.png)
%20%E6%8B%B7%E8%B4%9D.jpg)

【摘要】AI芯片正从单纯追求晶体管密度,转向以架构、封装、软件与生态协同为核心的系统级创新范式,以此突破功耗、散热与设计三大瓶颈,重塑智能计算的未来。
引言
人工智能,特别是生成式AI与大语言模型,正成为驱动社会数字化转型的“新电力”。这场变革的引擎,并非我们熟知的通用处理器,而是一类专为智能计算量身打造的硬件——AI芯片。我们必须清晰地认识到,这不只是一场关于速度的竞赛。它是一次深刻的范式转移。AI芯片的发展路径已经偏离了传统轨道,不再单纯依赖晶体管的微缩。它正通过架构的重构、系统的协同与场景的深度适配,为整个智能时代构建全新的硬件基石。理解这一新范式,是把握未来十年技术脉搏的关键。
🚀 一、AI算力的核心需求与专用化趋势
%20拷贝.jpg)
AI算力的需求呈现出近乎贪婪的增长态势。这种需求从根本上塑造了AI芯片的形态,并推动其走向一条不可逆转的专用化道路。
1.1 架构的根本分野:并行计算的回归
AI芯片与传统CPU的核心差异,源于它们为截然不同的计算任务而生。CPU作为通用计算核心,其设计哲学是处理复杂指令与逻辑分支,它擅长“举一反三”。而AI芯片,尤其是其核心的深度学习算法,本质上是海量同质化数据的并行处理,它需要的是“力大砖飞”。
这种任务属性的差异,导致了架构上的根本分野。
CPU (Central Processing Unit):其架构为低延迟、强控制流而优化。大量的芯片面积用于控制单元和缓存,计算单元(ALU)相对较少。它像一位经验丰富的项目经理,能灵活处理各种突发任务。
AI芯片 (AI Accelerator):其架构为高吞吐量、强数据流而优化。绝大部分芯片面积被密集的计算单元占据,控制逻辑被简化。它更像一个纪律严明的计算军团,高效执行大规模、重复性的矩阵乘加(MAC)运算。
我们可以通过一个更具体的对比来理解这种差异。
正是这种为并行而生的设计,使得AI芯片在处理AI负载时,能够实现数量级的性能提升和功耗降低。这并非简单的量变,而是质的飞跃。
1.2 市场驱动力:从英伟达主导到多元并存
市场的反应最直观地印证了专用化趋势。AI应用的井喷,特别是大语言模型动辄千亿、万亿的参数量,对算力提出了前所未有的要求。
英伟达的成功并非偶然,其核心在于构建了一个强大的“硬件+软件”护城河。其GPU硬件提供了强大的并行算力,而CUDA软件生态则将这种算力高效地释放给开发者。这个生态系统经过十多年的积累,涵盖了编译器、库、开发工具和庞大的开发者社区,形成了极高的用户粘性。这解释了为何英伟达能在AI训练市场占据事实上的标准地位。
然而,市场从不缺乏挑战者。一个“英伟达主导、多元并存”的格局正在形成。
传统巨头追赶:AMD凭借其MI300系列产品,在性能上紧追不舍,并积极构建ROCm软件生态,试图打破CUDA的垄断。
云服务商自研:谷歌的TPU、亚马逊的Trainium/Inferentia芯片,它们的目标是优化自身云平台内部的AI负载成本和效率,形成差异化优势。
新兴初创破局:Groq、SambaNova等公司则从更激进的架构创新入手,试图在特定推理或训练场景中实现性能的颠覆。
这种多元化的竞争格局,正在从不同维度推动AI芯片技术加速演进,为市场带来更多样化的选择。
1.3 必然趋势:走向深度定制的专用集成电路
通用计算的黄金时代,建立在“一套硬件满足所有需求”的假设之上。但在AI时代,这个假设已被打破。计算架构的“专用化”(Application-Specific)是应对成本和效率挑战的唯一出路。
这条专用化路径本身也存在不同的层次。
GPU (Graphics Processing Unit):通用并行计算的代表,灵活性高,生态成熟,是当前AI训练的主力。
FPGA (Field-Programmable Gate Array):现场可编程门阵列,硬件逻辑可被重构。它在灵活性和性能之间取得了很好的平衡,适合算法快速迭代和低延迟场景。
ASIC (Application-Specific Integrated Circuit):专用集成电路,为特定算法或应用“硬化”设计。它牺牲了灵活性,换来了极致的性能和能效比,是大规模部署推理任务的理想选择。谷歌的TPU就是一种典型的ASIC。
未来,我们将会看到更多针对特定领域(如自动驾驶、生物计算、推荐系统)的ASIC芯片涌现。通用计算让位于专用计算,这是AI时代半导体行业最深刻的结构性变化之一。
💡 二、摩尔定律放缓下的三大核心瓶颈
沿袭了半个世纪的摩尔定律,即晶体管密度每两年翻一番的规律,正面临严峻的物理和经济挑战。性能的提升不再是缩小晶体管尺寸的必然结果。整个行业正被三堵无形的“高墙”所阻碍。
2.1 功耗墙 (Power Wall):性能的“电费”账单
过去,随着晶体管缩小,其工作电压也会相应降低,从而控制住了功耗密度的增长。这就是著名的登纳德缩放定律(Dennard Scaling)。然而,大约在2005年之后,由于漏电流等物理效应,电压无法再按比例降低。
结果是,晶体管密度仍在增加,但功耗密度却在急剧攀升。芯片的性能提升,正越来越多地受到其供电和散热能力的限制。这堵墙,就是“功耗墙”。
为了绕开这堵墙,业界正在进行艰苦的探索。Auradine公司的拉吉夫·凯马尼分享了他们的思路,即在亚阈值电压(Sub-threshold Voltage)下运行芯片。
核心原理:芯片功耗与电压的平方(P ∝ V²)成正比。将常规的0.75V工作电压降至0.3V以下,理论上能带来数倍的能效提升。
工程挑战:极低电压会导致晶体管开关速度变慢、对工艺变化极其敏感。这会引发严重的良率、可靠性问题,并导致芯片频率急剧下降。
解决路径:唯一的办法是进行深度定制。这包括设计专门的电路库、算术库,并与晶圆代工厂紧密合作,对工艺进行针对性优化。
功耗问题已从一个次要考量,上升为AI芯片设计的核心制约因素。未来的竞争,很大程度上是“每瓦性能”(Performance per Watt)的竞争。
2.2 散热墙 (Heat Wall):芯片性能的“温度计”
功耗墙的直接产物就是“散热墙”。芯片消耗的电能,绝大部分最终都转化为了热量。如果这些热量无法被及时带走,芯片温度就会飙升,导致其必须降频运行以避免损坏,这种现象被称为热节流(Thermal Throttling)。
正如Frore Systems公司的塞舒·马达瓦佩迪所言,“如果你没有非常有效的散热方式,那么你就无法真正让数据中心在那种性能水平下运行。”
这个问题普遍存在于两个层面。
数据中心:一个AI服务器机柜的功耗可达数十千瓦,传统风冷已不堪重负。液冷,包括冷板式液冷和浸没式液冷,正从“可选项”变为“必选项”。这不仅是散热技术的升级,更要求对机柜、服务器、芯片封装进行系统性的协同设计。
边缘设备:在手机、笔记本电脑、自动驾驶汽车等功耗和空间受限的设备中,散热能力直接决定了AI应用的性能上限。微型化的主动散热方案,如压电风扇,正成为新的研究热点。
散热已不再是简单的工程配套问题,它已深度融入芯片和系统设计的核心环节,成为决定性能能否完全释放的关键。
2.3 设计墙 (Design Wall):创新的成本与周期
第三堵墙,是经济和工程层面的“设计墙”。随着芯片制程进入5纳米、3纳米甚至更先进的节点,其设计变得异常复杂和昂贵。
成本激增:一套先进工艺节点的光刻掩模(Mask)成本高达数千万美元。一次流片失败的代价是毁灭性的。
周期漫长:一款复杂AI芯片从设计到最终量产,通常需要2到3年时间。这与AI算法日新月异的迭代速度形成了鲜明对比。
人才稀缺:顶尖的芯片设计人才培养周期长,供给严重不足。
Cognichip公司的法拉吉·阿拉埃指出,过去每年有数百家芯片初创公司,如今已降至个位数。高昂的门槛正在扼杀创新。传统的设计方法,依赖大量人力和经验,已难以为继。如何让芯片设计变得更敏捷、更经济、更“民主化”,成为整个行业亟待破解的难题。
🛠️ 三、破局之道:多维度技术创新路径
%20拷贝.jpg)
面对功耗、散热和设计这三堵高墙,单纯依靠制程微缩的“暴力”手段已然失效。行业正转向一场多维度、系统性的技术革命,从芯片内部的架构,到设计芯片的方法,再到超越单个芯片的系统集成,寻找新的增长曲线。
3.1 架构创新:重塑芯片内部的数据流
创新的第一站,始于芯片内部,目标是解决计算的核心瓶颈——数据搬运。
3.1.1 存算一体:消除“存储墙”
传统的冯·诺依曼架构将计算单元和存储单元分离。数据需要在两者之间通过总线来回穿梭。在数据密集型的AI应用中,这种搬运造成的延迟和功耗,甚至超过了计算本身。这就是所谓的“存储墙”或“冯·诺依曼瓶颈”。
存算一体(In-Memory Computing)技术,旨在打破计算与存储的物理界限。其核心思想是在数据存储的地方直接进行计算,从而彻底消除数据搬运。
近存计算(Near-Memory Computing):将计算单元尽可能地靠近存储单元,例如将逻辑芯片与高带宽内存(HBM)堆叠在一起。这是目前较为成熟的实现路径。
存内计算(In-Memory Computing):利用存储器件(如SRAM、DRAM、RRAM、MRAM等)本身的物理特性来执行计算。例如,利用忆阻器(Memristor)阵列,通过基尔霍夫定律一次性完成矩阵向量乘法。这是一种更具颠覆性的方案,但仍面临材料、电路设计和编译等诸多挑战。
存算一体被认为是未来AI芯片架构演进的关键方向之一,有望带来能效比的巨大突破。
3.1.2 定制化与可重构计算:在效率与灵活间寻找平衡
既然通用架构效率低下,那么为特定应用打造专用架构就成为必然。
ASIC的极致效率:如前所述,ASIC为特定算法“硬化”了计算通路,能效最高。但其缺点是开发成本高、周期长,且一旦算法发生变化,芯片可能直接报废。
FPGA的动态重构:FPGA通过可编程的逻辑单元和布线资源,允许用户在芯片出厂后重新定义其硬件功能。这为算法的快速迭代提供了硬件级的支持,非常适合AI算法探索和需要频繁更新的场景。
领域专用架构(DSA):介于ASIC和FPGA之间,DSA为某一特定领域(如图像处理、自然语言处理)设计高度优化的指令集和计算引擎。它在保持一定灵活性的同时,获得了远超通用处理器的效率。
未来的AI芯片将呈现出更加丰富的架构形态,根据应用场景的需求,在效率与灵活性之间做出最优的权衡。
3.2 设计方法革新:用AI设计AI芯片
为了推倒“设计墙”,行业正在引入最强大的新工具——人工智能本身。AI驱动的EDA(电子设计自动化)正在从概念走向现实。
传统芯片设计流程,如布局布线(Place & Route),是一个极其复杂的组合优化问题,需要耗费大量计算资源和资深工程师数周甚至数月的时间。现在,AI大模型可以学习海量的设计数据,并从中总结出优化策略。
自动化布局布线:谷歌、英伟达等公司已证明,利用强化学习等AI技术,可以在数小时内生成优于人类专家的芯片布局方案,有效提升芯片的性能、功耗和面积(PPA)。
基础模型赋能:Cognichip等公司正在探索开发芯片设计领域的“基础模型”。开发者只需用高级语言描述芯片的功能需求,AI就能自动生成底层的硬件描述语言(RTL)代码,甚至直接进行物理版图的初步规划。
法拉吉·阿拉埃将其比作“为芯片设计师创造的Cursor”。“芯片像软件一样开发”的愿景,正通过AI赋能的自动化设计工具,一步步变为现实。这将极大地降低创新门槛,加速芯片的迭代速度。
3.3 系统级创新:超越单个芯片的摩尔定律
当单个芯片的性能提升遭遇瓶颈时,将多个芯片高效地组合起来,就成了延续性能增长的关键。这就是系统级创新的核心思想,它将战场从二维的芯片表面,扩展到了三维的立体空间。
3.3.1 先进封装:用“乐高”模式构建超级芯片
传统的芯片制造模式是单片系统(SoC),即把所有功能都集成在一块巨大的硅片上。随着芯片尺寸逼近光刻极限,这种模式的成本和良率风险越来越高。
Chiplet(小芯片)技术应运而生。它将一个大的单片芯片,按照功能拆分成多个更小的、独立的裸片(Die),然后通过先进的封装技术将它们像搭乐高积木一样互联起来,形成一个功能强大的系统级封装(SiP)。
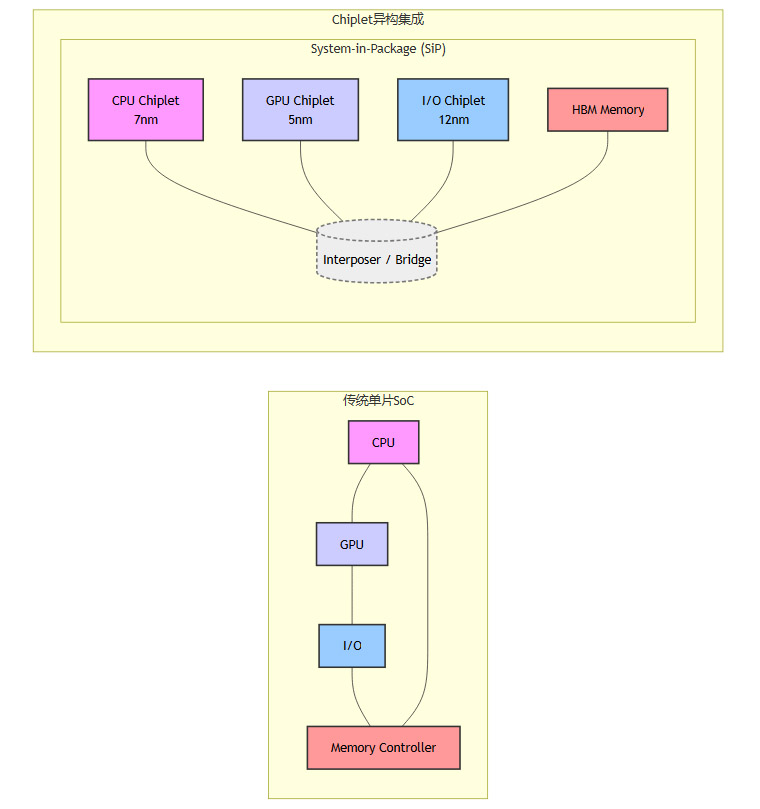
Chiplet模式带来了诸多优势。
提升良率:小芯片的制造良率远高于大芯片。
灵活组合:可以混合搭配不同工艺、不同功能的Chiplet,实现快速的产品定制。例如,计算核心使用最先进的3nm工艺,而I/O部分使用成熟的12nm工艺,以优化成本。
突破尺寸限制:可以集成远超光刻掩模尺寸的超大规模系统。
2.5D封装(通过硅中介层互联)和3D封装(垂直堆叠)是实现Chiplet集成的关键技术。它们共同构成了“超越摩尔定律”的核心驱动力。
3.3.2 颠覆性散热技术:与封装协同进化
系统级集成带来了更高的功率密度,也对散热提出了更苛刻的要求。散热技术必须与封装技术协同进化。例如,在3D堆叠芯片中,如何在层间有效地导出热量,是一个世界级的难题。**微流体通道(Microfluidic Channels)**等技术被集成到芯片封装内部,形成芯片级的液冷系统,正成为前沿的解决方案。
3.3.3 光子计算与互联:用光子取代电子
电子在导线中传输时,会因电阻而产生热量和信号衰减,这限制了芯片间通信的带宽和距离。光子作为信息载体,则没有这些问题。
硅光互联(Silicon Photonics):将光收发器件集成到硅芯片上,用光路取代电路,实现芯片间、服务器间的高带宽、低功耗数据传输。这被认为是解决数据中心网络瓶颈的关键技术,目前已进入商业化应用阶段。
光子计算(Photonic Computing):更进一步,直接用光来进行计算。利用光的并行性和干涉等特性,理论上可以在特定计算(如矩阵运算)上实现远超电子计算的能效。这仍处于早期研究阶段,但为未来的算力突破提供了激动人心的可能性。
🌐 四、未来展望:从单一芯片到异构集成的生态系统
%20拷贝.jpg)
展望未来,AI芯片的发展将不再聚焦于单一组件的性能,而是转向一个更加宏大和复杂的图景,一个由硬件、软件和开发者共同构成的动态生态系统。
4.1 硬件的未来是“组合”
未来的高性能AI计算单元,将不再是一块巨大的、无所不包的“超级芯片”。它会是一个高度异构的集成系统。在这个系统中,CPU、GPU、NPU、FPGA以及各种专用加速器,都将以Chiplet的形式存在。它们通过高速的Die-to-Die互联协议(如UCIe)组合在一起,根据任务需求,动态地调用最合适的计算资源。硬件设计将从“建造摩天大楼”转变为“规划智慧城市”。
4.2 软硬件协同设计至关重要
硬件的异构化和复杂性,给软件带来了巨大的挑战。如果软件无法高效地利用底层硬件,再强大的芯片也只是一堆昂贵的沙子。**软硬件协同设计(Hardware-Software Co-design)**变得前所未有的重要。
智能编译器:需要能够理解异构硬件的拓扑结构,自动地将AI模型拆分、映射到最合适的计算单元上,并优化数据流路径。
统一编程模型:需要为开发者提供一套简洁、统一的编程接口,屏蔽掉底层的硬件复杂性,就像CUDA为GPU所做的那样。
算法与硬件的共同进化:未来的AI算法(如稀疏化、量化、混合专家模型MoE)将与硬件架构同步设计,以实现最优的系统效率。
4.3 生态系统决定成败
最终,技术的竞争将是生态系统的竞争。一个成功的AI芯片平台,必须具备三个要素。
开放的硬件标准:Chiplet的成功,依赖于像UCIe这样的开放互联标准,它能让不同厂商的芯片实现互操作。
强大的软件工具链:包括编译器、调试器、性能分析器和丰富的算法库。
活跃的开发者社区:开发者用脚投票,他们会聚集在最易用、最高效、支持最完善的平台上。
英伟达的CUDA生态是最好的例证。未来的挑战者,不仅要在硬件性能上取得突破,更艰巨的任务是构建一个能够与之抗衡的软件和开发者生态。
结论
AI芯片的发展之路,已经清晰地超越了摩尔定律所定义的单线叙事。我们正进入一个以系统级创新为核心的“新范式”时代。在这条道路上,功耗与能效是基本法则,架构创新是核心引擎,先进封装与互联是加速器,而软硬件协同设计与开放的生态系统,则是决定最终胜负的终极战场。
这条道路充满了工程上的挑战,从原子尺度的材料科学,到数据中心规模的系统工程。但它也为创新者提供了无限的机遇。那些能够驾驭这种系统级复杂性,并构建起强大生态系统的参与者,将不仅定义下一代AI芯片,更将塑造未来智能社会的演化进程。
📢💻 【省心锐评】
AI芯片的未来,不再是单点冲刺的百米赛,而是考验架构、封装、软件与生态协同的“十项全能”。单打独斗的时代结束了,系统为王的时代已经到来。

评论