.png)
%20%E6%8B%B7%E8%B4%9D-gdvq.jpg)

【摘要】通过VLM在生成早期动态识别并排除常见概念,该方法迫使扩散模型跳出数据分布的“舒适圈”,在保证功能性的前提下,高效生成真正新颖的图像。
引言
在文生图(Text-to-Image)领域,我们见证了扩散模型(Diffusion Models)带来的巨大变革。模型能够以前所未有的保真度和细节,将文本描述转化为视觉图像。然而,一个深层次的挑战随之浮现。当用户请求“创意”、“新颖”或“独特”的内容时,模型输出的结果往往只是对已知概念的重组或变体。一只蓝色的猫,或是一条长着翅膀的狗,这些并非真正的创新,而是对训练数据中常见范式的浅层修饰。
这种现象并非模型能力的缺陷,而是其设计目标的必然结果。模型被训练来拟合数据分布,生成“典型”且“高质量”的图像。这导致了一种固有的“创意惰性”。模型倾向于走向概率最高的路径,也就是它见过最多的、最熟悉的那些概念。
Adobe研究院联合多所高校提出的一项研究,为破解这一困境提供了全新的工程化思路。他们没有尝试去定义“什么是创意”,而是反其道而行之,在生成过程中实时告诉模型“什么不是创意”。这种被称为**VLM引导的自适应负向提示(VLM-guided Adaptive Negative Prompting)**的机制,通过动态排除法,系统性地将模型推向其可能性空间中的未知领域。这不仅是一种技术上的巧妙实现,更代表了一种关于机器创新的范式转变。
🎨 一、问题的根源:AI创意生成的“舒适圈”
%20拷贝.jpg)
要理解新方案的价值,必须先剖析当前AI生成模型在创意任务上面临的根本性障碍。这些障碍源于其训练数据、优化目标和现有解决方案的内在局限。
1.1 训练数据的“典型性陷阱”
扩散模型的能力根植于其庞大的训练数据集。这些数据包含了数十亿张来自互联网的图像,覆盖了人类世界的方方面面。模型通过学习这些数据,掌握了物体、场景、风格的统计规律。
这个过程也带来了一个副作用,即路径依赖(Path Dependency)。
高频概念主导:数据集中,“猫”、“狗”、“汽车”等常见物体的图像数量远超于“犰狳”或“蒸汽朋克飞艇”。模型在去噪过程中,自然会倾向于将模糊的噪声解释为它最熟悉的高频概念。
“平均”而非“卓越”:为了在庞大的数据集上收敛,模型学习到的是各类概念的“平均”或“典型”形态。这使得它在生成标准物体时表现出色,但在创造从未见过的实体时,缺乏想象力的根基。
因此,当模型收到一个模糊的“创意宠物”指令时,其内部的概率流会本能地导向“猫”或“狗”的特征空间,因为这是阻力最小、概率最高的路径。
1.2 优化目标的内在矛盾
AI模型的训练和推理,本质上是一个优化过程。在图像生成任务中,优化的目标通常围绕两个核心。
保真度(Fidelity):生成的图像需要清晰、真实,符合物理规律和常识。
对齐度(Alignment):生成的图像需要与输入的文本提示紧密相关。
这两个目标共同塑造了一个“好”图像的标准。一个“好”的杯子应该看起来能装水,一个“好”的汽车应该有轮子。这种对“好”的定义,天然地与“创意”的某些方面相冲突。真正的创意往往意味着打破常规,偏离典型范式。
当优化目标倾向于生成清晰、可辨认、符合大众认知的内容时,模型实际上被鼓励去复现那些最安全、最标准的模式。这加剧了模型陷入“套路”的倾向。
1.3 现有创意生成方案的局限
为了提升AI的创意能力,业界已经进行了一些探索。但这些方法或多或少都存在不足。
提示词工程(Prompt Engineering)
方法:在提示词中加入“创意的”、“新颖的”、“想象中的”等修饰词。
局限:实验证明,这种方法效果非常有限。模型会将这些词理解为一种风格或属性,但生成的核心对象依然是常见的。它可能生成一个色彩斑斓的杯子,但那仍然是一个杯子。
静态负向提示(Static Negative Prompting)
方法:用户手动在负向提示中输入不希望出现的元素,如“猫, 狗, 鸟”。
局限:这种方法依赖用户预知模型可能会生成的“套路”。它无法在生成过程中动态适应,如果模型在避开猫狗后又转向了兔子,静态提示无法应对。
概念组合与编辑(Concept Combination & Editing)
方法:一些研究(如ConceptLab)尝试通过算法组合或编辑现有概念来创造新物体。
局限:这类方法虽然能产生新奇的视觉效果,但常常以牺牲**有效性(Validity)**为代价。生成的“创意杯子”可能没有容器结构,无法装水;“创意沙发”可能形态怪异,无法坐人。它破坏了对象的核心功能属性。
下表总结了这些方法的对比。
这些局限表明,我们需要一种全新的机制。它必须是动态的,能在生成过程中实时干预;它必须是智能的,能自主识别并避开套路;最重要的是,它必须在提升创意性的同时,维持有效性。
🎨 二、核心机制:VLM引导的自适应负向提示
Adobe团队提出的方案,其精妙之处在于它并未试图去定义或寻找创意,而是通过一个聪明的“排除法”来倒逼创意产生。其核心是利用一个外部的、具备多模态理解能力的“裁判”——视觉语言模型(VLM),来引导扩散模型的生成路径。
2.1 范式转换:从“正向指定”到“反向排除”
传统图像生成是“正向指定”的模式。用户通过提示词告诉模型“去哪里”。例如,“画一只猫”。
新范式则是“反向排除”。用户依然给出目标(如“画一个创意宠物”),但系统在生成过程中不断告诉模型“不要去哪里”。
初始状态:扩散模型从一个纯噪声图像开始。
迭代去噪:在每一步(timestep),模型都会对噪声进行一些处理,使其逐渐清晰化。
VLM介入:在某些步骤,系统会将当前的、仍然很模糊的中间状态图像输入给VLM。
实时判断:VLM被提问:“这张图中正在形成什么物体?”如果VLM回答“猫”,系统就认为模型正在走向“套路”。
动态更新“黑名单”:系统会将“猫”这个概念动态地添加到该次生成的负向提示列表中。
路径修正:在后续的去噪步骤中,扩散模型会受到这个新增的负向提示的影响,从而主动避开与“猫”相关的特征,被迫探索其他的可能性。
如果模型在避开“猫”之后,又开始倾向于形成“狗”的特征,VLM会在下一步的检查中识别出“狗”,并将其也加入“黑名单”。这个“黑名单”在生成过程中不断累积,像是在一个巨大的迷宫中,VLM不断地为模型关上一扇扇通往“陈词滥调”的门,最终迫使它找到一条无人走过的新路。
这种机制的本质,是一种约束下的创新。就像诗人需要在格律的约束下创作出优美的诗句,AI也在“禁止清单”的约束下,被激发出了前所未有的创意。
2.2 工作流程拆解
整个流程可以被看作是一个在扩散模型采样循环(sampling loop)中嵌入的反馈控制系统。
我们可以用一个流程图来清晰地展示这个过程。
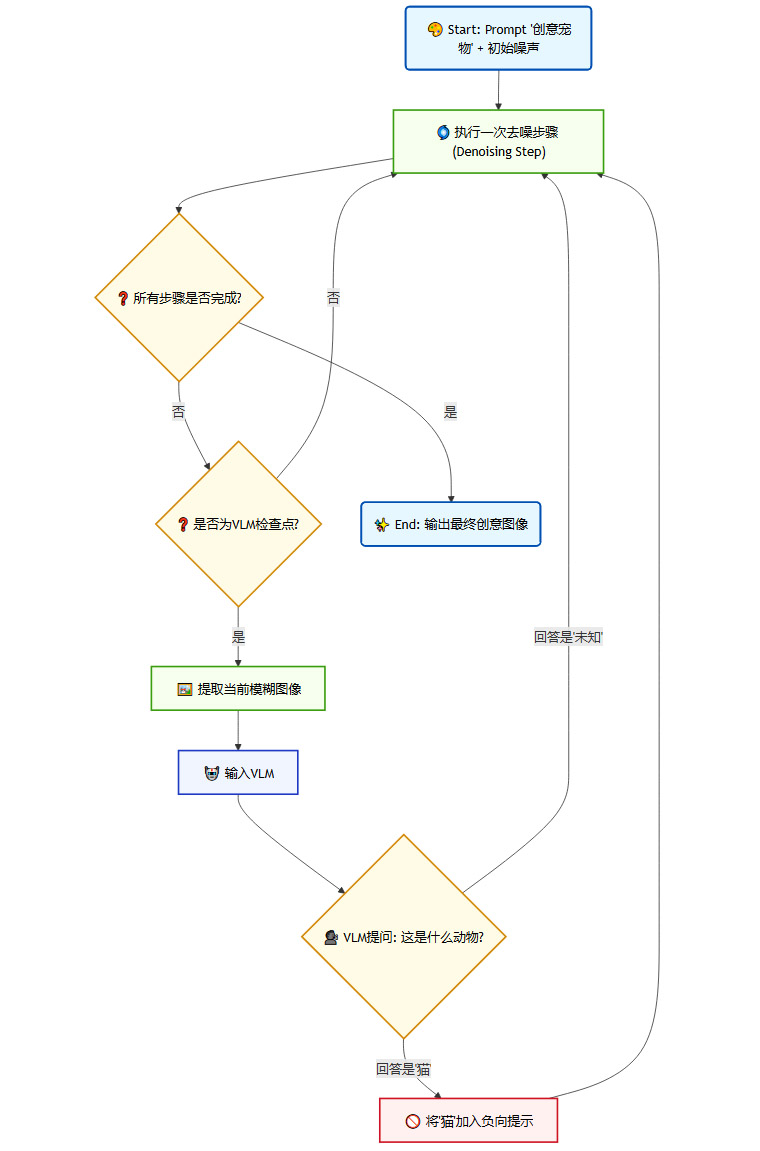
这个流程的核心在于VLM的实时分析与负向提示的动态累积。它将一次性的生成任务,转化为了一个持续进行“观察-判断-反馈-修正”的闭环过程。
2.3 “自适应”与“动态”的价值
与静态负向提示相比,这种方法的“自适应”和“动态”特性是其成功的关键。
自适应(Adaptive):该机制能够适应不同提示和不同模型的生成倾向。对于“创意汽车”的提示,它可能会禁止“轿车”、“SUV”;对于“创意建筑”,它可能会禁止“摩天大楼”、“教堂”。它不需要人工预设任何知识,而是根据生成过程中的实际情况自适应地做出反应。
动态(Dynamic):负向提示列表是滚雪球式增长的。这使得引导的力度可以随时间增强。在早期,模型有较大的探索空间;随着“禁区”越来越多,它的选择范围被收窄,最终被精确地引导到新颖的区域。
这种设计避免了对“创意”进行先验定义,而是通过排除所有“非创意”(即常见事物),让剩下的可能性自然浮现。这是一种非常优雅且高效的工程解决方案。
🎨 三、技术实现与工程优化
%20拷贝.jpg)
将上述核心机制从理论转化为一个高效、可用的系统,需要解决一系列工程挑战。研究团队在时序策略、VLM能力利用、维度控制和性能加速等方面进行了一系列精巧的设计。
3.1 关键洞察:早期介入与时序策略
在扩散模型的每一步都调用VLM进行分析,会带来巨大的计算开销,使得生成过程变得极为缓慢。团队通过实验发现了一个关键规律。
创意的方向主要在生成的早期阶段(early timesteps)就已确定。
这与我们的直觉相符。就像画家在画布上落下最初的几笔,这几笔往往决定了整幅画的基本构图和主题。后续的工作更多是细节的丰富和完善。在扩散模型中,早期的去噪步骤负责构建图像的整体轮廓和语义结构,而后期的步骤则负责填充纹理和高清细节。
基于这个洞察,团队设计了间歇性引导策略。
聚焦前半程:VLM的引导仅在生成过程的前半段(例如,总共50步中的前25步)进行。
降低频率:即使在前半程,也无需每一步都检查。可以每隔几步(例如,每2-3步)进行一次VLM反馈。
实验表明,仅需在前10-15个关键步骤进行引导,就足以将最终的生成结果推向一个全新的方向,其效果与全程引导几乎没有差异。这一优化极大地降低了方案引入的额外计算成本,使其具备了实用价值。
3.2 VLM的“早期可判性”挑战
该方法的可行性,严重依赖于一个前提:VLM能否在图像还非常模糊、充满噪声的中间状态下,准确地预测出它最终会变成什么?
这被称为早期可判性(Early Predictability)。
传统上,VLM(如CLIP、BLIP等)被训练用于理解清晰、完整的图像。让它们去分析一个噪声图,就像让一个未经训练的人去看一张严重失焦的照片。
令人惊讶的是,研究表明,现代强大的VLM在这方面表现出了超乎预期的能力。
高准确率预测:即使在去噪过程只进行了20%时,VLM预测最终生成类别的准确率就能达到**90%**以上。
特征提取能力:这表明VLM不仅仅是在做模板匹配,而是能够从模糊的轮廓、颜色块和初步的结构中,捕捉到底层的语义特征,并推断其发展方向。
VLM的这种“火眼金睛”般的能力,是整个自适应引导机制能够成立的技术基石。它确保了系统可以在“坏”的苗头刚刚出现时,就及时介入并进行纠偏,而不是等到图像成型后才发现为时已晚。
3.3 创意维度的可控性设计
“创意”本身是一个多维度的概念。一个物体可以在类别上创新,也可以在材质、风格或功能上创新。一个漫无目的的“创新”指令,可能会导致模型产生无意义的、随机的变形。
为了让创意可控,团队利用了VLM的问答(VQA)能力,通过设计不同的提问方式来引导创意的方向。
引导类别创新:
提问:“这张图片中的物体属于哪种动物?”
效果:VLM会专注于识别动物类别(猫、狗、鸟等),并将它们加入“黑名单”。这会迫使模型生成一个无法被归类为任何已知动物的新生物。
引导材质创新:
提问:“这张图片中的杯子是什么材质的?”
效果:VLM会识别出“玻璃”、“陶瓷”、“金属”等常见材质。模型将被迫探索如“由液体构成”、“由光线编织”等新颖的材质表现。
引导风格创新:
提问:“这幅画是什么艺术风格?”
效果:VLM会识别出“印象派”、“立体主义”、“赛博朋克”等。模型将被引导去创造一种融合的或全新的视觉风格。
这种基于提问的维度控制,赋予了用户极大的灵活性。它将一个模糊的“创意”指令,分解为了可以在具体工程层面操作的、可控的变量。这使得该方法不仅能生成新奇的图像,还能根据具体的设计需求,进行定向的、有目的的创新。
3.4 性能加速工程实践
尽管时序策略已经大幅减少了VLM的调用次数,但每一次调用仍然涉及将潜在空间(latent space)的特征解码为像素图像,再输入VLM,这个过程耗时较长。
为了进一步压缩时延,团队采用了一些工程加速技巧。
解码近似(Decoding Approximation):在VLM检查点,不进行完整的、高精度的解码,而是使用一个轻量级的、速度更快的近似解码器。这个解码器生成的图像质量较低,但足以保留让VLM做出判断所需的核心结构信息。这就像用一张草图代替精修图来进行快速概念评审。
批量处理与并行化:如果需要生成多张图像,可以将多个中间状态打包成一个批次(batch),一次性送入VLM进行分析,利用GPU的并行计算能力提升吞吐量。
通过这些优化,团队成功将引入的额外时间开销控制在了一个可接受的范围内。在他们的实验配置中,使用Stable Diffusion XL生成一张图像的基础耗时约为22秒,而启用VLM自适应引导后,总耗时约为35秒,额外开销仅为13秒。这使得该技术从一个纯粹的学术探索,向着可部署的实际应用迈出了一大步。
🎨 四、评估体系:如何科学地度量“创意”
评估一项创意生成技术的效果,本身就是一个巨大的挑战。“创意”是一个高度主观的概念,如何将其转化为客观、可量化的指标?研究团队为此设计了一个多维度、结合了人类主观判断和机器定量分析的复合评估体系。
4.1 人类评估:创意性与有效性的双维度权衡
最终,一张图像是否有创意,最有发言权的还是人类观察者。团队设计了一个大规模的人类评估实验,旨在捕捉对创意的直观感受,并解决前文提到的“创意”与“功能”的矛盾。
实验设计:招募了25名参与者,向他们展示了3200对由不同方法生成的图像。每一对图像都围绕同一个主题(如“创意杯子”),但由两种不同方法生成。
双维度评分:参与者需要从两个独立的维度对每一对图像进行比较和选择。
创意性(Creativity):哪一张图像更新颖、出人意料、超越常规?
有效性(Validity):哪一张图像更好地保留了该物体的核心功能和身份?(例如,一个杯子看起来仍然能用,一个宠物看起来仍然适合作为伴侣动物)。
这个双维度设计至关重要。它避免了将创意与有效性混为一谈,能够精确地衡量一个方法是否在追求新奇的同时,牺牲了基本的合理性。
4.2 实验结果与基线对比
实验对比了三种主要方法。
基线方法(Baseline):标准的Stable Diffusion XL,在提示词中加入“creative”、“novel”等词语。
ConceptLab:一种代表性的、通过概念组合来提升创意的方法。
本文方法(Ours):VLM引导的自适应负向提示。
人类评估的结果清晰地揭示了不同方法的特点。
关键结果:在“创意宠物”的生成任务中,由本文方法生成的图像中,约有87%被人类评估者判定为“未知”或“无法归类”的动物。这直接证明了该方法成功地突破了常见动物的范式。同时,这些新生物依然保留了“宠物”应有的可爱、温和等基本属性,维持了高有效性。
这个结果表明,VLM自适应引导成功地找到了创意性与有效性之间的“甜蜜点”,解决了现有方法顾此失彼的难题。
4.3 定量指标分析
为了补充人类主观评估,研究团队还采用了一系列定量指标,从数学和统计层面来衡量生成结果的特性。
相对典型性(Relative Typicality)
定义:使用一个预训练的图像分类器(如CLIP)来衡量生成的图像与该类别中最典型样本的距离。距离越远,说明图像越不“典型”,创意性可能越高。
结果:本文方法生成的图像,其相对典型性得分显著低于其他方法,表明它们在特征空间中远离了常见概念的聚类中心。
多样性(Diversity)
定义:衡量同一提示下多次生成结果之间的差异性。多样性越高,说明方法探索的可能性空间越广,而不是每次都生成相似的几个“创意模板”。
结果:本文方法在多样性指标上也表现出明显优势,证明其能够稳定地产生丰富多样的创意输出。
图像质量指标
定义:使用FID(Fréchet Inception Distance)等标准指标来评估图像的视觉质量和真实感。
结果:本文方法在图像质量上与基线方法持平,没有因为追求创意而导致画质下降。
综合人类评估和定量分析,可以得出结论:VLM引导的自适应负向提示,是在不牺牲图像质量和物体功能性的前提下,目前提升AI图像生成创意性的最有效方法之一。
🎨 五、应用场景与能力扩展
%20拷贝.jpg)
一个优秀的技术方案,其价值不仅在于解决一个孤立的问题,更在于其通用性和可扩展性。VLM自适应引导机制在处理复杂场景和向其他领域迁移方面,展现出了巨大的潜力。
5.1 复杂场景下的精准创新
现实世界的设计需求往往是复杂的,需要在满足一系列约束的同时,对特定元素进行创新。该方法能够很好地处理这类任务。
多对象场景:对于提示“一个穿着创意夹克的女性,坐在一家法式咖啡馆里”,传统模型可能会让整个场景都变得怪异。而本文方法可以将VLM的“提问”聚焦在“夹克”上,只对夹克应用自适应负向提示。
VLM提问:“这件衣服是什么类型的夹克?”
结果:系统会禁止“皮夹克”、“牛仔夹克”等,最终生成一件设计独特的夹克,而女性、咖啡馆等背景元素则保持正常和协调。
连贯的物品集合:对于提示“一套创意茶具”,该方法不仅能让每个单品(茶壶、茶杯、托盘)都具有创新性,还能通过共享的负向提示列表,确保整套茶具在风格、材质和设计语言上保持一致性和协调性。
这种**“正交性”(Orthogonality)**是其一大优势。创意引导模块与其他生成约束(如场景描述、人物姿态等)相互独立,互不干扰。这使得创新可以像一个可插拔的插件一样,被精确地应用到需要的地方,极大地增强了其在实际设计流程中的可用性。
5.2 超越图像:向多模态生成的迁移潜力
“避开套路”这一核心思想,具有高度的普适性,完全可以迁移到其他AIGC领域。
视频生成
问题:视频生成模型容易产生陈词滥调的镜头语言和动作模式(如俗套的追逐场景、重复的对话口型)。
迁移思路:可以在视频生成的中间阶段,使用一个视频理解模型(Video-VLM)来分析正在形成的关键帧或动作片段。如果识别出常见的运镜或情节模式,就将其动态加入负向提示,引导模型生成更具新意的叙事和视觉表现。
3D模型生成
问题:文本到3D模型生成,同样倾向于产生几何结构简单、形态常规的物体。
迁移思路:在3D表示(如NeRF或Mesh)的构建过程中,引入一个能够分析3D几何特征的模型。通过提问“这个模型的拓扑结构是否常见?”或“它的轮廓曲线是否过于平滑?”,来禁止常见的几何范式,探索更复杂的、非欧几里得式的形态。
音乐生成
问题:AI音乐容易生成符合流行和声进行和旋律走向的“口水歌”。
迁移思路:使用一个音乐分析模型,在MIDI序列或音频波形的生成过程中,实时判断旋律片段、和弦进行是否落入了某种常见的模式(如卡农进行)。一旦识别,就通过负向约束引导模型偏离这些“音乐套路”。
这种范式为解决更广泛的AIGC领域的“创意瓶颈”问题,提供了一个统一且可扩展的框架。它标志着我们从单纯追求“生成能力”,迈向了追求“生成智慧”的新阶段。
🎨 六、局限与未来展望
尽管VLM自适应引导取得了显著的成功,但作为一项前沿技术,它仍然存在一些局限,并指向了未来的研究方向。
6.1 当前面临的挑战
计算开销:虽然已经通过优化将额外时延控制在13秒左右,但这对于需要大规模、高通量生成的商业应用场景(如实时个性化内容推荐)来说,仍然是一个不可忽视的成本。进一步的算法和工程优化是必要的。
对VLM能力的依赖:整个系统的上限,在很大程度上取决于VLM的能力。
识别精度:VLM对模糊中间态的识别越准,引导就越精确。
知识广度:VLM知道的“套路”越多,能帮助模型避开的范围就越广。
未来:随着更强大的多模态基础模型的出现,该方法的效果有望水涨船高。
提问策略的人工依赖:如何针对不同的任务设计最优的提问策略(是问类别、问材质,还是问风格?),目前仍然需要领域专家进行人工设计和调试。实现提问策略的自动化生成,是提升系统自主性的关键一步。
6.2 对人类创意本质的启发
这项研究不仅具有技术价值,也为我们从计算的视角理解人类创意,提供了一些有趣的启发。
人类的创意过程,是否也包含了类似的“避免重复”机制?一位经验丰富的作家在下笔时,是否也在潜意识中主动排除了那些已经被用滥的词汇和情节?一位设计师在构思时,是否也在大脑中过滤掉了那些过于常见的设计元素?
从这个角度看,AI的这种“反向排除”机制,可能不仅仅是一种工程技巧,而是对人类某种深层创意认知过程的模拟。创意或许并非源于凭空的灵感闪现,而是在对已知世界的充分认知基础上,有意识地进行偏离和突破。
结论
Adobe研究院提出的VLM引导的自适应负向提示,为解决AI图像生成的创意瓶颈问题,提供了一条清晰、有效且可工程化的路径。它通过“实时观察、动态禁止”的核心机制,巧妙地将扩散模型从其数据驱动的“舒适圈”中推离,在保证生成内容有效性的前提下,显著提升了其新颖性和多样性。
这项工作最大的贡献,是提出并验证了一种“通过约束激发创新”的新范式。它告诉我们,有时候,最好的前进方式,是明确地知道不该往哪里走。这一思想不仅为图像生成领域带来了突破,更有望迁移至视频、3D、音乐等更广阔的AIGC领域,推动AI从一个优秀的“模仿者”,向一个真正的“创造者”进化。未来,随着多模态模型能力的持续增强和工程实践的不断优化,我们有理由期待一个由AI辅助、甚至由AI主导的,创意无限涌现的新时代。
📢💻 【省心锐评】
这不是教AI“画什么”,而是教它“不画什么”。通过VLM实时“拉黑”常见套路,用排除法倒逼模型在约束的夹缝中,开辟出真正新颖的视觉路径,是工程智慧对创意难题的一次优雅降维打击。

评论