.png)


【摘要】本文深度剖析了伊利诺伊大学等团队关于AI视觉推理模型“顿悟时刻”现象的最新研究,揭示了多模态AI自我验证能力的短板及其对未来AI发展的深远影响。文章结合实验数据、技术原理与行业趋势,系统梳理了AI推理、生成与验证机制的本质差异,并对AI在实际应用中的能力边界提出了理性建议。
引言
在人工智能的浩瀚星海中,AI的“自我觉醒”一直是人类最为着迷的议题之一。我们总是好奇:AI会不会像人一样,突然在某个瞬间灵光乍现,意识到自己的错误,然后自我修正?尤其是在那些能“看图说话”的视觉语言模型(VLMs)身上,这种“顿悟时刻”似乎更让人浮想联翩。毕竟,AI已经能在围棋、象棋、写作、绘画等领域大放异彩,难道它们真的会像人类一样,在推理过程中突然“醒悟”吗?
最近,伊利诺伊大学厄巴纳-香槟分校与密歇根大学安娜堡分校的研究团队,针对这一现象做了一次极为细致的“解剖”。他们不仅用严谨的实验方法验证了AI的“顿悟时刻”是否真实存在,还揭示了视觉语言模型在自我验证能力上的致命短板。本文将带你深入这项研究的技术细节,结合行业现状与未来趋势,全面解读AI推理与自我反省的边界。

一、🌟 AI的“顿悟时刻”——现象、误区与真相
1.1 “顿悟时刻”是什么?人类与AI的灵光乍现
1.1.1 人类的顿悟:灵感与反思的交汇
在心理学和认知科学中,“顿悟时刻”(Aha Moment)指的是人在解决问题时,突然意识到关键线索或发现错误,从而豁然开朗的瞬间。这种体验常常伴随着强烈的情感反应和自我反省,是人类高级智能的体现。
1.1.2 AI的“顿悟”:表象还是本质?
近年来,随着大语言模型(LLMs)和视觉语言模型(VLMs)的崛起,研究者们发现AI在推理过程中也会出现类似“等等,我刚才想错了”的自我修正行为。比如,AI在解答数学题时,可能会在中途突然“反悔”,推翻前面的结论,重新推理。这种现象被称为AI的“顿悟时刻”。
但问题来了:AI的“顿悟”到底是真正的自我反省,还是训练数据和算法机制下的“假动作”?这正是本次研究要解答的核心问题。
1.2 视觉语言模型的推理能力:进步与瓶颈
1.2.1 视觉语言模型的崛起
视觉语言模型(VLMs)是近年来AI领域的明星。它们能同时处理图像和文本,实现“看图说话”、“图文推理”等复杂任务。典型代表如GPT-4V、LLaVA、MiniGPT-4等。这些模型在多模态理解、视觉问答、图像描述等任务上表现优异,被广泛应用于教育、医疗、自动驾驶等领域。
1.2.2 推理能力的提升:从“多想一步”到“自我纠错”
研究发现,让AI在推理时“多想一步”——比如采用“思维链”(Chain-of-Thought, CoT)提示、生成多个答案再筛选——能显著提升准确率。强化学习(RL)进一步让AI具备了自我纠错的能力,出现了类似人类的“顿悟时刻”。
1.2.3 误区:AI的自我修正能力被高估了吗?
尽管AI在生成答案时表现得越来越像人,但它的自我验证能力——即判断自己答案对错的能力——是否真的可靠?尤其是在多模态场景下,AI能否像人一样,真正“反省”并修正错误?这正是本次研究的突破点。
%20拷贝-cjha.jpg)
二、🧪 实验设计:AI的“考试”与推理策略大比拼
2.1 实验对象与数据集
2.1.1 主要模型
本次研究选取了多种主流视觉语言模型,涵盖不同规模和训练方式:
R1-VL系列(2B、7B参数量)
VLAA-Thinker系列(3B参数量)
VL-Rethinker系列(7B参数量)
这些模型均经过强化学习训练,具备一定的自我纠错能力。
2.1.2 数据集
GeoQA170K:以几何推理题为主,考查模型的空间理解与逻辑推理能力。
MathVista:涵盖多种数学视觉问题,兼具图像与文本信息,难度较高。
2.2 推理策略对比
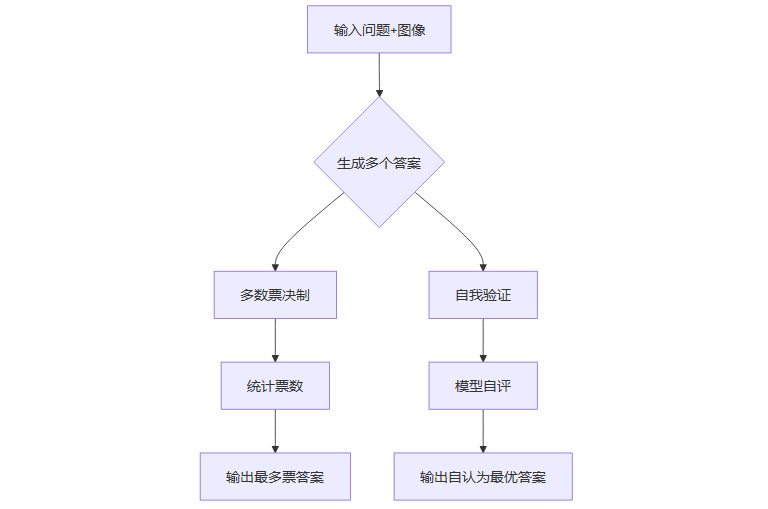
2.2.1 多数票决制(Majority Voting)
原理:模型独立生成多个答案,最终以“票数最多”的答案为准。
优势:依赖模型的生成能力,能有效规避偶发性错误。
类比:就像一群学生各自答题,最后选最多人选的答案。
2.2.2 自我验证最优选择法(Self-Verification)
原理:模型先生成多个候选答案,再自我评判哪个答案最好。
优势:理论上能发挥模型的自我反省与判断能力。
类比:学生做完题后,自己检查并挑选最优解。
2.2.3 策略流程图
2.3 实验流程与评测方法
每个模型在两个数据集上,分别采用两种推理策略进行测试。
评测指标为准确率(Accuracy),即最终答案与标准答案的匹配率。
采用GPT-4o作为“裁判”,自动检测模型输出中的“顿悟时刻”行为,包括回溯(backtracking)和验证(verification)。
三、📊 实验结果:数据背后的真相
%20拷贝-zafy.jpg)
3.1 多数票决制 vs. 自我验证:谁更胜一筹?
3.1.1 主要实验数据
3.1.2 结果解读
多数票决制在绝大多数场景下优于自我验证。
某些模型(如VLAA-Thinker-3B)在自我验证时准确率大幅下降,甚至比贪心解码还差。
只用文本验证有时比用图像+文本更准,反常现象引发深思。
3.1.3 现象总结
视觉语言模型的生成能力(出答案)远强于验证能力(判断答案好坏)。
自我验证机制并未带来预期的“自我提升”,反而可能拖后腿。
3.2 “顿悟时刻”检测:表面现象还是实质提升?
3.2.1 自动检测方法
利用GPT-4o自动识别模型输出中的“回溯”和“验证”行为。
统计含“顿悟时刻”回答的准确率与普通回答的对比。
3.2.2 关键数据
VL-Rethinker-7B在多数票决制下,含“顿悟时刻”回答准确率为65.5%。
但“潜在恢复率”极低:即使有正确且含“顿悟时刻”的答案,最终被选中的概率不足20%。
3.2.3 结论
“顿悟时刻”并未显著提升模型的最终表现。
这些行为更像是训练过程中的“副产品”,而非真正的智能反省。
3.3 图像信息的“反作用”:为何看图反而更差?
3.3.1 反常现象
某些模型在自我验证时,去掉图像信息反而准确率更高。
例如,VLAA-Thinker-3B在GeoQA上,文本验证准确率高于图像+文本。
3.3.2 可能原因
视觉信息未被有效利用,反而引入噪声或干扰。
模型在验证阶段更依赖文本,视觉信息整合能力不足。
3.3.3 行业启示
多模态AI的“融合”远未达到理想状态。
视觉语言模型在生成阶段能用好图像,但在验证阶段“掉链子”。
四、🔬 技术剖析:生成与验证的鸿沟
4.1 生成能力与验证能力的本质差异
4.1.1 生成能力
主要指模型根据输入生成合理答案的能力。
强化学习等训练方法极大提升了这一能力。
4.1.2 验证能力
指模型判断、比较多个答案优劣的能力。
需要更高层次的抽象、归纳与反思。
4.1.3 生成-验证差距的根源
当前训练方法偏重生成,忽视验证。
缺乏针对性训练,导致模型“会做题,不会检查”。
4.2 训练机制的局限性
4.2.1 强化学习的偏向
RL主要优化“生成正确答案”的奖励。
很少涉及“如何判断答案好坏”的训练。
4.2.2 多模态融合的难题
视觉与文本信息在生成阶段能协同,但在验证阶段难以整合。
现有架构缺乏“多模态自我评估”机制。
4.2.3 训练与推理流程对比表
4.3 未来改进方向
4.3.1 新型训练方法
引入“多模态自我验证”奖励机制。
设计专门的验证任务,提升模型的自我评估能力。
4.3.2 架构创新
开发专门的“验证模块”,与生成模块协同工作。
探索“多专家系统”,让不同子模型分工合作。
4.3.3 评估与优化策略
建立更细致的多模态评测体系。
动态调整生成与验证的权重,实现能力均衡。
五、🌍 行业影响与应用启示
%20拷贝-fzhv.jpg)
5.1 AI能力边界的再认识
5.1.1 不可盲信AI的自我评估
当前视觉语言模型的自我验证能力有限。
在关键任务中,不能完全依赖AI的自我判断。
5.1.2 多模态AI的“伪智能”风险
“顿悟时刻”更多是表面现象,未必带来实质提升。
需要警惕AI“自信但不靠谱”的输出。
5.2 实际应用建议
5.2.1 多答案生成+人工筛选
在视觉推理任务中,建议让AI生成多个答案,由人类最终选择。
避免完全依赖AI的自我验证,降低风险。
5.2.2 保持批判性思维
用户应对AI输出保持质疑和审慎,特别是在高风险场景。
结合多源信息,提升决策安全性。
5.2.3 适用场景列表
结论
伊利诺伊大学等团队的这项研究,为我们揭开了AI视觉推理模型“顿悟时刻”的神秘面纱。事实证明,当前视觉语言模型的自我验证能力远未达到人类水平,所谓的“顿悟时刻”更多是训练机制下的表面现象,而非真正的智能反省。多数票决制依然是提升准确率的有效手段,而自我验证机制则暴露出多模态AI在能力结构上的短板。
这项研究不仅为AI技术发展指明了新的方向——即提升多模态自我验证能力,更提醒我们在实际应用中要理性看待AI的能力边界。未来,只有通过创新训练方法、架构设计和评估体系,才能让AI真正具备“自我反省”的智慧,迈向更高层次的智能。
📢💻 【省心锐评】
“AI的‘顿悟’不过是表象,验证能力才是真瓶颈!多模态推理路还长,研发需聚焦验证机制,安全应用刻不容缓!”

评论