.png)


【摘要】一项由浙江大学领导的联合研究揭示了AI写作中的“时间振荡”现象,即模型在生成过程的中间步骤已得出正确答案,但最终输出时却被错误结果覆盖。研究团队为此提出了“时间自一致性投票”和“时间一致性强化”两种创新方案,通过挖掘和利用AI的“思考过程”,在多个数学推理任务上实现了高达25%的性能提升,为构建更可靠、更透明的AI系统开辟了全新路径。
引言
在人工智能的浪潮之巅,大型语言模型(LLM)以其惊人的文本生成和逻辑推理能力,正深刻地重塑着我们的世界。我们惊叹于它们写诗、编代码、答疑解惑的才华,习惯性地将它们视为一个深邃的“黑箱”——我们输入问题,它输出答案。我们评估其优劣的标准,也往往聚焦于这最终呈现的答案是否精准、流畅。然而,一个来自浙江大学、蚂蟻集團、浙江工業大學及斯坦福大學的聯合研究團隊,却勇敢地撬开了这个“黑箱”的一角,他们的发现足以颠覆我们对AI推理过程的传统认知。
这项发表于2025年1月,题为《Time Is a Feature: Exploiting Temporal Dynamics in Diffusion Language Models》的研究,揭示了一个令人既惊讶又着迷的现象:AI在生成答案的中间过程中,往往比它最终给出的答案更加“聪明”。这就像一位才华横溢的学生,在草稿纸上演绎出了完美的解题步骤和正确答案,却在誊写到答题卡上的最后一刻,莫名其妙地写下了一个错误的结果。
这一现象被研究团队命名为“时间振荡”(Temporal Oscillation)。它挑战了一个根深蒂固的假设:AI的推理过程是一个线性优化的过程,每一步迭代都应更接近最优解。但现实恰恰相反,中间过程的智慧火花,竟会被后续步骤的“画蛇添足”所淹没。这一发现不仅为我们解释了AI为何会“聪明反被聪明误”,更重要的是,它指明了一条全新的优化路径——与其仅仅盯着终点,不如回头看看沿途的风景,那里可能隐藏着真正的宝藏。
本文将深入剖析这一引人深思的“时间振荡”现象,详细解读研究团队提出的两种巧妙解决方案——“时间自一致性投票”与“时间一致性强化”,并探讨这一“时间即特征”的新范式,将对未来AI系统的设计、评估和可信度建设产生何等深远的影响。
一、🕵️♂️ 意外的发现:AI的“草稿纸”智慧
%20拷贝.jpg)
1.1 违背直觉的实验结果
一切始于一次对扩散语言模型(Diffusion Language Models)的常规测试。研究团队选择了两个代表性的模型——LLaDA-8B-Instruct和LLaDA-1.5,并在四个经典的数学推理数据集上对它们进行评估。这些数据集覆盖了从小学到高中的不同难度层次:
GSM8K: 包含数千道小学水平的数学应用题。
MATH500: 汇集了高中竞赛级别的数学难题。
SVAMP: 由基础的数学文字题构成,考验模型的基本理解和计算能力。
Countdown: 一个数字组合游戏,要求模型通过加减乘除将一组数字凑成目标值。
当团队按照传统方式,只评估模型最终输出的答案时,结果平平无奇,符合人们对当前AI能力的普遍认知。例如,在GSM8K数据集上,模型的最终准确率(Final Accuracy)为68.5%。然而,当他们转换视角,开始审视模型从生成第一个字符到输出最终答案的整个过程时,一个惊人的事实浮出水面。
他们定义了一个新的评估指标——“过程中曾出现正确答案的准确率”(Intermediate Truth Rate)。这个指标衡量的是,在整个生成序列的任意一个中间步骤,模型是否曾一度产生过正确的答案。测试结果令人大跌眼镜:在GSM8K数据集上,这个准确率竟然高达80.5%。
这意味着,有整整**12%**的问题,AI模型实际上已经“想”出了正确答案,但在抵达终点前的某个时刻,它又亲手将这个正确答案抛弃,换上了一个错误的结果。这种“得而复失”的现象,在所有测试的数据集和模型上都普遍存在,形成了一个显著的性能差距。
1.2 一个生动的案例
为了更直观地理解这种现象,让我们看一个研究中提到的典型案例。问题是关于植物分类的计算:
“一个植物园有100株植物。其中四分之一是室内植物,剩下的植物中有三分之二是室外植物,其余的都是开花植物。问开花植物占总数的百分之几?”
这是一个标准的小学数学题,正确的解题思路是:
室内植物数量:100 * (1/4) = 25株
剩余植物数量:100 - 25 = 75株
室外植物数量:75 * (2/3) = 50株
开花植物数量:75 - 50 = 25株
开花植物所占百分比:25 / 100 = 25%
研究团队观察到,AI模型在生成答案的过程中,其内部状态的变化如下:
在第55个时间步:模型生成了包含正确答案“25%”的完整且逻辑清晰的解题步骤。此时,它的“草稿纸”上写着满分答案。
在后续的步骤中:模型并未就此停止,而是继续进行“优化”和“精炼”。
在第64个时间步:模型输出了最终答案,但答案却离奇地变成了“2%”。中间的某个环节,可能是对数字的误读,或是逻辑链的断裂,导致了最终的错误。
这个例子生动地展示了“时间振荡”的本质:AI的推理并非一条稳步向前的康庄大道,而更像是一条蜿蜒曲折、时而偏离正轨的小径。中间过程的智慧,被后续步骤的“愚蠢”所掩盖。这一发现彻底颠覆了“迭代越多,结果越好”的传统观念,迫使我们重新审视AI的“思考”过程。
二、🔬 深入肌理:时间振荡背后的数学原理
为了揭开“时间振荡”现象的神秘面纱,研究团队从多个维度对其背后的数学和统计学特性进行了深入的剖析,试图理解AI为何会在推理的“时间长河”中迷失方向。
2.1 任务复杂度与准确率的动态演变
研究者首先绘制了不同任务下,准确率随生成时间步变化的曲线图。他们发现,任务的复杂性与准确率的演变模式之间存在着密切的联系。
对于简单任务(如SVAMP):AI模型往往能在较早的生成阶段就迅速达到一个较高的准确率平台。后续的生成步骤更多是在这个正确答案的基础上进行微调、润色或补充解释。曲线呈现出一种“早熟”并趋于稳定的形态。
对于复杂任务(如Countdown或MATH500):AI在初期阶段的准确率非常低,因为它需要时间来“思考”、探索和组合不同的可能性。准确率曲线会经历一个缓慢的爬升过程。然而,问题在于,这个爬升过程往往会“过头”,在达到峰值后,曲线反而开始下滑,最终稳定在一个低于峰值的水平上。这完美诠释了“过犹不及”的道理,过多的迭代反而引入了噪声和错误。
这种差异表明,AI的推理过程并非一成不变,而是根据任务难度动态调整其探索与优化的策略。对于复杂问题,更长的“思考时间”虽然必要,但也增加了偏离正确轨道的风险。
2.2 熵值波动:衡量AI的“不确定性”
为了更量化地描述AI在生成过程中的“心理状态”,研究团队引入了信息论中的“熵”(Entropy)概念。在这里,熵可以被通俗地理解为AI对当前生成内容的“不确定性”或“困惑程度”。熵值越高,表示模型在下一步生成什么内容上越犹豫不决,可能性分布越分散;熵值越低,则表示模型对当前路径越有信心。
通过追踪整个生成过程中的熵值变化,他们发现了有趣的规律:
总体趋势:无论是最终答对还是答错的问题,熵值在整个生成过程中总体上都呈现下降趋势。这符合直觉,因为随着生成内容的增多,约束条件也随之增加,模型的选择空间会逐渐收窄。
关键差异:那些最终答错的问题,其熵值曲线往往在中间过程中表现出更剧烈的波动。这就像一个人在做决策时,虽然大方向明确,但过程中却充满了反复的自我怀疑和摇摆。
2.3 三类问题的行为画像
更有启发性的是,研究者将所有问题根据其表现分为三类,并对它们的熵值变化进行了对比分析:
始终正确(Consistently Correct): 从某个时间点开始就得到正确答案,并一直保持到最后。
中间正确,最终错误(Mid-Truth, Final-Wrong): 即“时间振荡”现象的典型代表。
始终错误(Consistently Wrong): 从头到尾都没有产生过正确答案。
分析结果显示:
“中间正确,最终错误”的这类问题,在生成过程的早期,其熵值甚至比“始终正确”的问题还要低。这说明,在某个时间点,AI对于这个(后来被证明是正确的)中间答案是非常确定的。它并非偶然猜对,而是确实“想通了”。
然而,在后续的步骤中,这类问题的熵值会突然出现一个显著的峰值,然后才慢慢回落。这个峰值可能对应着模型引入新信息或进行不必要推理的时刻,正是这个“节外生枝”的操作,破坏了原有的正确状态,导致了最终的失败。
这一系列深入的分析,不仅证实了“时间振荡”的存在,更从数学层面揭示了其内在机制:它源于AI在复杂推理中,探索与稳定之间的失衡,以及后续优化步骤对前期正确状态的意外破坏。
三、💡 另辟蹊径:全新的“时间语义熵”评估体系
%20拷贝.jpg)
基于对时间振荡现象的深刻理解,研究团队意识到,传统的、只关注最终结果的评估方法存在巨大缺陷。它无法捕捉到AI推理过程的动态性和稳定性。为此,他们提出了一个极具创意的全新评估概念——时间语义熵(Temporal Semantic Entropy, TSE)。
3.1 从“结果对错”到“过程稳定”
时间语义熵的核心思想,是从评估“答案的正确性”转向评估“答案语义的稳定性”。它不再问“AI最终答对了吗?”,而是问“AI在整个思考过程中,它的想法是否一致?”。
这个概念可以用一个整理书架的例子来类比:
假设你要整理一个乱糟糟的书架。你每次调整书籍的位置,都会产生一个新的排列方案。
低TSE:如果你心中有一个明确的分类标准(比如按作者、按颜色),那么你每次调整的结果都会越来越接近那个最终的理想状态,不同调整方案之间的差异很小。这说明你的整理思路是稳定且一致的。
高TSE:如果你毫无头绪,一会儿想按大小排,一会儿又想按书名首字母排,那么每次调整的结果可能都大相径庭。这说明你的整理思路是混乱且摇摆不定的。
同样,在AI生成答案的过程中,如果它在不同时间步产生的答案,其核心语义高度一致(例如,反复出现“25%”、“答案是25”等),那么它的时间语义熵就很低。反之,如果答案的语义跳跃性很大(从“25%”跳到“75%”,再跳到“2%”),那么它的时间语义熵就很高。
3.2 时间语义熵的计算过程
计算时间语义熵的过程,大致可以分为以下几个步骤:
收集所有中间答案: 首先,在AI生成文本的每一个时间步,提取出当时已经形成的答案或关键信息。
语义聚类: 使用先进的自然语言处理技术(如句子嵌入模型),将所有这些中间答案根据其语义相似性进行分组。意思相同或相近的答案会被归为一类。例如,“25%”、“结果是25个百分点”、“twenty-five percent”都会被聚到同一个语义簇中。
计算分布熵: 统计每个语义簇中包含的答案数量,形成一个概率分布。然后,利用香农熵的计算公式,计算这个分布的熵值。
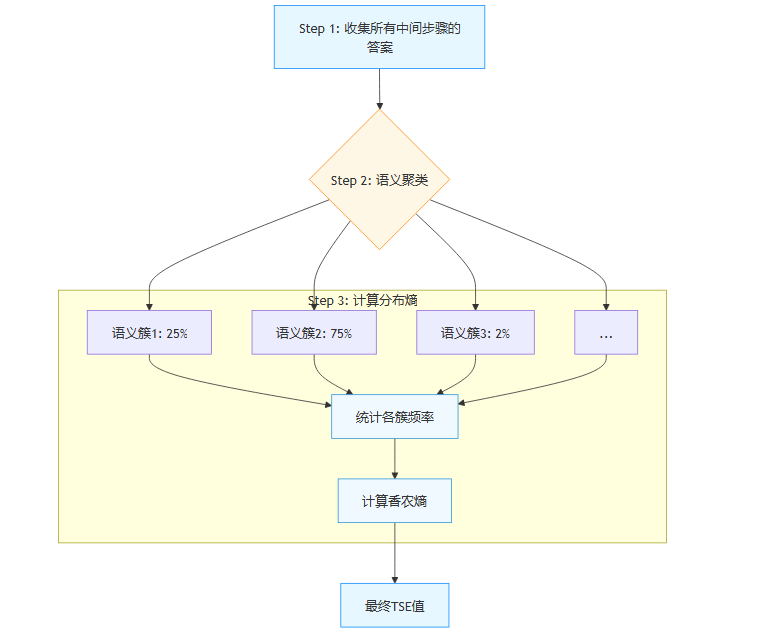
如果答案的语义高度集中在少数几个簇中,那么分布就比较“尖锐”,熵值很低。如果语义分散在大量不同的簇中,分布就比较“平坦”,熵值很高。
3.3 TSE的验证与价值
实验结果有力地验证了时间语义熵的有效性。在所有测试的数据集中,最终答对的问题,其时间语义熵普遍显著低于最终答错的问题。这表明,一个“思路清晰”的AI,其推理过程在语义上是高度一致和稳定的。
时间语义熵的提出,其意义远不止于一个新指标。它为评估AI系统的可靠性提供了一个全新的、超越最终结果的维度。在医疗诊断、法律文书生成、金融分析等高风险领域,我们不仅需要AI给出正确答案,更需要确信它的推理过程是稳健和可信的。TSE就像一个“思维稳定度检测仪”,能够帮助我们识别那些“摇摆不定”的AI,从而在关键应用中做出更审慎的判断。
四、🗳️ 巧妙的补救:时间自一致性投票
发现了问题,也找到了衡量问题严重程度的工具,下一步自然是解决问题。研究团队首先提出了一种简单、高效且几乎零成本的解决方案——时间自一致性投票(Temporal Self-Consistency Voting)。
4.1 集体智慧战胜个体失误
这个方法的核心思想非常直观:既然AI在中间过程可能更聪明,那么我们就不应该只相信它最后说的话。我们应该让它在生成过程中的所有中间答案进行一次“民主投票”,选出那个得到最多“支持”的答案作为最终结果。
这就像在一个重要的决策会议上,我们不会只听取最后一位发言者的意见,而是会综合考虑所有与会者的观点,通过投票来找出共识度最高的方案。在AI的生成过程中,每一个时间步产生的答案,都可以被看作是一个“专家意见”。虽然单个意见可能存在偏差,但集体智慧往往比个体判断更可靠。
4.2 加权投票:并非所有意见都生而平等
为了让投票过程更加科学,研究团队意识到,并非所有时间步的“意见”都具有同等价值。一个在生成初期、信息尚不充分时产生的答案,其可信度可能不如一个在生成后期、经过了更多推理后产生的答案。因此,他们设计了不同的权重分配策略:
平等投票(Uniform Weighting): 最简单的方式,每个中间步骤的答案权重都相同。
线性加权(Linear Weighting):越接近最终步骤的答案,其权重越高,权重呈线性增加。这体现了“越往后想得越清楚”的传统观念。
指数加权(Exponential Weighting):同样是给后期步骤更高的权重,但权重的增长速度呈指数级,变化更平滑。这种策略能更显著地放大后期稳定答案的影响力。
实验结果表明,指数加权策略的效果最佳。它在承认后期步骤判断可能更成熟的同时,又没有完全忽视早期步骤可能闪现的智慧火花,在“新”与“旧”之间找到了一个精妙的平衡点。
以LLaDA-8B-Instruct模型为例,在应用了指数加权的时间自一致性投票后,性能得到了显著提升:
GSM8K数据集的准确率从68.5%提升到70.1%。
MATH500数据集的准确率从27.4%提升到28.4%。
4.3 零成本的性能提升
这种方法最大的优势在于其极高的经济性。它是一种推理阶段(Inference-time)的后处理技术,完全不需要重新训练模型,也几乎不增加额外的计算负担。它只是在模型完成一次正常的生成任务后,对已有的中间状态进行一次快速的统计分析。
这就像在烹饪过程中,我们不需要更换厨具或食材,只是在出锅前增加了几个品尝味道的环节,从而更好地利用了过程中已经产生的信息。对于广大AI开发者和使用者而言,这意味着可以“即插即用”地集成到现有系统中,立即享受到性能提升带来的红利。
五、🧠 深层改造:时间一致性强化训练
%20拷贝.jpg)
如果说投票法是一种巧妙的“事后补救”,那么研究团队提出的第二种解决方案——时间一致性强化(Temporal Consistency Reinforcement),则是一种更深入、更根本的“事前预防”。它的目标是在AI的学习阶段,就教会它养成“深思熟虑、言行一致”的好习惯。
5.1 将“过程稳定”作为学习目标
这种训练方法巧妙地将前面提出的**时间语义熵(TSE)**作为奖励信号,并融入到强化学习(Reinforcement Learning, RL)的框架中。
在强化学习中,AI(代理,Agent)通过与环境互动,根据得到的奖励或惩罚来调整自己的行为策略。在这里:
行为(Action): AI生成文本的每一步。
奖励信号(Reward Signal): 不再仅仅是“最终答案是否正确”,而是加入了“生成过程是否稳定”,即时间语义熵的负值。
具体来说,AI每完成一次文本生成任务,系统就会计算这次生成过程的时间语义熵。
如果TSE值很低(意味着语义高度一致),AI就会得到一个正向奖励。
如果TSE值很高(意味着答案摇摆不定),AI就会收到一个负向惩罚。
这个过程就像训练一个学生,我们不仅在他答对题目时给予奖励,更在他展现出清晰、连贯、不自我矛盾的思维过程时给予表扬。通过这种方式,AI被激励去探索那些不仅能通向正确答案,而且过程本身也更加稳定、可靠的推理路径,从而从根本上抑制“时间振荡”的发生。
5.2 自我监督的强大威力
这种训练方法还有一个令人惊喜的优点:它在很大程度上实现了自我监督。传统的AI训练(如监督微调)需要大量标注好正确答案的数据集来指导学习。但在时间一致性强化训练中,奖励信号(TSE)是完全基于模型自身生成的中间过程计算得出的,理论上并不需要外部提供的标准答案。
这就像一个学生通过不断反思和审视自己的解题思路来提升逻辑能力,而无需老师时刻在旁告知正确答案。这种自我驱动的学习方式,极大地降低了对高质量标注数据的依赖,为在更广泛、更缺乏标注数据的领域训练可靠的AI模型提供了可能。
5.3 惊人的性能飞跃
实验结果雄辩地证明了这种深层改造方法的威力。
单独使用TSE作为奖励: 仅凭“过程稳定”这一项奖励,在Countdown数据集上就实现了**24.7%**的惊人平均性能提升。
结合传统奖励: 当将TSE奖励与传统的“答案准确性”奖励结合使用时,效果更上一层楼,在多个数据集上实现了全面提升:
GSM8K: 提升 2.0%
MATH500: 提升 4.3%
SVAMP: 提升 6.6%
Countdown: 提升 25.3%
这些数据表明,通过强化训练让AI学会保持“时间一致性”,不仅能有效解决“时间振荡”问题,更能从根本上提升模型的推理能力和最终性能。
六、📊 严谨的验证与方法的边界
一项出色的研究不仅要提出创新的方法,更要通过严谨的实验来验证其有效性,并诚实地探讨其局限性。
6.1 全方位的实验验证
研究团队进行了大规模的实验,确保了所提方法的普适性和鲁棒性。他们不仅在多个数据集和不同模型架构上进行了测试,还深入分析了不同参数设置的影响。例如,在时间自一致性投票中,他们发现指数加权的衰减参数设为5时,能在各个数据集上取得最均衡、最优秀的性能提升,平均达到1.5%。这一发现为方法的实际应用提供了宝贵的工程指导。
在分析经过时间一致性强化训练后的模型时,他们发现,训练后的模型确实表现出更低的时间语义熵,证明训练目标得到了有效实现。一个有趣的变化是,模型生成的文本长度也略有减少。研究者推测,这可能是因为更简洁、更直达要点的回答,本身就不容易出现内在的逻辑矛盾。
一个特别值得注意的发现是,两种方法是互补的。即使模型已经经过了时间一致性强化训练,在推理阶段再应用时间自一致性投票,仍然能够带来额外的性能提升。这就像一个学生,既通过日常训练培养了良好的思维习惯,又在考试时运用仔细检查的技巧来避免临场失误,双管齐下,效果更佳。
6.2 局限性与适用范围
研究团队也清醒地认识到,这些方法并非万能灵药。其有效性在很大程度上依赖于一个前提:AI模型本身具备一定的基础能力,能够在生成过程中的某个时刻触及正确答案。
他们用一个极具挑战性的数独游戏作为反例进行了测试。在数独任务中,由于问题的组合爆炸性,模型在所有中间步骤的平均准确率都低于5%。在这种情况下,投票池中绝大多数都是错误答案,进行“时间自一致性投票”反而会因为噪声的干扰而降低性能。
这个反例清晰地划定了方法的适用边界:它适用于那些模型“有能力解决,但偶尔会犯错”的任务,而不是那些模型完全无能为力的任务。
此外,计算资源的考量也是现实问题。时间自一致性投票轻量而高效,但时间一致性强化训练需要消耗大量的计算资源来重新训练模型,这对于资源受限的团队可能是一个挑战。
最后,当前的研究主要聚焦于结构性强、答案唯一的数学推理任务。对于创意写作、开放式对话等更主观、更发散的任务,这些方法的效果如何,对“一致性”的要求是否会有所不同,还有待进一步的研究和探索。
七、🚀 深远意义:开启“过程智能”新纪元
%20拷贝.jpg)
这项研究的价值,远远超出了在几个数据集上提升几个百分点的准确率。它为我们理解、评估和构建AI系统提供了一个全新的、至关重要的视角,其影响是深远而广泛的。
7.1 “时间即特征”:从关注结果到洞察过程
这项研究最重要的贡献,是提出了**“时间即特征”(Time is a Feature)**的核心理念。传统上,我们将AI的生成过程视为一个短暂的、无需关注的计算环节,但这项研究证明,这个动态过程中蕴含着极其丰富和有价值的信息。时间维度不再仅仅是计算的开销,而是智慧和信息的载体。
这一理念的转变,可能会深刻影响未来AI系统的设计思路。未来的模型架构可能会被设计成更容易暴露和利用其内部的中间状态,而不是将它们隐藏在黑箱之中。我们对AI的利用,也将从单纯地索取最终答案,升级为洞察其完整的“思考”轨迹。
7.2 AI安全与可靠性的新基石
在AI被越来越多地应用于高风险决策的今天,如何确保其安全性和可靠性是整个领域面临的核心挑战。时间语义熵(TSE)为此提供了一个强有力的评估工具。通过实时监测AI系统在推理过程中的语义一致性,我们可以在其输出看似合理的答案时,判断其内部状态是否稳定。一个TSE值异常高的结果,即使表面上看起来正确,也应该被标记为“低置信度”,需要人类专家进行复核。这对于避免AI在医疗、金融等关键领域“一本正经地胡说八道”具有不可估量的价值。
7.3 迈向可解释AI的重要一步
“黑箱”问题一直是阻碍AI获得更广泛信任的绊脚石。这项研究通过分析AI在不同时间步骤的输出变化,为我们提供了一条窥探其“思维链”的新路径。我们能够看到它是如何从一个想法跳到另一个想法,在哪些地方犹豫不决,又在何时茅塞顿开。这种对过程的理解,虽然还不是完全的“可解释”,但无疑极大地提升了AI系统的透明度,是迈向真正可解释AI(XAI)的重要一步。
总结
浙江大学联合团队的这项研究,如同一位细心的观察者,捕捉到了AI世界中一个转瞬即逝却至关重要的现象——“时间振荡”。它告诉我们,在追求人工智能更高智能的道路上,我们不仅要仰望星空,关注其最终能达到的高度,更要脚踏实地,审视其走过的每一步。
从发现“中间过程比最终答案更准确”这一反常识现象,到提出“时间语义熵”这一创新的评估体系,再到设计出“时间自一致性投票”和“时间一致性强化”这两种分别在推理端和训练端行之有效的解决方案,这项研究完成了一个从观察、理想到实践的完美闭环。
它揭示了一个深刻的道理,这个道理不仅适用于机器,或许也适用于我们人类:有时候,我们最初的直觉、中间的灵感,可能比反复权衡、过度思虑后的最终结论更加宝贵。这项研究的真正魅力在于,它不仅发现了AI的这一特性,更教会了我们如何去聆听和尊重AI在“思考”过程中的每一次呼吸与脉动。
归根结底,这项工作为我们打开了AI系统的一个全新维度——时间维度的智慧。通过深入挖掘和有效利用AI生成过程中的时间信息,我们不仅能显著提升当前系统的性能,更重要的是,为未来构建更智能、更可靠、更值得信赖的AI系统,指明了一条充满希望的康庄大道。
📢💻 【省心锐评】
这项研究巧妙地将AI的“思考过程”从成本变成了资产。它提醒我们,真正的智能不仅在于终点的正确,更在于抵达终点路径的稳健与一致。这是从“黑箱炼丹”迈向“透明工程”的关键一步。

评论