.png)


【摘要】约翰斯·霍普金斯大学与马里兰大学团队提出的C3PO方法,为AI专家混合系统带来了“临场发挥”的能力。该方法通过动态优化专家路径,让小模型在推理时超越大模型,极大提升了AI系统的效率与智能水平。本文系统梳理了C3PO的原理、创新机制、实验成效、技术细节、应用前景及行业意义,深入探讨了其对AI未来发展的深远影响。
引言
人工智能的进步正以前所未有的速度重塑着我们的世界。尤其是在大语言模型(LLM)领域,专家混合模型(Mixture of Experts, MoE)架构的出现,为AI系统带来了前所未有的效率和专业化能力。然而,随着模型规模的不断扩大,如何让AI在实际应用中“临场发挥”,成为了业界关注的焦点。2025年4月,约翰斯·霍普金斯大学李忠阳与马里兰大学李紫越、周天逸团队发布的C3PO方法,为这一难题提供了创新性的解决方案。本文将以技术论坛深度文章的标准,系统梳理C3PO的理论基础、创新机制、实验成效、技术细节、应用前景及行业意义,力求为读者呈现一场关于AI“临场智慧”的思想盛宴。
一、AI专家混合系统的“选择困境”与突破契机
%20拷贝-baag.jpg)
1.1 专家混合模型的原理与优势
专家混合模型(MoE)是当前提升大语言模型效率和专业化的主流架构。其核心思想是将模型划分为多个“专家”,每个专家负责特定类型的任务或知识领域。通过门控网络,模型能够在推理时动态选择部分专家参与计算,从而在保持模型容量的同时,大幅降低计算量。
1.1.1 MoE的工作机制
专家池:模型包含数十到数百个专家,每个专家是一个独立的子网络。
门控网络:根据输入内容,动态选择最合适的专家组合参与推理。
稀疏激活:每次推理只激活少数几个专家,极大节省计算资源。
1.1.2 MoE的优势
高效性:大幅降低推理时的计算量。
专业化:每个专家可针对特定任务优化,提升整体表现。
可扩展性:易于扩展模型规模,适应更复杂的任务需求。
1.2 “专家路径”选择的次优性问题
尽管MoE架构在理论上具备极高的效率和专业化潜力,但实际应用中却暴露出一个关键短板——专家路径选择的次优性。研究团队通过对OLMoE、DeepSeekMoE等主流模型的深入分析发现:
专家路径选择远非最优:模型在推理时选择的专家组合,往往未能充分发挥“智囊团”优势,导致准确率比理论最优路径低10-20%。
分布外样本表现更差:在处理新颖或分布外问题时,专家选择更容易出错,性能损失尤为明显。
1.2.1 形象比喻
可以将AI系统比作一个知识储备丰富但答题策略僵化的学生。即使具备90分的能力,因答题顺序和策略不佳,实际只能考到70分。这种“选择困难症”极大限制了AI系统的实际表现。
1.3 问题的本质与突破口
本质:MoE模型在训练阶段学到的专家选择策略,难以适应测试阶段的多样化和动态变化。
突破口:如果能在测试时动态优化专家路径,无需重新训练模型,即可显著提升AI系统的“临场发挥”能力。
二、C3PO:让AI“临场发挥”的创新机制
2.1 C3PO的核心理念
C3PO(Critical-Layer, Core-Expert, Collaborative Pathway Optimization)是一种在测试时动态优化专家选择路径的方法。其核心理念是:
向成功案例学习:借鉴相似问题的成功解答经验,动态调整专家选择策略。
聚焦关键层与核心专家:只优化对最终输出影响最大的层和专家,兼顾效果与效率。
多元优化算法:提供多种优化策略,满足不同场景下的性能与成本需求。
2.2 向成功案例学习:动态路径优化
2.2.1 工作流程
相似案例检索:对于每个新问题,C3PO在参考数据集中搜索与之相似且模型能正确解答的案例。
专家选择模式分析:分析这些“成功案例”中的专家选择模式,提取最优路径信息。
动态路径调整:基于分析结果,实时优化当前问题的专家选择策略。
2.2.2 比喻说明
这一过程类似于考生在考试时回忆类似题目的解题思路,动态调整答题策略,从而实现“临场发挥”。
2.3 聚焦关键层与核心专家:高效优化的秘诀
2.3.1 关键层的选择
研究发现,模型最后5层对最终输出影响最大,仅优化这5层即可获得与全层优化几乎相同的效果。
这种策略大幅降低了优化计算量,提升了实际应用的可行性。
2.3.2 核心专家的聚焦
每层虽有64个专家,但每个问题仅激活8个。
优化时只需关注激活概率最高的前20个专家(覆盖99.8%的被选中专家),进一步压缩计算资源消耗。
2.3.3 优化策略表
2.4 三大优化算法:多元路径选择
2.4.1 模式寻找法
统计相似案例中最常见的专家组合,简单高效,适合对计算资源要求高的场景。
2.4.2 核回归法
根据问题相似度加权平均专家选择(如高斯核函数),能更精准处理细微差异,适合对性能要求高的场景。
2.4.3 邻域梯度下降法
通过梯度下降直接优化相似问题的平均表现,精度最高(可达理论上限85-95%),但计算成本最大,适合对极致性能有需求的场景。
2.4.4 算法对比表
2.5 技术细节与实现要点
2.5.1 相似度计算
采用高斯核等方法,k=3的最近邻策略效果最佳。
只需参考3个最相似的成功案例即可获得良好优化效果。
2.5.2 优化步数与收敛性
主要性能提升在前6步优化完成,10步后趋于稳定。
优化过程稳定,仅有约5%的原本正确答案会变错,整体净收益显著。
2.5.3 Token级优化
只需优化最后一个token的专家选择即可获得最佳效果,进一步降低计算负担。
2.5.4 专家激活模式变化
优化后专家激活更集中,系统更倾向于使用少数高效专家,提升整体效率。
三、C3PO的实验成效与行业意义
%20拷贝-xydq.jpg)
3.1 实验结果:小模型逆袭大模型
3.1.1 性能大幅提升
C3PO在六个主流基准测试(如常识推理、科学问答、阅读理解等)上,将MoE模型的准确率提升了7-15%。
在科学推理任务(如ARC-C)上,提升幅度可达15%。
3.1.2 小模型超越大模型
应用C3PO后,只有1-3亿活跃参数的MoE模型,性能超过了传统7-9亿参数的密集模型,极大提升了参数效率。
这意味着企业和开发者可以用更小的模型,获得更高的性能,显著降低部署和运维成本。
3.1.3 与其他优化方法的对比
C3PO不仅效果优于上下文学习、前缀调优等常用方法,且计算成本更低。
在不知道真实答案的情况下,C3PO能达到理论最优专家路径85-95%的性能,接近“上帝视角”下的最优解。
3.1.4 实验结果表
3.2 优化过程的微观机制
3.2.1 优化步数与学习曲线
性能改进主要发生在前6个优化步骤中,之后趋于平稳。
这一过程类似于学习新技能时的“快速进步—缓慢提升”曲线。
3.2.2 专家激活的集中化
优化前,专家激活分散,使用频率平均。
优化后,激活更集中,少数高效专家承担更多关键任务,整体效率提升。
3.2.3 Token优化的意外发现
仅优化最后一个token的专家选择,效果优于分散优化多个位置。
这一发现为后续算法设计提供了重要启示。
3.3 技术落地与开源
研究团队已在GitHub开源C3PO代码(https://github.com/tianyi-lab/C3PO),开发者可立即集成。
预计短期内将应用于各类AI产品,提升响应速度并降低成本。
四、C3PO的应用前景与局限性
4.1 实际应用潜力
4.1.1 资源受限场景的福音
C3PO让小模型具备大模型性能,适合移动端、边缘计算等资源受限场景。
企业可用更低成本部署高性能AI,提升商业竞争力。
4.1.2 商业化部署的优势
显著降低推理成本和能源消耗,适合大规模AI系统部署。
支持动态自适应优化,提升用户体验和系统稳定性。
4.2 局限性与挑战
4.2.1 参考数据集依赖
C3PO依赖高质量参考数据集,专业领域数据获取可能受限。
参考数据集的质量直接影响优化效果,需持续维护和更新。
4.2.2 实时性与计算开销
虽然C3PO计算成本相对较低,但在极端实时应用中,额外开销仍需关注。
研究团队正在探索更快速的优化算法和近似方法,以进一步降低延迟。
4.2.3 新颖问题的适应性
对于完全新颖的问题,若缺乏相似案例,优化效果有限。
需不断扩充和多样化参考数据集,以适应不断变化的应用需求。
4.3 行业意义与未来方向
4.3.1 优化理念的转变
C3PO推动了AI优化理念从静态训练转向动态自适应,为高效AI系统设计提供了新范式。
未来,类似C3PO的思路有望在更多AI系统中推广,推动AI更智能、更高效地服务于实际应用。
4.3.2 生态系统的推动力
开源代码降低了技术门槛,促进了AI生态系统的繁荣与创新。
开发者和企业可基于C3PO进行二次开发,拓展更多应用场景。
五、C3PO的技术细节与实现流程
%20拷贝-puhc.jpg)
5.1 系统整体流程
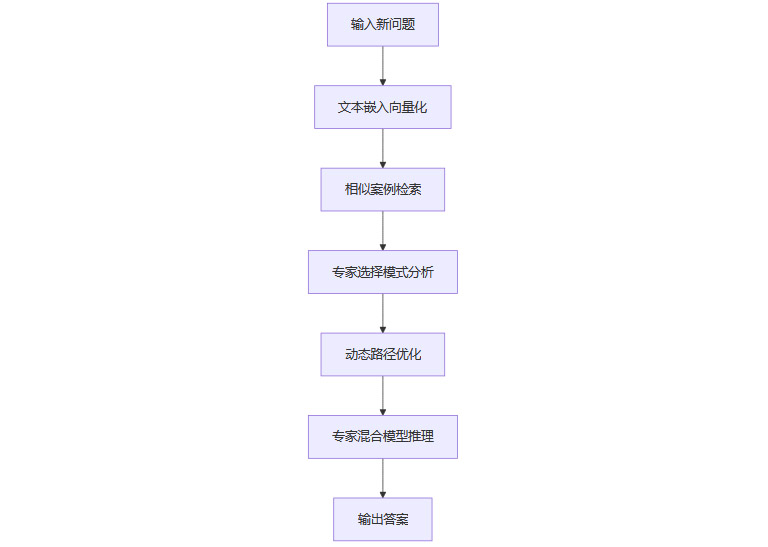
5.2 关键技术点
5.2.1 文本嵌入与相似度计算
使用预训练文本嵌入模型将问题转为高维向量。
相似度计算采用高斯核、k最近邻等方法,k=3效果最佳。
5.2.2 专家路径优化
仅优化最后5层和每层前20个核心专家,兼顾效果与效率。
三大优化算法灵活选择,满足不同场景需求。
5.2.3 优化收敛与稳定性
主要性能提升在前6步完成,10步后收敛。
优化过程稳定,负面影响极小。
5.2.4 专家激活模式调整
优化后专家激活更集中,系统更倾向于高效专家,提升整体推理效率。
六、C3PO的行业影响与未来展望
6.1 AI系统设计的新范式
C3PO为AI系统带来了“临场发挥”的能力,推动了从静态优化到动态自适应的转变。
这一创新不仅提升了AI模型的性能和经济性,也为AI系统的动态优化提供了新思路。
6.2 推动AI应用的普及与创新
通过聚焦关键层和核心专家、借鉴成功案例、采用多种优化算法,C3PO实现了小模型逆袭大模型的突破。
未来,C3PO有望在智能手机、在线AI服务、边缘计算等领域广泛应用,推动AI普及与创新。
6.3 持续优化与生态共建
随着参考数据集的不断扩充和优化算法的持续迭代,C3PO的性能和适应性将进一步提升。
开源社区的参与将加速C3PO的技术演进和生态共建,推动AI行业迈向更高水平。
结论
C3PO的提出,为AI专家混合系统带来了革命性的“临场发挥”能力。通过动态优化专家路径,C3PO让小模型在推理时超越大模型,极大提升了AI系统的效率与智能水平。其创新机制、卓越成效和广阔应用前景,预示着AI系统设计正迈向更加智能、自适应和高效的新时代。未来,随着C3PO及其衍生技术的不断发展,AI将在更多实际场景中展现出前所未有的价值与潜力。
📢💻 【省心锐评】
“C3PO的本质是算力杠杆,用5%的额外计算撬动20%性能增益。它不创造新知识,而是让现有智力资源高效协同——这正是AI工程化的精髓。”

评论