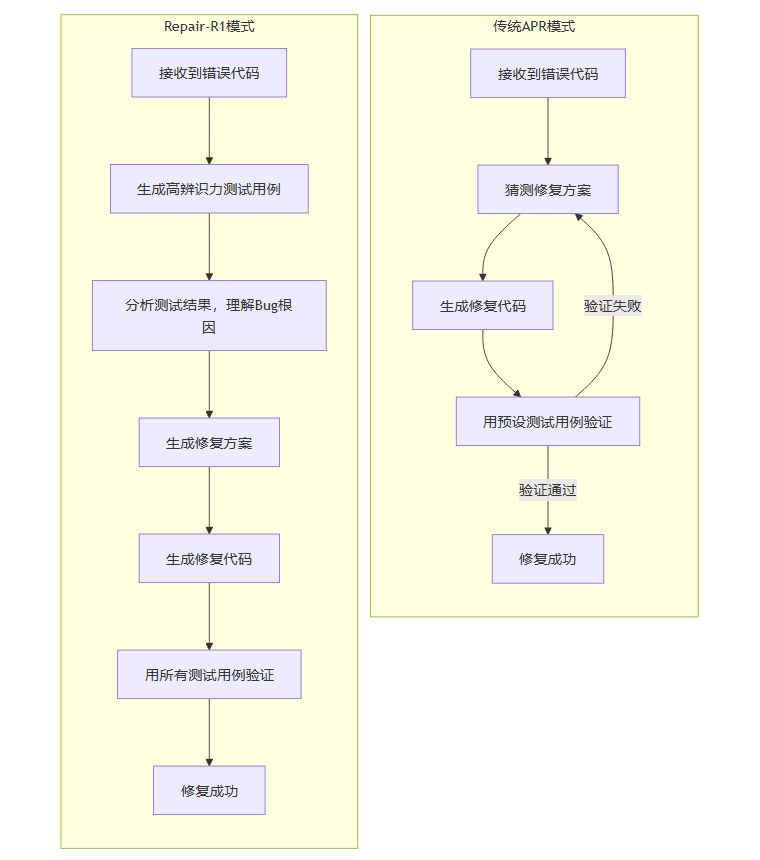
从流程图可以直观地看到,Repair-R1增加了一个至关重要的中间环节——通过生成和分析测试用例来理解Bug。这个环节如同在医生开药方之前插入了“全面体检”和“专家会诊”,使得后续的“治疗”行为更加精准和有效。
1.3 核心武器:“有辨识力的测试用例”
Repair-R1成功的关键,在于生成**“有辨识力的测试用例”(Discriminative Test Cases)**。
什么才算“有辨识力”?简单来说,就是一个测试用例,它在正确的代码上能够顺利通过,但在有bug的代码上则会失败。这样的测试用例就像一枚精准的探针,能够准确地刺探到bug的存在,并揭示其具体表现。
让我们通过论文中一个关于电子邮件格式验证的例子,来更深入地理解这个概念。
场景描述
待修复的错误程序:一个验证邮箱地址格式的函数,但它的逻辑有缺陷,只检查了字符串中是否包含
@符号。正确的参考程序:一个逻辑完备的函数,它不仅检查
@符号的存在,还要求@符号前后都必须有字符。
现在,我们来看几种不同的测试用例,以及它们在两个程序上的表现。
通过生成像"@"和"@163.com"这样的边缘用例(Edge Cases),Repair-R1迫使AI模型去思考一个更深层次的问题,不再是“这个字符串看起来像不像我以前见过的邮箱地址”,而是“一个合法的邮箱地址必须满足哪些结构性规则?”。
一旦AI理解了“@前后必须有字符”这一规则,修复就变得水到渠成。它不再是盲目地修改代码,而是有针对性地增加对@符号前后内容的检查逻辑。
这种从关注“表面现象”到深究“内在逻辑”的转变,正是Repair-R1实现革命性突破的根本所在。它让AI从一个只会背答案的“刷题家”,向一个懂得解题思路的“学霸”迈进。
二、⚙️ 强化学习驱动:让AI在试错中学会“望闻问切”
确立了“先测后修”的正确战略后,接下来的问题就是如何让AI学会这种新的、更复杂的工作模式。研究团队没有选择传统的监督学习,而是巧妙地采用了强化学习(RL)技术,为AI设计了一套精密的“成长体系”。
2.1 为什么选择强化学习?
要理解为何选择强化学习,我们得先看看监督学习(Supervised Learning, SL)在这里可能遇到的麻烦。
监督学习就像是让学生做大量的习题集。老师提供问题(错误代码)和标准答案(正确代码),学生通过模仿和记忆来学习。这种方法在数据量充足且分布均衡时效果很好。
但是,在代码修复这个任务上,数据往往是不均衡的。比如,在实验用的数据集中,来自CodeForces和CodeContests的复杂算法问题样本量巨大,而来自HumanEval和MBPP的函数级编程问题样本相对较少。
如果使用监督学习,模型会像一个“偏科”的学生。它会花大量精力去学习和模仿那些出现频率高的问题类型,而在样本稀少的问题类型上,表现可能不升反降。因为它试图将从多数样本中学到的模式强行应用到少数样本上,结果可能适得其反。实验结果也证实了这一点,传统的监督学习方法在某些数据稀少的任务上,表现甚至比未经训练的原始模型还要差。
而强化学习则完全不同。它不像老师那样直接给出答案,而是扮演一个“教练”的角色。它只定义目标(比如,修复bug)和计分规则(奖励机制),然后让AI自己去“赛场”上尝试。
做对了(比如,生成的测试用例成功识别了bug),就给予奖励。
做错了(比如,修复后的代码没通过测试),就给予惩罚或不给奖励。
通过不断的试错和反馈,AI会自己摸索出一套能够稳定获得高分的策略。这种方法不依赖于记忆特定的“题型”和“答案”,而是学习一套通用的问题解决元技能。因此,它对数据不均衡的问题具有更强的“免疫力”,能够在各类任务上都取得稳健的提升。
2.2 Repair-R1的双任务协同框架
Repair-R1的强化学习框架设计得非常巧妙,它要求AI同时扮演两个角色,并完成两个相互关联的挑战。
诊断师(Test Generator):负责生成有辨识力的测试用例。
治疗师(Code Repairer):负责根据诊断结果修复代码。
整个训练过程就像一场精心设计的游戏,每一轮都包含“诊断”和“治疗”两个阶段。
这个框架的核心在于双重奖励机制。AI不仅因为成功修复代码而获得奖励,也因为成功诊断问题而获得奖励。这两个任务被紧密地耦合在一起。
一个好的“诊断师”能生成高质量的测试用例,这为“治疗师”提供了清晰的修复方向,使其更容易获得修复奖励。
一个好的“治疗师”能高效地利用诊断信息完成修复,这反过来验证了“诊断师”工作的价值。
通过这种方式,AI在两个角色上的能力螺旋式上升,形成了一个1+1 > 2的协同效应。模型不仅学会了如何修复,更重要的是,它学会了如何理解一个bug。
2.3 “格式奖励”的精妙之处
除了上述两个核心奖励,研究团队还引入了一个看似细微但至关重要的概念——“格式奖励”(Format Reward)。
在代码生成任务中,AI有时会产生一些语法不正确或者不符合特定格式要求的输出。比如,让它生成一个Python的测试用例,它可能会漏掉一个括号,或者返回一个格式错误的结果。这些输出即使在逻辑上可能是对的,但在实际执行中会直接报错,导致整个流程中断。
“格式奖励”就是为了解决这个问题。它像一个严格的“卷面分”老师,检查AI生成的测试用例和代码片段是否满足基本的语法和格式规范。
如果输出的代码可以被成功解析和执行,就给予基础的格式奖励。
如果输出不规范,导致解析或执行失败,则不给予奖励。
这个机制确保了AI在追求“内容正确”的同时,也必须保证“格式规范”。这就像要求一个学生写作文,不仅立意要好,字迹也要工整,不能有错别字。这极大地提升了AI生成内容在实际工程环境中的可用性和稳定性,是连接理论模型与现实应用的重要桥梁。
通过这套“辨识度奖励 + 修复奖励 + 格式奖励”的组合拳,Repair-R1为AI构建了一个全面而高效的学习环境,驱动它从一个只会模仿的“鹦鹉”,成长为一个懂得思考和推理的“专家”。
三、📊 实验验证:从理论到实践的华丽转身
%20拷贝-vkbw.jpg)
任何一个新方法,无论其理论多么优雅,最终都需要通过严格的实验来证明其价值。Repair-R1的研究团队为此设计了一场堪称“华山论剑”式的比武大会,让新方法与传统方法在同一起跑线上,用数据说话。
3.1 实验设计:全面的“考场”与多样的“考生”
为了确保实验结果的全面性和可信度,研究团队精心挑选了实验的“考场”(数据集)和“考生”(基础模型)。
3.1.1 四大基准数据集
实验使用了四个在编程领域被广泛认可的基准数据集,它们覆盖了从简单到复杂的各种编程挑战。
这四个数据集的组合,就像一套包含“基础题”、“应用题”和“奥赛题”的综合试卷,能够全方位地考察一个模型解决实际编程问题的能力。
3.1.2 三个不同规模的语言模型
研究团队选择了三个不同规模的Qwen系列代码模型作为“考生”,来验证Repair-R1方法的普适性。
Qwen2.5-Coder-1.5B-Instruct
Qwen2.5-Coder-3B-Instruct
Qwen3-4B
这些模型就像是不同年级的学生,有的是初学者(1.5B),有的是进阶生(3B),还有的是高年级学生(4B)。通过在不同规模的模型上进行测试,可以观察Repair-R1方法是否对所有“学生”都有效,而不仅仅是那些天资聪颖的“尖子生”。
3.1.3 五种对比实验设置
为了清晰地展示Repair-R1的优势,研究团队设置了五种不同的实验方案,进行“控制变量”对比。
原始模型(Original):不进行任何额外训练,直接让模型参加考试,作为基准线。
监督学习(SFT):采用传统的监督学习方法进行微调,即让模型学习“错误代码 -> 正确代码”的映射。
仅修复强化学习(RL-Repair):只使用强化学习训练修复能力,不训练测试生成。
仅测试生成强化学习(RL-TestGen):只使用强化学习训练测试生成能力,不训练修复。
完整Repair-R1:同时训练测试生成和代码修复两种能力,即本文的核心方法。
这种精心的实验设计,使得每一种技术带来的增益都能被清晰地剥离和衡量。
3.2 惊艳的实验结果:数据不会说谎
实验结果非常令人鼓舞,在几乎所有的测试配置中,完整的Repair-R1方法都取得了最佳表现。
3.2.1 修复成功率(Pass@1)的显著提升
修复成功率是衡量APR方法最核心的指标。下表展示了与原始模型相比,Repair-R1带来的修复成功率提升幅度。
从数据中可以清晰地看到:
普遍有效:无论是对于哪个模型,哪个数据集,Repair-R1都带来了正向的、显著的性能提升。
提升巨大:在某些配置下,例如在CodeForces数据集上,成功率的提升幅度甚至接近50%。这种量级的改进在人工智能领域是相当罕见的,尤其是在代码修复这样一个公认的难题上。
对复杂问题更有效:相较于HumanEval和MBPP,Repair-R1在更为复杂的CodeForces和CodeContests数据集上提升更为明显。这恰恰说明,当问题越复杂、越需要深度理解时,“先诊断后修复”的优势就越突出。
3.2.2 测试生成能力的协同增长
Repair-R1不仅提升了修复能力,其“诊断”能力——即生成有辨识力测试用例的能力——也获得了惊人的增长。
测试生成成功率的提升,一方面证明了强化学习框架在训练“诊断”能力上的有效性;另一方面,它也与修复成功率的提升形成了强有力的呼应,直观地展示了“诊断”与“治疗”之间的正向协同关系。
3.3 深入数据背后:诊断与修复的强相关性
为了进一步探究“诊断”和“修复”之间的关系,研究团队对实验结果进行了更细致的分类分析。他们将每个修复尝试的结果分为四类:
修复成功 & 测试生成成功 (Repair-T & Test-T):既能修好代码,又能生成有效测试。这是最理想的状态。
修复成功 & 测试生成失败 (Repair-T & Test-F):代码修好了,但没能生成有效测试。这可能意味着模型是“蒙对”的。
修复失败 & 测试生成成功 (Repair-F & Test-T):没能修好代码,但生成了有效测试。这说明模型“看出了病,但治不好”。
修复失败 & 测试生成失败 (Repair-F & Test-F):诊断和治疗都失败了。
下图展示了原始模型和经过Repair-R1训练后的模型,在这四种类别上的分布变化(以Qwen-4B在HumanEval上的结果为例)。
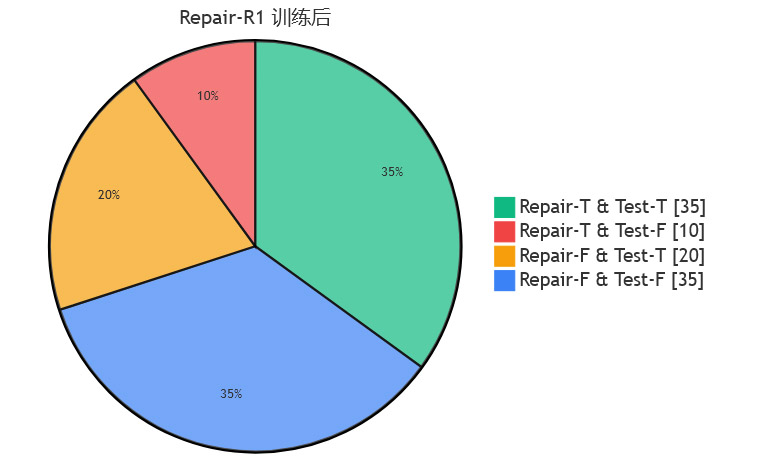
从图表的对比中可以发现一个非常有趣的现象:经过Repair-R1训练后,“修复成功 & 测试生成成功”这一理想类别的占比大幅增加,而“修复成功 & 测试生成失败”(即“蒙对”的情况)的占比显著减少。
这个发现极具说服力。它雄辩地证明了Repair-R1的成功,并非仅仅是让模型变得更会“猜答案”,而是真正地教会了模型如何通过诊断来驱动修复。模型的修复行为,变得更加有理有据,更加接近人类专家的思维方式。
四、🤔 深度剖析:为什么Repair-R1如此有效?
Repair-R1的成功并非偶然,其背后蕴含着对程序修复任务本质的深刻洞察,以及对不同机器学习方法优劣的精准把握。
4.1 从“模式匹配”到“逻辑推理”的升维
传统监督学习方法训练出的模型,其核心能力是模式匹配。它像一个记忆力超群但理解力有限的学生,强行记住“当看到A时,就输出B”。当遇到的问题与训练数据中的模式高度相似时,它能表现得不错。但一旦问题出现新颖的变化,超出了它记忆的范畴,就很容易出错。
Repair-R1通过引入“测试生成”这一强制性的中间步骤,从根本上改变了模型的学习范式。它不再允许模型直接从问题跳到答案,而是强迫它进行一个**“问题 -> 分析 -> 答案”**的逻辑推理过程。
生成测试用例,迫使模型去思考问题的边界、逻辑的缺陷和可能出错的各种情况。
分析测试结果,迫使模型从具体的输入输出对中,归纳出bug的通用规律。
这个过程,本质上是强迫模型从**“记忆现象”转向“理解本质”**。就像要求一个学生,不仅要给出数学题的答案,还必须写出详细的解题步骤和所用的公式。经过这种训练的学生,其解决未知问题的能力,自然远超只会背答案的同学。
4.2 强化学习对“数据偏科”的天然免疫力
正如前文所述,监督学习在面对数据不均衡问题时,容易出现“偏科”。模型会过度拟合样本量大的任务类型,而在样本量小的任务上性能下降。
而Repair-R1采用的强化学习,其学习信号来自于与环境交互后获得的奖励,而不是固定的“标准答案”。这个奖励是根据任务目标(修复bug)动态计算的,与该任务的样本在数据集中出现的频率无关。
无论一个bug是来自样本量大的CodeForces,还是样本量小的HumanEval,只要模型成功修复了它,就能获得正向的奖励。
学习的目标是最大化在所有任务上获得的总奖励,而不是在某个特定任务上模仿得最像。
这种机制使得模型必须学会一套通用的、适用于所有任务的问题解决方法,而不是针对特定任务的特定技巧。因此,即使在数据分布极不均匀的情况下,Repair-R1依然能够在所有数据集上都取得稳健的性能提升,展现了出色的泛化能力。
4.3 消融实验揭示的“协同效应”
研究团队进行的消融实验(Ablation Study)进一步证实了其方法设计的合理性。他们分别测试了只训练测试生成能力(RL-TestGen)和只训练修复能力(RL-Repair)的效果。
结果显示:
单独训练任何一种能力,都能带来一定的性能改进。 这说明测试生成和代码修复本身都是有价值的任务。
但两者结合(完整的Repair-R1)的效果,明显优于任何单一任务的训练。
这清晰地证明了测试生成和代码修复之间存在着强大的协同效应。它们不是两个孤立的任务,而是一个有机整体的两个侧面。高质量的诊断为精准的治疗提供了基础,而成功的治疗又验证并强化了诊断的价值。Repair-R1的框架设计,正是成功地利用并放大了这种协同效应。
五、📈 扩展性分析:更多样本,更好结果
%20拷贝-ycdh.jpg)
在实际应用中,我们往往不满足于模型只给出一个答案。一个更常见的做法是让模型生成多个候选解决方案,然后从中选择最好的一个。这个过程被称为**“测试时扩展”(Test-Time Scaling)**,通常通过增加采样数量(pass@k中的k)来实现。
研究团队专门测试了Repair-R1在“测试时扩展”方面的表现,结果揭示了一些有趣的规律。
实验结果显示,当生成的候选样本数量从1个(pass@1)增加到8个(pass@8)时,所有模型的修复成功率都有了显著的提升。这符合预期,因为更多的尝试次数自然会带来更高的成功概率。
但更有趣的发现来自于不同模型之间的对比。
在样本数量较少时(如
pass@1),专门针对代码优化的模型(如Qwen-Coder系列)可能表现更优。但随着样本数量的增加,通用的、规模更大的推理模型(如Qwen-4B)的表现逐渐追上甚至超越了专门的代码模型。
这个现象的可能解释是:
专用代码模型:它们在训练中更专注于代码任务,因此其“第一反应”往往更接近正确答案。在资源有限、需要快速给出单个高质量答案的场景下,它们具有优势。
通用推理模型:它们拥有更广阔的知识和更强的多样化思考能力。当给予足够多的尝试机会时,它们能够从更多不同的角度去探索解决方案,从而可能找到一些专用模型想不到的、更具创造性的修复方法。
这就像一个专业的汽车修理工和一个经验丰富的全能工程师。对于常见的发动机故障,修理工可能更快地找到问题并修复。但如果遇到一个涉及机械、电子和软件的复杂疑难杂症,工程师凭借其更广博的知识体系,在经过一番研究和尝试后,可能最终能提出更根本的解决方案。
这个发现对于Repair-R1的实际部署具有重要的指导意义。它表明,我们可以根据具体的应用场景和可用的计算资源,来选择最合适的模型和采样策略,以达到最佳的费效比。
六、🔬 理论基础:看似工程,实则数学
虽然Repair-R1看起来像是一个巧妙的工程解决方案,但它的背后实际上有着坚实而优美的数学理论作为支撑。研究团队通过严谨的数学推导,将其方法与统计学中的一个经典模型联系起来,为方法的有效性提供了理论层面的保证。
6.1 代码修复的潜变量模型视角
研究团队将代码修复问题重新表述为一个**潜变量模型(Latent Variable Model)**问题。
让我们用一个通俗的方式来理解这个模型。
观测变量(Observed Variable):我们能直接看到的东西,即有bug的代码(buggy code)。
目标变量(Target Variable):我们希望得到的东西,即修复后的代码(fixed code)。
潜变量(Latent Variable):一个我们无法直接观测到,但对整个过程至关重要的中间变量。在Repair-R1中,这个潜变量就是能够揭示bug根本原因的测试用例(discriminative test case)。
在这个模型下,传统的APR方法试图直接建立从“观测变量”到“目标变量”的映射,即 P(fixed code | buggy code)。这很困难,因为两者之间的关系可能非常复杂和非线性。
而Repair-R1则走了一条更迂回但更合理的路径。它认为,修复过程应该分为两步。
首先,根据有bug的代码,推断出那个隐藏的“根本原因”(潜变量),即
P(test case | buggy code)。然后,基于对“根本原因”的理解,再生成最终的修复代码,即
P(fixed code | test case, buggy code)。
整个过程的概率可以表示为对所有可能的潜变量(测试用例)进行积分或求和。
P(fixed code | buggy code) = ∫ P(fixed code | test case, buggy code) * P(test case | buggy code) d(test case)
这个公式的直观含义是,一个好的修复,是综合了所有可能的“病因诊断”之后,得出的最合理的“治疗方案”。
6.2 ELBO与强化学习的奇妙统一
上述积分公式在实际中是无法直接计算的,因为它需要遍历无穷无尽的测试用例。在统计学和机器学习中,处理这类问题的一个常用技术是变分推断(Variational Inference),其核心工具是证据下界(Evidence Lower Bound, ELBO)。
ELBO的作用,是为那个无法计算的真实概率,找到了一个可以计算的、并且尽可能接近它的“下限”。通过最大化这个下限(ELBO),我们就能间接地优化原始的目标。
最巧妙的部分来了。研究团队通过数学推导发现,他们所使用的强化学习算法GRPO(Generalized Reward Policy Optimization)的优化目标函数,在形式上与最大化ELBO的目标函数是高度一致的。
这意味着:
Repair-R1的强化学习框架,不仅仅是一个凭经验设计的工程技巧,它在数学上等价于在优化一个严谨的概率图模型的证据下界。
测试生成网络(Test Generator),在数学上扮演了变分推断中“识别网络”(Recognition Network)的角色,其任务是近似那个难以计算的“后验概率”
P(test case | buggy code)。代码修复网络(Code Repairer),则扮演了“生成网络”(Generative Network)的角色,其任务是基于推断出的潜变量来生成最终结果。
这种理论与实践的完美统一,是这项研究最深刻和最令人信服的地方之一。它不仅解释了为什么Repair-R1有效,更从根本上保证了其方法的合理性和稳健性。它告诉我们,Repair-R1的成功,是建立在坚实的数学地基之上的,而非空中楼阁。
七、🌍 实际应用价值:从实验室走向真实世界
%20拷贝-pszk.jpg)
一项研究的最终价值,体现在它能否走出实验室,为现实世界带来改变。Repair-R1在这方面展现出了巨大的潜力。
7.1 赋能开发者,提升修复效率与质量
在真实的软件开发环境中,程序员每天都在与各种各样的bug作斗争。传统的自动修复工具,往往只能处理一些语法错误、简单逻辑错误等“常见病”,对于那些隐藏在复杂业务逻辑深处、或者由多个模块交互引发的“疑难杂症”,则常常束手无策。
Repair-R1的“测试先行”策略,为解决这些复杂问题提供了全新的思路。通过首先生成全面的测试用例来深入理解问题的本质,系统有能力处理更加复杂和多样化的错误类型。
这就像给程序员配备了一个既会诊断又会治疗的全能智能助手。
当遇到一个棘手的bug时,开发者不再需要耗费大量时间去手动复现、定位和分析。
他们可以将问题代码交给Repair-R1,系统会自动生成一系列能够触发bug的测试用例,清晰地揭示出问题的根源。
更进一步,系统还能基于这些诊断信息,直接提供一个或多个高质量的修复方案供开发者参考或采纳。
这将极大地缩短bug的修复周期,将开发者从繁琐的调试工作中解放出来,让他们能更专注于创造性的编码活动。
7.2 “一箭双雕”:修复代码与生成测试资产
特别值得强调的是,Repair-R1在修复代码的过程中,其副产品——高质量的测试用例——本身就具有极高的价值。
在现代软件工程中,测试是保证软件质量的生命线。编写全面、有效的测试用例,是一项既重要又极其耗时的工作,尤其是在敏捷开发和持续集成的流程中。
Repair-R1在修复一个bug的同时,也为这个bug创建了一份永久的“病历档案”,即那些能够精准识别该bug的测试用例。这些测试用例可以被直接整合到项目的测试套件中,形成宝贵的测试资产。
它们可以用于回归测试,确保未来的代码修改不会意外地让这个旧bug“复活”。
它们可以作为API测试和自动化测试流程的一部分,持续守护代码库的健康。
这种“一箭双雕”的特性,使得Repair-R1的价值远不止于单次的bug修复。它能够持续地为软件项目贡献高质量的测试资产,从而构建一个更稳健、更可靠的软件质量保障体系。
7.3 开源共享,推动社区共同进步
研究团队深知开源的力量。他们已经将Repair-R1的代码和训练好的模型权重公开发布在GitHub和HuggingFace等平台上。
这意味着,全世界的开发者和研究人员都可以自由地:
使用这项技术来辅助自己的开发工作。
复现论文中的实验结果,验证其有效性。
改进和扩展这项技术,探索其在更多场景下的应用。
这种开放和共享的态度,无疑将极大地加速整个自动化程序修复领域的创新和发展,最终让整个软件行业受益。
八、🚀 未来展望:开启智能编程助手的新纪元
Repair-R1的成功,不仅仅是一次技术指标上的提升,它更像是一个里程碑,标志着自动化程序修复领域进入了一个全新的发展阶段。它所倡导的“理解优先”的思维方式,可能会在更广阔的AI领域引发一连串的连锁反应。
8.1 从“修复优先”到“理解优先”的范式转移
Repair-R1的核心贡献,是推动了从“修复优先”到**“理解优先”**的范式转移。这种转变的意义,可能远超代码修复本身。
在人工智能的许多其他应用领域,比如自动化写作、智能客服、AI辅助教育等,我们同样可以看到类似的挑战。
一个写作AI可能能生成语法通顺的句子,但逻辑混乱。
一个客服机器人可能能回答常见问题,但无法理解用户的真实意图。
一个教育AI可能能批改选择题,但无法诊断学生知识点的根本性缺失。
这些问题的根源,都在于AI缺乏对问题本质的“理解”。Repair-R1所展示的“诊断先行”策略,为解决这些问题提供了一个通用的、可借鉴的思路。我们可以设想:
未来的写作AI,在动笔前会先生成一个详细的逻辑大纲。
未来的客服机器人,在回答前会先通过一系列澄清式提问来准确理解用户需求。
这种从“头痛医头,脚痛医脚”的反应式智能,向“治病先治根”的分析式智能的转变,是通往更高阶人工智能的必由之路。
8.2 强化学习在代码智能领域的广阔前景
传统上,代码生成和修复等任务主要依赖监督学习。Repair-R1则有力地证明了,强化学习在这个领域同样具有巨大的潜力,甚至在某些方面更具优势。
这可能会催生一波基于强化学习的代码智能工具浪潮。未来的AI编程助手,可能不再仅仅是一个被动提供代码补全的工具,而是一个能够与开发者进行深度交互、共同探索问题解决方案的智能伙伴。它可以根据开发者的反馈,动态调整自己的行为,通过不断的“实战”来提升自己的编程技艺。
8.3 挑战与前路
当然,Repair-R1也并非终点。通往全自动、高可靠的智能编程之路依然漫长,前方还有许多挑战等待着研究者们去攻克。
效率问题:强化学习的训练过程通常比监督学习更耗时,如何在保持高质量的同时进一步提升训练和推理效率,是一个重要的工程问题。
复杂项目处理:当前的研究主要集中在单个文件或函数的修复上。如何处理涉及多个文件、多个模块、甚至多个代码仓库的复杂项目级bug,是一个巨大的挑战。
意图理解:如何让AI更好地理解程序员的“真实意图”,而不仅仅是代码的字面逻辑,是实现更高层次智能的关键。
这些挑战,也为未来的研究指明了清晰的方向。
总结
说到底,Repair-R1的最大价值,在于它深刻地改变了我们思考自动化程序修复的方式。它告诉我们,一个真正智能的修复系统,不应该满足于简单地模仿人类程序员的修复模式,而应该学习人类专家最宝贵的品质——先深入理解问题的本质,然后再提出解决方案。
这种“理解驱动”的方法,不仅能够帮助我们解决更复杂、更棘手的bug,更重要的是,它为我们构建更可靠、更智能、更值得信赖的编程辅助工具铺平了道路。
随着这项技术的不断演进和完善,我们有理由相信,未来的软件开发将变得更加高效、更加轻松、也更加富有创造力。程序员将从繁琐的“救火队员”角色中解脱出来,成为驾驭强大AI助手的“架构师”和“创造者”,最终让我们每个人,都能从更高质量的软件产品中受益。
对于那些渴望亲手触摸这项前沿技术的读者,完整的论文(arXiv:2507.22853v1)和开源的代码、模型,都已在网络上静候你的探索。
Q&A精选
Repair-R1与传统方法的本质区别?
Repair-R1“先测试后修复”,通过高辨识力测试用例精准定位bug根因,再有针对性修复,效果更好,泛化能力更强。强化学习在Repair-R1中的作用?
AI通过生成测试用例和修复代码两个任务获得奖励,双重激励机制让诊断和修复能力同步提升。Repair-R1能处理哪些类型的bug?实验效果如何?
能处理函数级、算法级等多种类型的编程bug,修复成功率最高提升48.29%,测试生成成功率最高提升53.28%,展现极强通用性。
📢💻 【省心锐评】
Repair-R1让AI从“抄答案”的学渣进化为“会诊断”的学霸,代码修复不再是碰运气,而是有理有据的科学诊疗,这才是智能编程该有的样子。

评论