.png)


【摘要】 本文深入探讨了现代多模态大语言模型在文本-视频检索任务中存在的“候选项先验偏见”问题。通过剖析偏见产生的根源,文章详细介绍了一种名为BLiM的创新框架,该框架通过双向似然估计和候选项先验标准化技术,显著提升了AI系统的检索准确性和公平性,并展示了其在多个AI领域的广泛应用前景。
引言
当你在浩如烟海的视频网站中,轻轻敲下“小猫玩毛线球”的搜索指令时,屏幕上几乎瞬间浮现出最匹配的视频内容。这个看似天衣无缝的交互背后,是一套复杂而精密的智能检索系统在默默工作。我们早已习惯了它的高效与便捷,却很少思考一个问题:AI在做选择时,真的“大公无私”吗?
答案或许会令人感到意外。最新的研究揭示,这些看似客观的AI系统,实则内心藏着不为人知的“偏心”——它们并非总是根据你的真实需求来筛选,而是不自觉地偏爱某些特定类型的内容。这就像一位过分依赖“第一印象”的图书管理员,当你向他询问一本冷僻但高度相关的专业典籍时,他却可能视而不见,固执地向你推荐那些摆在门口、包装精美、借阅率高的“大众读物”。
这种现象被称为**“候选项先验偏见”(Candidate Prior Bias)**。近期,一项由韩国科学院(KAIST)金炫宇教授团队领衔,联合韩国大学与Meta GenAI共同完成的研究,系统性地揭开了这个问题的面纱。他们发现,即便是当前最先进的多模态大语言模型,在进行文本-视频检索时,也严重受困于此。系统倾向于选择那些在训练数据中高频出现的文本或视频,而非与用户查询最相关的选项。
这篇发表于2025年8月、题为《Bidirectional Likelihood Estimation with Multi-Modal Large Language Models for Text-Video Retrieval》的论文(arXiv:2507.23284v2),不仅精准地诊断了病灶,更开出了一剂良方。研究团队提出的BLiM(Bidirectional Likelihood Estimation with Multi-Modal Large Language Models)框架,通过一种巧妙的“双向思考”机制,让AI学会了从两个角度审视问题,从而更准确地判断内容间的真实关联。
本文将带您深入探索这场关于AI偏见的“诊断与治疗”。我们将一同剖析AI检索系统“固有偏见”的产生机理,理解BLiM框架如何通过双向思考和先验标准化技术“矫正”AI的认知,并领略这项技术在实验中取得的卓越成果及其广阔的应用前景。这不仅是一次技术的革新,更是一次对AI决策机制的深刻反思。
一、 AI检索的“隐秘角落”:候选项先验偏见探源 🐾

要理解AI为何会“偏心”,我们首先需要走进其工作的“幕后”,探寻那些隐藏在算法深处的“隐秘角落”。当我们使用搜索引擎寻找视频时,AI的核心任务是理解我们的文字描述,并在庞大的视频库中找到语义最匹配的内容。这个过程,远比表面看起来更具挑战性。
1.1 主流方法的运作与困境
当前,主流的解决方案是利用**多模态大语言模型(Multi-Modal Large Language Models, MLLMs)**来完成这项跨模态的匹配任务。这些模型如同精通多国语言的翻译官,能够同时理解文本、图像、音频和视频等不同形式的信息。其基本工作流程如下:
编码(Encoding): 当用户输入一段文字查询(如“日落时分的海滩”),模型会将其编码成一个数学向量。同时,视频库中的每一个候选视频也会被编码成相应的向量。这些向量可以被看作是内容在“AI大脑”中的高度浓缩的表示。
匹配(Matching): 模型会计算文本向量与每一个候选视频向量之间的“相似度”或“匹配度”。这个分数代表了模型认为该视频与文本描述的契合程度。
排序(Ranking): 最后,系统会根据匹配度得分从高到低对所有候选视频进行排序,并将得分最高的视频呈现给用户。
然而,韩国科学院的研究团队在这个看似逻辑严谨的过程中,发现了一个根本性的缺陷。AI模型在计算匹配度时,会无意识地受到**“候选项先验概率”(Candidate Prior Probability)**的严重影响。这个术语听起来有些学术化,但其概念却异常直白:模型会天然地偏爱那些在训练阶段见得多的、更“熟悉”的内容类型。
1.2 “汉堡包”与“牛排”的类比
为了更形象地理解这个问题,我们可以将其类比为一家餐厅的点餐系统。假设一个AI服务员在训练时,接触了成千上万份订单,其中90%都是汉堡和薯条,只有极少数是关于牛排或龙虾的。久而久之,这个AI服务员的“知识体系”就形成了强大的路径依赖。
当一位顾客前来询问:“有什么特别推荐的吗?”这位服务员几乎会本能地脱口而出:“汉堡和薯条!”这并非因为它分析了顾客的口味、着装或消费能力,而是因为“汉堡薯条”这个选项在它的“记忆”中拥有最高的出现频率,也就是最高的先验概率。即便顾客真正想吃的是一顿精致的晚餐,这个被数据“塑造”出的服务员也可能因为自身的偏见而错失良机。
在AI视频检索中,这种偏见表现得更为隐蔽和深刻。研究团队通过严谨的数据分析,揭示了这种偏见在文本和视频两个维度的具体表现。
1.3 文本偏见:对“冗长”与“重复”的非理性偏爱
在文本描述的选择上,AI的偏见尤为明显。研究发现,系统的候选项先验概率与两个文本特征呈现出惊人的强相关性:
文本长度(Text Length): 先验概率与文本长度的相关系数高达 0.97。这意味着,描述越长,无论其内容质量如何,系统就越倾向于选择它。一个冗长但空洞的描述,其“天生优势”远大于一个简洁但精准的描述。
重复短语(Repetitive Phrases): 先验概率与文本中重复短语数量的相关系数也达到了 0.93。那些包含大量重复词句的文本,例如“一只鸟在飞,一只白色的鸟在飞,一只白色的鸟在天空中飞”,会获得极高的先验概率。
这种偏好的根源在于大语言模型的自回归(Autoregressive)训练机制。这些模型通过预测序列中的下一个词来学习语言。在这一过程中,重复的、符合统计规律的语言模式更容易被模型学习和预测,因此在模型的内部评估中被赋予了更高的概率权重。当模型需要做选择时,它自然会倾向于那些更符合其“语言直觉”的选项,而非真正与查询内容语义最匹配的选项。
这种偏见会导致荒谬的结果。比如,当用户搜索一个关于“儿童在公园玩耍”的视频时,系统可能会返回一个关于“成年人办公室工作场景”的视频,仅仅因为后者的文字描述更长,且包含更多诸如“电脑”、“会议”、“报告”等常见商业词汇。
1.4 视频偏见:对“静态”与“简单”的潜在倾向
更令人担忧的是,这种偏见同样存在于视频内容的选择上。研究显示,AI系统倾向于选择那些场景相对静态、内容变化较少的视频。这类视频在训练数据中更容易被算法准确地标注和处理,其特征也更容易被模型捕捉和编码。
相比之下,那些内容丰富、场景切换频繁、动作复杂的动态视频,虽然可能更符合用户的搜索意图,但由于其信息密度高、处理难度大,在模型的评估体系中反而可能处于劣势。这就像一个学生在做阅读理解题时,倾向于选择那些段落简短、结构清晰的文章来回答,而回避那些思想深刻但行文复杂的长篇论述。
这个发现揭示了当前AI检索技术的一个重要盲区。尽管这些系统在表面上能够处理复杂的多模态信息,但它们的判断标准在很大程度上仍然依赖于训练数据的统计特征,而非对内容语义的深层理解。AI的“智能”在某种程度上被其学习过程中形成的“成见”所束缚,导致其决策并非总是基于理性的、针对具体问题的分析。
二、 破局之道:让AI学会“双向奔赴” 🤝
面对“候选项先验偏见”这个棘手的难题,研究团队没有选择在原有框架上修修补补,而是提出了一种颠覆性的解决方案:让AI学会双向思考。这个理念的核心在于一个简单而深刻的直觉——如果一段文字和一段视频是真正的“天作之合”,那么无论从哪个方向看,它们都应该表现出高度的匹配性。
2.1 传统方法的“单行道”
传统的检索方法本质上是一条“单行道”。它只问一个问题:给定这个视频(V),这段文字(T)有多大的可能性(P)是对它的准确描述? 用数学语言表达就是,它在努力最大化 P(T|V)。
这就像一个传统的相亲场景,只有一方(比如男方)在单向地评判另一方(女方)是否符合自己的标准,而女方的看法和感受则被完全忽略。这种单向的评判机制极易受到评判者自身偏见的影响。评判者可能会基于自己固有的偏好(比如偏爱某种外形或职业),而做出并非真正基于双方是否“般配”的判断。
在AI检索中,这种单向评估的弊端显而易见。当一个视频因为场景简单(高先验概率)而被系统“看好”时,即使它与查询文本的关联度不高,也可能因为其“天生优势”而在 P(T|V) 的计算中获得一个不错的初始分数,从而错误地排在前面。
2.2 BLiM框架的“双向思考”
BLiM框架的创新之处,在于它为这条“单行道”开辟了另一条反向车道,构建了一个“双向奔赴”的评估体系。在进行文本到视频的检索时,系统不仅会计算传统的**“候选项似然度”(Candidate Likelihood),即 P(T|V),还会计算一个全新的维度——“查询似然度”(Query Likelihood)**,即 P(V|T)。
P(V|T) 反过来问了另一个至关重要的问题:给定这段文字(T),这个视频(V)有多大的可能性(P)是它所描述的场景?
这就像在相亲中赋予了双方平等的评判权。只有当男方认为女方合适,并且女方也认为男方合适时,这次相亲才算得上是真正的成功匹配。
我们可以通过一个流程图来更清晰地理解这种差异:
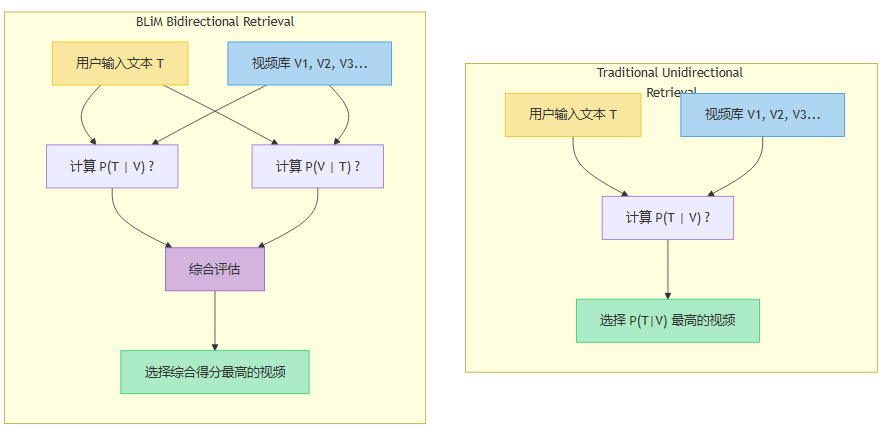
这种双向评估的巧妙之处在于,它能够有效地相互抵消偏见的影响。当系统因为某个视频包含常见静态场景(高视频先验)而给予过高的 P(T|V) 评分时,反向的 P(V|T) 评估会介入。它会检查,如果只看查询文本,我们有多大的可能会生成或指向这个特定的视频。如果视频内容与文字描述存在明显差异,反向评估就会给出一个较低的分数,从而拉低整体的匹配度,实现对偏见的“校准”。
2.3 训练AI掌握“双重技能”
为了实现这种双向思考,研究团队需要训练AI模型同时掌握两种不同的、但又互补的技能:
视频到文本生成能力(V→T): 这是传统多模态模型已经具备的能力,即观看一个视频后,能够生成准确的文字描述。这是计算 P(T|V) 的基础。
文本到视频特征生成能力(T→V): 这是BLiM框架的关键创新。模型需要学会根据一段文字描述,在“脑中”构想出对应的视频应该具备的核心特征表示。这些特征包含了视频的关键信息,如场景内容、物体关系、动作序列等。这就像一位经验丰富的导演,仅仅听到剧本描述,就能在脑海中构思出具体的画面、镜头和氛围。这是计算 P(V|T) 的基础。
研究团队采用了一种名为**“对比学习”(Contrastive Learning)**的技术来训练模型。在训练过程中,系统会同时接触到大量的(视频,正确文本)配对和(视频,错误文本)配对。模型的任务就是学习如何拉近正确配对在向量空间中的距离,同时推远错误配-对的距离。通过这种方式,模型不仅深刻理解了不同模态信息之间的对应关系,还能准确地估计这种对应关系的强度。
2.4 “查询似然度”的惊人发现
在实际应用中,BLiM系统会对每个候选项计算两个分数:候选项似然度 P(T|V) 和查询似然度 P(V|T)。最终的匹配分数是这两个分数的综合结果,从而既考虑了内容的相关性,又避免了单方面的偏见。
实验结果带来了令人震惊的发现:仅仅是引入查询似然度 P(V|T) 这一个维度,就能将检索的准确率提升30到40个百分点! 这个巨大的飞跃雄辩地证明了传统单向方法存在着严重的信息损失,而双向思考能够挖掘出被长期忽视的关键匹配信息。
更有趣的是,研究团队发现,在很多情况下,查询似然度 P(V|T) 往往比传统的候选项似然度 P(T|V) 更能准确地反映内容的真实匹配度。这个发现几乎颠覆了业界的传统认知,它表明,在多模态检索任务中,“这段文字是否能精准地指向这个视频”这个问题,可能比“这个视频是否能被这段文字所描述”更为重要和根本。
三、 精准“去偏”:为AI戴上“校准眼镜” 👓
.png)
如果说双向思考是让AI学会了从多个角度看问题,那么研究团队开发的另一项关键技术——“候选项先验标准化”(Candidate Prior Normalization, CPN),则是为AI戴上了一副“校准眼镜”,帮助它摘掉“有色眼镜”,更客观、更公平地评判每一个选项。
3.1 CPN的工作原理:减去“外观加分”
要理解CPN的工作原理,我们可以再次回到一个熟悉的场景:考试评分。想象一位语文老师在批改作文时,可能会不自觉地偏爱那些字迹工整、卷面整洁、篇幅较长的作文,即便这些作文的内容质量可能并不突出。这种基于“外观”的偏好,就是一种偏见。为了实现公平评分,一个有效的方法是在最终分数中,主动减去这部分由卷面带来的“外观加分”,从而让评分更真实地反映作文的思想深度和文学价值。
CPN的工作方式与此异曲同工。它的核心任务是估算并消除每个候选项在系统中的“天然优势”,也就是我们前面反复提到的“候选项先验概率”。它会先计算出每个文本或视频在没有任何特定查询的情况下,仅仅因为其自身特征(如长度、重复度、场景静态性等)而被模型选择的概率。然后,在进行最终匹配度计算时,将这个“天然优势分”从总分中减去或进行标准化处理。
这就像在田径比赛中,为了公平起见,根据风速等外部条件为选手调整最终成绩,或者为不同水平的选手设置不同的起跑线,以确保比赛结果真正反映选手的竞技实力,而非先天条件或外部环境的差异。
3.2 “即插即用”的优雅实现
CPN最巧妙的一点在于,它是一个**“即插即用”(Plug-and-Play)的后处理(Post-processing)模块**。这意味着它完全不需要对庞大而复杂的多模态大语言模型进行重新训练。这极大地降低了该技术的应用门槛。任何现有的检索系统,只需在最终排序阶段加入CPN这个简单的计算步骤,就能立刻享受到去偏见带来的性能提升。这就像给一副普通的眼镜加上一层偏振膜,不改变镜框和镜片本身,就能显著改善视觉效果,过滤掉恼人的眩光。
具体来说,CPN的实现公式可以简化为:
最终得分 = 原始匹配分 - α * log(候选项先验概率)
其中:
原始匹配分: 由BLiM双向思考机制计算出的综合分数。
候选项先验概率: 候选项(文本或视频)自身被选择的概率,这个概率可以被高效地估算出来。
α (alpha): 一个可调节的超参数,用于控制标准化(去偏)的强度。α越大,对先验概率的惩罚就越重。
这种设计的灵活性使得CPN能够适应各种不同的任务和数据集。研究人员可以根据具体应用场景的需求,通过调整α值,在“消除偏见”和“保留部分先验知识”之间找到最佳平衡点。
3.3 CPN的显著成效
研究团队通过大量实验,令人信服地验证了CPN的强大效果。他们发现:
在没有CPN的情况下,某些具有极高先验概率的文本(例如,那些冗长且充满重复的描述),会被超过 37% 的完全不相关的视频错误地匹配上。这是一个惊人的数字,意味着系统在很大程度上被“噪音”所主导。
应用CPN之后,这种极端的一对多错误匹配现象几乎完全消失。每个内容都更有可能与真正语义相关的查询配对,系统的决策变得更加“理性”和“专注”。
更令人惊喜的是,CPN的威力并不仅限于文本-视频检索。研究团队将其应用于其他多模态AI任务,同样观察到了一致且显著的性能提升。这雄辩地证明了“候选项先验偏见”是多模态AI系统中的一个普遍性、根源性的问题,而CPN提供了一个通用的、高效的解决方案。
四、 实验为证:数据揭示的压倒性优势 📊
理论的优雅最终需要通过实践的检验。研究团队在四个业界公认的、最具权威性的文本-视频检索数据集上,对BLiM框架进行了全面而严苛的测试。实验结果不仅令人印象深刻,更在多个指标上刷新了记录,展现了新方法的压倒性优势。
这些数据集各具特色,共同构成了对AI模型综合能力的全面考验:
DiDeMo: 包含超过1万个视频片段的大型数据库,内容多样。
ActivityNet: 专注于各类人类活动,包含200多种不同类型的活动视频,挑战性高。
LSMDC: 专门收集电影片段及其描述,内容包含复杂情节和多样化场景。
MSRVTT: 包含大量YouTube用户生成内容,视频质量和风格差异大,最接近真实世界应用场景。
4.1 准确率的“三级跳”
在这些数据集上,BLiM系统的表现堪称惊艳。以下是其在文本到视频检索任务(Text-to-Video Retrieval)中的核心指标(R@1,即首位命中率)与先前最先进方法(State-of-the-Art, SOTA)的对比:
这些数字背后,是用户体验的质的飞跃。在DiDeMo和MSRVTT数据集上超过12个百分点的提升,在AI研究领域是相当罕见的,相当于一个学生的考试成绩从“良好”直接跳跃到“优秀”,代表了方法论上的根本性突破。这意味着当用户进行搜索时,得到正确结果的概率大大增加,无效浏览的时间和精力被显著节省。
4.2 深入的消融研究(Ablation Study)
为了厘清成功的关键因素,研究团队还进行了深入的消融研究,即分别测试系统中每个组件的独立贡献。这项分析揭示了更多有趣的内幕:
传统方法的“真相”: 当单独使用传统的候选项似然度 P(T|V) 时,其表现相当糟糕,平均准确率仅为 27.3%。这个惊人的发现揭示了传统方法存在着根本性的缺陷,也解释了为何新方法能带来如此巨大的改进。这就像发现一个你一直信赖的指南针,其指向从一开始就是错误的。
查询似然度的“神力”: 单独引入查询似然度 P(V|T),就能带来 30-40个百分点 的巨大准确率提升。这证明了“反向思考”是解锁更高性能的关键钥匙。
CPN的“点睛之笔”: 在双向思考的基础上,再加入候选项先验标准化(CPN),又能进一步带来 4-8个百分点 的性能提升。这表明,在建立了正确的评估框架后,精准地“去偏”能够起到画龙点睛的作用。
4.3 定性分析:眼见为实
除了冰冷的数字,研究团队还提供了大量生动的定性案例,让我们直观地看到新旧方法的差异。
在一个典型的例子中,查询视频是一个婴儿在地上玩耍,一个女孩在旁边跺脚举手的场景。
传统方法返回的文本: “圣诞装饰品挂在墙上,一个姜饼人出现在屏幕上,另一个姜饼人也出现在屏幕上……”
分析: 这个文本与视频内容风马牛不相及。它之所以被选中,完全是因为它篇幅长,且包含大量重复短语(如“姜饼人”、“出现在屏幕上”),拥有极高的先验概率。传统方法被这种“虚假繁荣”所迷惑。
BLiM系统返回的文本: “一个婴儿低头看下面,一个女孩跺脚并举起手,孩子先向前走。”
分析: 这个描述简洁、准确,完美地捕捉了视频中的核心动态和人物关系。BLiM系统成功地穿透了先验概率的迷雾,找到了真正的语义匹配。
4.4 计算效率的考量
有人可能会担心,双向计算会带来巨大的计算开销。研究团队对此也进行了巧妙的设计。他们采用了一种**两阶段检索(Two-stage Retrieval)**策略:
初筛阶段: 首先使用一个计算成本较低的高效方法,从海量视频库中快速筛选出前K个(例如K=16)最有可能的候选项。
精排阶段: 然后,仅对这K个候选项进行精确但计算稍复杂的BLiM双向评估和CPN校准。
通过这种设计,新方法在带来巨大性能提升的同时,整体计算时间仅增加了约 5%,实现了性能与效率的完美平衡。
五、 跨界赋能:不止于视频检索的广泛影响力 🌐
.png)
BLiM框架的价值远不止于提升视频搜索的准确性。研究团队惊喜地发现,其核心思想——双向思考和先验标准化——具有惊人的通用性,能够像一把“万能钥匙”,解锁多个不同多模态AI任务的性能瓶颈。这证明了“候选项先验偏见”是AI领域的一个共性问题,而BLiM为此提供了一套行之有效的通用解决方案。
5.1 文本-图像检索
研究团队将BLiM技术应用于经典的文本-图像检索任务,在Flickr30K和COCO这两个权威数据集上进行了测试。结果显示,新方法在四个核心子任务中的三个都达到了业界最佳性能(SOTA)。特别是在Flickr30K的文本到图像检索中,准确率提升了 2.4个百分点。这个结果有力地证明了BLiM的理念可以无缝地从视频迁移到静态图像,其价值在不同媒体形式间具有高度的一致性。
5.2 视觉问答(Visual Question Answering, VQA)
视觉问答要求AI系统不仅要“看懂”图像,还要基于图像内容回答自然语言提出的复杂问题。传统VQA系统常常过度依赖文本中的语言先验知识,导致“看图说话”变成了“闭眼瞎猜”。例如,当被问到图片里的人在喝什么时,系统可能会因为“咖啡”在训练数据中与“喝”这个动词高频共现,而直接回答“咖啡”,即使图片里的人明明在喝茶。
应用CPN技术后,系统在七个不同的VQA评测基准上都实现了性能提升,平均改进幅度达到了惊人的 4-12个百分点。
在一个生动的案例中,系统被展示一张图片,并被提问:“这个人打开门之前做了什么?”
传统方法回答: “拿杯子。” (因为“拿杯子”后“开门”是训练数据中常见的一种行为序列)
应用CPN后回答: “拿书。” (这才是图片中真实发生的事情)
这种改变看似微小,却反映了AI从**“基于统计的猜测”到“基于视觉的推理”**的根本性转变。
5.3 视频/图像描述生成
描述生成任务要求AI为给定的视频或图像生成一段流畅、准确的文字描述。传统系统生成的描述常常充满套话、重复内容,甚至出现事实性错误(Hallucination),这些问题很大程度上也源于对语言模式的过度依赖。
CPN通过降低对文本先验的依赖,鼓励模型更多地关注视觉内容本身,从而生成了更准确、更多样化、更忠实于原文的描述。在六个不同的评测数据集上,应用CPN的系统都展现出了持续的性能提升。
这种广泛的适用性,根源在于现代多模态AI系统共享的架构基础。无论是检索、问答还是生成,它们的核心都离不开一个大规模语言模型。而只要使用了语言模型,就不可避免地会引入其在训练过程中学到的文本统计规律。BLiM和CPN技术,正是对症下药,精准地校准了这种由语言模型带来的系统性偏见。
六、 追本溯源:深入理解偏见的“基因” 🧬
为了彻底根治AI的“偏心病”,我们不仅需要有效的“药物”,更需要深入理解病症的“病理”和“基因”。研究团队为此进行了细致入微的分析,揭示了候选项先验偏见产生的根本原因及其具体的表现形式。这些发现,为未来AI系统的设计和优化提供了宝贵的启示。
6.1 偏见的量化分析:数字背后的真相
通过对海量文本数据的统计分析,研究团队量化了偏见的具体表现,其结果令人触目惊心:
长度偏见(Length Bias): 如前所述,文本长度与先验概率的相关性高达 0.97。这意味着,在AI眼中,一篇冗长平庸的文字,其“天生权重”几乎总是高于一篇精炼深刻的短文。这直接导致了系统对“长篇大论”的非理性偏爱。
重复偏见(Repetition Bias): 重复短语数量与先验概率的相关性也达到了 0.93。这源于语言模型的自回归特性——模型在预测下一个词时,重复的模式是最容易预测的,因此被赋予了极高的概率。这解释了为何那些内容空洞、不断重复的描述反而能得到AI的“青睐”。
视频内容偏见(Video Content Bias): 在视频端,系统同样存在明显的偏好。静态场景或内容变化平缓的视频,由于其特征在时序上更稳定,更容易被模型编码和匹配,因此获得了更高的先验概率。而那些充满动感、信息丰富的视频,反而因为其“复杂性”而受到“歧视”。
6.2 偏见的可视化:一图胜千言
为了让人们更直观地感受到偏见的严重性,研究团队创建了一系列分析图表。在一项包含1000个查询-候选对的实验中,他们绘制了匹配关系的分布图:
传统方法(左图): 图像显示出一种极端的“多对一”匹配模式。一个具有极高先验概率的文本(图中的一个点),竟然吸引了 374个 完全不同的视频(指向该点的线)作为其最佳匹配。整个匹配图谱呈现出一种极度不健康的、向少数几个“明星”候选项集中的状态,导致了检索结果的严重扭曲和同质化。
BLiM + CPN方法(右图): 图像则呈现出一种健康、均衡的“一对一”匹配模式。绝大多数内容都能找到自己唯一的、最相关的匹配对象。不合理的集中现象完全消失,匹配关系恢复了其应有的多样性和准确性。
6.3 偏见的深层根源:大语言模型的“原罪”
这些分析最终指向了一个更深层次的技术哲学问题:AI系统做出判断的根本依据是什么? 传统方法实际上是基于**“什么更常见?”(What is more common?)来做决策,而非“什么更相关?”(What is more relevant?)**。这种看似微妙的区别,在实际应用中却会导致截然不同的用户体验。
这个问题的根源,与大语言模型(LLMs)的基础训练范式——“下一个词预测”(Next Token Prediction)——密切相关。模型通过学习海量文本数据来掌握语言的统计规律。在这个过程中,它们不可避免地会将“高频出现”等同于“高概率”,将“符合统计规律”等同于“正确”。当这些被文本统计规律深度“塑造”过的模型被应用于需要理解视觉、听觉等多模态信息的任务时,它们会不自觉地将这种在文本世界学到的“偏见”泛化到其他模态,从而影响其对视觉信息的客观判断。
可以说,候选项先验偏见,在某种程度上是当前主流大语言模型训练方式所带来的“原罪”。而BLiM和CPN的成功,正是在于它们没有试图去改变模型的“本性”,而是通过引入外部的、更对称和公平的评估框架,来校准和对冲这种与生俱来的偏见。
七、 未来展望:从实验室走向现实世界 🚀
.png)
BLiM技术的成功,不仅是一次学术上的突破,更预示着其在真实世界应用中的巨大潜力。随着视频内容在互联网上呈指数级增长,准确、高效、公平的检索技术正变得前所未有的重要。
7.1 赋能核心应用场景
视频搜索引擎: 新技术将直接改善数十亿用户的日常搜索体验。无论是YouTube、TikTok,还是各类专业视频平台,更精准的搜索意味着用户能更快地找到所需内容,无论是用于教育、娱乐还是新闻消费。
内容创作与媒资管理: 视频创作者、新闻记者、影视剪辑师将从中极大受益。他们可以从海量的素材库中,以前所未有的效率和精度找到所需的视频片段,从而极大地提升创作效率和质量。博物馆、图书馆等机构也能更有效地管理和盘活其珍贵的视频档案。
商业与电商: 在电商平台,消费者可以更准确地搜索到展示商品特定功能的视频,而不是被那些拍得更长或更流行的视频所误导。这将帮助消费者做出更明智的购买决策,提升平台的转化率和用户满意度。
7.2 引领AI技术发展方向
从更宏观的技术发展角度看,BLiM代表了多模态AI发展的一个重要新方向:
对称性与公平性: “双向思考”的理念强调了在处理跨模态信息时,不同模态应被赋予平等的“话语权”。未来的AI系统可能会更多地采用这种对称性思维,来构建更公平、更鲁棒的决策模型。
AI去偏见化(Debiasing): CPN提供了一种轻量级、即插即用的去偏见方案,为解决AI公平性问题提供了宝贵的新思路。随着AI在金融、医疗、司法等高风险领域的应用日益广泛,如何减少系统偏见、提高决策公平性,已成为一个核心议题。
可解释性(Explainability): 通过对比双向评分的差异,研究人员和开发者可以更好地理解系统的决策过程,诊断出潜在的错误来源。例如,当P(T|V)很高而P(V|T)很低时,我们就能高度怀疑系统受到了候选项先验的干扰。这种增强的可解释性,对于构建可信赖的AI系统至关重要。
7.3 未来的探索空间
这项研究也为未来的工作打开了新的大门。研究团队提到,双向思考的理念可以进一步扩展到**“多向思考”**,在处理包含文本、视频、音频等多种模态的内容时,综合考虑所有模态之间的相互关系。同时,先验标准化技术也可以结合更多的上下文信息,实现更动态、更精细化的偏见校正。
总结
从最初发现AI检索系统令人意外的“偏心”,到深入剖析其背后的“候选项先验偏见”,再到提出革命性的BLiM框架,韩国科学院团队的这项研究为我们上演了一场精彩的“AI诊断与治疗”之旅。他们不仅揭示了当前多模态大语言模型的一个根本性缺陷,更通过“双向思考”和“先验标准化”这两剂“良药”,成功地校准了AI的认知,使其判断回归到对内容本身的关注。
这项工作的影响是深远且广泛的。它不仅在文本-视频检索领域取得了SOTA级别的突破,更以其卓越的通用性,为图像检索、视觉问答、描述生成等一系列多模态任务带来了性能的显著提升。它告诉我们,构建更智能的AI,有时并不在于堆砌更大的模型或更多的数据,而在于设计更聪明、更公平的评估机制。
说到底,这项研究解决的不仅仅是一个技术难题,更是对AI系统如何理解和处理信息这一根本性问题的深刻反思。通过让AI学会更平衡、更客观地看待世界,我们正向着构建更可信、更有用、更能服务于人类共同利益的人工智能系统,迈出坚实而重要的一步。当AI不再被内容的“外表”所迷惑,而能真正洞察其“灵魂”时,它才能成为我们真正值得信赖的智能伙伴。
📢💻 【省心锐评】
“双向验证”与“先验校准”,BLiM框架直击多模态AI偏见的痛点。这不仅是技术的精进,更是AI迈向公平与深度理解的哲学思辨,价值非凡。

评论