.png)


【摘要】Transformer长期主导大模型领域,但在长序列处理和算力效率上面临瓶颈。Mamba架构以线性计算效率和动态信息过滤为核心,推动混合架构在千亿参数模型中的落地。腾讯混元T1等案例验证了Mamba-Transformer混合范式的工业可行性,开启了长上下文处理新纪元。未来,混合架构有望成为AI大模型主流,助力产业智能化升级。
引言
在人工智能大模型的技术演进史上,Transformer无疑是最具标志性的架构之一。自2017年问世以来,Transformer凭借自注意力机制在自然语言处理、计算机视觉、语音识别等领域取得了突破性进展,成为大模型的事实标准。然而,随着模型规模的不断扩展和应用场景的日益复杂,Transformer在处理长序列、推理效率和算力成本等方面的短板逐渐暴露。尤其是在千亿参数级别的超大模型和长文本任务中,Transformer的O(N²)计算复杂度、KV-Cache内存瓶颈和长距离依赖捕捉能力的不足,成为制约其进一步发展的关键障碍。
在这样的背景下,Mamba架构应运而生。它以选择性状态空间模型(Selective SSM)为核心,摒弃了传统的全局自注意力机制,采用递归式状态更新和动态信息过滤,带来了计算效率、内存占用和长上下文处理能力的多重突破。更为重要的是,Mamba与Transformer的混合架构在千亿参数级模型中的工业级落地,已经在腾讯混元T1等产品中得到了验证,推动了AI大模型从“全注意力”向“高效混合”范式的转变。
本文将系统梳理Transformer架构的瓶颈,深入剖析Mamba的技术创新与优势,详解腾讯混元T1等混合架构的工业实践,并展望长上下文处理新范式对产业的深远影响。文章将以技术深度与广度兼备的视角,全面呈现Mamba混合架构对AI大模型生态的冲击与变革。
一、Transformer的瓶颈与挑战
%20拷贝-ptbz.jpg)
1.1 计算复杂度的天花板
Transformer的自注意力机制是其强大建模能力的核心,但也带来了计算复杂度的巨大负担。对于长度为N的输入序列,标准自注意力的计算和内存复杂度均为O(N²)。这意味着:
序列长度翻倍,计算和内存成本需提升四倍。
在长文本、代码、基因组等超长序列场景下,算力和内存消耗呈指数级增长。
推理阶段,KV-Cache的存储需求急剧增加,成为部署和扩展的瓶颈。
1.1.1 复杂度对比表
1.2 KV-Cache内存瓶颈
Transformer在推理时需缓存每一层的Key和Value向量,随着序列长度增加,KV-Cache的内存占用呈线性增长。对于千亿参数级模型,长上下文推理时,KV-Cache的内存消耗甚至超过模型本身,严重制约了推理速度和并发能力。
1.3 长距离依赖的捕捉难题
尽管自注意力机制理论上可以建模任意距离的依赖关系,但在实际超长文本场景下,Transformer容易出现上下文信息丢失和遗忘现象。主要原因包括:
注意力分布稀疏,远距离token的权重被稀释。
长序列训练时,梯度消失和爆炸问题加剧。
需要大量的算力和数据才能有效捕捉长距离依赖。
1.4 产业落地的现实困境
随着大模型向千亿参数级别扩展,Transformer的上述瓶颈愈发突出,直接影响到:
训练和推理的算力成本,成为企业部署的主要障碍。
长文本、法律、金融、医疗等行业的智能化升级进程。
大模型的普及和产业化落地速度。
二、Mamba架构的核心创新与优势
2.1 选择性状态空间模型(Selective SSM)
Mamba架构的最大创新在于引入了选择性状态空间模型(Selective SSM),彻底摒弃了传统的全局自注意力机制。其核心思想是:
采用递归式状态更新,每一步只需关注当前输入和历史状态,无需全局扫描。
动态信息过滤机制,自动判断输入信息的重要性,聚焦关键内容,降低无意义信息的权重。
结构化状态空间持续压缩有效信息,避免冗余计算,提升长序列建模能力。
2.2 线性计算效率
Mamba架构将计算复杂度从O(N²)降至O(N),推理成本随序列长度线性增长,极大提升了长文本处理的可扩展性。具体表现为:
在推理阶段,KV-Cache内存占用显著减少,吞吐量可达Transformer的5倍。
支持大规模并行和工业部署,硬件友好,能充分利用现代GPU的高带宽内存(HBM)和SRAM。
通过内核融合、并行扫描等技术进一步提升效率,适合超长序列和高并发场景。
2.2.1 计算效率提升示意表
2.3 动态信息过滤与选择性记忆
Mamba通过选择性压缩技术,自动判断输入信息的重要性,聚焦关键内容,降低无意义信息的权重。这一机制类似于人脑的信息筛选:
结构化状态空间持续压缩有效信息,避免冗余计算。
动态过滤机制提升了长序列建模能力,减少上下文丢失。
支持百万级token的超长上下文窗口,性能随序列长度扩展依然保持高效。
2.4 长上下文处理能力
Mamba架构在长文本任务(如法律文档、基因组分析、代码生成)中,能有效捕捉长距离依赖,减少上下文丢失。其优势包括:
支持百万级token的超长上下文窗口,远超传统Transformer的能力。
在长文本任务中,上下文捕捉准确率提升28%-40%。
适用于法律、金融、医疗等对长文档处理有极高需求的行业。
三、腾讯混元T1案例:混合架构的工业级落地
%20拷贝-ioel.jpg)
3.1 架构设计与创新
腾讯混元T1是业界首个在千亿参数级模型中无损应用Mamba-Transformer混合架构的工业级案例。其架构设计具有以下特点:
采用Hybrid-Mamba-Transformer融合模式,动态路由机制根据输入长度分配计算资源。
短文本优先调用Transformer保证语义精度,长文本则启用Mamba提升效率。
动态切换机制兼顾了Transformer的通用性和Mamba的高效性。
3.1.1 混合架构流程图
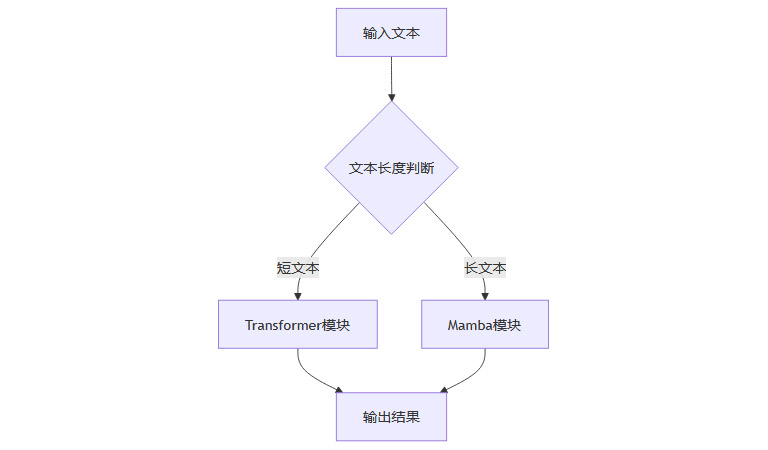
3.2 成本与效率的双重突破
混元T1混合架构在成本与效率上实现了显著突破:
训练成本降低约35%,推理成本减少50%。
首字响应时间低于500ms,吐字速度达60-80 tokens/s,显著优于同类纯Transformer模型。
支持大规模并发和超长文本推理,极大提升了工业部署的可行性。
3.2.1 成本与效率对比表
3.3 性能表现与产业化落地
混元T1在MMLU-PRO(87.2分)、CEval(92.1分)等基准测试中,性能持平或超越同级别顶尖模型。长文本任务上下文捕捉准确率提升28%-40%。在产业化落地方面:
已集成于腾讯文档、微信读书等产品,服务数亿用户。
API定价低于行业平均,推动AI大模型的普及和产业化。
支持法律、金融、医疗等行业的智能化升级,助力企业降本增效。
四、长上下文处理新范式与产业影响
4.1 从“全注意力”到“高效混合”
Mamba及其混合架构推动了长上下文处理的新范式。国际主流大模型(如英伟达Nemotron-H、AI21 Jamba)也采用Mamba-Transformer混合架构,实现256K甚至百万级上下文窗口,长文本推理效率和准确性大幅提升。
4.1.1 混合架构优势列表
兼顾Transformer的通用性与Mamba的高效性
支持超长上下文窗口,提升长文本推理能力
降低算力和内存成本,提升产业落地速度
动态路由机制,灵活适配不同任务需求
4.2 状态压缩替代注意力覆盖
Mamba通过结构化状态空间压缩信息,避免了传统注意力机制的全局扫描和RAG技术的幻觉问题。其优势包括:
有效压缩冗余信息,提升推理效率
降低长序列推理的内存和算力消耗
提升长距离依赖的捕捉能力,减少上下文丢失
4.3 产业应用的广泛拓展
Mamba混合架构的普及,推动了法律、金融、医疗等对长文档处理有极高需求的行业实现智能化升级。具体表现为:
法律行业:支持超长法律文档的智能分析与检索
金融行业:提升长周期金融数据的建模与预测能力
医疗行业:支持基因组、病历等超长文本的智能处理
五、挑战、分歧与未来方向
%20拷贝-dlwk.jpg)
5.1 持续突破与技术融合
尽管Mamba在小规模模型(≤7B参数)已展现出超越Transformer的潜力,但在千亿参数级模型上的全面验证仍需进一步突破。当前最优解是混合架构,如英伟达实验表明,Mamba与Transformer层按8:1比例混合(如56B模型含10层注意力+108层Mamba/MLP),可兼顾效率与性能。
5.2 通用性与复杂推理的平衡
Transformer在通用性和复杂推理任务上仍具优势,Mamba在某些任务(如上下文学习)尚需改进。未来架构将聚焦“让每个FLOP更有价值”,结合SSM的效率与注意力的精确回忆能力。
5.3 未来趋势与产业展望
Mamba推动的线性计算范式将催生长文本、生物信息等垂直领域的新突破。随着Mamba及其混合范式在更大规模和多模态场景中的应用深化,AI大模型的能力、效率和产业价值有望实现新一轮跃升。
结论
Mamba架构以其线性计算效率、动态信息过滤和硬件友好性,正在成为Transformer的有力挑战者。腾讯混元T1等混合架构的成功落地,标志着大模型领域正从“Transformer一统天下”迈向“高效混合架构”新纪元。尽管Transformer在通用性和复杂推理上仍具优势,但Mamba混合架构已开启长上下文处理的新范式,为AI大模型的高效化、产业化和普及注入了强大动力。未来,混合架构有望成为主流,推动AI技术迈向更高效、更可持续的发展方向。
📢💻 【省心锐评】
Mamba混合架构开启了AI效率革命,混元T1证明其产业价值。未来,混合范式或成主流,Transformer霸权面临真正挑战!

评论