.png)


【摘要】ByteDance与复旦大学联合研发的全自动训练系统FTRL,通过创新的环境构建与奖励机制,使语言模型能高效学习使用工具,实现了小模型超越大型商业模型的卓越表现,且不损害通用能力,标志着AI向实用型万能助手迈出关键一步。
引言
当我们拿起智能手机,一个无形的生态系统便在指尖展开。拍照用相机,寻路用地图,计算用计算器——我们娴熟地在不同应用(工具)间切换,以应对纷繁复杂的需求。这背后,是人类与生俱来的、利用工具解决问题的本能。现在,试想一下,如果人工智能(AI)也能像我们一样,拥有一个随需应变的“工具箱”,并能灵活自如地调用其中的工具来完成任务,那将是怎样一番景象?
这并非遥远的科幻畅想,而是正在发生的现实。最近,由ByteDance的SEED团队与复旦大学联合完成的一项研究,就为我们揭开了这激动人心一幕的序幕。这项名为《Fully Automated Tool Learning from Reinforcement Learning and Language Models》(FTRL)的研究,由复旦大学的叶俊杰博士领导,成果已于2024年8月公布。研究团队构建了一套全自动的训练系统,旨在教会语言模型如何高效、准确地使用工具。这项工作的完整代码与数据已在GitHub上开放,供全球的研究者与开发者探索:https://github.com/bytedance/FTRL。
长期以来,大语言模型(LLM)给人的印象,更像一位困于书斋的博学之士。它能引经据典,对答如流,拥有惊人的知识储备。然而,一旦面对需要与现实世界交互、需要实际操作的任务,这位“书生”便常常显得力不从心。你问它“明天北京的天气如何?”,它只能根据训练数据中的过时信息进行推测,而无法主动查询实时天气预报;你让它“帮我预订一家评价不错的餐厅”,它也无法直接调用预订系统完成操作。这种知识与行动之间的鸿沟,极大地限制了AI在现实世界中的应用潜力。它就像一个满腹经纶却手无寸铁的智者,空有智慧,却无法改变周遭。
为了弥合这一鸿沟,学术界与工业界进行了诸多尝试,但始终面临两大难以逾越的障碍。第一个挑战,是为AI提供一个稳定可靠的“训练场”。现有的方法大多依赖于互联网上公开的API或服务作为AI的训练工具。但这就像让一个孩子在车水马龙的街道上学骑自行车,环境充满了不确定性。这些外部服务可能因服务器宕机而无法访问,可能因API更新而改变行为,返回的结果也可能不准确甚至充满噪声。在这样“脾气不定”的环境中,AI的训练过程既低效又不稳定,难以保证学习效果。
第二个挑战,则是如何建立一套公平客观的“考核标准”。如何评判AI是否真正“学会”了使用工具?传统方法往往依赖另一个更强大的AI模型来充当“考官”,对被训练模型的行为进行打分。这种“模型评模型”的模式,好比让一个学生去评判另一个学生的试卷,其评价结果难免受到“考官”模型自身偏见、知识局限和幻觉的影响,缺乏客观性和可信度。
面对这些棘手的难题,ByteDance与复旦大学的研究团队另辟蹊径,提出了FTRL这套完整的解决方案。它不仅是一个算法,更是一个从环境构建、奖励设计、数据收集到模型训练的全自动化闭环系统。这套系统如同为AI量身打造的一座设施完备、规则严明的“工具使用训练营”,旨在将AI从一个“理论家”锻造成一个“实干家”。本文将深入剖析这套系统的设计哲学、技术细节及其令人瞩目的实验成果,探讨它如何为AI的未来发展开辟一条全新的道路。
一、🛠️ 打造理想“训练场”:全自动环境构建流程
%20拷贝.jpg)
要训练出优秀的运动员,首先需要一个专业的训练场地。同理,要让AI学会使用工具,一个稳定、可控、可扩展的训练环境至关重要。FTRL系统的基石,正是一套精心设计的五阶段全自动环境构建流程。这个流程彻底摆脱了对外部服务的依赖,通过在本地生成和部署所有工具,为AI创造了一个完美的“沙盒实验室”。
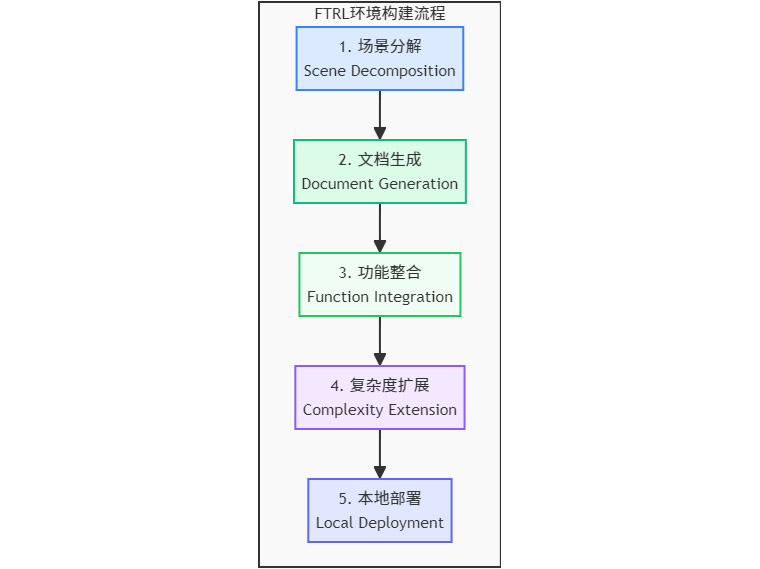
1.1 场景分解:从简单到复杂的“课程设计”
训练的第一步,是为AI规划一套科学的“课程大纲”。研究团队没有直接抛出复杂无序的现实问题,而是将它们系统性地分解为不同类型的子任务,并定义了四种由易到难的基本场景。这就像一位经验丰富的教练,会根据学员的水平,设计从基础动作到高难度组合的训练项目。
单跳场景(Single-Hop):这是最基础的训练科目,要求AI通过一次工具调用就解决问题。它考验的是AI对问题意图的精准理解和对工具的直接选择能力。
示例:查询游戏《艾尔登法环》的发布日期。AI只需准确调用
game_release_date_lookup工具并传入正确的游戏名称即可。
并行单跳场景(Parallel Single-Hop):难度稍有提升,要求AI同时处理多个相互独立的子问题,并将结果进行整合。这考验的是AI的多任务处理和信息汇总能力。
示例:查询今天和明天的国际原油价格,并进行比较。AI需要并行调用两次
oil_price_query工具,一次查询今天,一次查询明天,然后对返回的两个价格进行比较。
多跳场景(Multi-Hop):这是对AI逻辑推理能力的真正考验。问题被设计成一个任务链,前一个工具调用的输出是后一个工具调用的输入。这就像一场解谜游戏,AI必须按部就班,步步为营。
示例:查询2022年冬季奥运会的举办国,然后再查询该国在1937年时的首都名称。AI需要先调用
olympics_host_country工具找到举办国(中国),然后将“中国”作为参数,调用country_capital_in_year工具查询其在1937年的首都(南京)。
并行多跳场景(Parallel Multi-Hop):这是最复杂的场景,融合了并行处理和链式推理。AI需要同时处理多个独立的多跳任务,对规划和执行能力提出了极高的要求。
示例:分别查询加拿大和澳大利亚当前的人口数据,然后计算两国人口之和。AI需要启动两个并行的多跳任务链(可能每个查询本身就需要多步),最后将各自的结果汇总并执行加法运算。
通过这四种场景的组合与生成,FTRL系统能够构建出一个结构化、层次化的任务空间,让AI在循序渐进的学习中,稳步提升其工具使用能力。
1.2 文档生成:为每个工具配备清晰的“说明书”
有了任务场景,还需要为AI提供清晰的工具使用指南。在文档生成环节,系统会自动为每个子任务生成对应的工具文档(Docstring)。这份文档就像是工具的“说明书”,用自然语言详细描述了工具的功能、输入参数的名称、类型和含义,以及预期的输出格式。
这份自动生成的“说明书”至关重要。它将抽象的编程接口转换为了AI能够理解的自然语言描述,是AI连接问题意图与具体工具之间的桥梁。一个清晰、准确的文档,能让AI更快地理解“这把钥匙能开哪扇门”,从而做出正确的工具选择和参数填充。
1.3 功能整合:打造高效的“多功能工具箱”
在自动生成大量工具的过程中,难免会出现功能相似或重叠的情况。例如,可能会同时生成一个query_population_of_country工具和一个get_country_population工具。为了避免冗余,提高工具库的效率和整洁度,系统引入了功能整合环节。
系统会利用语言模型分析所有工具的功能描述,识别出那些语义上相似的工具,并将它们整合成一个功能更强大、更通用的新工具。例如,上述两个查询人口的工具可以被整合成一个统一的population_service工具,它既保留了原有的功能,又通过更泛化的接口设计,提升了复用性。这个过程好比整理一个凌乱的工具箱,将功能重复的螺丝刀合并成一套可更换批头的多功能螺丝刀,让工具箱更加精简高效。
1.4 复杂度扩展:从“基础算术”到“高等数学”的进阶
如果训练环境中的工具都过于简单,AI就会像一个只会做基础算术题的学生,一旦遇到复杂问题便束手无策。为了提升AI的泛化能力和应对复杂场景的能力,FTRL系统设计了一套巧妙的复杂度扩展策略。系统会有意地增加工具的“使用难度”,迫使AI学习更复杂的推理和适应能力。
研究团队设计了四种复杂度扩展策略:
功能泛化(Function Generalization):让原本功能单一的工具能够处理更多类型的任务。例如,一个只能查询“电影”信息的工具,可以被泛化为能够查询“电影、书籍、音乐”等多种媒体信息的
media_info_query工具。参数扩展(Parameter Extension):为工具增加更多的可选配置参数。例如,一个天气查询工具,除了必需的“城市”参数外,还可以增加“日期范围”、“温度单位”(摄氏/华氏)等可选参数,要求AI根据具体问题进行更精细的配置。
参数类型泛化(Parameter Type Generalization):将简单的参数类型(如字符串、数字)升级为更复杂的数据结构(如列表、字典)。例如,一个预订会议室的工具,其“参会人员”参数可以从单个字符串泛化为一个包含姓名和邮箱的字典列表。
工具集扩展(Tool Set Extension):在工具库中故意添加一些功能相似但非必需的“干扰”工具。这会增加AI在选择工具时的难度,迫使它更仔细地辨别不同工具之间的细微差别,从而锻炼其决策能力。
这个过程,本质上是在模拟真实世界中工具的复杂性和多样性,确保AI在训练营中接触到的挑战,能够与未来在“战场”上遇到的问题相匹配。
1.5 本地部署:构建完全可控的“实验室环境”
流程的最后一步,也是确保训练稳定性的关键一步,就是本地部署。系统会将经过上述所有环节处理后生成的工具,全部转换为可在本地执行的Python函数。同时,系统还会自动生成一个验证器(Validator),确保这些函数在给定输入时能够返回确定且正确的结果。
这一步的意义是革命性的。它彻底切断了对外部网络和第三方服务的依赖,将整个训练环境“私有化”。这意味着:
稳定性:不再有服务器宕机、网络延迟或API限流的困扰。
一致性:每次调用工具,只要输入相同,输出就完全一致,保证了训练过程的可复现性。
安全性:所有操作都在本地进行,无需担心数据泄露或外部服务的安全风险。
高效性:本地执行远快于网络请求,大大缩短了训练周期。
通过这五个环环相扣的自动化步骤,FTRL系统成功地构建了一个前所未有的、完全隔离且高度可控的工具使用训练环境。在这个“理想实验室”里,AI可以心无旁骛地进行成千上万次的试错与学习,为掌握复杂的工具使用技能打下坚实的基础。
二、🎯 设计公正“记分牌”:可验证的奖励机制
有了顶级的训练场,还需要一位公正严格的“裁判”。在强化学习的框架下,这个“裁判”就是奖励函数(Reward Function)。它负责评估AI的每一步行为,并给出一个分数(奖励),引导AI朝着正确的方向学习。如前所述,依赖其他AI模型进行评价存在主观偏差,而FTRL则设计了一套完全基于环境反馈、可客观验证的奖励机制。
这套机制的核心思想,是在两个关键指标之间寻求完美的平衡:精确度(Precision)和完整度(Recall/Completeness)。
2.1 精确度与完整度的权衡
让我们用一个通俗的比喻来理解这两个概念。假设AI的任务是“组装一辆玩具车”,这需要拧紧A、B、C三颗螺丝。
精确度:衡量AI调用工具的准确性。如果AI尝试拧了五次螺丝,其中四次都用对了螺丝刀和位置,那么它的精确度就很高。这好比学生解题时,每一步的计算和推理是否正确。一个高精确度的AI,不会胡乱调用工具,也不会填错参数。
完整度:衡量AI是否解决了所有必要的子问题。如果AI最终只拧紧了A和B两颗螺丝,漏掉了C,那么它的完整度就不高,即使它拧A和B的过程完美无瑕。这好比学生是否完成了试卷上的所有题目。
这两个指标有时是相互矛盾的。一个极端保守的AI,可能为了追求100%的精确度,只在有十足把握时才调用工具,导致很多子问题被遗漏,完整度极低。反之,一个激进的AI,可能为了解决所有问题而胡乱尝试,调用大量无关工具,导致精确度惨不忍睹。
因此,一个好的奖励机制,必须能够引导AI在这两者之间找到最佳平衡点。
2.2 F1-Score启发的平衡式奖励
研究团队从信息检索领域经典的F1-Score中获得灵感,设计了一种能够综合评价精确度和完整度的平衡式奖励函数。F1-Score是精确度和召回率的调和平均数,能够有效地惩罚极端情况。
具体到FTRL的奖励计算,系统会综合考虑以下几个因素:
n_solved:AI成功解决的子问题数量。n_total:任务包含的总子问题数量。n_tool_call:AI总共调用工具的次数。is_final_answer_correct:AI给出的最终答案是否正确。
基于这些可从环境中直接获取的客观数据,精确度和完整度可以被定义为:
精确度 (Precision) =
n_solved/n_tool_call完整度 (Completeness) =
n_solved/n_total
最终的奖励分数(Reward)是这两者的调和平均数,并结合最终答案的正确性进行加权:
Reward = (2 Precision Completeness) / (Precision + Completeness) * (1 + is_final_answer_correct)
这个公式的精妙之处在于:
鼓励高效:如果AI调用工具次数(
n_tool_call)远大于解决的问题数(n_solved),精确度会很低,导致总奖励下降。这有效抑制了AI滥用工具的行为。强调全面:如果AI解决的问题数(
n_solved)远小于总问题数(n_total),完整度会很低,同样导致总奖励下降。这鼓励AI努力解决所有子任务。结果导向:最终答案的正确性会使奖励翻倍,给予了最强的正向激励,确保AI的学习目标始终是解决整个问题。
2.3 奖励机制的客观性与重要性
这套奖励机制的最大优势在于其完全的客观性。所有的评价指标都直接来源于AI与本地环境的交互记录,不存在任何模糊地带或主观判断。就像一场数学考试,对就是对,错就是错,有唯一的标准答案。这彻底解决了“模型评模型”带来的偏见和不确定性问题。
为了验证这套平衡式奖励设计的优越性,研究团队还进行了消融实验,比较了四种不同的奖励函数:
实验结果雄辩地证明,一个精心设计的、平衡的奖励函数,对于成功训练出强大的工具使用模型至关重要。它就像航船的舵,确保AI这艘大船能够沿着最正确的航线,稳健地驶向目标。
三、📈 从训练到超越:惊人的实验成果
%20拷贝.jpg)
在搭建好“训练场”和“记分牌”之后,真正的训练开始了。研究团队首先让AI在构建好的环境中进行多轮交互,这个过程被称为数据收集。系统会详尽记录AI的每一步操作、工具调用的参数与结果、环境反馈以及最终的奖励分数,形成宝贵的训练数据。
随后,基于这些带有奖励信号的数据,研究团队采用了基于偏好的强化学习算法(如GRPO)来对模型进行微调。这种方法的思想很直观:让AI学会“趋利避害”。通过比较不同行为序列获得的奖励高低,模型会逐渐学习到哪些行为模式(“偏好”)能带来高分,哪些会导致低分,从而不断优化自身的决策策略。这就像训练一个孩子,通过表扬和批评,让他逐渐形成良好的行为习惯。
为了全面检验FTRL系统的有效性,研究团队设计了严谨而全面的实验。测试不仅包括在自建数据集上的“课内考试”(域内测试),还涵盖了在ToolHop、τ-bench和RoTBench这三个业界公认的公开数据集上的“校外联考”(域外测试),以评估模型的泛化能力。
3.1 显著的性能提升与泛化能力
实验结果令人印象深刻。无论是在何种规模的语言模型上,FTRL系统都展现出了立竿见影的改进效果。
以7B参数量的Qwen2.5模型为例,在使用FTRL-GRPO算法进行训练后,其在自建数据集上的综合表现(一种结合了成功率和效率的评分)从25.97分飙升至46.78分,提升幅度接近80%。这表明模型通过训练,确实掌握了更高效、更准确的工具使用策略。
更令人惊喜的是,这种能力并非简单的“死记硬背”。在完全陌生的公开数据集上,训练后的模型同样表现出色,展现了强大的泛化能力。这证明AI学到的不是针对特定工具的“应试技巧”,而是一套可迁移的、关于如何理解问题、规划步骤、选择工具的通用方法论。
3.2 “以小博大”:开源模型超越商业巨头
本次实验中最引人注目的发现,莫过于训练后的中小规模开源模型,在工具使用能力上实现了对顶级商业模型的逆袭。
研究团队将经过FTRL训练的8B和14B参数量的开源模型,与包括GPT-4o、Claude-4.0在内的业界顶尖商业闭源模型进行了正面对决。结果显示,在多个工具使用基准测试中,这些经过专门训练的“小模型”,其平均表现竟然超越了那些参数量远大于它们的“巨无霸”。
这一“大卫战胜歌利亚”式的结果,具有深远的行业意义。它表明,通过高效、自动化的专门训练,模型的“智慧”可以弥补“体量”上的不足。这为中小企业和研究机构利用相对廉价的开源模型,开发出在特定领域比肩甚至超越商业巨头的AI应用,提供了现实的可能性。
3.3 一个有趣的发现:推理模式并非万能灵药
在实验中,研究团队还观察到一个反直觉的现象。目前,许多模型都提供了“推理模式”(或称思维链,Chain-of-Thought),旨在通过让模型逐步思考来解决复杂问题。人们普遍认为这种模式在工具使用这类需要规划的任务上会表现更好。
然而,实验数据显示,虽然推理模式在复杂的多跳任务上确实优于非推理模式,但在简单的单跳任务上,其表现反而更差。这就像让一位数学家去算“1+1”,他可能会写下一长串的公理推导,反而不如普通人直接给出答案来得快和准。
这一现象揭示了当前推理机制的一个局限性:它们大多是为解决数学或逻辑推理问题而优化的,在工具使用场景下,这种“过度思考”有时会引入不必要的复杂性和错误。例如,在面对一个简单的查询任务时,推理模式下的模型可能会“脑补”出一些不存在的约束条件,从而选择了错误的工具或填写了错误的参数。
这提示我们,在工具使用的语境下,模型的推理能力需要被更精细地引导和塑造,而不是简单地套用现有的思维链模式。
四、🔬 深入探究:FTRL为何如此有效?
惊人的实验数据背后,隐藏着更深层次的机制。FTRL系统之所以能取得如此成功,并非偶然。研究团队通过细致的参数分析和案例剖析,为我们揭开了模型能力蜕变的神秘面紗,让我们得以一窥其“黑箱”之下的变化。
4.1 参数分析:训练究竟改变了什么?
一个核心问题是:强化学习的微调过程,究竟在模型的神经网络中留下了怎样的烙印?是为了使用工具而长出了新的“器官”,还是对已有的“大脑”结构进行了优化?
通过对模型参数更新的追踪,研究团队发现了一个关键现象:训练过程主要更新了模型底层的MLP(多层感知器)参数,尤其是网络结构中靠前几层的参数。
MLP可以被通俗地理解为神经网络中负责进行信息处理和特征提取的核心单元。而靠前的网络层,主要承担着理解和编码输入信息的基础性工作。这一发现揭示了FTRL训练的本质:
它并非简单地让模型死记硬背“遇到A问题就调用B工具”这样的僵硬规则。恰恰相反,训练的重点在于提升模型更底层的、更基础的能力,包括:
上下文理解能力:模型能更准确地从用户的复杂提问中,捕捉到核心意图和关键实体信息。
基础推理能力:模型能更好地理解问题内部的逻辑关系,为后续的工具选择和规划打下基础。
换言之,FTRL系统没有给AI强行灌输一套工具使用手册,而是通过实践训练,强化了它的“阅读理解”和“逻辑思维”能力。这种底层能力的提升,自然而然地带来了更强的泛化性。因为无论工具如何变化,准确理解问题、提取关键信息的需求是共通的。这就像教一个学生,不是让他背诵题库,而是教会他解题的思路和方法,这样他才能举一反三,应对各种新题型。
4.2 案例剖析:从“失误”到“精准”的蜕变
抽象的参数分析,不如具体的案例来得直观。通过对比训练前后的模型在具体任务上的表现,我们可以清晰地看到这种能力的飞跃。
案例一:政治继任者查询
问题:“谁是接替鲍里斯·约翰逊担任英国首相的保守党领袖?”
训练前模型(原始模型):模型能够识别出需要查询政治人物的继任者,但它在调用
successor_lookup工具时,错误地将参数position(职位)填写为Conservative Party leader(保守党领袖),而不是更准确的Prime Minister of the United Kingdom(英国首相)。这个细微的偏差导致工具无法返回正确答案。训练后模型(FTRL模型):模型表现得像一个经验丰富的政治分析师。它能准确地从问题中提取出两个关键信息:人物“鲍里斯·约翰逊”和核心职位“英国首相”。随后,它精准地调用工具,正确填写参数,从而一步到位地获得了正确答案“莉兹·特拉斯”。
这个案例生动地展示了模型在关键信息提取和参数映射能力上的巨大提升。
案例二:选举结果查询
问题:“在2020年美国总统大选中,乔·拜登在哪个州获得的选举人票数最多?”
训练前模型(推理模式):这个案例暴露了前文提到的推理模式的弊端。模型在推理过程中,虽然正确识别了需要查询每个州的选举人票,但它在最后一步调用
electoral_votes_lookup工具时,却因为“过度思考”,错误地将state参数填写为all(所有),而不是逐一查询或选择最有可能的州。这种逻辑上的跳跃导致了最终的失败。训练后模型(FTRL模型):模型展现出了清晰、直接的执行力。它准确地识别出需要查询的目标是“加利福尼亚州”(通常被认为是民主党票仓),并直接调用工具查询该州的选举人票数,最终获得了正确答案。
这个案例说明,FTRL的训练帮助模型抑制了无效的、甚至有害的“过度推理”,使其行为更加目标导向,决策更加果断和准确。
五、🛡️ 安全性验证:通用能力是否受损?
%20拷贝.jpg)
在为模型装备上强大的新技能时,一个不容忽视的风险是:这种专门化的训练是否会损害其原有的通用能力?这就像一位运动员在专攻短跑后,其长跑能力可能会下降。如果AI在学会使用工具后,其语言理解、数学推理或代码编写能力出现退化,那将是得不偿失的。
为了打消这一顾虑,研究团队进行了一项至关重要的“体检”——在六个业界公认的、衡量大模型通用能力的标准测试集上,全面评估了模型训练前后的表现。
这些测试集覆盖了广泛的领域:
MMLU:大规模多任务语言理解,考验模型的综合知识水平。
BBH:大语言模型基准测试,包含一系列具有挑战性的推理任务。
GSM8K & MATH:小学和高中水平的数学应用题,考验模型的数学推理能力。
HumanEval & MBPP:代码生成任务,考验模型的编程能力。
测试结果令人放心。数据显示,经过FTRL训练后,模型在上述所有通用任务上的表现基本保持稳定,甚至在部分任务上还出现了轻微的提升。
这一结果有力地证明了FTRL训练方法的安全性。它像一位优秀的教练,在为模型开启新技能树的同时,也精心维护了其已有的能力基础。这也再次印证了前文的参数分析结论:训练提升的是模型底层的通用能力,而非表层的特定技能记忆,因此这种提升能够正向迁移到其他任务中,而不会产生负面干扰。
六、🌐 框架的通用性与鲁棒性
一个优秀的解决方案,不仅要效果好,还要有广泛的适用性。FTRL系统在这方面同样表现出色,其框架设计展现了高度的通用性和鲁棒性。
算法无关性:无论是使用Reinforce++还是GRPO作为核心的强化学习算法,FTRL的整套框架都能与之无缝对接,并带来显著的性能改进。这表明系统的价值主要在于其创新的环境构建和奖励设计,而非绑定于某一种特定的训练算法。
模式普适性:无论是对于需要逐步思考的推理模式模型,还是对于直接输出答案的非推理模式模型,FTRL的训练都能带来一致的、可观的提升。这证明了该框架能够适应不同类型模型的决策机制。
持续改进性:研究团队跟踪了模型在多个训练轮次(Epoch)中的表现变化。结果显示,绝大多数模型在每一个新的训练轮次中,性能都有明显的持续提升。这说明训练策略能够为模型提供足够丰富的探索空间,避免其过早地陷入局部最优或产生过拟合,保证了训练过程的健康和高效。
这种跨算法、跨模式、可持续的改进效果,充分说明了FTRL并非一个“脆弱”的实验室方案,而是一个坚固、可靠、可广泛应用的工程化解决方案。
结论
回顾全文,ByteDance与复旦大学联合研发的FTRL系统,为“如何教会AI使用工具”这一核心挑战,提供了一份堪称典范的答卷。它通过一套全自动的五阶段环境构建流程,彻底解决了现有方法对外部服务不稳定的依赖,为AI创造了一个完美的本地“训练营”。同时,其设计的基于F1-Score的可验证奖励机制,用客观、公正的“记分牌”取代了充满偏见的人工或模型评价,确保了训练方向的正确性。
这项研究的意义,远不止于技术层面的突破。它更像是一套为AI量身打造的“职业培训课程”,通过系统性的、自动化的训练,成功地将语言模型从一个只会“纸上谈兵”的博学书生,转变为一个能够灵活运用各种工具解决现实问题的“万能助手”。
更重要的是,这套方法的全自动化和开源特性,极大地降低了研究和应用的门槛。它向我们证明,模型的强大,不仅取决于其参数规模,更取决于其所接受的训练质量。通过FTRL这样的高效训练范式,中小规模的开源模型也能爆发出超越商业巨头的惊人潜力。
随着这套方法的推广和应用,我们有理由相信,一个AI新时代正加速到来。未来的AI助手,将不再仅仅是知识的存储库,更是行动的执行者。它们能够主动调用合适的工具,为我们查询信息、预订服务、分析数据、控制设备……真正无缝地融入我们的工作与生活。这或许标志着AI从“知识库”向“工具箱”的决定性转变,也为我们迈向更通用的、真正能够“动手”解决问题的人工智能,铺就了一条坚实而清晰的道路。
📢💻 【省心锐评】
FTRL的精髓不在于教会AI用锤子,而在于全自动建好了从伐木到炼钢再到造锤子的全套工厂。它将竞争焦点从“谁的模型大”引向“谁的训练流水线更智能”。

评论