.png)


【摘要】本文系统梳理全球主流大模型的评测与排名,深度对比推理、长文本、多模态等能力,结合权威榜单与实际应用场景,提供详实的选型指南,助力企业与开发者科学决策。
引言
人工智能大语言模型(LLM)的飞速发展,正深刻改变着信息处理、知识创造与产业升级的格局。无论是企业数字化转型,还是开发者创新应用,模型能力的优劣已成为核心竞争力之一。面对层出不穷的模型版本与技术流派,如何科学评测、理性选型,成为业界关注的焦点。SuperCLUE、Chatbot Arena等权威榜单,为模型能力的客观对比和选型提供了坚实的基础。本文将以详实的数据、系统的分析,全面梳理全球大模型的最新格局、能力对比、适用场景及选型建议,助力读者在AI浪潮中把握先机。
一、权威榜单与全球大模型最新排名
%20拷贝-abrb.jpg)
1.1 评测体系的多元化与权威性
大模型能力的评测,已从单一维度走向多元化、场景化。主流评测体系包括:
SuperCLUE:以标准化测试为核心,覆盖数学推理、科学推理、代码生成、智能体、指令遵循、文本理解与创作等多维任务,兼顾中文与多模态场景,强调通用能力。
Chatbot Arena:采用用户真实投票的匿名盲测机制,聚焦实际对话、推理、创意等场景,反映模型在真实交互中的体验。
Hugging Face Leaderboard:聚焦开源生态,强调模型的开放性与社区活跃度。
TAU-bench、多模态专项榜:专注于文本、图像、音频、视频等多模态任务,评估模型在跨模态理解与生成方面的能力。
多维度的评测体系,为模型能力的全面刻画提供了坚实基础,也为选型决策提供了多角度参考。
1.2 全球主流大模型最新排名
权威榜单的最新排名,既反映了技术进步的速度,也揭示了中美“双强格局”下的竞争态势。以下为2025年主流榜单的综合排名:
1.2.1 榜单排名的细节与差异
不同榜单在具体排名上存在细微差异。例如,Chatbot Arena更强调用户体验与实际交互,SuperCLUE则注重标准化能力测试。部分模型如Gemini 2.0、Grok 3、SenseNova-V6 Reasoner在多模态专项榜表现突出,但在通用榜单中排名略低。这一现象反映了评测维度与用户偏好的多样性,也提示选型时需多榜单交叉参考,避免单一维度的片面性。
1.3 多模态能力的崛起
多模态能力已成为大模型竞争的新高地。Gemini 2.0、GPT-4o、Qwen2.5-VL、SenseNova-V6 Reasoner等模型,在文本、图像、音频、视频等多模态任务上表现优异。值得关注的是,商汤SenseNova-V6 Reasoner在Hugging Face多模态评测中以80.4分超越Gemini 2.5 Pro,显示出国产模型在多模态领域的突破。多模态能力的提升,为内容创作、教育、医疗等行业带来了全新可能。
二、主流模型能力对比与适用场景
2.1 关键能力维度的系统梳理
大模型的能力评估,主要聚焦于以下五大维度:
推理/数学能力:衡量模型在逻辑推理、数学计算、科学分析等方面的表现,适用于科研、金融、复杂决策等场景。
长文本处理能力:评估模型对超长上下文的理解与生成能力,适用于法律、学术、金融等大文档分析。
多模态能力:考察模型对文本、图像、音频、视频等多模态输入输出的处理能力,适用于内容创作、教育、医疗等领域。
代码生成能力:反映模型在编程、自动化开发、代码补全等方面的水平,适用于开发者工具、自动化运维等场景。
中文能力:评估模型在中文理解、生成、角色扮演等任务上的表现,适用于本地化和政企应用。
2.2 主流模型能力对比表
2.3 典型能力与场景适配
2.3.1 推理/数学能力
推理与数学能力是大模型智能的核心标志。GPT-4.5、Claude 3.7、Qwen2.5-Max、DeepSeek R1、Grok 3等模型在此维度全球领先,广泛应用于科研、金融、复杂决策等高要求场景。模型在数学推理、科学分析、逻辑归纳等任务中的表现,直接决定了其在高端智力密集型行业的适用性。
2.3.2 长文本处理能力
随着法律、学术、金融等行业对大文档分析的需求激增,长文本处理能力成为模型竞争的新焦点。Claude 3.7、KimiGPT2.0、DeepSeek R1、Qwen2.5-Max、文心一言4.0等模型,支持超长上下文,能够高效处理百万字级文档,极大提升了法律条文分析、学术论文综述、金融报告解读等场景的智能化水平。
2.3.3 多模态能力
多模态能力的崛起,推动了AI在内容创作、教育、医疗等领域的深度应用。Gemini 2.0、GPT-4o、Qwen2.5-VL、SenseNova-V6 Reasoner等模型,支持文本、图像、音频、视频等多模态输入输出,能够实现跨模态理解与生成,为行业创新提供了坚实支撑。值得注意的是,多模态能力与通用能力并非完全一致,部分模型在专项榜单表现突出,但在通用榜单中排名略低,选型时需结合实际需求权衡。
2.3.4 代码生成能力
代码生成能力已成为开发者工具与自动化运维的核心驱动力。Claude 3.7、Qwen2.5-Max、DeepSeek R1、Grok 3等模型,在编程、自动化开发、代码补全等任务中表现优异,极大提升了开发效率与创新能力。模型在HumanEval等权威编程评测中的高分表现,验证了其在实际开发场景中的实用价值。
2.3.5 中文能力与本地化
中文能力的提升,使国产模型在本地化和政企应用中展现出强大竞争力。文心一言4.0、Qwen2.5-Max、Doubao-1.5-pro、SenseChat5.5等模型,在中文理解、生成、角色扮演等任务上表现突出,适用于政务、金融、教育等本地化场景。值得一提的是,国产模型在情感识别、长文本处理等任务上,已与国际顶级模型接近甚至超越,成为中文场景下的首选。
三、选型建议与场景推荐
%20拷贝-pkel.jpg)
3.1 选型的核心原则
科学选型需遵循以下核心原则:
明确业务需求:根据实际应用场景,确定对推理、长文本、多模态、中文优化等能力的需求优先级。
多榜单交叉参考:结合SuperCLUE、Chatbot Arena、Hugging Face Leaderboard等多榜单的评测结果,避免单一维度的片面性。
关注模型开放性与生态支持:优先考虑开源模型与活跃生态,便于二次开发与定制化部署。
评估API成本与数据安全:结合API调用成本、数据安全合规等因素,选择性价比高、风险可控的模型。
动态跟踪榜单变化:大模型技术迭代迅速,需持续关注榜单动态,及时调整选型策略。
3.2 典型场景与模型推荐
3.2.1 通用对话/内容创作
适合模型:GPT-4.5、Claude 3.7、Qwen2.5-Max、Doubao-1.5-pro
应用场景:智能客服、内容生成、知识问答、创意写作等
3.2.2 长文本处理/法律/科研
适合模型:KimiGPT2.0、Qwen2.5-Max、文心一言4.0、DeepSeek R1
应用场景:法律条文分析、学术论文综述、金融报告解读等
3.2.3 多模态内容生成/分析
适合模型:Gemini 2.0、GPT-4o、Qwen2.5-VL、SenseNova-V6 Reasoner、Doubao视频生成
应用场景:内容创作、教育培训、医疗影像分析、工业设计等
3.2.4 代码生成/开发者工具
适合模型:Claude 3.7、Qwen2.5-Max、DeepSeek R1、Grok 3
应用场景:自动化开发、代码补全、智能运维、开发者助手等
3.2.5 中文本地化/政企应用
适合模型:文心一言4.0、Doubao-1.5-pro、SenseChat5.5、腾讯混元
应用场景:政务服务、金融风控、教育培训、企业知识管理等
3.2.6 低成本/开源部署
适合模型:Qwen2.5-Max、DeepSeek R1、LLaMA3(Meta)
应用场景:预算有限的企业、二次开发、私有化部署等
3.3 选型流程图
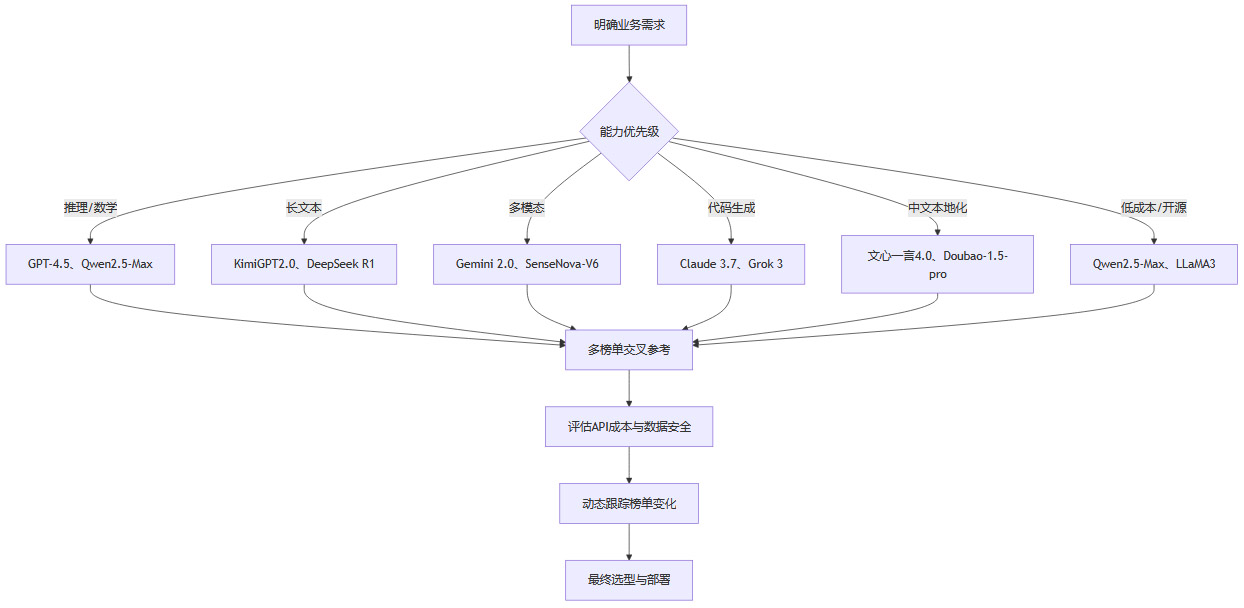
3.4 选型建议的细化
对于企业级应用,建议优先试用多家主流模型,结合自有数据进行效果验证。
关注模型的开放性(开源/闭源)、生态支持、API成本、数据安全等因素。DeepSeek R1等国产模型以极高性价比(训练成本仅为国际模型1/27)适合预算有限的企业。
动态跟踪榜单变化,及时调整选型策略,确保技术领先与业务适配的最佳平衡。
四、评测体系与发展趋势
%20拷贝-qbfy.jpg)
4.1 评测体系的全面性与客观性
主流评测平台各有侧重,需多维度交叉验证,确保评测结果的全面性和客观性:
SuperCLUE:标准化测试,强调通用能力与多维任务覆盖。
Chatbot Arena:用户盲测,突出实际交互体验与创新能力。
Hugging Face Leaderboard:开源生态,关注模型开放性与社区活跃度。
TAU-bench、多模态专项榜:聚焦多模态能力,评估模型在跨模态理解与生成方面的表现。
4.2 发展趋势的深度洞察
4.2.1 中美“双强格局”与国产模型崛起
全球大模型格局正处于快速演进期,中美“双强格局”日益明显。OpenAI、Anthropic、Google等国际巨头与中国本土力量(阿里、百度、深度求索、字节、商汤等)形成多极竞争。国产模型在开源、垂直优化、成本效率等方面实现突破,国内外第一梯队差距持续缩小。
4.2.2 多模态、长文本、低成本、行业定制化
多模态、长文本、低成本、行业定制化成为新一轮竞争焦点。模型能力的持续提升,将在医疗、法律、工业设计等垂直领域展现更大潜力。开源生态的爆发,推动Qwen、DeepSeek、LLaMA等开源模型在全球开发者中活跃,促进了技术创新与应用落地。
4.2.3 榜单排名的动态变化与行业影响
榜单排名的动态变化,反映了技术进步与用户需求的演变。部分模型在多模态专项榜表现突出,但在通用榜单中排名略低,说明多模态能力与通用能力并非完全一致。选型时需结合多榜单交叉参考,确保模型能力与实际需求的高度契合。
4.2.4 中文能力与本地化的持续突破
国产模型在中文场景下的表现已与国际顶级模型接近甚至超越,特别是在情感识别、长文本处理等任务上。对于中文本地化需求,优先考虑国产主流模型,能够更好地满足政企、金融、教育等行业的本地化应用需求。
五、结论
全球大模型格局正处于快速演进期,技术创新与应用落地齐头并进。不同模型在推理、长文本、多模态、中文优化等维度各有侧重,用户选型时应结合权威榜单、模型能力、业务需求和生态支持,动态关注最新评测结果,科学决策,才能最大化AI大模型的应用价值。未来,持续关注评测动态和行业趋势,将有助于把握大模型技术红利,实现业务创新与升级。无论是企业数字化转型,还是开发者创新应用,科学的模型选型与持续的能力评估,都是赢得AI时代主动权的关键。
📢💻 【省心锐评】
大模型选型,既要看榜单,更要看场景,动态调整,方能立于不败之地。

评论